基于持久化内存的索引设计重新思考与优化
2021-02-07韩书楷熊子威蒋德钧
韩书楷 熊子威 蒋德钧 熊 劲
(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)(中国科学院大学 北京 100049)(hanshukai@ict.ac.cn)
非易失性内存(non-volatile memory, NVM)是近几年来出现的一类存储介质的统称,例如:PCM[1],ReRAM[2],STT-RAM[3]等.一方面,这些存储介质同DRAM(dynamic RAM)一样有着低访问延迟、可字节寻址的特性;另一方面,与DRAM不同的是,它们具有非易失性、较低的能耗和较高的存储密度.这使得基于NVM技术的非易失性内存有着更大的单片存储容量,同时能够作为存储设备保存数据.若利用基于非易失性内存构建存储系统,一方面,相对于传统基于内存的存储系统而言,可以受益于非易失性内存的非易失、大容量、低能耗特点[4];另一方面,相对于传统基于磁盘的存储系统而言,可以受益于更低的访问延迟以及更细粒度寻址方式.因此,NVM技术有望被大规模的应用在存储系统的研发与构建中,成为存储系统进一步发展的新机遇.
键值存储系统是数据中心中一类重要的基础性存储设施,例如内存键值存储系统Memcached[5],Redis[6]和磁盘键值存储系统LevelDB[7],RocksDB[8]等.无论是内存键值存储系统还是磁盘键值存储系统,索引结构都是这些存储系统中非常重要的基础技术,一直以来便是存储领域的热点研究问题.在之前的研究工作中,索引结构大多构建在DRAM中.随着低访问延迟、可字节寻址、可持久化数据的NVM的出现,这使得基于NVM构建持久化的高性能索引成为可能.近年来,很多面向NVM的索引研究工作[9-16]认为NVM有着同DRAM近似的读延迟以及高于DRAM数倍的写延迟的特性.因此,大部分研究工作提出通过降低NVM写开销从而构建不同的高效持久化索引.这些工作基本可以分成2类:一类是针对单一索引结构的设计优化.例如:Level Hashing[10]是面向NVM设计的Hash索引,它使用2层的Hash表结构以降低表拓展时搬运的数据总量.NV-Tree[12]是针对B+树索引的优化,它不对同一叶子节点内的数据进行排序,从而减少了插入数据时的写开销,此外NV-Tree还将内部节点放在DRAM以降低树分裂时对NVM的写开销.另一类是面向DRAM-NVM混合内存结构的混合索引,例如,HiKV[15]是基于DRAM-NVM构建的混合索引键值存储系统,它对同一份数据同时维护Hash表和B+树2种索引去保证高效的读性能,为了HiKV将写开销较低的Hash表放在的NVM而将写开销较高的B+树放在DRAM中,从而降低对NVM写负担.
从2009年开始,NVM便被计算机系统领域广泛研究.然而,研究早期NVM技术还未成熟,尚未有成熟的NVM设备可供使用,上述大部分研究工作都是基于对非易失性内存器件的性能假设并使用模拟器进行实验评测[4-5].2019年4月,英特尔公司正式发布了基于3D-XPoint技术[17]的NVM硬件产品apache pass(AEP)[18],这为研究人员基于真实的NVM硬件进行研究提供了基础.目前,已有一些针对真实NVM硬件的评测工作显示,现有的NVM硬件有着接近DRAM的写延迟以及高于其数倍的读延迟.而之前研究工作所采用了如下性能假设:1)NVM有着同DRAM近似的读延迟,2)NVM有着高于DRAM数倍的写延迟.这些假设和现有真实NVM硬件性能评测结果并不完全相符.这使得我们需要重新审视之前基于NVM性能假设的索引研究工作,并基于实际的NVM硬件特性开展有效的优化工作.
本文的主要贡献有3个方面:
1) 对最新的AEP硬件进行了评测,我们评测了AEP硬件的不同访问线程、不同访问粒度下的读写延迟、带宽,以及读写混合下AEP的性能变化趋势.
2) 基于真实AEP硬件评测结果,我们分别重新审视了之前研究工作并针对混合索引结构和单一索引结构进行了优化.针对混合索引结构,本文基于AEP硬件真实性能,重点关注索引放置的优化.本文探索了不同索引放置方式对混合索引结构的影响,当面临读密集的负载时,通过将主索引放置在DRAM,辅助索引放置在AEP上,从而可以有效提升索引的读性能.本文针对不同应用场景,提出索引放置相应的设计原则考虑.我们针对混合索引(HybridIndex)提出了读优化的改善方案Hybrid-Index+,该方案下HybridIndex最多可提升80%的读性能.
3) 针对单一索引结构,本文基于AEP读延迟较高的特性,提出基于DRAM的异步缓存方法,将位于NVM中持久化索引通过高速Hash索引的方式缓存在DRAM中,从而获得高效的访问性能.此外,本文还针对FP-Tree[13]、FAST-FAIR[11]和持久化跳表[14]实现了异步缓存,评测结果显示经过我们的优化,最多可以降低持久化索引20%~50%的读延迟.
1 非易失性内存简介
在实际的NVM硬件投放市场之前,学界对持久化内存的访存特性具有一些基本假设,比如:NVM有着数倍于DRAM的写延迟及相近的读延迟.该假设是否成立尚需物理器件的验证.此外,非易失性内存的具体特性尚处于未知,如访问粒度对延迟带宽的影响、多线程对延迟带宽的影响、混合访存对延迟带宽的影响等.对AEP进行详细的测试可以为我们揭示一类非易失性内存的物理特性,为研究者和开发者在后续基于非易失性内存的工作中提供参考,也可为系统工作者构建包含非易失性内存的新型存储系统提供参考.本节主要介绍了非易失性内存的特性,并对当今最新的NVM硬件在各个维度进行了详细的评测.
1.1 非易失性内存技术
NVM与传统DRAM一样,可以被挂载在CPU地址总线上按字节进行寻址.如表1所示,目前已有多种可用于生产持久化内存的存储介质.这些介质有着接近DRAM的纳秒级读写延迟以及更高的集成密度.此外,相比DRAM需要频繁的刷新去记录数据,非易失性内存介质不需要频繁的刷新去保证数据的有效性,这使其能耗相比DRAM更低.

Table 1 Comparison of the Properties of Different Storage Media[19]
需要注意的是,表1仅为不同存储介质的性能对比而非实际的存储硬件性能.NVM设备的复杂性要求我们进行细致的评测和分析以获得硬件的实际性能和详细特性.
1.2 Apache Pass
英特尔公司在2019年4月公布了第1代基于3D-XPoint技术[17]的商用持久化内存硬件AEP[18],当前发布的AEP分别为128GB256GB512GB容量.这标志着持久化内存正式进入了实际可用的阶段.
2 AEP硬件性能评测
目前存在着如MLC(memory latency checker)[20]等内存检查的工具,但这些工具的高度定制化和闭源特性不符合我们对AEP进行细粒度测试的需求,因此我们编写了一系列测试代码(1)已开源:https://github.com/KinderRiven/AEP_TEST,这些测试代码主要完成对AEP硬件的延迟、带宽等基本性能的评测,探索AEP的物理特性,以揭示其带宽延迟特性,最佳访问模式等信息,为后续设计工作在AEP上的系统提供指导.
2.1 测试环境和方法
AEP有着接近传统易失性内存的访问延迟,此外还有着传统持久化设备的持久化特性,因此它在传统存储层次架构中可以担任不同的角色.一方面作为内存而言,它可以作为DRAM的下层大容量存储介质;另一方面作为可持久化设备,它可以作为存储层中的高速上层存储介质,位于传统的高速SSD之上.
基于这2种使用方法,AEP提供了Memory Mode和App Direct Mode这2种配置使用方法[21].若采用Memory Mode进行配置,AEP将被当作大块内存而非持久化存储设备使用,因此对应用程序不可见;如果采用App Direct Mode进行配置,AEP则被当作一块持久化设备使用,可以被应用程序直接看到并访问.需要注意的是.由于我们的研究工作主要将AEP作为高性能且持久化的存储设备而使用,因此本文所进行的评测都基于Direct Mode进行配置和使用,该模式可以有效反映AEP作为有效存储设备的性能.而对于Memory Mode模式下的性能评测,我们暂时没有进行.
表2展示了进行评测的物理环境.对于每组评测,我们均进行5次评测并在每组波动不超过5%的基础上取平均值.另外,为了避免CPU预取对测试结果造成影响,我们在测试中关闭了CPU预取.
