一种优化FCN的视频异常行为检测定位方法
2021-03-12陈纪铭陈利平
陈纪铭,陈利平
(湖南工学院 计算机与信息科学学院 湖南 衡阳 421002)
0 引 言
随着监控设备的日益普及,有必要通过计算机视觉技术对视频数据进行分析。其中,异常检测[1]是视频数据分析的重要分支。很多视频异常事件由稀少形状或罕见动作组成,但由于“异常”的定义具有一定的主观性,且取决于情景,因此,该研究的挑战性较大。
目前很多方法将正常帧的区域或分块作为参考模型进行学习,这些参考模型包括训练数据的正常运动或形状。在测试阶段,将不同于正常模型的区域视为异常。其中,目标行为常用基于轨迹的方法定义[2],但基于轨迹的方法存在2个主要缺陷[3]:①不能处理遮挡问题;②计算复杂度较高。为避免出现上述问题,一些方法使用了时空低阶特征,如光流或梯度。文献[4]将高斯模型拟合到时空梯度特征中,并使用隐Markov模型(hidden Markov model, HMM)来检测异常事件。文献[5]在相关约束下,利用光流特征图结构(graphic structure, GS)的迭代尺度化变换,有效降低了视频异常检测中的光流特征数量,从而完成特征优化。文献[6]提出一种公交车人群异常检测方法,根据人群运动轨迹确立图像感兴趣区域,利用L-K光流法提取运动目标速度信息,通过速度大小进行异常情况的检测。但该方法难以解决遮挡和大量人群问题。文献[7]提出了深度级联分类器(deep cascade classifier,DCC),利用2个深度神经网络进行异常检测,首先利用一个较小的深度网络识别出有挑战性的分块;然后将邻近分块通过另一个深度网络作分类操作。文献[8]提出基于密集轨迹对准及其运动影响描述符的算法,其中,密集轨迹保证对视频运动目标的有效提取,捕获运动目标的关键信息,然而该方法的计算复杂度较高,且无法对遮挡进行有效处理。文献[9]提出一种描述群体中的个体信息结构描述符,引入了固体物理中粒子间作用力的势能函数,同时,设计鲁棒的多目标跟踪器来关联不同帧中的目标。文献[10]提出利用灰度值与光流场的分布提取运动区域,通过对运动区域的分割得到有效运动块,使用运动连续性约束来抑制噪声,然而运动连续性约束产生很大的计算量。综上,大多数异常检测方法主要有2个改进方向:①特征优化,如采用梯度直方图或光流直方图等低阶特征;②框架改进,针对特定情况优化求解框架。
