基于Isomap融合朴素贝叶斯分类器的信用预测
2021-02-28许义仿陈晋李林张波司思思
许义仿 陈晋 李林 张波 司思思

摘要:因为金融数据存在海量、高维度、非线性的特点,所以如何选择原始数据中的本质特征关系到分类器的精度。本文提出了一种基于Isomap算法的朴素贝叶斯分类器。该算法的核心本质是对高维大样本的金融数据运用Isomap算法进行降维处理,进而在此基础上运用朴素贝叶斯分类算法进行分类。选取1069家公司的财务指标数据进行实证分析,结果证明该分类器的预测准确率优于朴素贝叶斯分类器。
关键词:Isomap;朴素贝叶斯;信用风险评估
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)35-0125-02
1 引言
信用评估指的是信用评估机构使用专家判断和数学分析方法, 对企业或个人履约各种承诺能力、详细评价其信誉程度, 并用简洁的文字或符号表达出来,进而满足赎回需要的市场行为。
鉴于此,本文在现有的研究基础上针对非线性、高维度的财务数据提出了基于Isomap的朴素贝叶斯(ISOMAP-NB)信用评估模型, 把数据降维当成数据预处理中的一步,简化了朴素贝叶斯分类模型的结构, 并选取了1069家企业的财务指标数据集进行实证研究,结果证明该模型好于朴素贝叶斯分类模型,在企业信用预测方面提高了预测的准确率。
2 ISOMAP-NB模型
2.1 Isomap 算法
Isomap算法是在多维尺度变换(MDS)的根基之上,力图保持数据点的内在几何性质,也就是说保持2点间的测地距离。
Isomap算法步骤如下[1]:
步骤1 算出样本点之间的欧氏距离矩阵, 构建邻域关系图[GV,E],对每个[xi(i=1,2,...,N)]计算其[k]近邻[xi1,xi2,…xik], 记为[Nj], 以点[xi]为定点, 欧氏距离[d(xi,xij)]为边, 建立邻域关系图[GV,E]。
确定近邻点有2种方法:
i) 利用[ε-]近邻法, 如果[xi-xj2≤ε],则点对[xi,xj]可视为近邻点.
ii) 利用[k-]近邻法, 事先给定近邻个数[k], 然后确定近邻点。
步骤 2 计算测地距离[D=(dij)n×n],在近邻关系图[GV,E]中寻找最短路径,即:
[dij=dij∀xj∈Ni or xi∈Nminkdij,dik+dkjotherwise]
步骤3 对距离[D=(dij)N×N]运用古典MDS方法,求出最低维嵌入[Y={y1,y2,...,yN}]。
2.2 朴素贝叶斯分类算法
朴素贝叶斯的分类说明步骤如下[2-4]:
(1) 把每个数据样本数值化,用一个[n]维特征向量[X={x1,x2...xn}]表示样本属性的[n]个度量。
(2) 假定[m]个类[C1,C2,...,Cm]。给定一个待分类的样本[X], 根据贝叶斯定理可得样本[X]的概率为:
[P(Ci|X)=P(X|Ci)P(Ci)P(X)]
(3) 由于[P(X)]对所有类都是常数,即只需[P(X|Ci)P(Ci)]最大。假如类的先验概率不明,则通常情况下这些类是等概率的。即[P(C1)=P(C2)=...P(Cm)],所以只需[P(X|Ci)]为最大。
(4) 为了计算[P(X|Ci)],我们往往做类条件独立的朴素假定. 则:
[P(X|Ci)=k=1nP(Xk|Ci)]
即概率[P(X1|Ci),P(X2|Ci),…P(Xn|Ci)]由训练样本估计,其中:
i) 如果[Ak]是分类属性,则:
[P(Xk|Ci)=SikSi]
其中[Sik]是属性[Ak]上具有[Xk]的类[Ci] 的训练样本数, 而[Si]是[Ci]中的训练样本数;
ii) 假如是连续属性, 则往往假设该属性服从高斯分布。 因而:
[P(Xk|Ci)=g(xk,uci,σci)=12πσcie(x-uci,)22σci2]其中给定类样本的[Ci]的训練样本属性[Ak]的值[g(xk,uci,σci)]是属性[Ak]的高斯密度函数,因而[uci],[σci]分别为平均值和密度差。
(5) 对未知样本[X]分类, 计算[P(X|Ci)P(Ci)],比较[P(X|Ci)P(Ci)]与[P(X|Cj)P(Cj)],如果[P(X|Ci)][P(Ci)>] [P(X|Cj)P(Cj)],则[X]被分到[Ci]类中,反之则分到[Cj]。
3 实证分析
3.1 研究样本的获取
我们利用在沪深交易所上市的1069家企业2015年的财务指标数据(数据均选自新浪财经),并从其中选用了15个财务指标当成关键变量,且这15个指标都是数值型属性变量, 类变量是有两个状态{good, bad}, 相应地将1069家企业划分为两类:good, 代表“具有信用好的条件”的企业和bad表示“不具有信用好的条件”的企业. 并从其中抽取769个样本作为训练集, 剩下300个样本作为测试集。
3.2 指标体系的选择
财务指标指的是企业概括和评价财务状况和经营成果的相对指标。我们往往通过分解和解剖企业的财务指标对企业经济效益的好坏做出准确的评价与推断,用来判定银行是否贷款给这些企业。
经过研究文献[5-7]以及大公国际信用评级的关键财务指标,本文选取了上市公司的15个财务指标。这15个财务指标分为四大类:偿债能力指标(现金比率、流动比率、资产负债率、速动比率)、运营能力(存货周转率、流动资产周转率、应收账款周转率)、盈利能力(净资产收益率、毛利率、净利率、每股主营业收入)、发展能力(股东权益增长率、净资产增长率、总资产增长率、每股收益增长率)。
3.3 构建ISOMAP-NB模型
通过Isomap算法对数据进行降维并将其当成朴素贝叶斯分类算法的前置数据预处理系统。对非线性、高维度的企业财务样本实行降维处理,进而精简了朴素贝叶斯分类模型结构,减少训练时间, 提高分类精度。
融合Isomap数据降维的朴素贝叶斯分类模型架构图如图1所示。
算法描述如下:
(1) 指标体系的建立:从财务数据库中选取描述企业信用级别的指标。
(2) 特征提取:利用Isomap算法减小特征向量的维数。
(3) 建立分类器:利用朴素贝叶斯算法将样本进行分类处理。
3.4 离差标准化处理
依据原始数据显现的特征,如果数据之间存在很大的变异程度, 就考虑实行离差标准化处理[8]。由于本文选取的数据量纲不同且数据的差异很大,故我们对源数据进行离差标准化处理,利用公式[xik=xik-min(xk)Rk]将原始数据变化到(0,1)之间。
3.5 利用Isomap降维
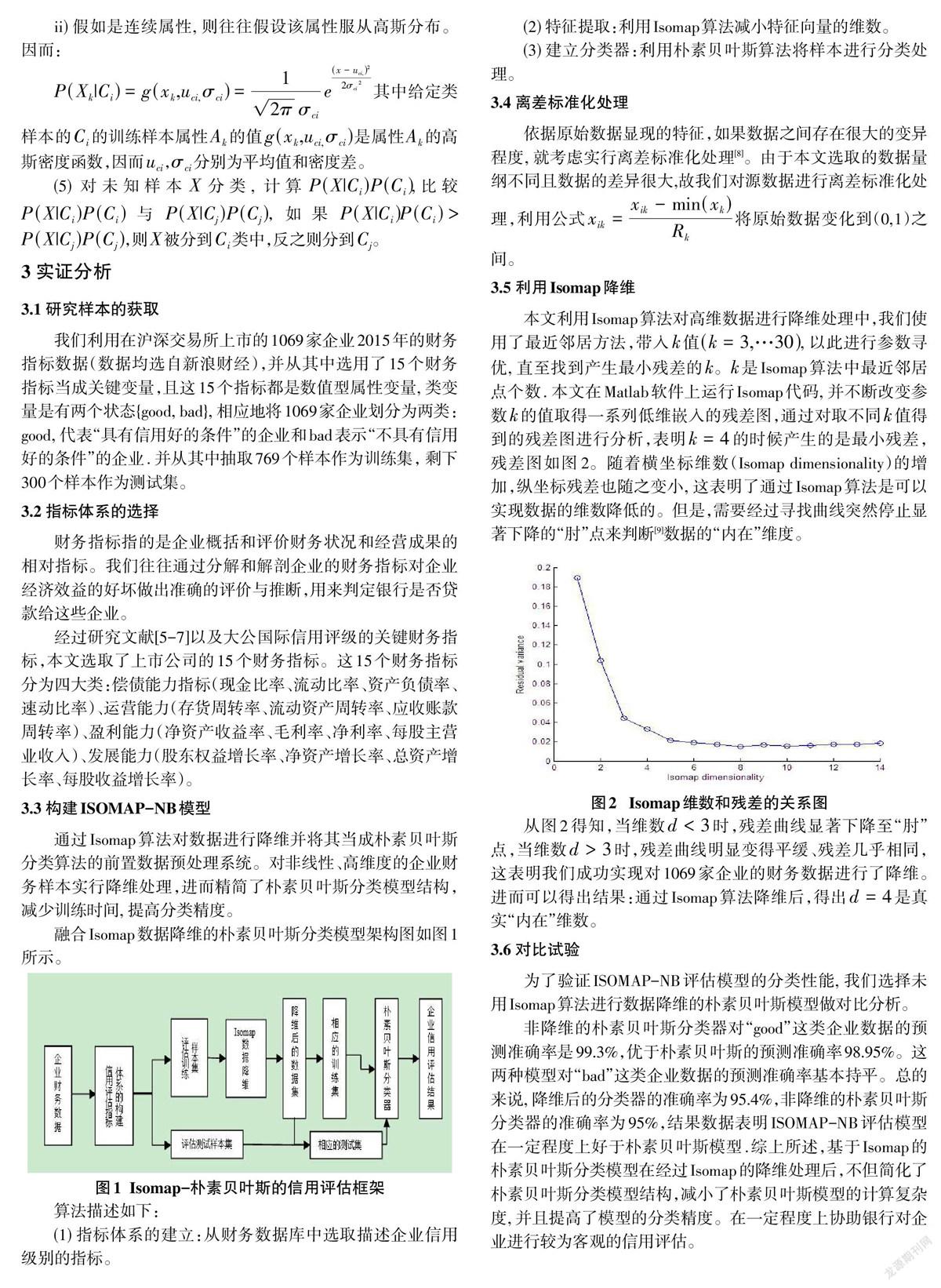