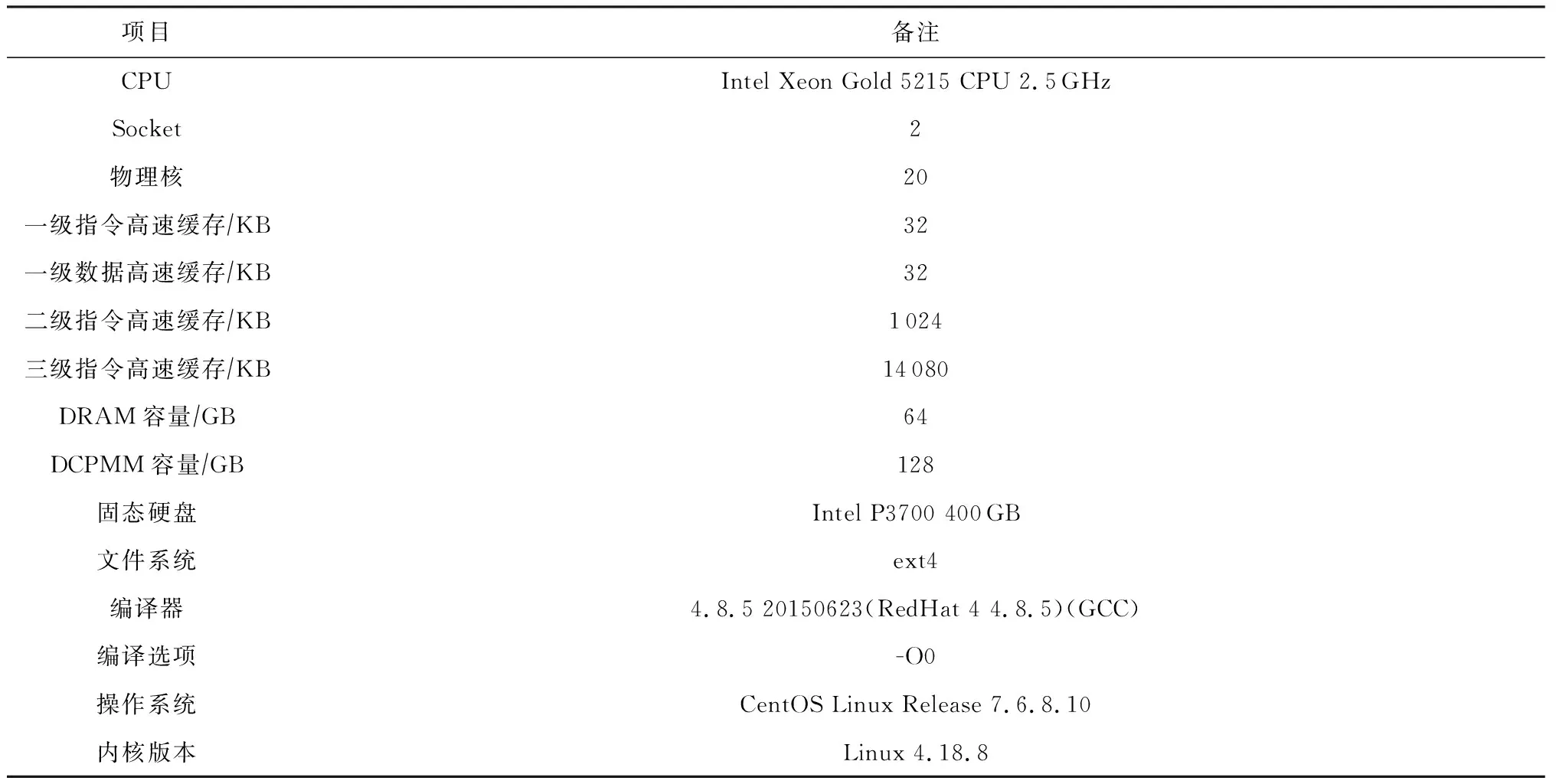
Table 2 Experimental Environment
2.2 测试结果
2.2.1 延迟
表3展示了使用单线程对AEP进行小粒度随机和顺序读写时的延迟对比情况.可以看到,小于256 B的随机读延迟基本接近256 B的随机读延迟,这是由于AEP的访问粒度为256 B.当访问粒度小于256 B时,顺序读相比随机读延迟要低很多,这是由于AEP的内部存在缓存机制,使得对同一访问单元(256 B大小的物理块)进行连续访问时的性能得到提升.
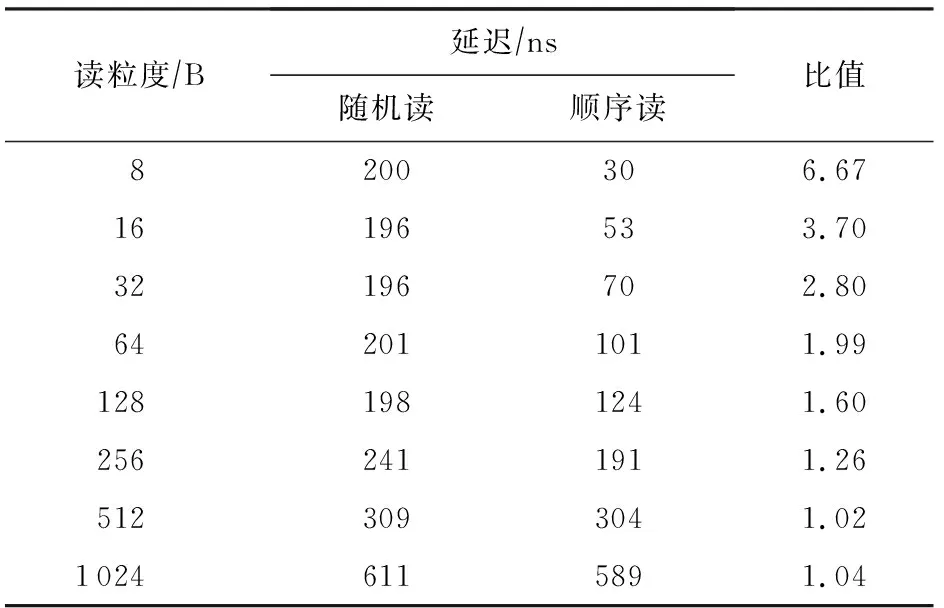
Table 3 Comparison of Random and Sequential Read Latency of Small Access Granularity for AEP
表4展示了使用单线程对AEP进行大粒度随机和顺序读时的延迟对比情况.可以看到,AEP的随机和顺序读延迟基本一样,结合表3来看,在不考虑访问小粒度数据时内部缓存机制的影响,AEP的随机和顺序读延迟基本一样.
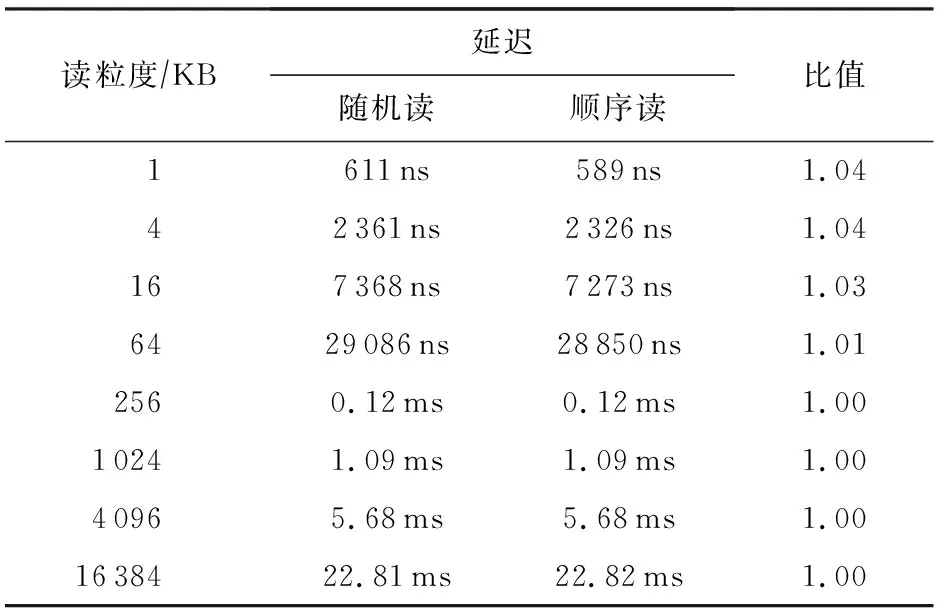
Table 4 Comparison of Random and Sequential Read Latency of Large Access Granularity for AEP
表5和表6展示使用单线程对不同粒度数据进行随机和顺序写的延迟对比,可以看到,不论在大小粒度下,AEP的随机和顺序写延迟都是一样的.同读访问一样,AEP有着较好的随机访问特性.需要注意的是,在进行小于64 B数据的访问时,出现了延迟上升的情况,这主要是由于我们使用了NTStore指令进行写操作,该类指令可以不经CPU cache而将数据直接写入内中,而NTStore指令在处理小于64 B的数据时存在延迟升高的问题.
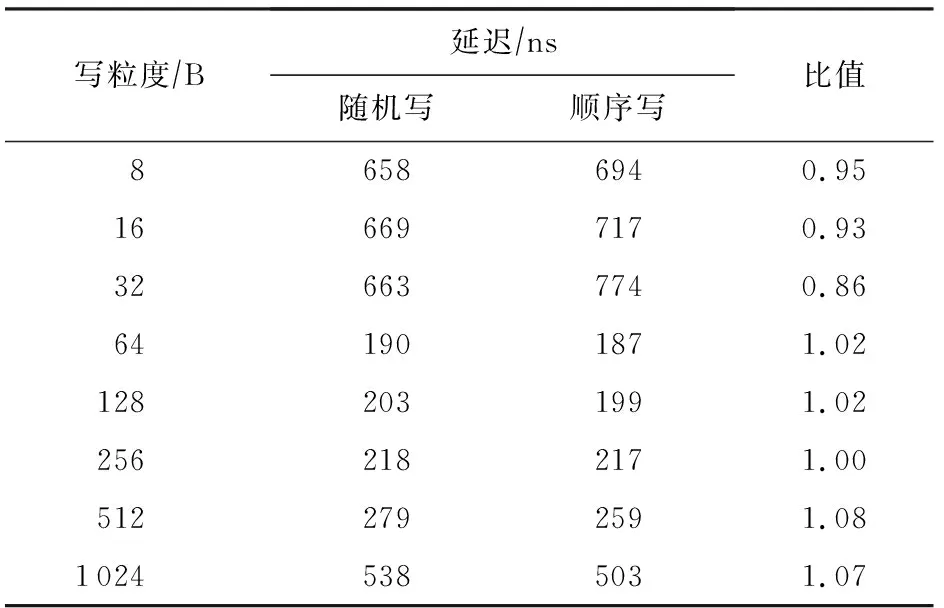
Table 5 Comparison of Random and Sequential Write Latency of Small Access Granularity for AEP
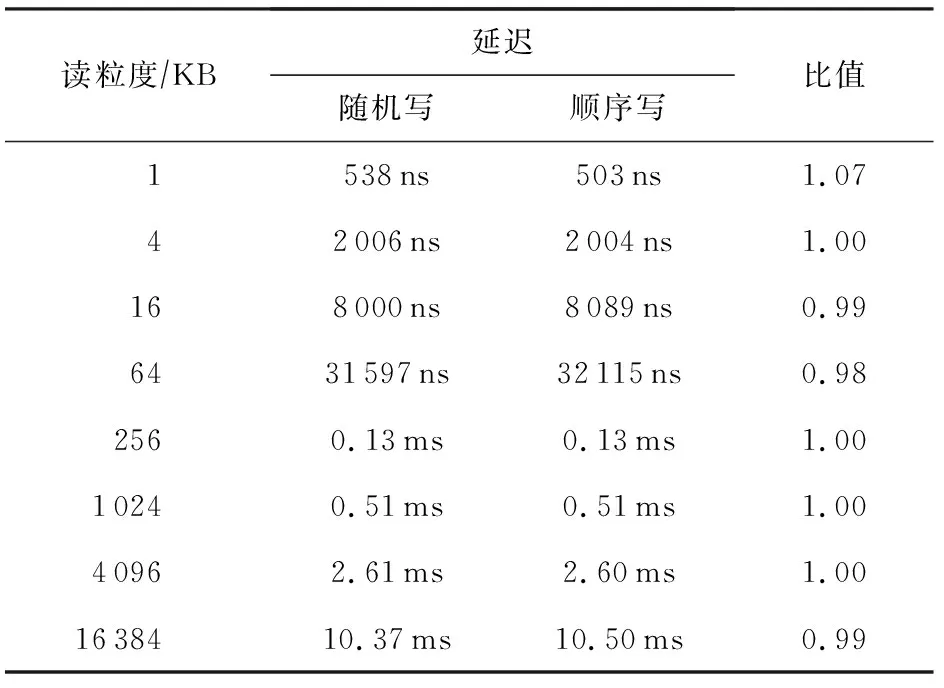
Table 6 Comparison of Random and Sequential Write Latency of Large Access Granularity for AEP
综上所述,AEP有着良好的随机访问特性,最佳访问粒度为256 B.在处理1 KB及以下的数据时,AEP可以保证纳秒级别的访问延迟.