众所周知,卷积神经网络[11](convolution neural network, CNN)可以为各种应用确定有效的数据分析,与传统计算方法相比,其数据处理能力更强大,由于权值可以共享,所用参数的数量更少,可以适用于多种计算场景。但使用CNN进行异常检测时,分块的速度过慢,且无法从不存在的异常类中训练大量样本。全卷积网络[12](full convolution network, FCN)作为CNN的一种优化,依然存在以上问题。因此,本文对FCN进行优化,使用AlexNet模型[13]预训练的CNN的数个初始卷积层和一个额外卷积层,采用该方法提取出的特征,对于视频数据中的异常具有足够的可辨别性。本文主要工作总结如下:①将预训练分类的CNN应用到FCN,以生成同时描述运动和形状的视频区域;②提出了一种优化的FCN架构,以高效完成异常检测和定位。
1 所提方法概述
视频数据中的异常行为一般被定义为异常形状或异常运动。因此,形状和运动的识别至关重要。为了识别出运动特性,需要一系列视频帧。因为单帧中不包含运动特性,仅能提供形状信息。
为了同时分析形状和运动,本文考虑了当前帧It和上一帧It-1的像素平均为
(1)
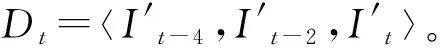
为了推导出特征向量,首先,在尺寸w×h递减的网格上对视频帧进行表征,定义序列Dt在大小w0×h0的网格Ω0上;然后,将序列Dt传递到FCN,由第k个中间卷积层定义,其中,k=0, 1,…,L,尺寸wk×hk的网格Ωk上定义每个视频帧,满足wk>wk+1,hk>hk+1。
FCN的第k个中间卷积层的输出为特征向量fk∈Rmk(即每个包含mk个实特征值),其中R为代数域,从m0= 1开始。对于输入序列Dt,第k个卷积层的输出为向量值矩阵
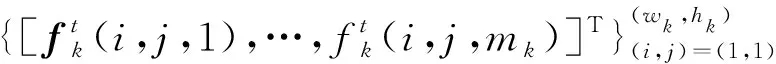
(2)
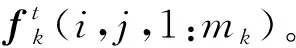
特征向量的推导可以总结为①针对视频第t帧给出Dt的高阶描述;②通过FCN的第k个中间卷积层(k=0, 1,…,L)对Dt进行表征。使用该表征,在Ωk(接受域)中识别出部分逐对重叠区域集合。同此,通过Ω0上的序列Dt对帧It进行表征;③通过Ωk上的mk次映射,从接受域推导特征向量。
假设视频的q个训练帧都是正常的,基于FCN的第k个卷积层对这些普通帧进行表征,则2D正常区域的描述可定义为wk×hk×q个长度为mk的向量。为了对正常行为建模,将高斯分布作为正常区域描述的分类器进行拟合,从而定义出正常参考模型。在测试阶段,以类似的方式通过一组区域特征来描述测试帧It。将不同于正常参考模型的区域标记为异常。值得一提,预训练CNN(AlexNet的第2层)生成的特征已经具备足够的可分辨性,对接受域的表征效果如图1。当再次通过自动编码器(即最终卷积层)来表示区域描述符时,异常区域在热图中更具视觉上的可区分性。

