基于梯度提升决策树的病理语音识别
2021-02-28姜子星叶武剑吕友成刘怡俊
姜子星 叶武剑 吕友成 刘怡俊

摘要:病理语音是患者神经系统受损导致发音运动不协调所产生的语音。现有病理语音分析方法大多数采用频域语音特征如梅尔倒谱系数,并且识别模型也大多采用支持向量机模型。因此,提出一种时频特征短时傅里叶变换系数与梯度提升决策树的病理语音识别模型。首先,使用自建的脑卒中构音障碍数据集,提取语音的时频特征短时傅里叶变换系数。随后,结合梯度提升决策树算法进行分类识别。实验结果表明,提出的声学特征能够胜任脑卒中构音障碍识别任务。与梯度提升决策树分类器结合后,音节级别的准确率为68.5%,上升到说话人级别后准确率达到88.2%。
关键词:梯度提升决策树;构音障碍识别;时频特征
中图分类号:TN912.34 文献标识码:A
文章编号:1009-3044(2021)35-0131-03
Pathological Voice Recognition Based on Gradient Boosting Decision Tree
JIANG Zi-xing1, YE Wu-jian1, LV You-cheng2, LIU Yi-jun1
(Guangdong University of Technology, Guangzhou 510006, China; 2.Guangzhou Xinghai Integrated Circuit Center Co., Ltd., Guangzhou 510006, China)
Abstract: Pathological voice is the speech produced by uncoordinated pronunciation and movement caused by damage to the patient's nervous system. Most of the existing pathological voice analysis methods use frequency domain voice features such as Mel cepstrum coefficients, and most of the recognition models use support vector machine models. Therefore, proposed a pathological voice recognition model with time-frequency feature and gradient boosting decision tree. Firstly, using the self-built stroke dysarthria dataset to extract the short-time fourier transform coefficients of the time-frequency features of speech. Subsequently, the classification and recognition are carried out by the gradient boosting decision tree model. The experimental results show that the proposed feature can be competent for the recognition task of stroke dysarthria. After combining with the gradient boosting decision tree classifier, the accuracy rate of the syllable level is 68.5%, and the accuracy rate reaches 88.2% after rising to the speaker level.
Key words: gradient boosting decision tree; dysarthria recognition; time-frequency feature
1 引言
构音障碍是指由于患者中枢神经系统受损导致的发音运动不协调,从而导致患者发音混乱的现象,其严重程度决定于神经肌肉受损的程度[1]。研究调查发现,我国每年脑卒中新发病例超过250万人,已成为主要死亡原因之一[2]。因此能否有效诊断构音障碍对患者的预防及治疗起至关重要作用。
传统的构音障碍诊断方法主要是通过外科手术的方式。传统方法耗时且依赖于临床医生的主观判断,因此,研究人员和从业者一直在努力寻找这些手术的替代方法,基于语音样本的诊断就是其中之一[3]。语音信号的声学分析能够实现语音病理学的非入侵性、经济性、无偏见性和快速评估的优点[4]。
