基于时空缓存数据库的医院图书馆人脸识别应用研究
2021-02-28冯瑛
冯瑛
(延安市人民医院,陕西 延安 716000)
0 前 言
医院图书馆管理关系到医护人员借阅的便捷性,也是医院技术水平提高的象征性标志之一[1]。现有技术中,出入医院图书馆的人员大多采用电脑登记和刷卡方式进行管理,这种方式管理落后。
随着人工智能和人脸识别技术的逐步发展和应用,在医院图书馆中,出现了相关技术研究[2]。文献[3]公开了一种将人脸识别和门禁系统相结合的方法,这种方法虽然能够在一定程度上解决医院图书馆的安全性问题,但是人脸识别系统还是存在高错误率。文献[4]公开了一种打破传统的新型Adaboost算法,将这个算法运用到人脸识别中。这种方法虽然能够在一定程度上增加人脸识别的准确率,但是在人多情况下识别需要消耗大量的时间[5]。针对上述技术问题的不足,本文采用一种新型的图书馆人脸识别方法。
1 总体方案结构图
本文应用了一种时空缓存数据库的管理方法,该方法将时空数据模型和新型Adaboost算法恰当地融合在一起,能够实现进出图书馆人脸信息的动态索引和查询,进而解决现有技术中人脸识别技术的识别准确率差和速度慢的问题[6],其中时空数据模型在实际应用中有多种形式,例如时空耦合模型、连续快照模型、基态修准模型、立体时空模型和时空对象模型等。模型以时空数据库为基础,对采集到的医院图书馆人脸数据信息进行综合管理。本文方案的总体架构如图1所示。
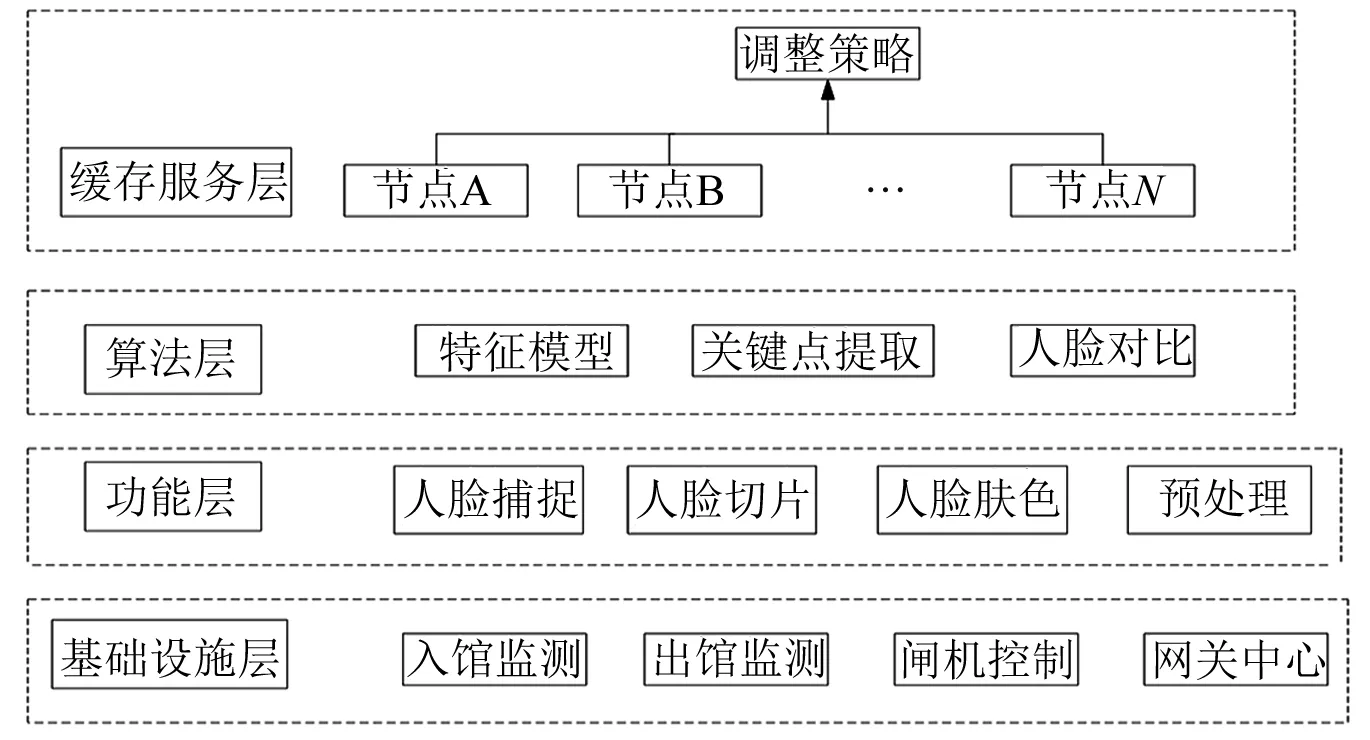
图1 总体架构示意图
在本文研究的技术方案中,将整体的结构图划分为多个不同模块,这些模块分别为基础设施层、功能层、算法层和缓存服务层4个模块,通过这4个模块,能够实现图书馆入馆人员的信息监测、信息捕捉、特征算法和人脸对比等处理,最终实现人脸识别应用。下面分别进行说明。
(1) 基础设施层。基础设施层主要是医院图书馆的门禁系统的操作设施,其中包括入馆监测、出馆监测、闸机控制和网关中心。入馆监测和出馆监测均通过智能摄像头智能扫描采集人脸图像数据信息。闸机控制在接收到人脸识别正确的数据信息后自动开启,红外线扫描人员通过后自动关闭等待下一个信息。网关中心主要是保证网络的通信正常和安全,若出现紧急状况则放弃闸机通道开启紧急安全通道,人员进行人脸识别记录后直接穿过即可。
(2) 功能层。功能层为基础设施层提供相关的技术支持,该层主要是对人脸数据的收集和预处理。当人员人脸对上智能摄像头时,采用静态图像分析人脸的不同位置、不同角度和不同表情收集数据信息进行保存。人脸切片是对于人脸的小范围进行识别扫描,这样能将人脸特征识别得更为细微精确。通过小区域的人脸肤色特征,首先选择颜色空间,然后根据亮度的分级和色度值分类,接着建立肤色特征模型,最后将人脸图像数据信息进行简单的预处理。