图1 对接受域的表征效果Fig.1 Representation of reception domain
本文将可疑区域表征为一个“更具辨识性”的特征集。这一表示法有助于更好地区分异常区域和正常区域。即AlexNet生成的特征被转换为一个异常检测问题,通过在普通区域上训练的自动编码器来完成;然后,将可疑区域传递至自动编码器,以得到更好的表征。
本文所提检测方法的流程图如图2。首先,将输入帧传递至预训练后的FCN;然后,在第k层的输出中生成hk×wk个区域特征向量。使用高斯分类器G1对这些特征向量进行验证。将与G1存在显著差异的分块标记为异常。将低拟合置信度的可疑区域输入到稀疏自动编码器中。在该阶段中,基于高斯分类器G2(与G1工作原理相似)标记这些区域。G2是区域特征向量上训练后的高斯分类器,表示为一个自动编码器;最后,这些异常区域的位置将被自动传回FCN。

图2 所提方法流程图Fig.2 Flow chart of the proposed method
2 本文关键技术
2.1 优化的FCN结构
本文使用卷积层将CNN的分类调整为FCN。由于选择最适合表征视频的层至关重要,本文考虑如下2点。
1)虽然深层特征通常具更好的可分辨性,但使用深层特征会增加计算时间。此外,由于CNN针对图像分类而训练,使用更深层次可能会得到图像分类的过拟合特征。
2)更深层次会造成输入数据中接受域更大;由此会增加不准确定位的可能性,造成性能下降。
所实施的FCN包含3个卷积层,为了找到最优卷积层k,设初始k为1,其后增加至3。在确定最优k后,忽略更深的卷积层。首先,使用层C1的输出,在区分异常区域与正常区域时,相应的接受域尺寸较小,且生成的特征无法得到适当结果,因此,会得到大量假阳性样本;然后,使用更深层的C2的输出。在此阶段得到优于C1的性能,这是因为在C1的输入帧中相应的接受域足够大,且更深的特征具有更好的可分辨性;最后,k=3时,将层C3的结果作为输出。此时,虽然网络容量增加,但结果却不如第2个卷积层。因此,多增加1层将会得到更深的特征,但这些特征存在过拟合现象。
综上,本文使用C2的输出来提取区域特征,利用卷积层转换每个生成区域特征的描述[14],通过稀疏自动编码器得到卷积层的内核。所提FCN结构如图3,该FCN仅用于区域特征提取。在之后的阶段,嵌入2个高斯分类器以标记异常区域。新的层称为CT,位于CNN的C2层之上。通过预训练CNN的3个初始层(即卷积层C1、下采样层S1和卷积层C2)与额外的新卷积层的组合,作为异常检测的联合架构。
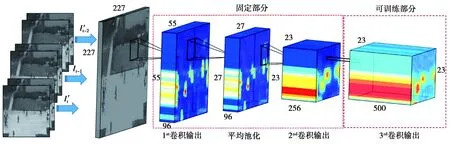