图1为AEP的在不同线程、不同粒度随机读延迟变化趋势图.

Fig. 1 Trend of random read latency of AEP over access granularity图1 AEP的随机读延迟随访问粒度增加的变化趋势
我们注意到,在256 B以内的随机读延迟并不显著受到线程数的影响.但可以看出线程数的增加导致了延迟的升高,这个趋势在读粒度较大、延迟较高的情况下更为明显.在顺序读的测试中,AEP也具有相似的趋势,读粒度小于256 B时延迟受线程数影响较小,且读延迟随线程数增加而升高.总结如下:
1) 多线程写操作会导致AEP读延迟的升高;
2) 为了维持较低的读延迟,小于等于256 B的读粒度是较优的读粒度.
图2是AEP的随机写延迟变化趋势图.与读延迟类似的是,写粒度小于256 B时AEP维持较低的延迟,且对线程数的增加更为敏感.且当写延迟在访问粒度接近256 B时取得最小值.总结如下:
1) 多线程读操作会导致AEP写延迟的急剧升高;
2) 接近256 B的写粒度是较优的写粒度;
3) 从延迟的角度来看,读写的最佳粒度是256 B,且访问线程数不应太多.

Fig. 2 Trend of random write latency of AEP over access granularity图2 AEP的随机写延迟随访问粒度增加的变化趋势

Fig. 3 Trend of random read bandwidth of AEP over access granularity图3 AEP随机读带宽随访问粒度增加变化趋势
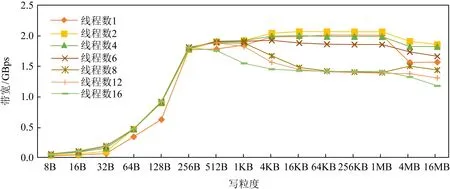
Fig. 4 Trend of random write bandwidth of AEP over access granularity图4 AEP随机写带宽随访问粒度增加变化趋势
2.2.2 带宽
图3和图4展示了多线程下不同粒度下随机读写带宽变化情况,可以看出,AEP最大读带宽为7 GBps左右,最大写带宽为2 GBps.且在多线程下,256 B的访问粒度下读写带宽基本可以达到最大带宽上限.这主要是由于AEP的访问粒度为256 B所导致的,小于256 B的访问会造成读写放大从而降低有效带宽.
此外,我们从图3和图4中发现,若访问粒度超过一定阈值,AEP的读写带宽反而出现了下降.这是由于对于读带宽,cache的频繁替换造成了性能的损失.而对于写带宽,我们认为是CPU乱序导致写操作被拆分为64 B粒度,由于AEP写带宽较低并受256 B写粒度的影响,当数据被拆分成64 B的随机写后乱序写回,这造成了数据的写放大从而引起带宽下降.为了验证我们的判断,将一个数据块写回时,每隔256 B添加一次内存屏障(sfence),确保数据的有序写回.如图5所示,添加内存屏障后AEP的写带宽没有出现下降的情况.
图6和图7展示了多线程下不同粒度下顺序读写带宽变化情况.可以看出,相比随机访问需要在256 B达到最大读写带宽,顺序访问在64 B的访问粒度时即可达到最大读写带宽.对于读操作而言,这是由于AEP内部的缓存机制使得小于256 B的顺序访问可以有效命中缓存,从而降低读放大减少带宽浪费;对于写而言,这主要是由于AEP内部会对连续地址的请求进行合并,这使得AEP在顺序写入64 B的数据时能够将其合并成一个256 B单位的数据写入硬件中,从而避免了写放大问题.此外,我们依然可以看出,在大粒度的顺序访问时读写带宽依然出现了退化的情况.
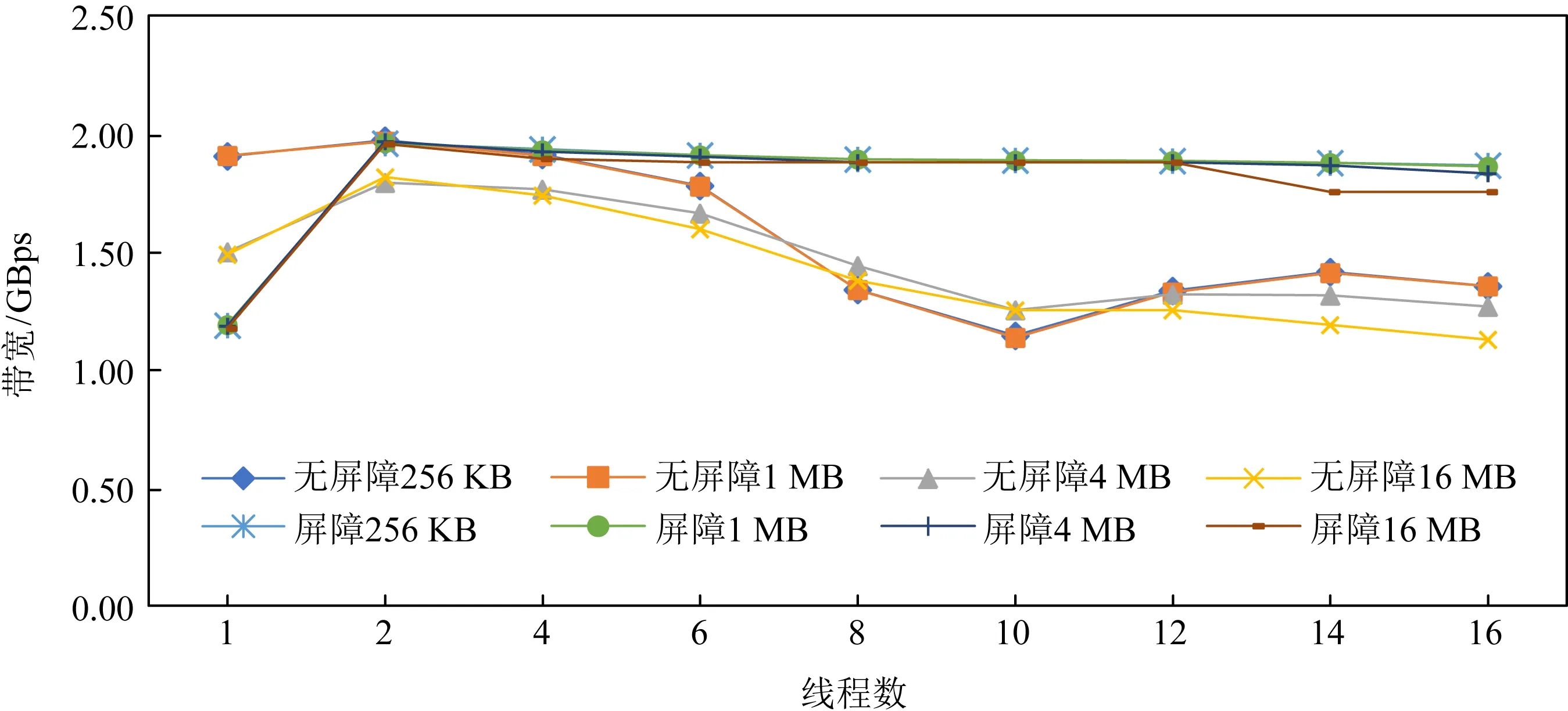
Fig. 5 Impact of using memory barriers on write bandwidth degradation图5 内存屏障对写带宽退化的影响
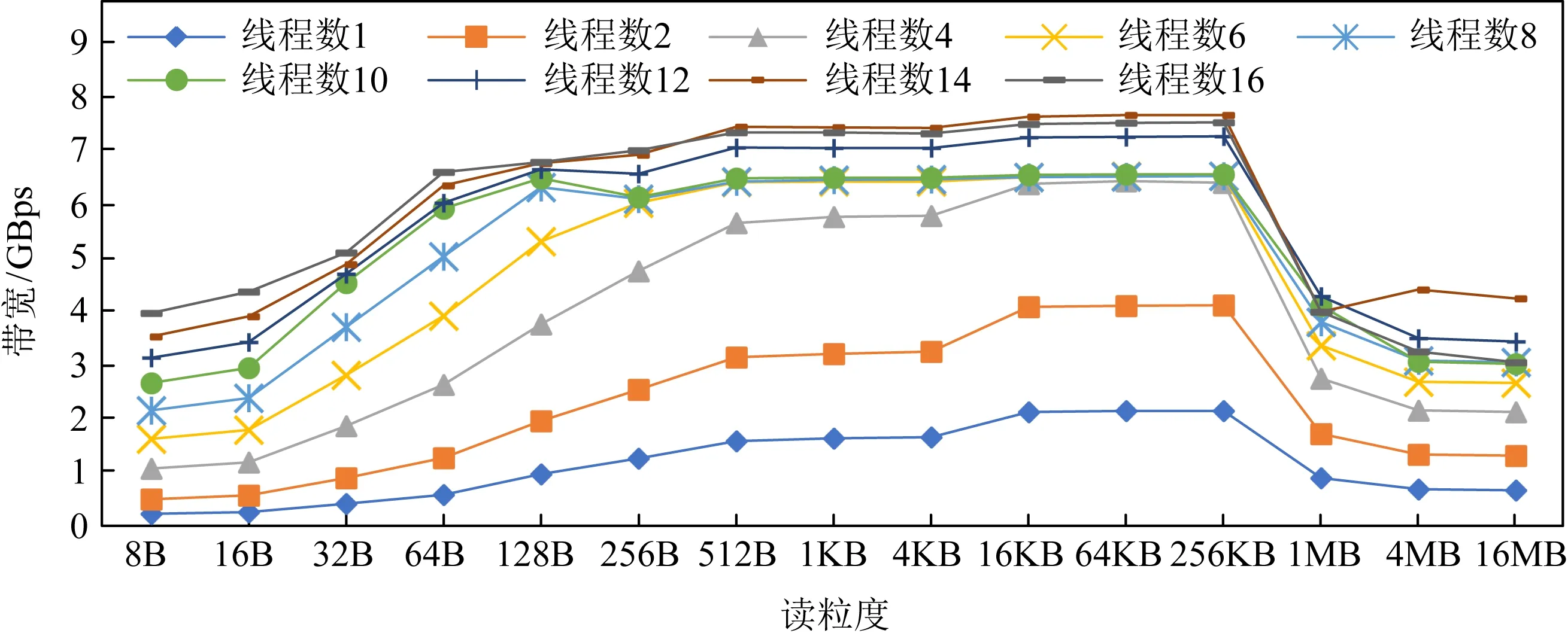
