大规模MIMO系统基于多分辨率深度学习网络的CSI反馈研究
2021-02-02李中捷熊吉源高伟金闪
李中捷,熊吉源,高伟,金闪
(中南民族大学 电子信息工程学院&智能无线通信湖北重点实验室,武汉 430074)
过去十年中,全球移动数据流量高速增长,预计2021年全球互联网流量相比2005年数据量将增长23倍.随着信息时效性在工作生活中不断增强,人们对更高速的通信网络需求更加迫切.大规模多输入多输出(Multiple Input Multiple Output,MIMO)系统以及毫米波的使用,可以实现从4G到5G的提升.未来的6G网络更需要这些大规模MIMO系统[1],以及人工智能决策的加入.对于大规模MIMO系统,基站(base station,BS)将会配备数百个甚至数千个天线[2],该系统可以减少多用户之间的网络干扰并提高小区用户网络传输速率[3].CSI在系统中起着至关重要的作用,它可以增加信道容量,降低误码率和硬件复杂性.在频分双工模式中,用户设备(User Equipment,UE)需要将其CSI发送回BS,BS根据CSI来调整系统传输策略.为了保证CSI的时效性,必须尽可能降低反馈延迟.但是,在大规模MIMO系统中,随着天线数量增加,CSI反馈数据量也随之增加,这对大规模MIMO系统及时传输CSI提出更高要求.因此,提出一种高效、简洁的压缩算法至关重要.目前,通常采用矢量量化或基于码本的方法来减少反馈开销.然而,这些方法产生的反馈量与发射端天线数量成线性比例,且在大规模MIMO系统中不具备适用性.大规模MIMO系统中CSI反馈的挑战激发了众多研究[4-5],这些工作主要集中在通过使用CSI的空间和时间相关性来减少反馈开销,相关的CSI可以转换为不相关的稀疏向量,因此,可以使用压缩感知从不确定线性系统中获得对稀疏矢量足够准确的估计.这个概念启发基于压缩感知和分布式压缩信道估计的CSI反馈,例如LASSO[6]和TVAL3[7]等算法.由于信道矩阵中不同情况下矩阵信息是不同的,这些算法并未明显提高CSI恢复质量,且在降低复杂度,低延迟等方面效果微乎其微.
由于深度学习的兴起,在文献[8]中设计 “CSINet”神经网络,显示其相对于传统压缩感知方法的压倒性优势.之后,文献[9]和[10]中提出“CSINetPlus”和“CRNet”通过更换卷积内核或改变残差类型来提高网络性能,而无需额外操作.它们证明CSI反馈任务中网络设计的巨大潜力.但“CSINetPlus”不仅继承了大多数“CSINet”架构设计,且“CSINetPlus”和“CRNet”具有计算量大和网络复杂度高的劣势,违背便捷部署的初衷.而本文提出的MCSINet在网络复杂度,浮点计算量及训练时长等方面都优于其它网络.
本文提出MCSINet模型来解决上述问题.为了解决CSINet网络的单一性,本文提出分类讨论思想,针对不同情况改变网络相关结构进行训练.另一方面针对训练时长以及网络复杂度相关问题,提出使用多分辨率网络卷积核以及压缩网络层数的方案来解决,最后通过引入再图像处理方向效果显著的残差网络[11]模型.实验表明:MCSINet不仅训练时长更短,而且在计算量、误码率以及复杂度方面都优于其他算法.
1 系统模型
本文假设一个具有频分双工模式下的单小区下行链路大规模MIMO系统,如图1所示.基站有Nt个发射天线,用户有一个接收器天线,OFDM具有Nc个子载波.第n个子载波的接收信号可以表示如下:
(1)
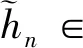

图1 MCSINet辅助下行CSI反馈工作流程Fig.1 MCSINet assisted downlink CSI feedback workflow

(2)