图3 所提优化的FCN结构Fig.3 Proposed optimized FCN structure
优化的FCN包括2部分:固定部分和可训练部分。固定部分来自于AlexNet,所有的训练视频帧由固定部分来表征,使用从正常视频中提取出的所有特征向量来训练稀疏自动编码器。将1×1×256特征向量转换为尺寸1×1×500的稀疏向量(见图3)。假定有m个(1, 256)维的特征向量,而xi∈RD=1×256是用于自动编码器学习的原始数据。自动编码器通过重建原始数据以最小化公式
(3)
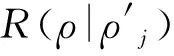
2.2 异常检测
本文使用区域特征集对视频进行表征。这些特征是密集提取的,通过第k个卷积层输出的特征向量来描述。针对判断的标准,首先,将一个高斯分类器G1(.)拟合到FCN生成的所有正常区域特征中;然后,判断与G1(.)的距离大于阈值α的区域特征视为异常;与G1相兼容的区域特征(即与G1的距离低于阈值β)标记为正常;与G1之间的距离在α和β之间的区域视为可疑区域。
将所有可疑区域传递至下一个卷积层,该卷积层在预训练FCN生成的所有正常区域上训练。由此,这些可疑区域将获得分辨性更好的新表征
当n=1,2,…,h
(4)
(4)式中,h表示自动编码器生成的特征向量的大小(与隐藏层的大小相等)。
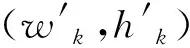
(5)
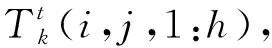
(6)
(6)式中,d(G,x)为区域特征向量x到G-模型的Mahalanobis距离。
2.3 定 位
假设第一个卷积层有m1个尺寸为x1×y1的卷积内核。在分析第t帧时,序列Dt用这些内核作卷积,通过卷积运算提取特征。通过长度为m1的特征向量来描述FCN输入的每个区域。在这个连续过程中,将mk个映射作为第k层的输出。由此,用第k层输出的一个点,来描述FCN输入中重叠的第(x1×y1)个接受域的子集,如图4。
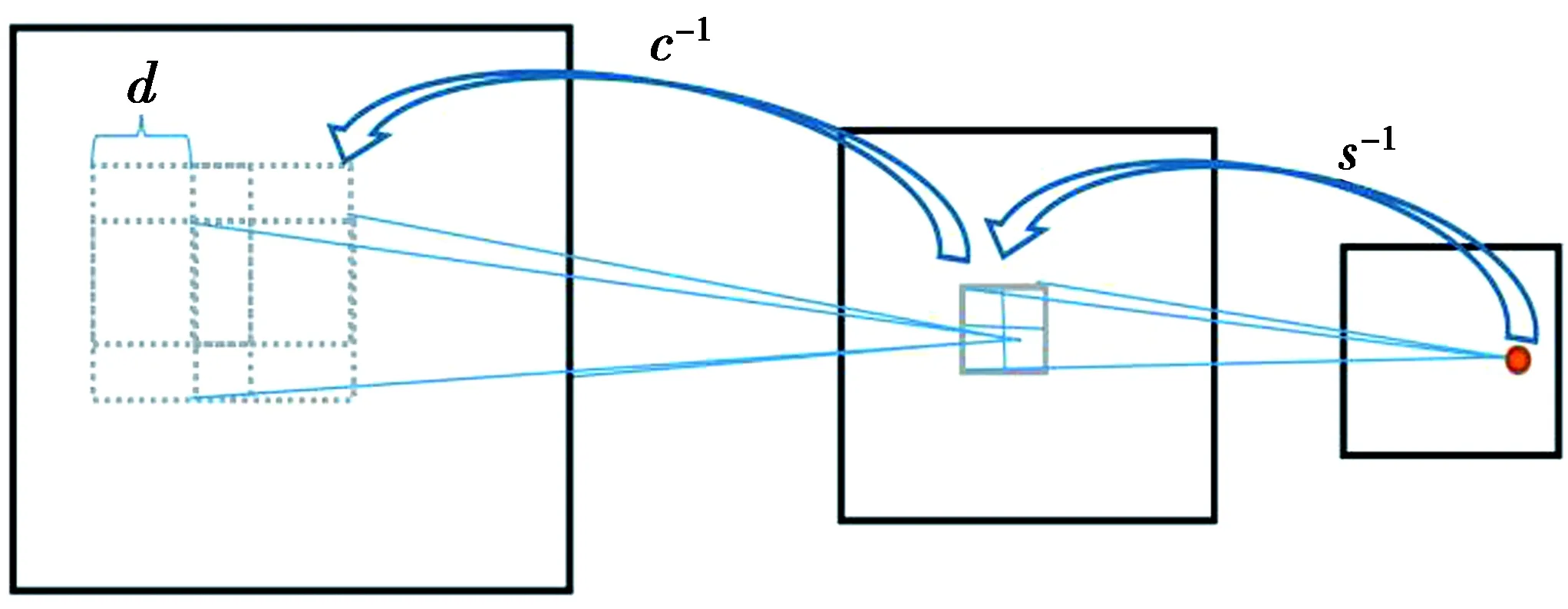
图4 寻找输入帧的相关接受域Fig.4 Finding the relevant reception domain of input frame
修改后的AlexNet中的层序为
Alexnet→[C1,S1,C2,S2,C3,fc1,fc2]
(7)
(7)式中,C和S分别为卷积层和下采样层。最后2层为全连接层。
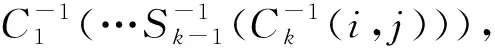