Fig. 6 Trend of sequential read bandwidth of AEP over access granularity图6 AEP顺序读带宽随访问粒度增加变化趋势
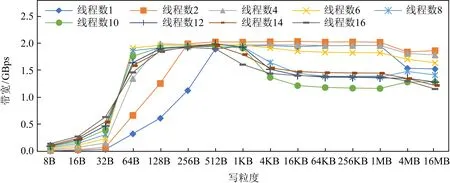
Fig. 7 Trend of sequential write bandwidth of AEP over access granularity图7 AEP顺序写带宽随访问粒度增加变化趋势
经过评测有如下结论:
1) 当AEP进行大粒度数据访问时,会出现带宽退化的现象,对于读带宽的带宽,可以利用内存屏障进行写序控制从而防止退化.
2) AEP更加适合处理小粒度数据,考虑到其访问粒度为256 B,因此处理更小粒度的数据时可能会造成读写放大,从而浪费带宽.
3) 尽管受制于256 B的访问粒度,但AEP内部仍存在某些顺序访问的优化机制.
2.2.3 与DRAM和SSD的比较
在延迟方面,与DRAM的读延迟对比如表7所示,写延迟对比如表8所示.
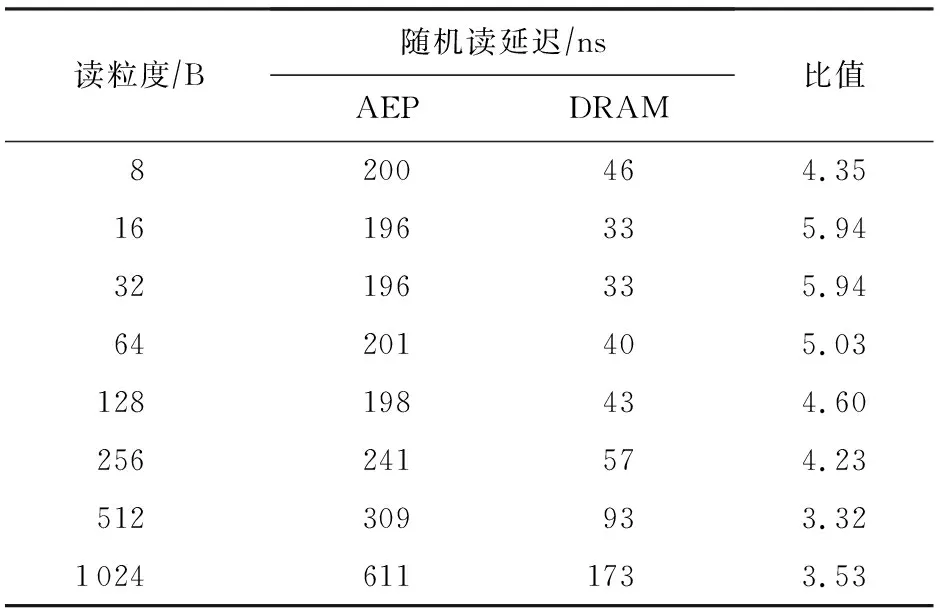
Table 7 Latencies of AEP and DRAM Random Read with Single Thread for Small Access Granularity
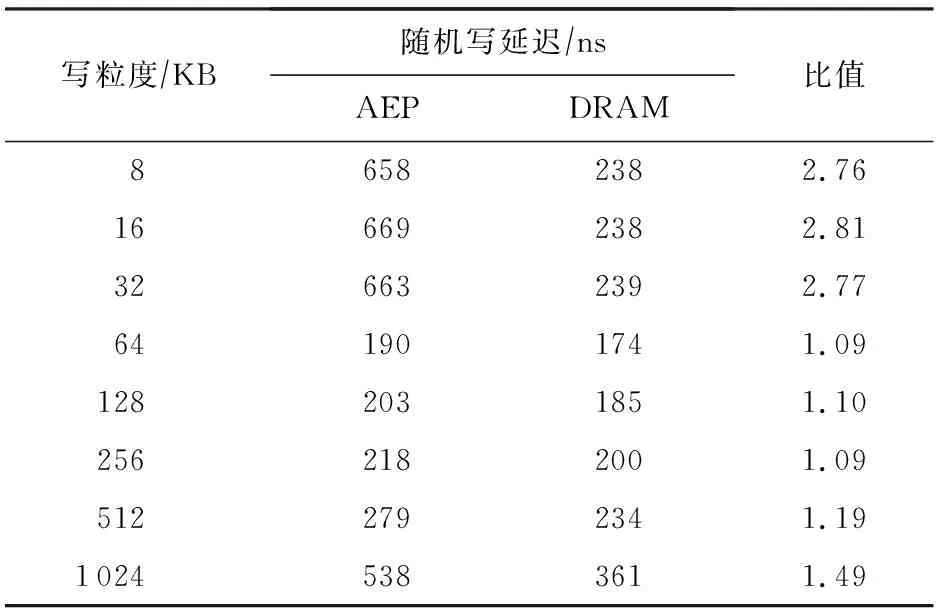
Table 8 Latencies of AEP and DRAM Random Write with Single Thread for Small Access Granularity
从表7~8中可以看出,读延迟上AEP为DRAM的4~5倍,之前关于“NVM比DRAM有着更高的写延迟和一样的读延迟”的假设与实际器件是不符合的.而写延迟,DRAM和AEP都表现出了非对称的写延迟,但AEP的写延迟在写粒度接近256 B时与DRAM相差不大.因此对非易失性内存的假设应当修正为:对于采用与AEP相似技术的NVM,其整体具有比DRAM更高的读延迟以及与DRAM相近的写延迟.此外,在带宽方面,DRAM具有高达10 GBps以上的读写带宽,而AEP读带宽为7 GBps,写带宽仅2 GBps.因此AEP目前还不具备完全代替DRAM的潜力.
尽管表现逊色于DRAM,AEP的性能远远优于目前已有的SSD产品.我们使用fio测试了传统NVMe SSD的性能,可以发现系统内SSD的峰值读带宽为870 MBps,远远低于AEP.尽管目前已有较高端的SSD产品达到了2 GBps的读带宽,但对比AEP高达7 GBps的读带宽,仍旧显得逊色.而写带宽上系统内SSD的峰值写带宽仅680 MBps,也远低于AEP高达2 GBps的带宽.因此我们有如下观察:
1) AEP在256 B访问下具有较优异的读写带宽和延迟表现;
2) AEP并不是一个高并发友好的器件,访问AEP的线程数应控制在较低的数量;
3) AEP目前暂不具备完全代替DRAM的潜力;
4) AEP的性能表现远远好于SSD,在现有的存储层次中,可作为DRAM于SSD甚至HDD之间的新层级.
如2.2.2节所述,访问粒度和线程数对AEP的性能表现存在较大影响,接下来将分别说明粒度和线程数对AEP性能表现的具体影响.
2.2.4 访问粒度的影响
2.2.2节已粗略展示了随着访问粒度的升高,AEP出现带宽下降、延迟升高的性能退化问题,本节将以单线程的结果,更详细分析访问粒度对AEP性能的影响.由于带宽的下降是有限的,因此本节不讨论AEP带宽的变化.
从图8和图9中可以看出,尽管较小粒度(小于512 B)时AEP展现了百纳秒级别的优秀表现,但当访问粒度上升至KB级别,AEP延迟开始上升到了微秒级别,而如果采用MB基本的访问,AEP的延迟飙升至毫秒级别,逼近了SSD的延迟.随机写具有类似的现象.因此可见,AEP是一个小粒度友好的设备,在设计工作在AEP上的系统时,应当尽量避免过大粒度的访问.