2 多分辨率信道状态信息网络(MCSINet)
2.1 MCSINet模型
为达到最佳网络效果,本文借鉴在图像处理方面效果较好的残差网络,并对其进行改进形成现有的MCSINet.如图2所示,实现通信系统中对应的编码器和解码器.由于室内和室外的信道矩阵具有不同稀疏度,不同压缩率(Compress Ratio,CR)对应的信道恢复所需要提取的特征向量也是不同的,因此,针对这两个问题,本文需要采用不同的网络结构.在解码器端,MCSINet采用不同卷积核提取信道信息,对于包含更复杂信息的室内信道而言,本文将采用较小卷积核来提取出更为细致的特征,与此相反,对于包含更多无用信息的室外信道而言本文将采用较大卷积核.在编码器端,恢复压缩后的特征矩阵,对于不同压缩率,采取不同的恢复方式.同时,为了让网络训练效果最佳,在编码器端中间部位采用残差网络结构,如图2中的Block模块.
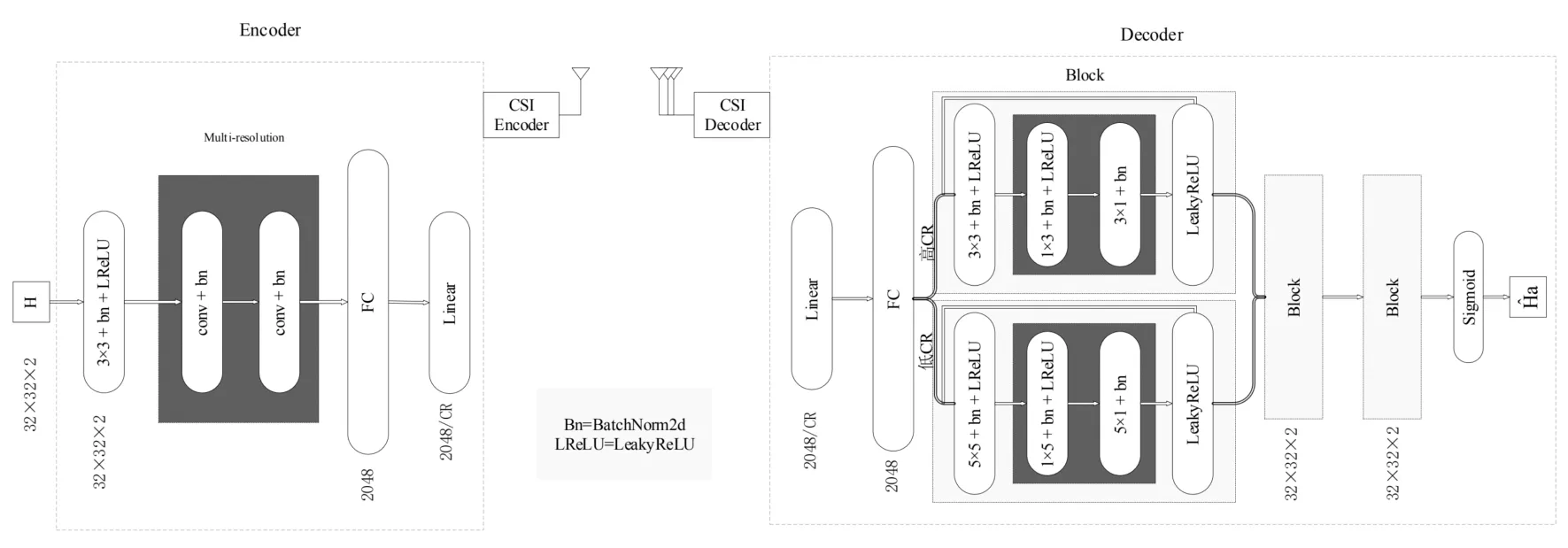
图2 MCSINet编码器和解码器设计以及对应层输入输出大小Fig.2 MCSINet encoder and decoder design and corresponding layer input and output size
2.1.1 针对室内压缩
对于室内低CR:网络采用3×3小卷积核和5×5大卷积核作比较,发现小卷积核实验结果表现更优.经过分析发现:在室内低CR时,需要提取到更多信道矩阵细节,因此,提取信道矩阵的特征提取选用小卷积核能够捕获到更细节的信息,不会造成信息遗失,有助于网络对信道矩阵学习.
对于室内高CR:网络采用5×5大卷积核来进行学习,将上一个网络中除解码器端卷积核以外的其它卷积核全部替换成5×5卷积核,这样将有助于网络仅需对基站处的参数进行微调.经过实验发现,在解码中恢复信道矩阵经过高压缩率后的特征矩阵时,需要大卷积核重复恢复特征信息,以确保原信道矩阵恢复准确性.
2.1.2 针对室外压缩
由于室外信道矩阵0元素较多,所以本文对编码器采用大卷积核去提取信道矩阵中的特征,这样可以避免无用信息掺杂影响信道恢复,实验证明该方法行之有效.另外对应不同压缩率处理也是和同室内的方法相同.
为降低网络复杂度以及训练时长,文章采用将网络中编码器和解码器添加多分辨率卷积核,即将传统卷积核替换为两个累加的多分辨率卷积核,这样不仅能减少矩阵之间计算来降低网络复杂度,而且可以缩减训练时长,降低通信系统的直接延迟.例如:将传统7×7卷积核,改成7×1加1×7卷积核,通过使用thop这个Python库计算发现这样大大降低矩阵之间计算消耗.最后再通过Block模块叠加三次产生输出经过sigmoid函数恢复信道.
2.2 模型训练
本文使用与文献[8]相同数据进行实验,这些数据通过COST2100[12]仿真获得.考虑两种类型场景:5.3 GHz室内场景和300MHz室外场景.为了便于比较,本文采用与CSINet[8]相同系统设置.BS考虑Nt=32的均匀线性阵列(ULA)模型.对于FDD系统,在频域中取Nt=1024,在角域中取Na=32.150000个独立生成信道分为三个部分.训练,验证和测试数据集分别包含100000、30000和20000信道矩阵.
整个通信系统在PyTorch中实现.随机初始化网络参数.网络超参如表1所示,以及Adam优化器相关参数.根据实验观察,网络训练100个epoch就能达到与文献[8]相同效果.