另外,下采样(平均池化)层也可考虑为仅有1个内核的卷积层。原始帧(即Ω0)中任何被检测为异常的区域,均为一些较大重叠分块的组合,但这样会造成定位性能较差。为了提高异常检测的精度,本文将Ω0中被超过ζ个相关接受域覆盖的像素识别为异常。
3 实验结果与分析
3.1 数据集及参数设置
实验基于前文定义的最优FCN(见图3)完成所有测试。在自动编码器的目标函数中,β(惩罚项权值),ρ(稀疏性)和s(隐藏层节点数)的参数值分别设为0.1,0.05和500,其中,隐藏层的节点用于存储可训练部分向量(最大维数为500),因此,s取值500。参数β为稀疏自动编码器目标函数中惩罚项的权值,ρ是伯努利分布的参数,表示稀疏性,即通过自动编码器以0.05的稀疏性完成特征学习,且β和ρ均是经验数值。
本文在UCSD[15]和Subway数据集[16]上对所提方法进行性能评价。其中,UCSD数据集内的动态目标是行人,人群密度从低到高变化,汽车、滑板、轮椅或自行车等目标视为异常。数据集中包含12个用于测试的视频序列,16个用于训练的视频序列,分辨率为320像素×240像素,异常帧和正常帧的总数分别为约2 384帧和约2 566帧。
Subway数据集包括地铁站入口(96 min,144 249帧)和出口(43 min,64 900帧)录制的2个视频序列。进出车站的人通常是行为正常的。异常事件定义为向错误方向移动的人(即离开入口或进入出口),或逃票。该数据集存在2个局限:异常事件的数量较少,且空间上的定位是可预测的(在入口或出口区域)。
3.2 评价指标
本文使用受试者操作特征(receiver operating characteristic, ROC)曲线、等错误率(equal error rate, EER)和曲线下面积(area under curve, AUC),比较所提方法与其他先进方法的结果。使用了帧级和像素级2个度量[17]。根据这些度量将帧分为异常(阳性)或正常(阴性)。这些度量定义如下。
1)帧级:该度量中,若1个像素检测到异常,则考虑其为异常。
2)像素级:若算法检测出的像素至少覆盖了40%异常的真实像素,则该帧被视为异常。
3.3 定性和定量结果
所提方法在UCSD和Subway数据集的样本上的输出如图5。可以看出,本文方法正确检测并定位了这些样本的异常。图5a的UCSD数据集检测结果中,在校园道路上,检测出一些使用滑轮车的人、骑自行车的人以及行驶的汽车;图5b的Subway数据集检测结果中,第1行是地铁出口的门禁处,有行人准备逆向行走,并有跨越门禁的行为。这些行为均被检测出,并标有红色,其中,第2,第3帧是从出口强行通过门禁进入地铁,第4帧是从楼梯处逆向步行到门禁处。第2行是地铁入口,第2行的第2和第3帧图像检测出异常,可以看出,该人正在翻越门禁,第4帧图像检测的异常是该人正在逆向行走,从入口出来。