2.2.5 访问线程数的影响
本节同样聚焦于线程数对随机读延迟的影响.如图10所示,在小粒度的情况下(小于256 B),AEP的延迟上升不明显.线程数从1增加15倍到16之后,延迟并未上升15倍,而仅升高了2倍左右.但在大粒度的情况下,延迟基本随线程数线性增长.这进一步说明在并发的情景下,AEP也仍然是一个小粒度访问友好的设备.较小的访问粒度可以避免高并发下延迟陡增的情况.随机写也具有类似的现象.

Fig. 8 The impact caused by small access granularity to the read latency of AEP with single thread图8 单线程下小粒度访问对AEP随机读延迟的影响
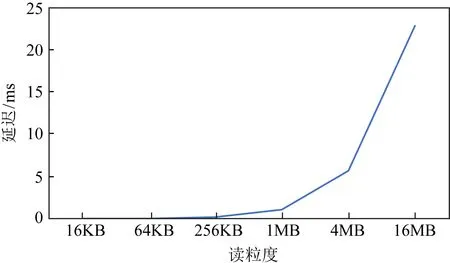
Fig.9 The impact caused by large access granularity to the read latency of AEP with single thread图9 单线程下大粒度访问对AEP随机读延迟的影响
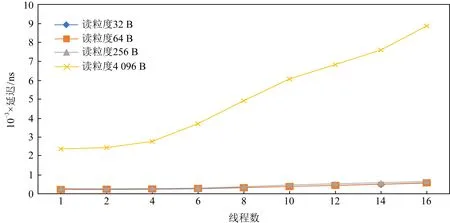
Fig. 10 The impact caused by number of thread to the read latency of AEP图10 不同线程数对AEP读延迟的影响
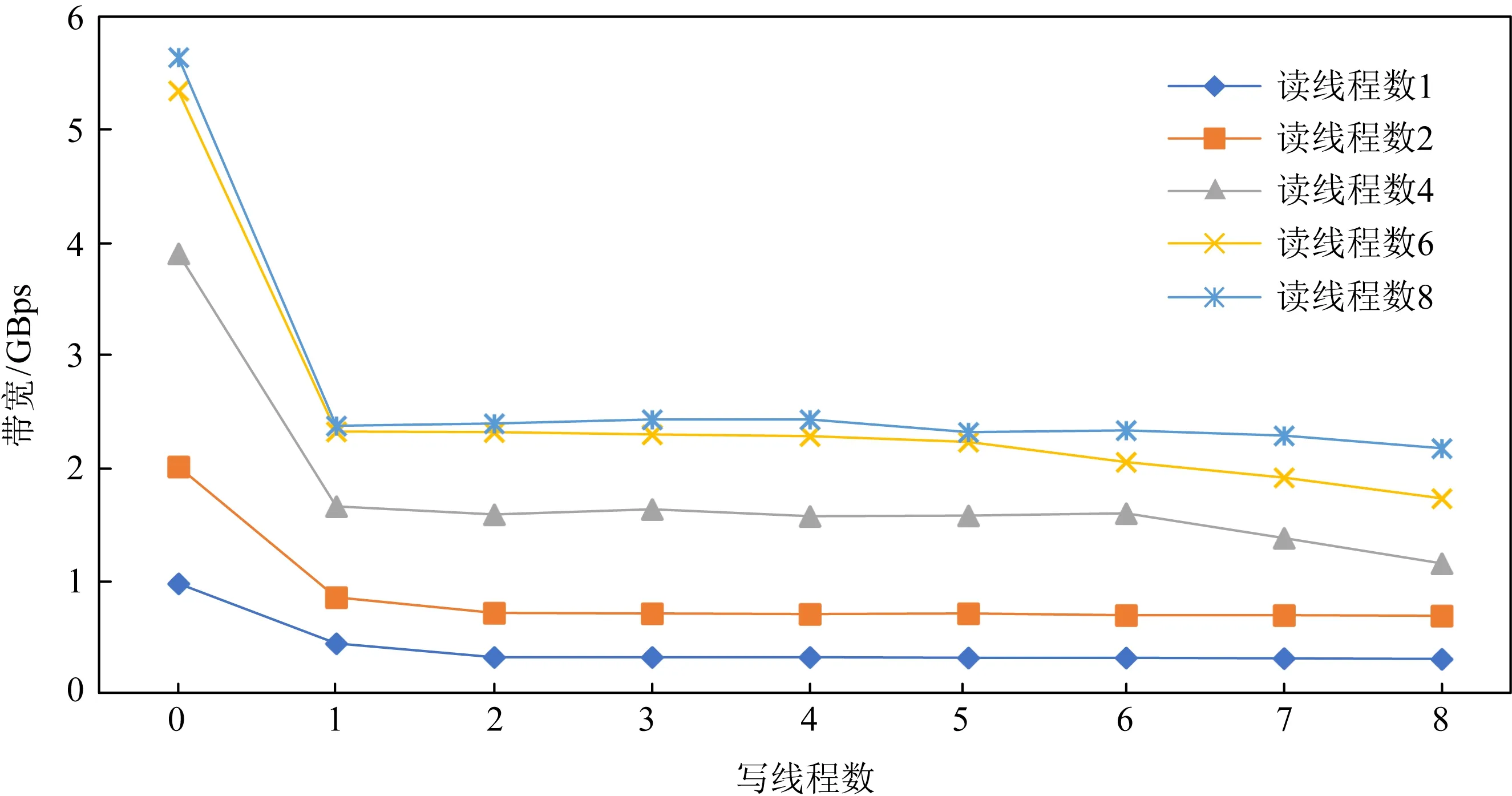
Fig. 11 Read bandwidth variation of AEP under mixed read-write at granularity 256 B图11 256 B粒度混合读写下的AEP读带宽变化情况
2.2.6 混合读写的影响
我们评测了读写混合下AEP硬件带宽和延迟的变化趋势,如图11所示.我们注意到若固定读线程数,一旦出现写线程,则读取带宽出现急剧下降的情况,但这种下降不是无限制的,随着写线程的不断增加,读带宽下降变得不再明显.这表明AEP内部存在一定的读保护机制,阻止读带宽受到写带宽的过度影响.如图12所示,反之若固定写线程,增加读线程数,写带宽也同样出现下降的情况,但最终也逐渐趋于平缓不再下降,.综上表现来看,AEP内部对于读写带宽的控制存在一定的“保底”,从而避免了高并发情况下出现读写带宽不平衡的情况.
在延迟方面,AEP也呈现出类似的趋势,从图13和图14中可以看出,AEP内部的读保护机制也阻止了读写延迟受线程影响也发生过大的升高,保证了读写延迟稳定在1 μs左右.
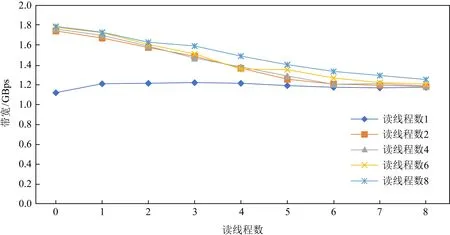
Fig. 12 Write bandwidth variation of AEP under mixed read-write at granularity 256 B图12 256 B粒度混合读写下的AEP写带宽变化情况
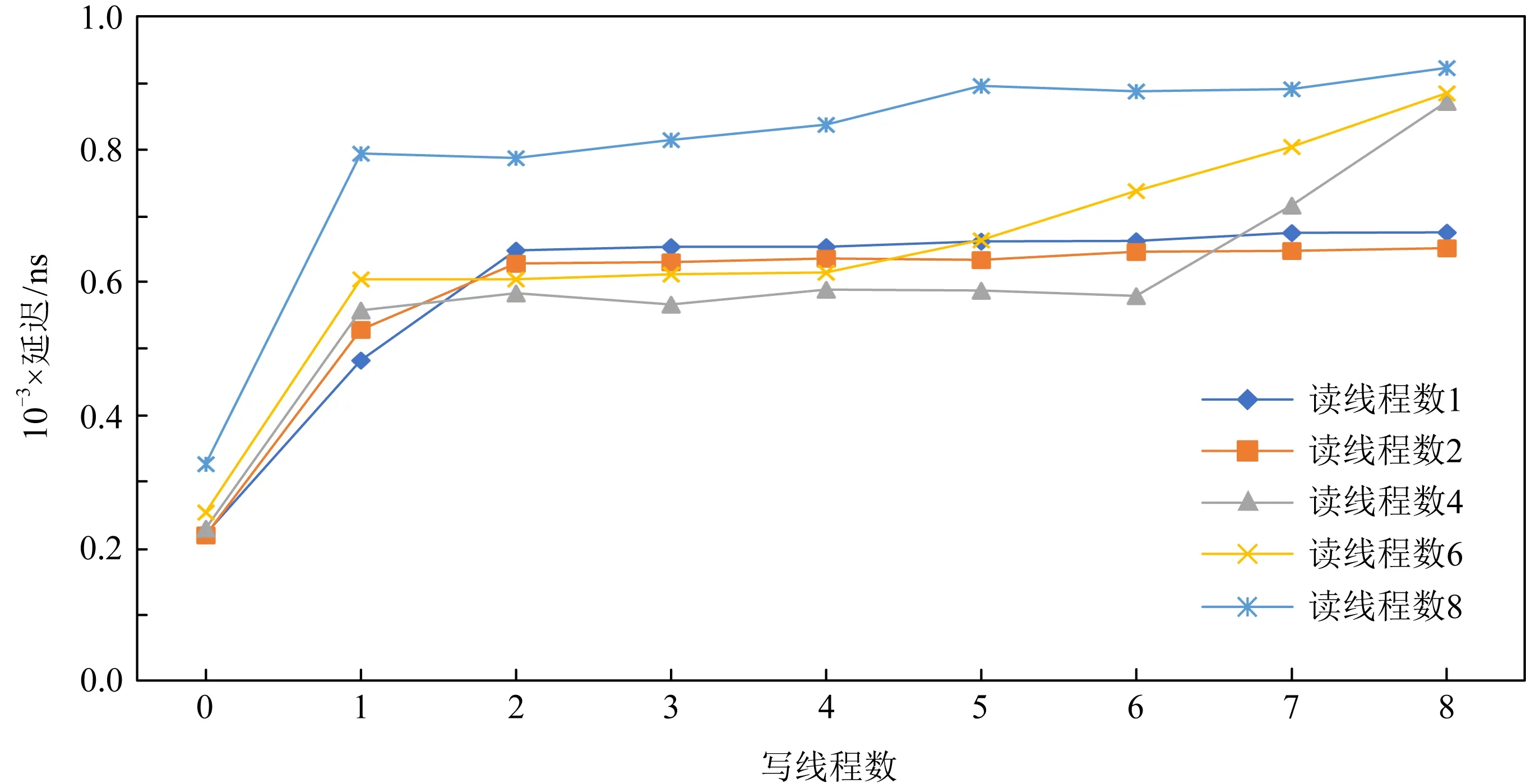
Fig. 13 Read latency variation of AEP under mixed read-write at granularity 256 B图13 256 B粒度混合读写下AEP读延迟的变化情况
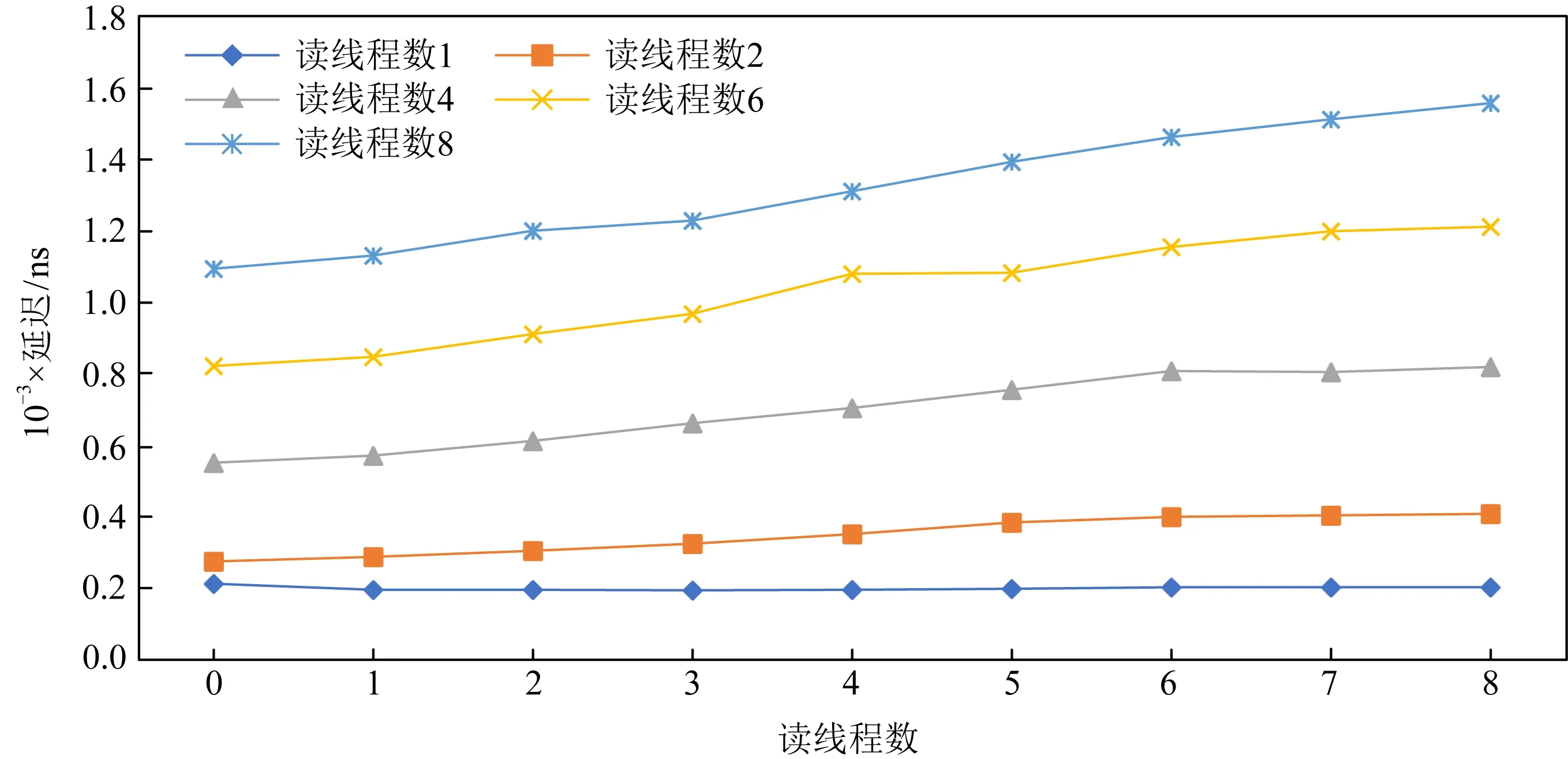
Fig. 14 Write latency variation of AEP under mixed read-write at granularity 256 B图14 256 B粒度混合读写下的AEP写延迟变化情况