表1 训练超参Tab.1 Training super parameters
为了使网络预测更加准确,本文加入了BatchNorm2d模块将数据归一化:
(3)
其中数值在表1中给出.为了减少不同训练批次间的数据抖动情况,从而提高训练速度,防止过拟合.
每个卷积后都进行批量归一化.此外,在每个“conv-bn”层的末尾添加LeaKyReLU激活层,以提供非线性.LeaKyReLU的定义在公式(4)中显示.
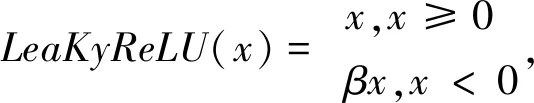
(4)
其中β∈(0,1)是负斜率.本文的MCSINet中将β设置为0.3.
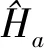
(5)
(6)
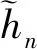
3 仿真结果与分析
对于传统算法以及现有的神经网络算法,进行分开比较.对于传统算法,本文更在意的是原信道矩阵与恢复过后的信道矩阵之间的NMSE误差和余弦相似度ρ进行分析.结果如表2所示.

表2 不同算法NMSE(DB)和ρ比较Tab.2 Comparison of NMSE(DB) and different algorithms
从表中可以清晰看出对于传统算法,本文提出的神经网络模型无论在任何场景和压缩率的情况下,NMSE和ρ都是低于其他算法,尤其是在高CR情况下,MCSINet信道恢复表现更加出色,这也说明网络单一性的劣势以及对不同情况进行不同分析的正确思想.
由于同属神经网络模型训练,与现有深度学习方法进行比较时,NMSE差值将不再是最重要的,而是更看重网络计算量,训练时长以及网络参数数量.已知CSINet网络的训1000 epochs需要5 h,而网络在同等环境下训练100 epochs仅需要0.5 h就达到同样效果,甚至在大多数场景下,本文提出的模型能训练出更低NMSE(如图3所示).最后本文在经过500 epochs训练后的性能进行对比和分析.

图3 MCSINet和CSINet训练不同时长的结果对比Fig.3 Comparison of the results of MCSINet and CSINet training for different durations
在计算浮点运算数量方面,MCSINet网络使用多分辨率卷积以及减少网络层数,注重简便快捷,能够获得低时延效果.图4显示网络浮点计算量的比较,可以看出在CR=4、8、16、32时,MCSINet网络计算量无论是室内还是室外都小于其它网络,尤其是在室内情况下,这将会得到更短训练时长,更快地进行信息传输.最后可以注意到,在由低压缩率到高压缩率时,网络的复杂度会增高,这是由于网络在高压缩率情况下选择大卷积核所造成的影响,但是计算量还是低于CSINet与CRNet.