目前,绝大数异常检测方法的主要问题是依然存在一定的假阳性率。图6给出了使用所提方法时,被错误地检测为异常区域(假阳性)的例子。假阳性会在2种情况下产生:①过于拥挤的场景;②人们向不同方向行走。由于训练识别中未观察到走反方向的其他行人,所提方法会将这一行为识别为异常。

图6 2个假阳性样例Fig.6 Two false positive samples
所提方法与文献[4]提出的隐Markov模型方法(简称HMM[4])、文献[5]光流特征图结构方法(检测GS[5])和文献[7]提出的深度级联分类器方法(DCC[7])进行比较。各方法在UCSD数据集上的帧级和像素级的ROC比较如图7。
图7中TPR(%)表示分到正样本中真实的正样本占所有正样本的比例,定义为
(8)
(8)式中:TP表示被判定为正样本,事实也是正样本;FN表示被判定为负样本,事实是正样本。
FPR(%)表示被错误分到正样本类别中真实的负样本占所有负样本总数的比例,定义为
(9)
(9)式中,FP表示被判定为正样本,事实是负样本;TN表示被判定为负样本,事实也是负样本。
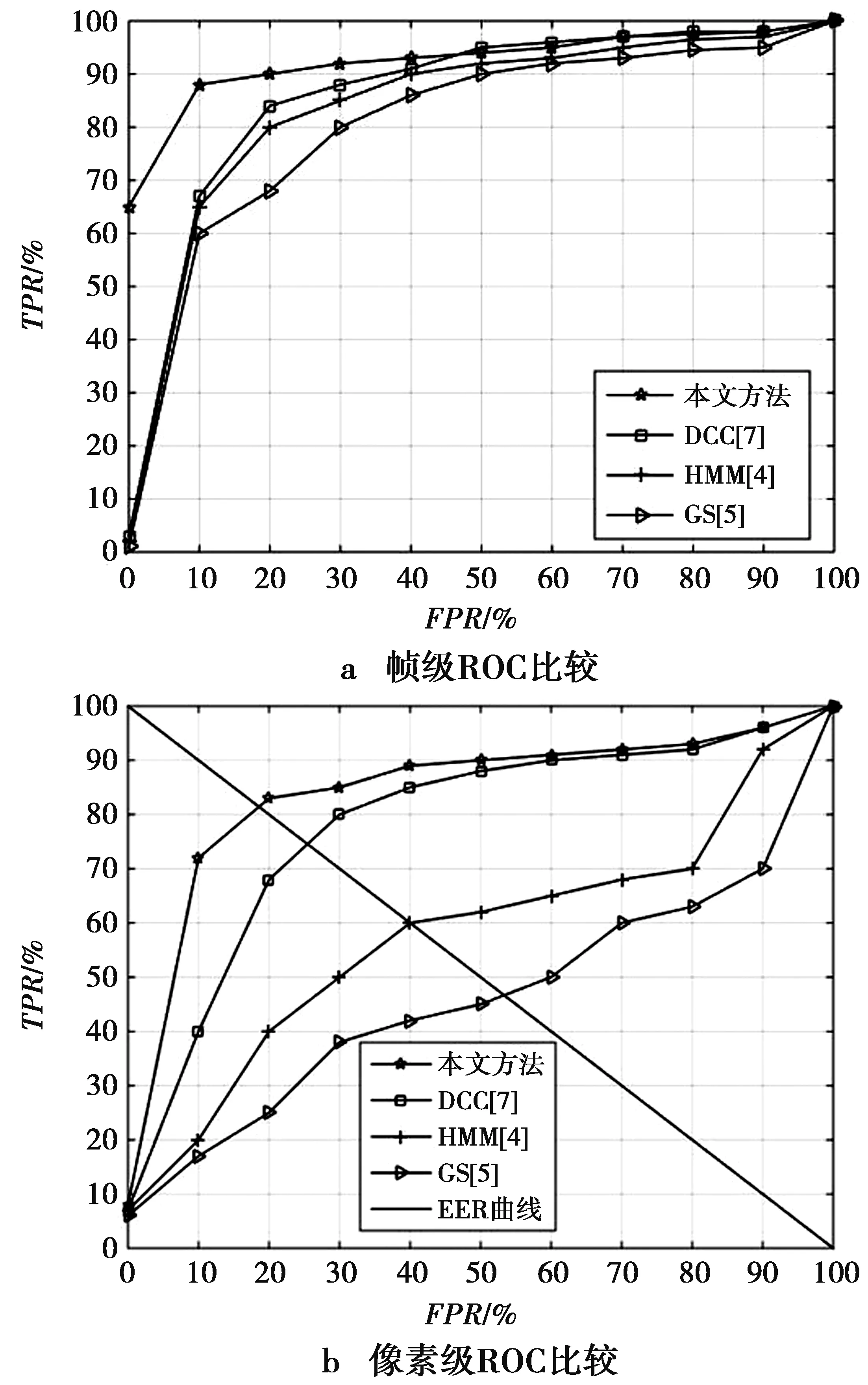
图7 各方法的ROC比较Fig.7 ROC comparison of different methods
在图7的ROC结果图中,当FPR越小,TPR越大时,表示分类的效果越好。EER用于衡量方法的整体性能,表示FPR等于FNR(假阴性)的值,由于FNR=1-TPR,因此,可以画一条从(0,1)到(1,0)的直线(即EER曲线),该曲线与某方法ROC曲线的交点(横坐标FPR值)表示该方法的EER值,EER值越小表示错误率越低,方法性能越好。由图7a和图7b可知,所提方法的ROC性能优于其他方法。这主要是因为所提FCN架构对输入数据作了分块级操作,生成的区域特征不受情境影响,从而增加了异常检测的准确率,降低了误检率。
在UCSD数据集上,各方法在的帧级和像素级EER如表1。所提方法的帧级EER为11%,仅次于DCC[7]的EER,在像素级EER方面,所提方法的EER为15%,表现最优。
在Subway数据集上,各方法在AUC和EER方面的性能比较如表2,这里分别讨论了地铁出口和入口。表格中的数值第1个是AUC值,第2个是EER值。对于出口场景,所提方法在AUC和EER度量上均优于其他方法;其中AUC和EER分别比其他方法至少提升0.5%和0.4%。对于入口场景,所提方法的AUC比其他方法至少提升0.4%;在EER度量上提出的方法性能与DCC[7]几乎相同。