本文利用Isomap算法对高维数据进行降维处理中,我们使用了最近邻居方法,带入[k]值[(k=3,…30)], 以此进行参数寻优, 直至找到产生最小残差的[k]。[k]是Isomap算法中最近邻居点个数. 本文在Matlab软件上运行Isomap代码, 并不断改变参数[k]的值取得一系列低维嵌入的残差图,通过对取不同[k]值得到的残差图进行分析,表明[k=4]的时候产生的是最小残差,残差图如图2。随着横坐标维数(Isomap dimensionality)的增加,纵坐标残差也随之变小, 这表明了通过Isomap算法是可以实现数据的维数降低的。但是,需要经过寻找曲线突然停止显著下降的“肘”点来判断[9]数据的“内在”维度。
从图2得知,当维数[d<3]时,残差曲线显著下降至“肘”点,当维数[d>3]时,残差曲线明显变得平缓、残差几乎相同, 这表明我们成功实现对1069家企业的财务数据进行了降维。进而可以得出结果:通过Isomap算法降维后,得出[d=4]是真实“内在”维数。
3.6 对比试验
为了验证ISOMAP-NB评估模型的分类性能, 我们选择未用Isomap算法进行数据降维的朴素贝叶斯模型做对比分析。
非降维的朴素贝叶斯分类器对“good”这类企业数据的预测准确率是99.3%,优于朴素贝叶斯的预测准确率98.95%。这两种模型对“bad”这类企业数据的预测准确率基本持平。总的来说, 降维后的分类器的准确率为95.4%,非降维的朴素贝叶斯分类器的准确率为95%,结果数据表明ISOMAP-NB评估模型在一定程度上好于朴素贝叶斯模型.综上所述,基于Isomap的朴素贝叶斯分类模型在经过Isomap的降维处理后,不但简化了朴素貝叶斯分类模型结构,减小了朴素贝叶斯模型的计算复杂度, 并且提高了模型的分类精度。在一定程度上协助银行对企业进行较为客观的信用评估。
4 结束语
针对非线性、高维度的大样本财务数据进行分类处理,本文首先应用了Isomap算法做降维处理,将原始数据从15维变量降到了4维变量,然后再利用朴素贝叶斯分类器对降维后的数据做分类处理,构建了基于Isomap的朴素贝叶斯分类模型,并选取2015年1069家企业的财务指标数据进行实验研究,结果显示该分类模型有效地提高了朴素贝叶斯的分类精度。不但把Isomap用在非线性的金融数据上,还可以为银行信用评估创新了一种判断方法。
参考文献:
[1] 段志臣,芮小平,张立媛.基于流形学习的非线性维数约简方法[J].数学的实践与认识,2012,42(8):230-241.
[2] 曹根,葛孝堃,杨丽琴.基于K-近邻法的局部加权朴素贝叶斯分类算法[J].计算机应用与软件,2011,28(9):267-268,291.
[3] 孙程,邢建春,杨启亮,等.基于改进朴素贝叶斯的入侵检测方法[J].微型机与应用,2017,36(1):8-10,14.
[4] 杨光祖,王国军.一种新的朴素贝叶斯属性选择算法[J].科学技术与工程,2009,9(4):978-980.
[5] 赵志冲,迟国泰.基于似然比检验的工业小企业债信评级研究[J].中国管理科学,2017,25(1):45-56.
[6] 迟国泰,张亚京,石宝峰.基于Probit回归的小企业债信评级模型及实证[J].管理科学学报,2016,19(6):136-156.
[7] 刘丽杰.中国企业债券信用评级指标体系研究与创新[J].中国证券期货,2010(9):23.
[8] 王志.基于PCA-NBC算法的股票分类研究[D].兰州:兰州大学,2014.
[9] Tenenbaum J B,de Silva V,Langford J C.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290(5500):2319-2323.
【通联编辑:李雅琪】