2.3 评测总结
针对AEP的评测可总结出以下的结论:
1) AEP访问粒度为256 B,其内部存在缓存机制,从而可对于小粒度的顺序访问进行优化.但对小粒度的随机访问该优化通常不奏效,因而对AEP的小粒度随机访问会造成读写放大问题.在进行大粒度数据访问时,AEP存在带宽退化的问题且性能较差.综上所述,AEP更加适合用于存储小粒度的数据,特别是256 B到4 KB之间大小的数据.
2) 在带宽方面,AEP读写带宽较低且不平衡.AEP的读带宽大约为7 GBps,仅为DRAM的13左右;而写带宽更低约为2 GBps,仅为DRAM的16左右.
3) 在延迟方面,AEP顺序随机访问性能持平,作为一种随机存储设备是合格的.它的写延迟接近DRAM,而读延迟为DRAM的3~5倍.
4) 相比其较低的带宽,AEP的延迟显得更为优秀.因而AEP更适合作为低延迟的响应设备,用于存储对延迟需求较高且需要持久化的数据,比如索引、日志等重要的元数据.此外,同之前工作主要聚焦于NVM高写延迟上不同的是,经评测由于AEP的读延迟高于DRAM,面向AEP的设计更应该关注高读延迟所带来的问题并进行优化.
3 基于非易失性内存的索引设计
近几年来,关于如何使用NVM一直是存储系统领域的热点研究问题.一方面,NVM有着接近易失性内存的纳秒级访问延迟,以及可字节寻址的特性;另一方面,NVM相比易失性内存有着更大的容量以及非易失性的特性,此外尽管NVM有着较低的访问延迟,但受制于介质特性,其拥有的带宽相比DRAM而言并不高.因此有很多工作考虑在NVM中构建高效的持久化索引[9-16].
然而,在过去几年里由于NVM硬件尚未商业化,很多工作都是基于模拟环境进行;此外,过去的针对NVM性能的假设也存在一些偏差,比如过去的很多模拟器大多模拟NVM比易失性内存写延迟高5倍,而读延迟同易失性内存一样,这同我们对AEP实际硬件的评测结果并不一致.因此,上述原因使得过去的很多工作的设计和评测存在一些局限性.
在本节,我们针对实际的AEP硬件重新优化并评测了过去针对NVM模拟器进行设计的索引,通过2个实例分析证明我们工作的有效性.
3.1 案例分析:面向混合索引的性能优化
混合索引键值存储系统(hybrid index key-value store, HiKV)[15]是面向混合内存架构的一种高性能键值存储系统.由于不支持范围查询的Hash索引的查询复杂度为O(1),而B+树等支持范围查询的数据结构查询复杂度为O(logn),因此,该系统中提出了面向DRAM-NVM混合内存架构的混合索引(HybridIndex)机制.具体而言,HybridIndex采用Hash表和B+树组成的混合索引机制来支持高效的查询.
如图15所示,HybridIndex对同一份数据维护2个索引,HybridIndex使用Hash索引进行单点查询,使用B+树进行范围查询.为了保证索引的持久化,HybridIndex将Hash索引放在NVM而将B+树索引放在易失性内存,宕机之后根据NVM中的持久化Hash索引重建易失性内存中的B+树.此外,为了降低写延迟,HybridIndex只对NVM中的Hash索引进行持久化更新,这种设计主要是针对当时NVM普遍被认为写延迟高于DRAM而读延迟和DRAM近似的情况,而随着实际的NVM硬件出现,这种设计不再合理.经过实际评测,NVM的写延迟同易失性内存近似,而NVM的读延迟会比易失性内存高3倍.因此,受制于NVM的高读延迟,这使得置于NVM的Hash索引无法提供高效的单点查询.由于在很多实际负载中的查询操作大部分为单点查询,且查询操作在很多负载中为主要的负载占比,因此主要面向查询优化而设计的HybridIndex无法再提供高效的系统吞吐量.
