基于SVM的网络不良信息识别方法
2021-03-04陆向艳,陆生权,刘峻
陆向艳,陆生权,刘峻
摘要:当前用户在互联网中发布的一些文本信息中包含色情、暴力、政治敏感或恶意广告等不良信息,对网络生态环境造成破坏,特别对广大青少年网民的健康成长影响较大。本文提出一种基于SVM的不良信息识别方法,该方法包括文本标记、文本分词、Doc2Vec文本向量化、SVM不良信息分类器训练、SVM不良信息测试5个步骤。实验结果表明该方法能有效识别网络不良信息,为网络不良信息的甄别提供了一种方法参考。
关键词:不良信息 ;SVM;识别;Doc2Vec;Jieba分词
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)34-0097-02
1引言
当前互联网进入了快速发展的阶段,第44次《中国互联网络发展状况统计报告》[1]显示,截至2019年6月,我国网民数量达8.54亿。互联网信息发布呈指数级的快速增长,其中一些信息内容涉及色情、暴力、政治敏感或为恶意广告,这些信息对网络生态环境造成了不良影响,若不加甄别将对广大青少年网民的健康成长带来不利影响。将网络不良过滤后,再呈现给青少年具有重要意义。当前互联网不良信息识别主要有基于语义和基于机器学习两种方法[2-5],基于后者本文提出一种基于SVM的不良信息識别方法,为不良信息识别,净化网络提供参考。
2 基于SVM的网络不良信息识别方法
2.1 识别模型
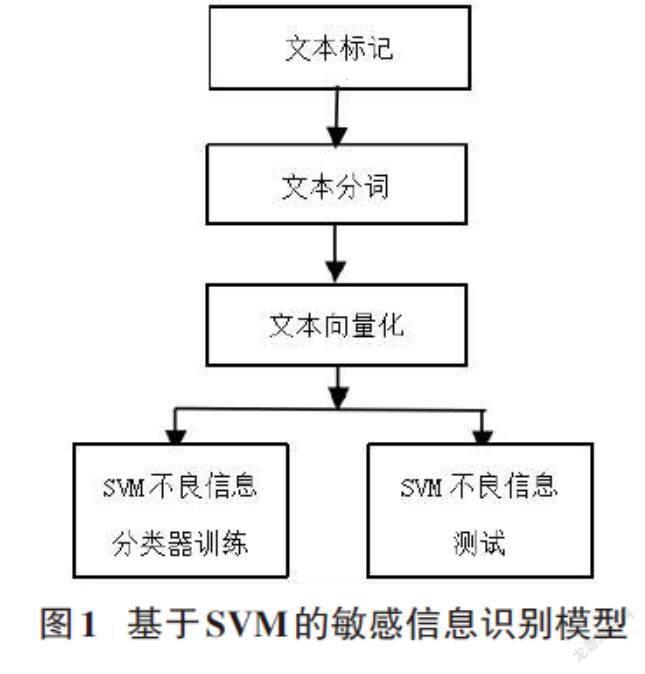
基于SVM的网络不良信息识别方法包括文本标记、文本分词、Doc2Vec文本向量化、SVM不良信息分类器训练、SVM不良信息测试5个步骤,方法模型如图1所示。
2.2文本标记
用爬虫收集网络文本数据集,将数据集分成训练集和测试集两部分,并进行分类标记,不包含色情、暴力、政治不良和广告这四种敏感词的文本数据集标记为正面数据,包含的则标记为负面数据,并按类别分开训练和测试。
2.3文本分词
应用Python中文分词组件Jieba分词的精确模式对所有文本数据集进行分词、去除停用词处理。
2.4 Doc2Vec文本向量化
用Doc2Vec模型将文本分词进行向量化,设置词向量长度为200(对于SVM来说就是有200个特征),形成文本数据的向量化表示,用于后续的SVM训练和测试。
2.5 SVM不良信息分类器训练
经过Doc2Vec文本向量化后的训练数据集表示为{T1,T2,T3,T4}分别代表政治敏感、色情、广告和暴力四个类别的数据集,第i个数据集:Ti={(ai1,bi1),(ai2,bi2),...,(aim,bim)},其中aij表示第i个数据集第j个文本的词向量,bij表示第i个数据集第j个文本的是否为不良信息,是则取值为1,不是则取值为0。分别用SVM算法对数据{T1,T2,T3,T4}进行训练得到对应的分类器。