基于机器学习的方法能够快速将患者与正常人进行区分,易于理解和解释。O. Lachhab 利用异方差线性判别分析(HLDA)方法对声矢量进行线性变换,在自建数据库FPSD(French pathological speech database)使用HMM/GMM模型進行评估[5]。Xun对MEEI数据进行RAE优化后,应用GMM-EM模型进行识别,准确率可达98%[6]。Gao等提取Hurst参数、时延、二阶Renyi熵、Shannon熵、关联维数等7维非线性病理语音特征,对病态语音进行定量分析。然后采用高斯混合模型(GMM)和支持向量机(SVM)进行建模,识别率分别为97.22%和97.30%[7]。Fang等将声像信号与病历相结合,构建多模态病理语音识别框架,该框架可提高2.48%-17.31%的准确率[8]。Muhammad等采用MPEG-7音频低层特征,对MEEI数据库中健康人和患者的持续元音,采用支持向量机(SVM)进行10次交叉验证,准确率达到99.994±0.0105%[9]。Gan等对传统声学特征与非线性特征进行比较,并用SVM进行识别,得到非线性特征参数能较好地区分健康和病理性的声音[10]。
时频STFT特征对在表现语音的平稳程度性能较好,能在很大程度上表现出语音的特征。梯度提升决策树作为一种集成学习算法,在处理低维数据效果很好,且泛化能力与预测精度高。因此,本文提出了基于STFT特征,并采用梯度提升决策树算法,将两者应用于脑卒中构音障碍识别中。
2 方法
2.1 STFT特征
短时傅里叶变换(Short-Time Fourier Transform,简称STFT):也称为滑窗式或分时傅里叶变换,是一种简单有效的时频分析方法。其特征系数的实质是加窗的傅里叶变换。在语音信号做傅里叶变换之前乘上一个窗函数h(t),并假定非平稳信号在分析窗的短时间隔内是平稳的,通过窗函数在时间轴上的移动,对信号进行逐段分析,从而得到语音信号的STFT特征。信号x(t)的短时傅里叶变换定义为:
式中,为分析窗函数。
2.2 梯度提升决策树分类器
梯度提升决策树(GBDT)是集成学习算法的一种,其基本思想是采用串行的方式,每一次建立模型是在之前建立模型损失函数的梯度下降方向,即利用了损失函数的负梯度在当前模型的值作为回归问题提升树算法的残差近似值,去拟合一个回归树。损失函数用来评价模型性能,损失函数越小,性能越好。而让损失函数持续下降,其最好的方法就是使损失函数沿着梯度方向下降,其构成方式遵循以下思想:
Boosting思想:先从初始训练集训练出一个基学习器,再根据及学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器。如此重复进行,直至基学习器的数目达到事先指定的值t,最终将这t个基学习器进行加权结合。
通过多轮迭代,每轮在上一轮分类器残差基础上进行训练,最终将每轮得到的分类器加权求和得到最后的总分类器。相比于单个决策树,梯度提升决策树具有更强的泛化能力和表达能力。此外,梯度提升决策树作为分类器时,可以处理非线性数据,且对于低维数据效果很好,预测精度高。文中不限制随机森林的决策树深度,树的数量选择100。
3 数据集与评价标准
3.1 数据集
本文使用自建的脑卒中构音障碍数据集。参与数据收集的人员均为说普通话的成年人,所有参与数据采集的说话人都进行了体格检查、在构音障碍发生之前,所有的病人都可以顺利地用普通话交流,正常人没有任何语音方面的障碍。为了方便后續处理,语音数据以.wav格式进行存储。
语音数据分为A和B两部分。A部分由15位脑卒中构音障碍患者与22位正常人的语音组成,每人录取82段不同的音节发音,部分参与者由于个体差异存在个别语音的缺损。B部分包括后来收集的20名卒中后构音障碍患者,每名患者包含28段不同的音节片段。
3.2 评价标准
在病理语音分析中,正常人无疾病表现为阴性,而患者为阳性。识别模型的输出结果可分为真阳性、真阴性、假阳性和假阴性四种情况。并以准确度(Accuracy)、精密度(Precision)、召回率(Recall)、F1-score作为评价各模型性能的指标。
4 实验结果与分析
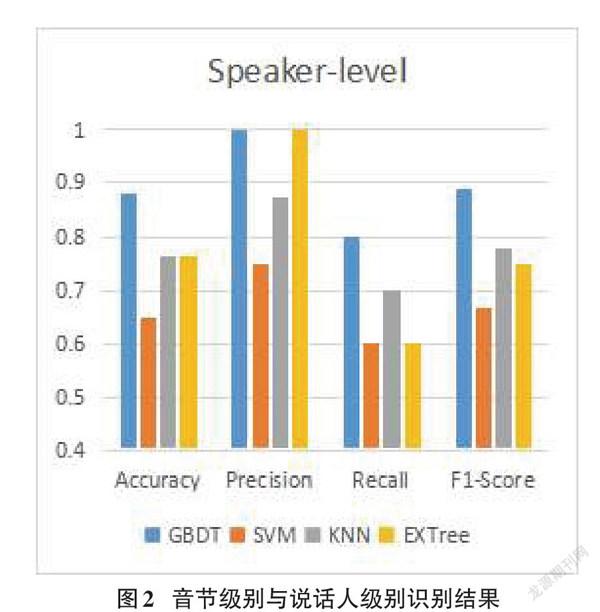
利用Keras APIs在tensorflow平台上搭建了相关网络模型。为了判别已知说话人的任务,所构建的识别模型在音节水平和说话人水平进行验证,通过将表1中的所有音节发音以7:3的比例随机划分为训练集和测试集进行训练,实验结果如图2所示。
图2为GBDT、SVM、极端随机树(EXTree)和KNN的对比分析。从音节级别结果可以看出,STFT特征在GBDT模型中取得了较好的结果,仅有Precision略逊色于SVM与EXTree。从KNN在四种分类模型中分类结果较差,说明我们提取的STFT特征相似性不强。也从侧面说明GBDT能够更好地胜任STFT特征的分类工作。