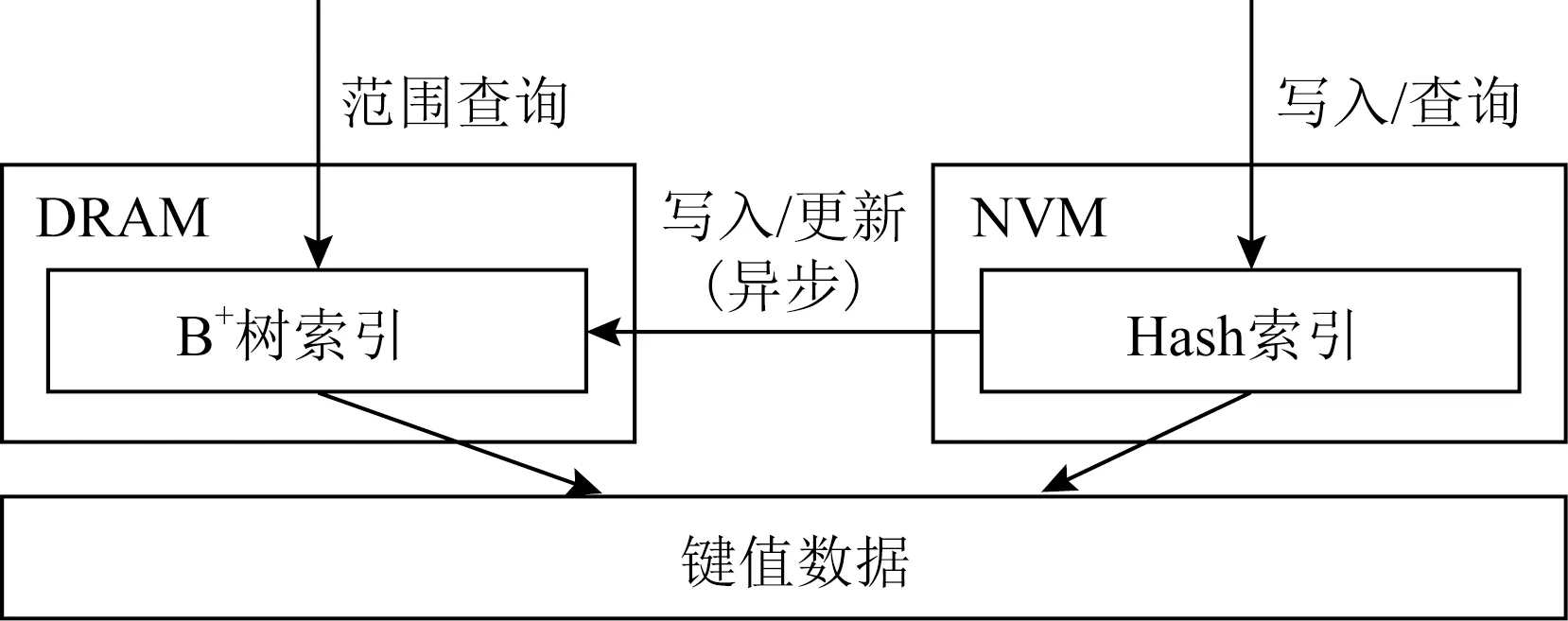
Fig. 15 HybridIndex system architecture图15 HybridIndex系统架构
本文对HybridIndex面向实际的NVM硬件进行了优化并提出了HybridIndex+.如图16所示,HybridIndex+对换了Hash索引和B+树索引的位置,将Hash索引放在了易失性内存,将B+树索引放在了NVM,并采用同步更新的方法同时更新2个索引.HybridIndex+采用了FAST-FAIR[11]作为持久化B+树,在进行宕机恢复时,可以瞬间恢复B+树,之后异步地重建DRAM中的Hash索引.HybridIndex+的设计优势为:1)将Hash索引放在读延迟更低的易失性内存有利于降低读开销,而B+树由于只提供范围查询服务,因此在查询B+树通常会查询整个叶子节点,可以有效地利用NVM较大读粒度的特点,不会造成读放大问题;2)在进行宕机恢复时,HybridIndex+在恢复完B+树后,HybridIndex+便可以正常提供服务,而易失性内存中Hash索引的恢复会放在后台异步进行.在这个过程中,B+树即可提供单点查询又可提供范围查询,当Hash索引恢复完成后,Hash索引便可提供更高效的单点查询服务.相比HybridIndex需要等待B+树全部恢复完成才可提供完整的查询服务,HybridIndex+有着更低的宕机恢复时间.

Fig. 16 HybridIndex+ system architecture图16 HybridIndex+系统架构
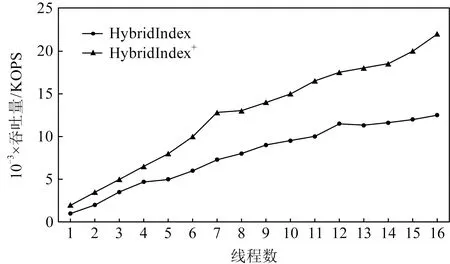
Fig. 17 Read performance comparison of HybridIndex and HybridIndex+图17 HybridIndex和HybridIndex+读性能对比
评测结果如图17所示,经过优化后,Hybrid-Index+的读性能最多可提升至HybridIndex的1.8倍.但是由于采用了同步更新方法,HybridIndex+的写性能相比HybridIndex降低了30%.此外,由于HybridIndex+大部分读发生在DRAM中,而HybridIndex的读均发生在NVM中,由于NVM的读带宽相比DRAM较差,因此随着线程的不断增加,HybridIndex的性能与HybridIndex+的性能差距逐渐增大.
讨论:在上述评测中,HybridIndex+考虑采用同步方式修改Hash表,这是因为若采用异步方式修改,可能存在查询Hash表时该更新还在异步队列中,这使得该查询需要等待队列中的更新完成后才能得到有效的数据,这将增加读请求的延迟.因此,对于写占比较大的负载场景,更加适合使用HybridIndex来降低写延迟,而对于读倾斜较高的负载场景,使用HybridIndex+能获得更低的读取延迟.此外,也可以根据实时的负载压力动态调节混合索引的同步异步更新方式.比如,可以在写负载较高而读负载较低时采用异步写的方法去降低写延迟,而当读负载较高写负载较低时可以采用同步写的方式去降低读延迟.
3.2 案例分析:基于持久化内存的异步缓存方法
在过去的几年里,很多研究普遍认为NVM的写延迟较高的问题[9-16],很多工作针对NVM设计了各种写优化索引,它们大多针对NVM设计了精细的数据结构从而减少了在索引持久化过程中的写开销.这些优化在现在看来依然是有效的,但过去的工作大多没有针对NVM硬件高读延迟的问题进行优化,因此,我们提出了一种基于持久化索引的异步缓存方法(asynchronous cache scheme, ACS)去优化现有持久化索引.
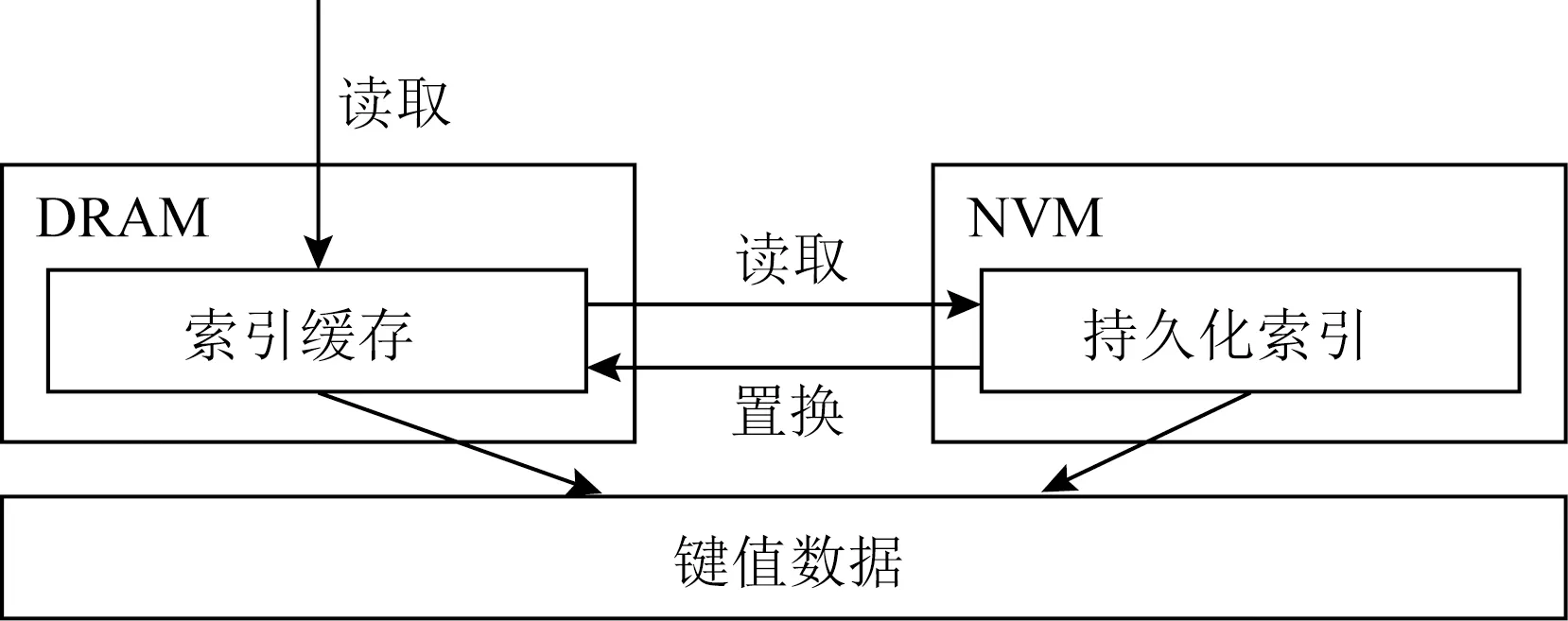
Fig. 18 Asynchronous cache scheme based on NVM图18 基于持久化内存的异步缓存方法
ACS的设计思路是在不改变现有的持久化工作基础上,在易失性内存中缓存部分索引去提高NVM中索引的读性能.如图18所示,ACS在易失性内存中维护了一个Hash索引去提供高效的单点查询.当进行一次查询时,首先需要搜索易失性内存中的Hash表,若该查询命中,则返回结果;若该查询未命中,则继续搜索NVM中的持久化索引,若命中持久化索引则返回结果,并将该索引异步更新到易失性内存中的读缓存中.需要注意的是,易失性内存中的Hash索引仅仅是NVM中索引的部分缓存,用户可以根据自身需求配置其大小,当它可缓存的索引项饱和从而无法再进行写入时,根据替换策略替换其中的索引项,在我们的实现中采用了LRU算法.此外,为了保证易失性内存和NVM中索引的同步,对于更新删除操作,ACS采用了同步更新策略,对易失性内存和NVM同时存在的索引项进行同步更新,从而避免了数据不一致性的问题.