2.6 SVM不良信息测试
SVM训练成功后.利用训练好的SVM分类器对向量化以后的测试数据集进行不良信息分类测试,以确定测试文本是否为不良信息。
3 实验和结果分析
实验数据是用爬虫进行数据爬取,收集政治敏感、色情、广告和暴力四个类别文本数据各800个,600个文本用于训练,200个文本用于测试。将本文方法和基于朴素贝叶斯(NB)的不良信息识别方法进行对比实验,验证本文提出的基于SVM的网络不良信息方法的有效性。采用正确率,召回率,F1值作为评价指标,计算公式为:
正确率=(TP+TN)/(P+N) (1)
召回率=TP/(TP+FN) (2)
F值=(TP+TN)/(P+N) (3)
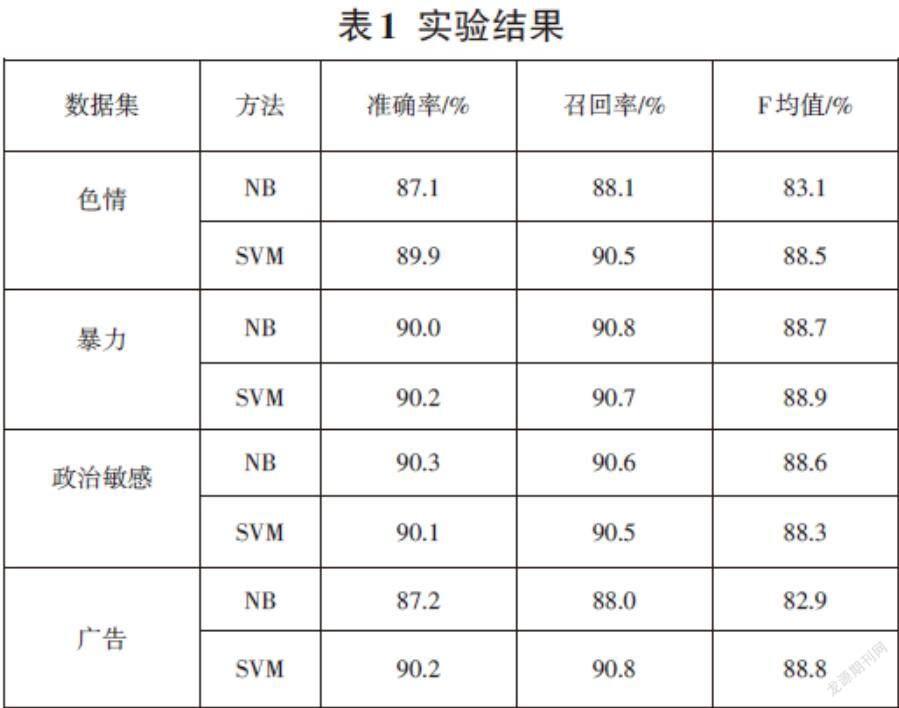
其中,P为正面样本数,N为负面样本数,P+N为总样本数,TP为将正的预测为正的数目,TN表示将负的预测为负的数目,TP+FN为预测总信息数。实验结果如表1所示。
实验对于暴力和政治敏感数据集,SVM算法和朴素贝叶斯算法的准确率和召回率基本相同,而对于色情和广告数据,SVM方法的准确率和召回率都高于朴素贝叶斯方法,主要原因是朴素贝叶斯的属性独立性假设造成,因为色情和广告文本分词比政治敏感及暴力文本具有更大的属性相关性。
4 结论
网络不良文本信息会对网络生态环境造成破坏,尤其会对青少年儿童的健康成长具有较大的影响。本文提出一种基于SVM的网络不良信息识别方法。实验结果表明本文方法能有效识别不良文本信息。对净化网络环境,辅助青少年网民健康成长具有重要意义。
参考文献:
[1] 于朝晖.CNNIC发布第44次《中国互联网络发展状况统计报告》[J].网信军民融合,2019(9):30-31.
[2] 汤烈,穆合义,候爱莲,等.基于K最近邻算法的网络不良信息过滤系统研究[J].计算技术与自动化,2019,38(4):172-175.
[3] 李兆翠,朱振方,李颖.基于改进SVM的网页过滤系统研究[J].软件导刊,2016,15(2):159-161.
[4] 刘玉娥.基于数据挖掘技术的网络信息过滤系统设计[J].现代电子技术,2018,41(16):51-54.
[5] 刘凯.移动网络环境中不良信息智能过滤方法仿真[J].计算机仿真,2018,35(10):329-332.
[6] 王斌.基于朴素贝叶斯算法的垃圾邮件过滤系统的研究与实现[J].电子设计工程,2018,26(17):171-174.
[7] 孙玉杰.中文词汇语义关系抽取及应用研究[D].南京:南京师范大学,2014.
[8] 聂证,曹燕.大数据时代面临的信息安全机遇和挑战[J].信息记录材料,2018,19(2):47-48.
【通联编辑:唐一东】
