一种用于图像识别的稀疏增强概率协同表示分类算法
2021-02-27邓定胜
邓定胜
(四川民族学院理工学院,四川康定626001)
0 引 言
近年来,随着计算机及人工智能技术的飞速发展,计算机人工智能逐渐通过替代人脑对周围复杂环境进行感知、识别和判断,进而代替人类完成一些常规的反馈行为。其中计算机视觉分析识别技术是其中关键一环,依托于计算机视觉技术的图像识别领域也是目前研究的热点之一,广泛应用于图像处理、自动化控制、信息识别融合等领域[1-2]。人脸识别作为图像识别中最为关键的应用领域已在现代社会中得到广泛的应用。
有研究表明,稀疏表示分类方法(Sparse Representation Classification,SRC)在人脸识别技术领域取得了良好的识别效果[3]。SRC 对人脸面部区域进行稀疏表示,把人脸区域表情动作训练成一组冗余的基础(字典)求解稀疏优化问题,每一个字典代表一个特定的面部表情,基于这个完备字典去做分析并将面部辨识出来[4-6]。为此,学界对SRC 在人脸识别中的应用进行了大量研究,有学者基于稀疏表示进行人脸识别,给出了具有代表性的完整字典,包括了大部分脸型的子空间,可快速甄别不同的人脸,同时采用经典的字典训练方法将分类器的性能进行优化[7-8];也有学者提出可通过稀疏线性组合(Sparse Linear Combination,SLC)将多张训练影像组合成测试影像,该方法除了能有效改善影像对于光源、表情及遮蔽的情况,在分类效果上也优于最近距离法及线性支持向量机[9]。为了进一步证明SRC 在训练特征充足的情况下可以任意将脸部数据组成测试影像,有研究者将识别系统设计成每一类以数十张影像去涵盖所有可能的光源变化,且大部分稀疏表示分类的相关研究也是基于此假设下的实验设置进行比较,但对于测试样本少的环境,SRC 仍具有一定局限[10]。因此,有学者提出了协同表示分类算法(Collaborative Representation Classification,CRC)用以针对样本较少情况的人脸图形识别[11]。
本研究将SRC 联合CRC,并通过概率协同子空间,提出稀疏增强概率CRC。所谓稀疏增强即利用稀疏表示系数来增强概率系统表示分类算法的表示系数,进而解决测试样本少、图像遮挡及像素污染情况下的图像识别问题,提高人脸识别的鲁棒性,并应用于机器学习中。
1 稀疏增强概率CRC的构建
1.1 稀疏表示分类算法
SRC是将一个信号样本表达为字典元素中的一组线性组合的技术[12],

式中:X为信号样本;D 为字典;A 为在字典D 上信号样本X 的线性组合,且A 为稀疏性,即其中的非零项只有几个或个数远大于为零的项数。在许多图像处理或对象分类研究中已证明稀疏表示用于信号样本重构相当有效。
1.1.1 字典初始化
在字典学习训练中,有学者提出K-SVD 算法,每个信号找出一个完备字典D 使得X≈DA 成立。X 为一个n维度特征向量空间中的N个输入信号,表达式如下[13]:

在K-SVD 中通过固定第K 项迭代运算解算式(1)的问题:

式中:D = [d1,d2,…,dK]∈Rn×K是学习训练出的字典;A = [a1,a2,…,aN]∈RK×N为输入信号X在稀疏表示中的线性组合;T 为非零系数的期望数即稀疏程度式(3)可等价表示为

式中:ε是字典学习时的可容忍误差。
1.1.2 字典学习
在求解式(3)的等价问题上,有学者使用正交匹配追踪算法(Orthogonal Matching Pursuit,OMP)。OMP是一种贪婪式算法,在每次迭代过程中使用贪婪迭代的方法可以减少重建中的错误。每次迭代时,OMP 从字典中选出一个最相似的基础向量,通过该向量投影后计算出新的余差值用来更新字典,根据已知信号X与字典D计算出最佳的稀疏表示α,即[14]:

K-SVD算法以两阶段来学习过完备字典:①为稀疏编码阶段。固定字典,用任一种追踪算法来求解;②更新字典和稀疏系数阶段。K-SVD的迭代流程如图1所示。

图1 K-SVD算法迭代流程图
初始字典可由过完备基础向量集或观测数据本身的原子获得。基于初始字典D,通过OMP 算法用式(3)将每个αi优化,并允许每项系数向量拥有不超过T个非零系数元素来固定字典D。接着利用OMP 算法求出稀疏表示A 与已知输入信号X 更新字典D 中每列dk的值,另外为稀疏表示A中的第k行,非零值的表示输入信号X与dk间的线性组合关系。因此,式(1)可改写成[15]:

式中:

dk和更新值可以通过求解式(6)得到:
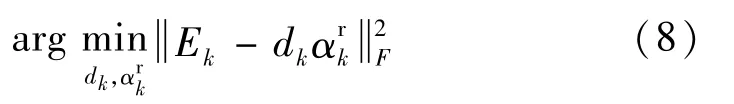
K-SVD算法使用奇异值分解(SVD)将Ek进行矩阵奇异值分解,寻找进而更新dk。
1.2 CRC
为了解决SRC中字典不全等问题,有学者提出了CRC,并与概率子空间进行结合,将SRC 中的约束条件进行替换,得到如下的目标函数[16]:
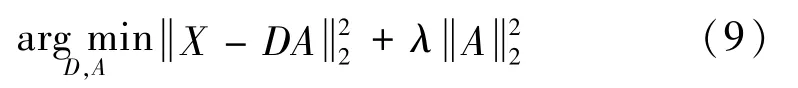
式中:λ为概率协同系数。
相比SRC,概率CRC 具有字典数量少、计算速度快以及识别率准确等优点。
1.3 稀疏增强的概率CRC
本研究在概率CRC的基础上,使用稀疏表示系数来增强概率协同表示系数的稀疏性,此时的目标函数:

式中:前两项表示协同表示项;第3 项表示稀疏增强项;γ为平衡参数。
1.4 算法流程
针对本研究的算法流程,首先计算出表示系数,即利用K-SVD和OMP 算法得到表示系数,特别是稀疏表示系数γ,随后根据字典学习对测试样本重新分类,具体流程如下所示:① 给出训练样本矩阵X、字典D,以及在字典D上信号样本X 的线性组合A。② 通过式(8)和(9)求得λ 及γ。③ 对目标函数进行最优化求解,更新字典,从而获得图像的标准特征标签。
2 实验设计
针对本研究建立的人脸辨识算法,需要测量标准评估算法,人脸图像数据库能够提供在不同环境变化下的人脸信息,通过光源、表情、年龄等脸部的变化,建立起一个复杂的人脸辨识系统。完整的数据库会提供标准的测试流程,对于样本可定义为三部分:训练组(Train Set)代表提供系统用来训练特征空间;注册组(Target Set)使系统定义对象类别;测试组(Query Set)用来评估系统效能。本研究选择FERET、Multi-PIE、FRGC 3 个常见的国外人脸数据库评估人脸识别算法的性能,三者在实验测试上都有包含光源变化、表情。通过以上3 个数据库来考虑本研究的人脸识别算法在不同光源条件下的效果,同时与传统的稀疏表示算法进行对比,表1 为3 个数据库的基本参数。
将数据库的原始图像缩放成30 ×30 大小,组成900 像素的图像矢量。同时随机选择4 幅表情不同的图像作为训练样本,其余为测试样本。试验重复10次,分别记录识别准确率及标准差。算法设置的参数如下:SRC设置的误差限为小于0.05,CRC 的正则化参数设置为0.001,K-SVD 和OMP 的稀疏度设为20,字典的个数设置为50 个。另外,将本算法和稀疏增强协同表示分类算法(SA-CRC)的稀疏度设置为40,同时误差限小于0.02。