(3) 算法层。算法层是根据功能层提供的数据信息进行分析计算,将结果反馈至基础设施层。算法层包含的内容有特征模型、关键点提取和人脸对比。关键点提取是把特征模型的图像信息进行数字化,得到这个特征的人脸编号序列。人脸对比是利用缓存服务层搜索不同的人脸编号序列,并对比不同人脸的特征模型,从中来判断该人脸图像数据信息是否需要进行缓存。
(4) 缓存服务层。缓存服务层是为算法层提供很好的访问性能。该层是利用Redis集群构建时空缓存数据库,用来存储人脸图像的数据信息,为算法层进行人脸对比提供便利。
2 关键技术设计
在实际工作中,图书馆人员进出比较复杂,采集到的图片信息蕴含了多种具有多维度和时间维度的数据量,基于这些数据量,常规技术的索引和查询方式在动态识别人脸方面显得尤为困难。因此,为了提高图书馆人脸识别水平,动态检索和查询就非常必要。本文还通过Redis集群分布式缓存构架实现图书馆的时空缓存数据库数据存储,这种方法能够解决图像识别困难和识别时间长的问题。
2.1 Adaboost算法模型在人脸识别中的应用
本文采用改进型Adaboost算法,分类模型架构如图2所示。
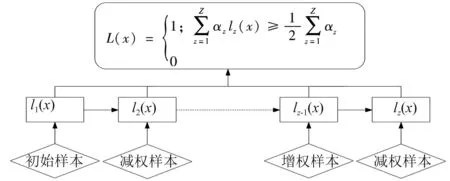
图2 Adaboost算法模型应用示意图
Adaboost算法模型的应用过程说明如下:
(1) 假设将进出图书馆的人脸特征集合记作为{(x1,y1),(x2,y2),…,(xn,yn)}。在该数据集合中,将x记作为一种类型的人脸特征,用字母y表示经过分类器分类后的人脸特征标识,为了区分对待,将人脸特征可以记为0和1。在y=0的情况下,该特征表示为非人脸数据样本,在y=1的情况下,表示该特征为分类属性范围内的人脸样本。n为分类特征中人脸特征类型的数量[7]。
(2) 然后对分类后的人脸特征进行赋值、计算,其中赋值的数据集合记作为:
D={D0,1,D0,2,…,D0,n}
(1)

(3) 然后再归一化处理分类器输出的人脸特征样本权值,输出的样本数据集合为:
pz={pz,1,pz,2,…,pz,n}
(2)
式中:pz为人脸特征样本权值;pz,n为第n特征集合的人脸特征样本权值。
(3)
式中:πz,n为分类器的属性。
(4) 经过权值归一化处理后,弱分类器可以转换为以下形式:
lz:{x1,x2,…,xn}→{0,1}
(4)
式中:xn为不同的弱分类器。每个不同的分类错误率可以通过式(5)来表示。
(5)
式中:ξz为分类错误率;Pz,j为第j特征集合的人脸特征样本权值;hz(xi)为分类器;yi为第i个数据集。
(5) 在历经弱分类器经过Z次分类后,弱分类器可以转换成强分类器L(x),可以通过式(6)表示。