图4 不同网络的浮点数计算量Fig.4 Floating point calculation amount of different networks
接下来具体分析对于解码器端卷积核的选择,在室内情况下本文对比大卷积核与小卷积核的训练效果,发现对于低压缩率情况来说小卷积核将会有更低NMSE,而高压缩率时则与此相反,大卷积核表现更好.本文采用CR分别为8和32的室内情况来代表低压缩率和高压缩率.由于低压缩率情况下,需要更详细的特征提取,确保特征矩阵中包含尽可能多的有用信息,这就间接说明为什么在低压缩率情况下要选用小卷积核.同理高压缩率情况下,需要产生更小的导频信道,只有通过大卷积核才能提取出包含有用信息的特征矩阵.如果将在低压缩率下表现很好的模型用在高压缩率情况下,效果却不尽如人意.
当CR=8时,本应使用3×3卷积核(包括多分辨率卷积核),为了不在用户端改变参数,本文改变基站端卷积模块为5×5.参数对比如表3,可以清晰发现在低压缩率情况下,将小卷积核改变为大卷积核后,准确率反而降低2.5%,也会增加53.85%模型计算量,导致训练时长增加.如图5所示,最后在对比同样训练时长下的NMSE时,可以看出NMSE相差2.56,尤其MCSINet在训练50个epochs时,就达到了理想值.其中黑线部分给出,在同样环境下CSINet训练1000 epochs所得到的NMSE,明显看出MCSINet再训练时间缩短至十分之一情况下,所产生的结果优于CSINet.这也是本文提出对于不同任务,选用不同模型的意义所在.

表3 不同卷积核对应不同参数对比Tab.3 Comparison of different parameters corresponding to different convolution kernels
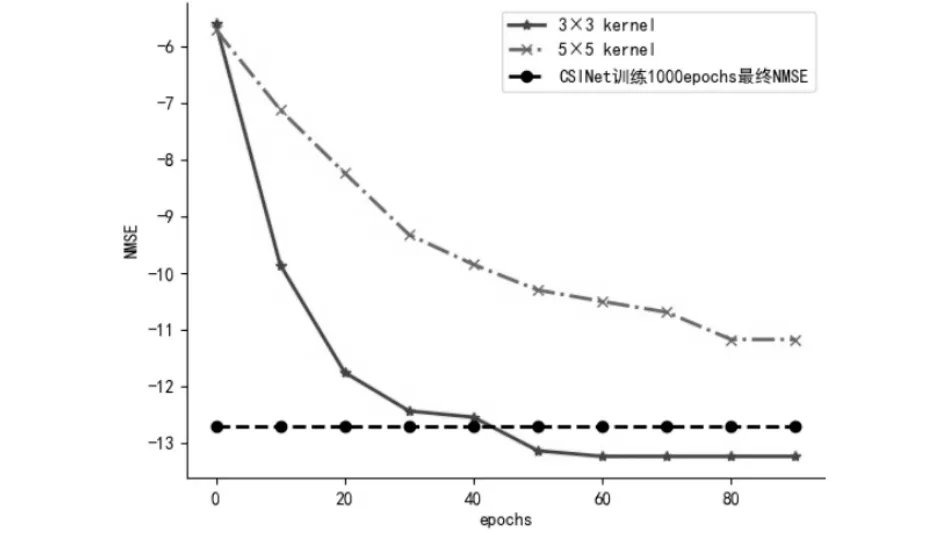
图5 室内CR=8时不同卷积核以及CSINet的NMSE对比Fig.5 Comparison of different convolution kernel NMSE when indoor CR=8
如图6所示,当CR=32时,将已有模型与大卷积核模型相比较,也能看出小卷积核并不适用于高压缩率情况,通过训练数据发现使用小卷积核会降低1.48%的准确性,虽然在训练100个epochs时NMSE只相差0.55,但是能发现随着训练时间的增加,之间相差的越大.同时图中给出,在同样环境下的CSINet训练1000 epochs所得到的最终NMSE,可以发现MCSINet效果更好.
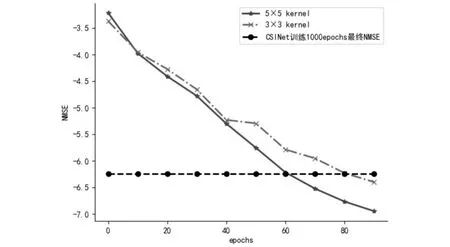
图6 室内CR=32时不同卷积核NMSE对比Fig.6 Comparison of different convolution kernel NMSE when indoor CR=32
接下来针对室外情况进行改进,对于CSINet,CRNet等网络都是单一训练,网络模型不发生改变,这样的工作相对简单.对于不同网络应该适应不同模型,这样才不会单一化,对不同情况,分类别进行处理,才会预测出更准确的信道矩阵.在CR=4的室外情况下,针对编码器端进行改进,以克服室外信道矩阵中包含无用信息较多的情况.实验中对于室外的情况分别调换了编码器端卷积头进行比较,如图7所示,可以发现在解码器端相同情况下,小卷积头在训练的前期表现的更好.在训练结束时,对比NMSE则发现5×5卷积核模型综合表现更佳,但卷积核持续增大并不意味着效果进一步增加,反而将会更差.对于编码器端改进,如室内情况相同,这里不再做详细介绍.
最后,本文挑选出一种情况:室内CR=16时,MCSINet训练500 epochs时NMSE为-9.8,与CSINet训练1000 epochs时NMSE为-8.65和MCSINet训练100 epochs时NMSE为-8.593的情况相比(如图8所示),提升14%.同时根据实验数据(如表4所示)显示误码率也提升2%和1.8%,再一次证明MCSINet网络经过更久训练,会达到更好效果.
图7 室外改变编码器端卷积核的对比Fig.7 Comparison of changing the convolution kernel on the encoder side outdoors