表1 3 个国外常见的人脸数据库基本参数
3 试验结果与分析
3.1 FERET人脸数据库上的实验结果
FERET人脸数据库是由美国军方FERET 项目创建,所采用的样本是3 年间分15 个时间点收集的1 199 个人,影像张数为641 126,数据库的测试样张如图2 所示。在本研究中将本算法与其他6 种算法的识别率和标准误差结果进行对比,如表2 所示。为描述结果方便,用算法的英文简写代替。
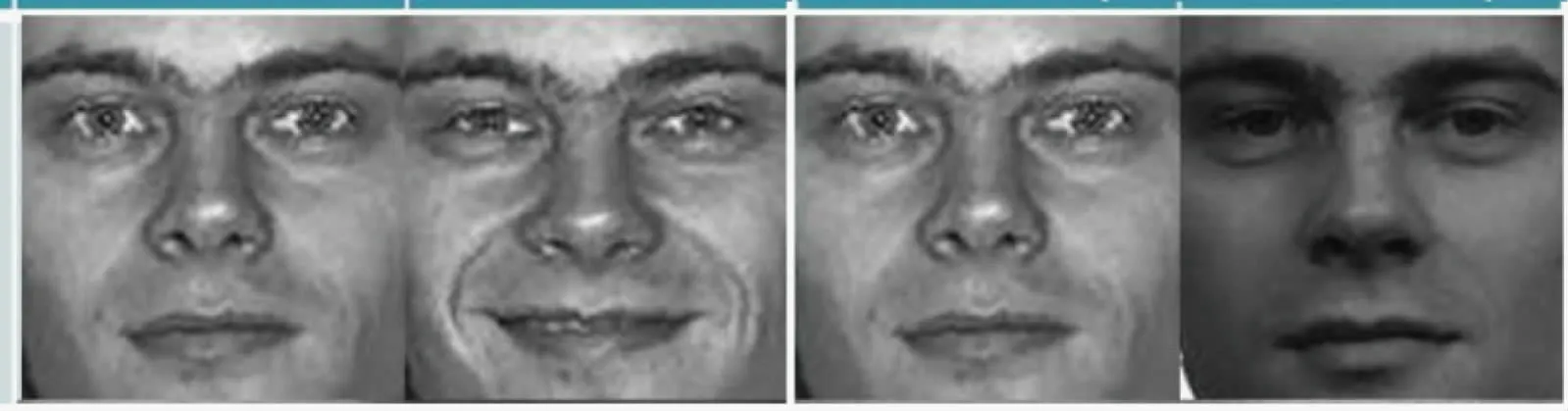
图2 FERET数据库测试样张

表2 FERET人脸数据库中各算法对比结果分析
从表2 可以看出,本研究算法的识别准确率最高,相比最低的OMP 识别率提升了近10%,与经典的CRC与SRC算法相比,识别准确率也有不同程度的提升,验证了本算法在FERET人脸数据库中识别的准确性及有效性。
3.2 Multi-PIE人脸数据库上的实验结果
CMU Multi-PIE人脸数据库最早由美国卡耐基梅隆大学创建,注册人数达337 人,不同于FERET 数据库,其考虑多种角度、表情、光源变化,每个人有15 种角度变化及19 种光源条件,纪录时间分为4 个Sessions,每个Session 的被拍摄人不相同,且拍摄者也有不同表情设定,测试样张如图3 所示。同时将本算法与其他6 种算法的识别率和标准误差结果进行对比,如表3 所示。

图3 Multi-PIE数据库测试样张

表3 Multi-PIE数据库测试分析结果
从表3 可以看出,本研究算法的识别准确率超过95%,识别精度最高;最低的仍为OMP算法,识别准确率不到90%。相比经典的CRC 与SRC 算法,本研究算法的准确率提升显著,这与算法中加入稀疏增强系数直接相关。因此,本算法在Multi-PIE人脸数据库中识别的准确性及有效性都有显著提高。
3.3 FRGC人脸数据库上的实验结果
FRGC人脸数据库收集来自美国诺特丹大学(University of Notro Dame),数据库的拍摄共分为4 个session,其中接受拍摄者的对象参加其中1 ~4 个session不等,每个学期中会挑数个时间点进行拍摄。FRGC与Multi-PIE人脸数据库的相同之处在于FRGC的拍摄环境是通过环绕摄影机进行瞬间拍摄,所以每个人在影像中的姿势均是固定的,且光源变化也都一致。同时,在光源变化下FRGC 也较贴近一般日常生活情况,故对于人脸辨识来说具有一定挑战性。FRGC人脸数据库的测试样张如图4 所示,将本算法与其他6 中算法在FRGC 人脸数据库中进行测试对比,结果如表4 所示。

图4 FRGC人脸数据库上的测试样张

表4 FRGC人脸数据库的测试分析结果
从表4 可以看出,本研究算法的识别准确率超过其他6 种算法,识别准确率相比传统的SRC与CRC算法均提升显著,同时由于FRGC 人脸数据库的辨识难度性高于前面两种,因此,整体算法的识别准确率有所下降,但本研究算法的准确率仍然接近94%,再次验证了本算法的准确性。
4 结 语
由于SRC能够有效改善影像对于光源、表情及遮蔽的情况,因此在图像识别特别是人脸识别技术领域中得到了广泛应用。本研究基于SRC 将概率协同表示分类算法与SRC结合,并利用稀疏表示系数增强概率系统表示分类算法的表示系数,进而提高算法的识别准确率及有效性。通过FERET、Multi-PIE 与FRGC人脸数据库实验测试结果对比可以看到,本研究提出的稀疏增强概率协同表示分类算法能够显著提升人脸识别的准确率,相比其他传统分类算法的识别准确率均有一定程度提升。可见,本研究算法在不同的人脸识别情景中具有广泛应用价值。