(6)
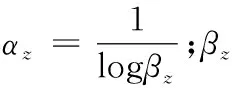
经过上述公式讨论后,再进行图书馆人脸识别时,可以针对不同类型的用户进行人脸识别,大大提高了人脸识别程度。针对非人脸特征样本的图像识别如图3所示。
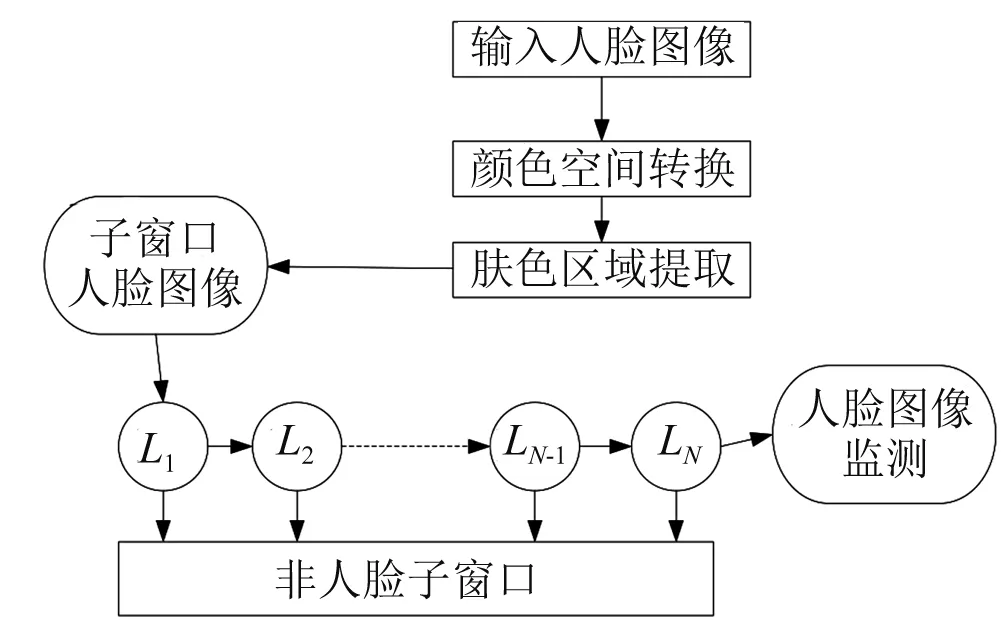
图3 非人脸特征样本处理示意图
在进行非人脸特征样本进行识别时,首先需要设置分类阈值,如果抽取的样本数据信息的权值处于设定的阈值范围内,可以再进一步增加样本的权值。当抽取的样本数据信息的权值没有在设定的阈值范围内时,则将权值进行减小处理。由于选择的弱分类器不同,输出的权值也不同。通过调整不同分类器的权值,可以提高样本训练的正确率。而强分类器是将多种强分类器串联在一起,每个强分类器都由多种弱分类器组合而成,这样通过多层次地对人脸特征进行筛选,提高了人脸精度。
在上述步骤中,尤其是在提取肤色区域时,需要构建肤色模型。这是由于肤色模型不同,需要构建不同的数学建模,以进一步描述肤色在不同色彩空间之间的分布情况,通过这种方式,能够识别出图像中那些部分属于肤色[8]。再进行阈值计算,通过阈值的不同,能够构建起肤色模型和非肤色模型,通过这种方式以将肤色区域和非肤色区域区分开来。
2.2 Redis集群设计
2.2.1 Redis和Redis集群
Redis集群和Memcached集群在结构上比较类似,都是NoSQL中的一种,属于内存比较高、运行比较快的高性能key-value(k-v)数据库。这种方式与Memcached所表现不同的是,Redis集群能够支持string、list、set、zset(sorted set)和hash类型数据类型,上述的这些数据类型大部分都能够支撑push/pop、add/remove交集、并集和差集等多种、多项操作,与memcached集群表现形式比较类型。在工作过程中,为了保证数据集合的应用效率,大部分数据被缓存在内存中[9]。有待区分的是redis集群,该集群能够周期性地把更新后的数据信息读入磁盘,或者将修改后的操作信息存储到记录文件中,进而使得master-slave能够实现(主从)同步工作。在应用redis集群之后,能够将memcached集群这类key/value存储信息的不足给充分地利用起来。该数据库信息提供了多种应用信息,比如Java、C/C++、C#、PHP、JavaScript、Perl、Object-C、Python、Ruby和Erlang等客户端。
2.2.2 Redis-Cluster 集群构建时空缓存数据库