表4 不同网络的误码率对比Tab.4 Comparison of bit error rates of different networks
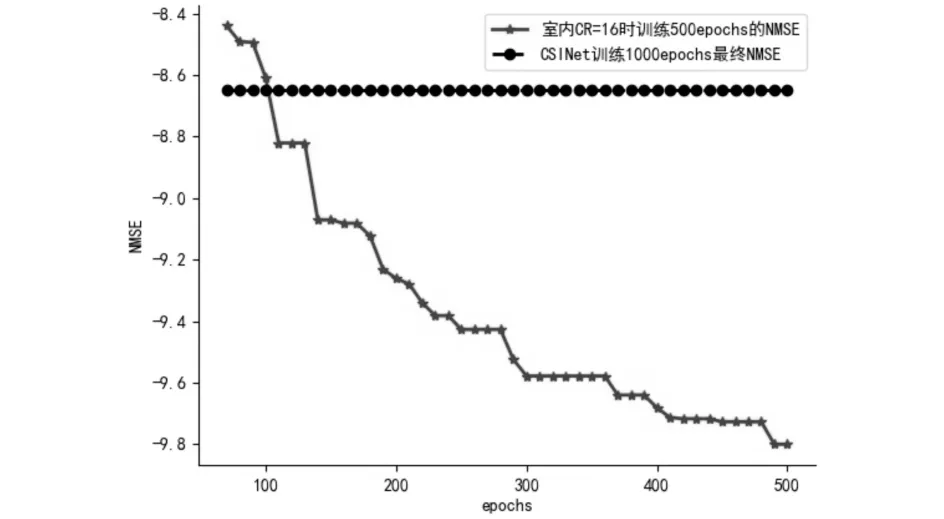
图8 培训过程对MCSINet NMSE(DB)性能的影响Fig.8 The impact of the training process on the performance of MCSINet NMSE(DB)
4 总结
针对大规模MIMO 频分双工系统中CSI反馈,本文提出一种基于深度学习多分辨率和多元化模型的压缩感知框架,并解释设计初衷,成功地提高网络性能.在与传统算法和其它深度模型框架对比后发现MCSINet表现更佳,特别是在训练时长,计算量以及误码率和复杂度方面.另外在室内情况下不需要对用户处编码器进行任何参数更新,只需在基站处解码器中针对不同CR进行微调.实验表明,在相同信道矩阵条件下,MCSINet网络达到预期结果仅需CSINet训练时长的1/10,大多数情况下结果甚至会更好.然而在网络简洁化,以及不同数据集测试等方面还需要更为充分详实研究,这也是接下来的研究重点.