从说话人实验结果表明,GBDT分类效果远胜于其他三种分类模型。相比音节实验,上升到说话者阶段后,GBDT、KNN与EXTree都取得了较大的提升,说明部分音节识别错误并不会影响整体判断的结果。传统的SVM模型,并不能很好地对病理语音进行识别任务。
5 结论
本文提出了一种基于STFT特征的脑卒中构音障碍预测方法,通过使用专业的录音设备获得脑卒中病人和正常人的特定语音片段;然后对语音信号进行相关预处理,再进行相应的语音特征提取。实验结果表明,STFT特征能够较好地对说话人级别进行识别,但是对于音节级别的识别还有待改善。但本研究仍有不少局限性。
1)数据集较少,可尝试对语音数据进行数据增强,从而扩充语音数据集,减少因数据集稀缺问题带来的影响。
2)对于特征提取而言,还可进一步探讨特征的维度对准确率的影响。
3)针对本文特征而言,可以探讨其他类型的语音特征,从而提升语音特征的全面性。
参考文献:
[1] 李东,张雪英,段淑斐,等.结合语音融合特征和随机森林的构音障碍识别[J].西安电子科技大学学报,2018,45(3):149-155.
[2] 史慧玲,张敏,汪梦月,等.脑卒中后认知障碍病人筛查与管理最佳证据总结[J].护理研究,2021,35(8):1346-1352.
[3] Islam R,Tarique M,Abdel-Raheem E.A survey on signal processing based pathological voice detection techniques[J].IEEE Access,2020,8:66749-66776.
[4] Gidaye G,Nirmal J,Ezzine K,et al.Wavelet sub-band features for voice disorder detection and classification[J].Multimedia Tools and Applications,2020,79(39/40):28499-28523.
[5] Lachhab O,Di Martino J,Ibn Elhaj E H,et al.Improving the recognition of pathological voice using the discriminant HLDA transformation[C]//2014 Third IEEE International Colloquium in Information Science and Technology (CIST).October 20-22,2014,Tetouan,Morocco.IEEE,2014:370-373.
[6] Xun, LU, Yi, CAO, Su-yao., and WANG, Pathological Voice Recognition Research by GMM-EM. Control and Automation Engineering(ECAE 2013) .
[7] Gao J F,Hu W P.Recognition and study of pathological voice based on nonlinear dynamics using Gaussian mixture model/support vector machine[J].Sheng Wu Yi Xue Gong Cheng Xue Za Zhi,2012,29(4):750-753,759.
[8] Fang S H,Wang C T,Chen J Y,et al.Combining acoustic signals and medical records to improve pathological voice classification[J].APSIPA Transactions on Signal and Information Processing,2019,8:e14. DOI:10.1017/atsip.2019.7.
[9] Muhammad G,Melhem M.Voice pathology detection and classification using MPEG-7 audio low-level features[C]//Interspeech 2013.ISCA:ISCA,2013:3627-3631.
[10] Gan D Y,Hu W P,Zhao B X.A comparative study of pathological voice based on traditional acoustic characteristics and nonlinear features[J].Sheng Wu Yi Xue Gong Cheng Xue Za Zhi,2014,31(5):1149-1154.
【通聯编辑:梁书】