在对Redis进行初始分布时,通常应用分片的方式进行,在具体应用时,应用客户端和Proxy分片的方式进行,在应用客户端时,在水平方面的扩展程度比较不易,硬件资源内耗比较大,需要的硬件环境也比较高。需要在Redis3.0集群的情况下提出Cluster集群模式,模式示意图如图4所示。

图4 Redis-Cluster集群架构示意图
通过图4可以看出,当应用Redis-Cluster集群时,通常是无中心结构的。图4中的每个应用网络节点都能够将数据和整个集群状态存储起来,其中节点之间实现了互联互通,不同的Redis节点之间互联(PING-PONG机制)过程中实现信息交互。集群架构中还使用二进制协议进行数据优化,以进一步优化网络的传输速度和带宽。网络节点的fail能够借助于集群中节点(通常超过一半)才能实现正常工作。
在客户端,通过将应用的硬件设备与Redis节点实现直接连接,该过程无需中间Proxy层即可完成。因此,在客户端应用的用户不必连接集群内的所有节点,任意一个连接节点即可满足需求。在应用过程中,还需要根据人脸识别系统,对 Redis集群的应用方法进行设置或者配置。
(1) 节点的配置或者创建。对三个不同的主节点进行创建,假设其不同的节点分别为 A、B、C,并且A、B、C三种不同的节点可以分别为一台机器上的三个端口,也可以为三台不同的服务器的三个节点。
(2) 空间分片。空间分片能够实现节点数据的快速应用,在具体工作时,能够采用哈希槽 (hash slot)对16 384个slot进行分类,如果应用了3个不同的节点,则这三个节点能够实现不同的应用功能,比如在slot 区间范围内:在节点A,能够覆盖0~5 460范围内的数据信息;在节点B,能够覆盖5 461~10 922范围内的数据信息;在节点C,能够覆盖10 923~16 383范围内的数据信息。在具体应用过程中,假设对一个数据信息数据进行存储,可以根据Redis-Cluster哈希算法进行计算,计算式有:
CRC16(‘key’)384 = 6 782
在这种情况下,能够将key 的数值存储在B中。通过这种方式,当对(A,B,C)内任一节点进行“key”信息获取时,能够将内部节点跳转到B节点,以进一步获取相关数据信息。
(3) 节点时间调度。如果在应用过程中,需要对某个节点进行增加或者删除,集群量不会减少,集群过程也不会停止。根据该原理,在大量人员入馆和离馆过程中,将全部的缓存节点缓存起来,能够大大提高进入馆人员的人脸识别度。
3 仿真试验与分析
为了能够证实Redis集群构建时空缓存数据库能够提高人脸识别技术的计算速度、增强过的Adaboost算法能够提高人脸识别准确率,下面将分别进行仿真试验。
3.1 Redis 集群的构建时空缓存数据库