为了验证有效性,我们使用该方法对一些过去的持久化索引的研究工作进行了优化.在这里我们选择了基于B+树实现的持久化索引FAST-FAIR[11]、FP-Tree[13]以及持久化跳表[14]作为优化对象.FAST-FAIR是在FAST会议上发表的基于B+树的持久化索引工作,它利用FAST(failure-atomic shift) 和 FAIR(failure-atomic in-place reba-lance)算法去实现索引的持久化并保证高性能.FP-Tree也是基于B+树的持久化索引工作,为了降低B+树分裂时的写开销,FP-Tree只将叶子节点保存在NVM并将内部节点保存在DRAM,为了降低数据插入叶子节点的开销,FP-Tree不对同一叶子节点内的数据进行排序.跳表作为一种简单且高效的索引结构被广泛应用在各种键值数据库中,如LevelDB[7]和RocksDB[8]都将跳表作为内部数据的索引结构,自NVM出现以来也有工作讨论基于NVM的持久化跳表实现.
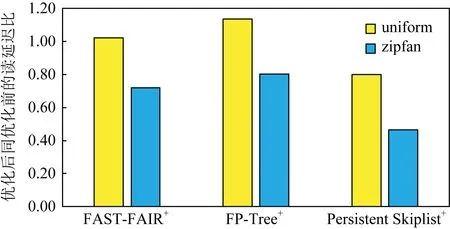
Fig. 19 Index read latency comparison after using ACS optimization图19 经过ACS优化后的索引读延迟对比
在为索引加载了5 000万个索引项后,我们分别使用YCSB[22]中的均匀负载以及非均匀负载(负载分布为zipfan)进行了读评测.在评测中,将缓存的容量设置为最多可容纳总数据量10%的容量,评测结果如图19所示.在均匀的负载情况下,由于缓存命中率较低从而导致一次搜索需要同时搜索缓存以及持久化索引,这使得ACS优化下的索引读性能并没有的提升;而在zipfan的负载情况下,缓存的命中率较高,因此一次搜索只会搜索缓存而不会搜索索引,因此经过ACS优化后的索引最多可以降低40%的读延迟.可以看到,被优化索引的性能越差,通过ACS优化后所取得的收益越高.需要注意的是,对于插入操作,ACS不会影响索引的性能,但对于更新操作,ACS为了保证缓存和实际索引的一致性,需要在更新时对缓存进行修改,因此使用了ACS优化后的索引更新性能会下降20%~30%.
讨论:ACS可以在zipfan负载下取得较高的缓存命中率,因此可以获得较好的读性能,然而在面向uniform的负载倾斜时面临着读延迟升高的情况.这主要是由于ACS的搜索为串行执行,当搜索DRAM中缓存不成功时,还需要继续搜索位于NVM的持久化索引.为了解决该问题,我们可以使用并行搜索方法去降低请求延迟.如图20所示,当进行一次搜索时,可以在搜索DRAM中缓存的同时让后台线程搜索位于NVM的持久化索引,从而避免当缓存未命中时而导致的高读延迟.对于更新操作同样可以使用该方法进行优化.
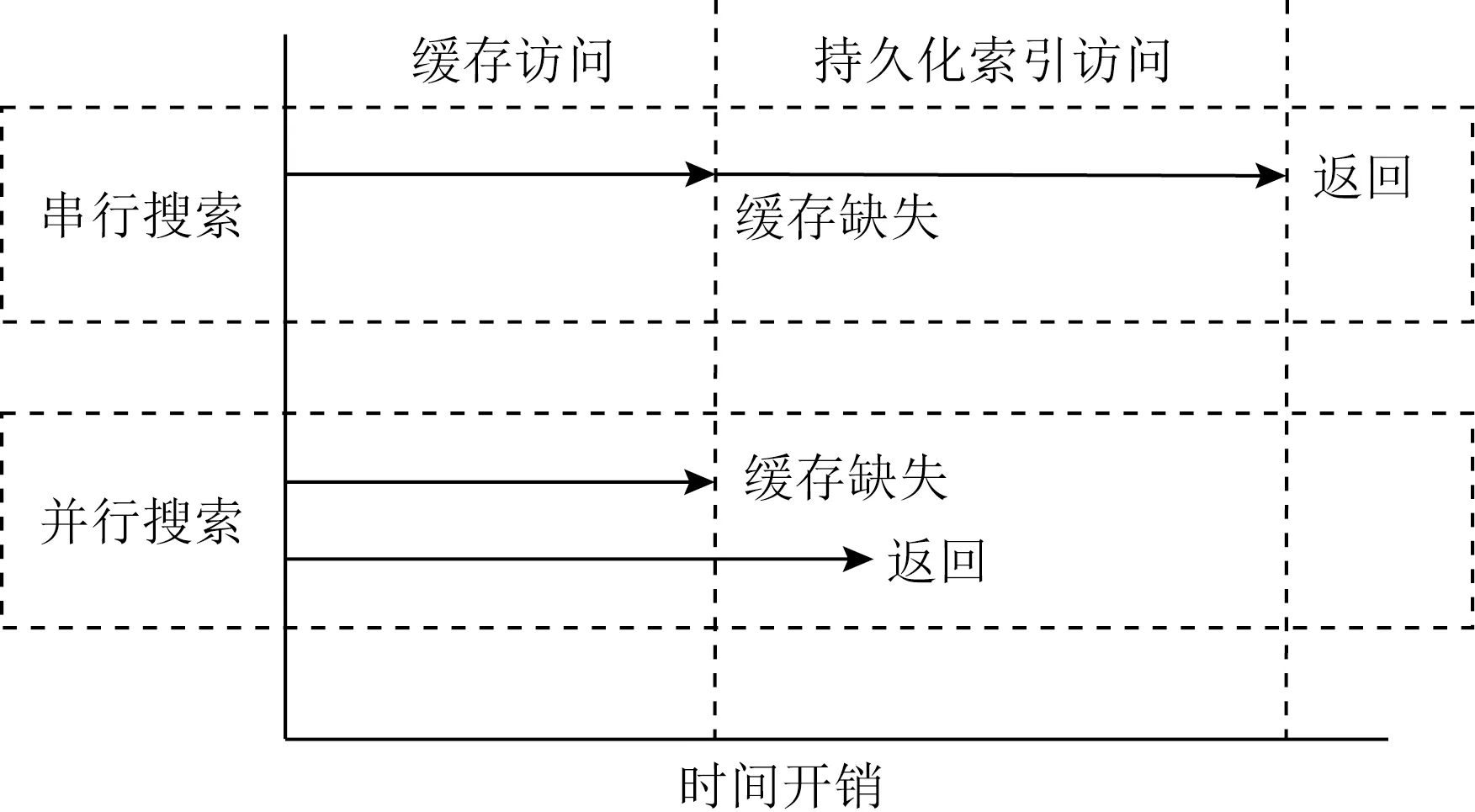
Fig. 20 Comparison of parallel/serial access time process based on ACS图20 基于ACS的并行/串行访问时间过程对比
实验表明,经过并行搜索优化后的ACS,在缓存未命中情况下其读性能和更新性能不会下降.然而,进行并发搜索会消耗额外的CPU和带宽资源,因此在设计系统时可以根据缓存命中率决定是否启用并行执行,当缓存命中率较低时可以开启并行访问模式,反之当缓存命中率较高时可以只开启串行模式避免额外的系统资源消耗.
4 相关工作
目前已有其他AEP的测试工作,在文献[23]中,作者测试了AEP的带宽和延迟数据和AEP在若干系统中的表现(如Memcached, RocksDB).但该工作主要聚焦于AEP在系统内的表现,忽视了AEP本身的物理特性,未能挖掘出AEP的详细访问特性.而在文献[24]中,除AEP的带宽延迟信息外,作者进一步探索了AEP的尾延迟特性和多线程下的表现,分析了AEP的多线程访问中性能下降的问题,但并发提及混合读写下AEP的读写保护机制.
在过去的几年里,有许多工作基于NVM去设计高性能索引.Level Hashing[10]采用了2层Hash结构设计,在Hash表拓展时只进行一层结构的重构,从而减少了Hash拓展时的写开销;CCEH[9]采用段结构来降低Hash表拓展时的写开销;NV-Tree[12]针对B+树进行优化,它将内部节点保存在易失性内存中,将叶子节点保存在NVM中,从而减少了树分裂时对NVM设备被造成高昂写开销;FP-Tree[13]基于NV-Tree基础上设计了简单高效的并发算法并利用signature槽优化了访问叶子节点时开销;FAST-FAIR[11]设计了一种高效的持久化B+树算法;WORT[16]针对字典树在NVM中进行了写优化.
这些工作大多面向NVM高昂的持久化开销来进行优化,本文的工作主要面向非易失性的高读延迟进行优化,在保留过去研究设计的基础上设计了面向混合内存架构的异步缓存方法,在高倾斜的读负载情况,我们的优化能降低不同索引20%~40%的读延迟.
5 总 结
本文对实际的非易失性内存器件AEP进行了评测.基于评测结果发现,AEP的硬件性能同之前的假设有所不同:AEP同DRAM相比有着更高的写延迟以及更低的读延迟.为此,本文重新审视了之前的工作.一方面,针对过去的混合索引研究工作,本文提出对换索引位置提高索引的搜索性能,实验表明,HybridIndex+相比HybridIndex可提升80%的读性能;另一方面,不改变原索引结构的基础上,本文提出了在DRAM中建立高速缓存的方法去加速AEP中的持久化索引搜索.实验表明,本文提出的优化方法最多可以降低50%的读延迟.在本文中主要讨论了在不改变原索引设计的基础上如何基于混合内存架构去提升原索引性能.然而,根据硬件评测结果显示,AEP作为可字节寻址设备依然与DRAM有着不小的区别,比如AEP有着更低的读写带宽以及更大的访问粒度,这也为日后的持久化索引研究工作提供了更多挑战.