表1 各方法在UCSD数据集的EER性能比较

表2 各方法在Subway数据集的性能比较
3.4 参数敏感性分析
由于β和ρ的取值可能会对性能结果产生影响,因此,有必要对这些参数的敏感性进行分析。其中,β是正则化项的惩罚系数,取值为[0,1];ρ是稀疏性参数,也是伯努利分布(0~1)的概率,取值为(0,1),实验常用的几个数值有0.01,0.05,0.1,0.2和0.5;实验数据集选取Subway,度量采用EER值,β与EER关系如图8。可以看出,β取值0时,正则化项的系数为0,函数退化,EER性能最差;当正则化项的惩罚系数β为0.1时,EER表现较优。稀疏性参数ρ与EER关系如表3,可以看出,ρ=0.05,EER表现最优。通常情况下,ρ值越大,区域特征的表征越差,因为一些无用特征的权重被赋值;相反,ρ值越小,很多无用特征的权重被置为0,有利于特征表示。

表3 稀疏性参数ρ的影响
3.5 运行时间分析
本文方法在Intel酷睿双核i3的台式机上运行,2.89 GHz,内存4 GByte,采用matlab和C++混合编程。在处理视频帧时,需要执行3个步骤:①重新调整帧尺寸并重建FCN的输入;②通过FCN对输入进行表征;③利用高斯分类器对区域描述符进行检验。所提方法预处理平均时间为0.01 s,表征0.001 s,分类0.01 s,单个帧的异常检测为0.021 s,大约60 frame/s。

图8 惩罚系数β的影响Fig.8 Influence of penalty coefficient β
与其他方法的比较如表4,由于硬件和编程方法的差异,会有所差异,但差异应该不会很大。可以看出,本文方法速度最快。其原因主要在于使用了全卷积神经网络,仅处理2个卷积层,并使用稀疏自动编码器对一些区域进行分类。处理这些较浅的层可以明显降低计算量。此外,本文方法还采用FCN同时执行特征提取和定位,由此实现了比其他方法更快的处理速度。
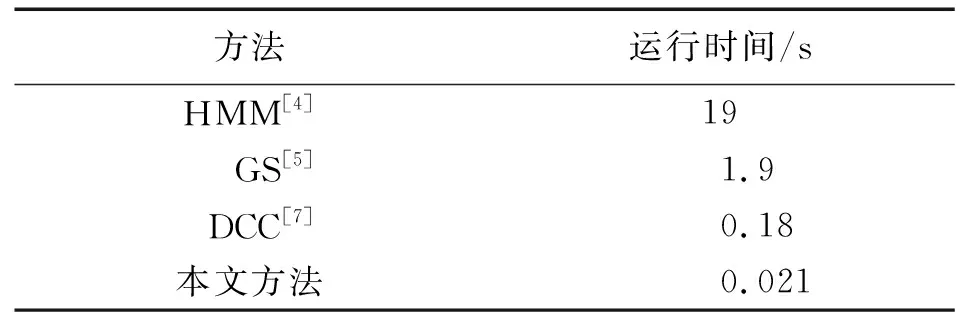
表4 平均运行时间比较
4 结 论
本文提出了一个优化的FCN架构,生成并描述视频的异常区域。利用FCN架构对输入数据做分块级操作,由此生成的区域特征不受情境影响。此外,提出的FCN结合了预训练CNN(AlexNet版本)和卷积层(根据训练视频训练的内核),克服了使用训练采样来学习完备CNN的限制。实验结果表明,所提方法优于其他同类方法,且整个方法的运行速度在60 frame/s左右,实时性较好。