首先要构建Redis 集群,来检验人脸识别系统加入时空缓存数据库能有效地提升识别计算速度。本文采用CentOS6.8(x64)操作系统、4.0.1版本的Redis和2.4.6版本的ruby脚本,Intel(R) Xeon(R) CPU E5-2640 v2、2.00 GHz主频、千兆网卡、8核16G内存、512 GB硬盘的硬件环境[10]。创建三个服务器主节点,分别复制备份出2个虚拟节点,一共9个节点搭建Redis集群作为分布式缓存。为了检验各种类别测试人脸特征的识别效果,试验调取了100张人脸图像,从不同年龄段、不同性别、不同肤色和不同人脸角度分别测试每张图像的识别效果。采用时空缓存数据库和Redis集群的识别时间,与传统人脸识别方法识别的时间进行对比,结果如表1所示。

表1 人脸识别耗时对比 ms
如表1所示,有关人脸识别的四个数据类型,采用100张人脸图像,基于时空缓存数据库和Redis集群的识别方法与传统识别方法相比,耗时全部都要短。为了对比更加清晰,本文将以柱状图形式展现,对比示意图如图5所示。

图5 人脸识别耗时对比图
如图5所示,用时空缓存数据库和Redis集群使人脸识别的执行速度得到有效提升,比传统识别方法快了大约10%。因此得出结论:对于医院图书馆人脸识别系统来说,构建时空缓存数据库的效果还是很明显的。
3.2 Adaboost算法验证
与传统的Adaboost算法不同,本文采用的新型Adaboost算法在漏检率方面大大降低,下面来进行仿真试验。采用Pentium(R)CPU、8核16G内存,电脑的硬盘容量为256G的硬件环境,软件的操作系统Windows XP, JDK1.5,通过MATLAB软件系统进行仿真。分别对单人脸的正面、单人脸侧面和多人脸正面图像进行识别,数量均为 100张人脸图像,统计成功识别的次数,结果如表2所示。
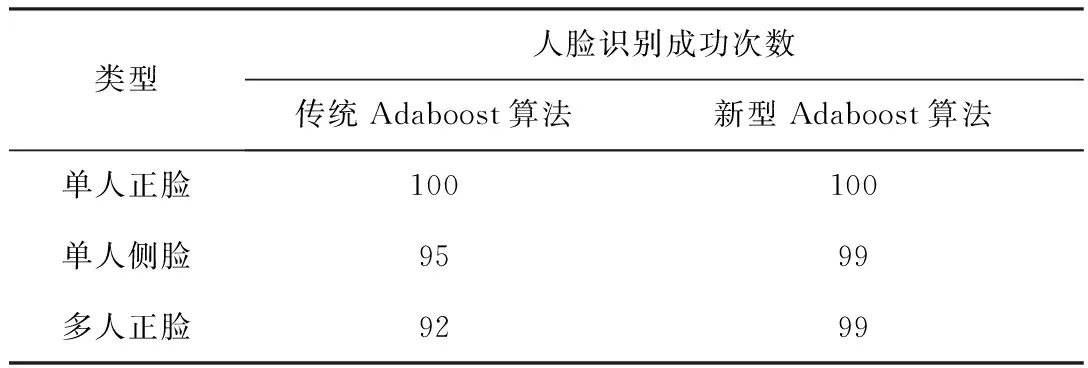
表2 人脸识别成功次数对比 次
通过上述数据,在单人正脸方面,由于人脸识别比较容易,传统Adaboost算法和改进过的Adaboost算法均能全部成功识别,没有表现出差距。在单人侧脸和多人正脸方面,存在识别的关键点减少等因素影响,有时会无法完全识别人脸图像特征,识别率为95%和92%。根据肤色特征可以大大减少上述因素的影响,利用新型的Adaboost算法识别率均提高到99%。仿真试验结果表明:新型Adaboost算法可以提高准确度。
4 结束语
本文基于时空缓存数据库设计了新颖的人脸识别系统,利用Redis集群在空间上增减节点的同时,在时间上对不同的节点设置不同的停止服务时间,达到时间和空间上的缓存优化,可快速且高效地进行人脸识别。类似人脸识别这样的智能技术与传统图书馆服务的结合,也必将为智慧图书馆的建设带来更广阔的发展空间。
