基于多特征集成决策树算法的门诊需求预测
2021-02-01彭俊张肖建徐超谢勇项薇何达
彭俊 张肖建 徐超 谢勇 项薇,2 何达
0 引言
随着我国经济水平的快速增长、人口的增加、健康服务质量标准的提高,人民对医疗环境、医疗服务、医疗质量的期望值越来越高,从而为医院的运作带来越来越大的压力[1],并促使管理者更加注重医院的运作管理,优化医院的运作流程和资源配置,而门诊需求预测是优化医院运作管理和资源配置的前提。
门诊是医院机构优化管理的一个重要部门,预测日门诊量可以为门诊管理决策提供前提条件,做好门诊资源的统筹和安排,从而提高医疗机构管理水平。医疗机构日门诊量的预测属于中短期预测,现有研究根据模型和方法可分为两类:基于时间序列的传统预测模型[2-5]和基于机器学习算法的预测模型[6-8]。前者通常只考虑自身历史时间序列数据对未来值的影响,如经典自回归移动平均模型(autoregressive integrated moving average model, ARIMA),具有短期预测精度较高、中长期预测效果较差的特点,并且该模型只考虑数据本身对未来的影响,并没有考虑数据外的影响因素。基于机器学习算法除了考虑到自身历史数据的影响,还考虑了与问题相关联的天气、空气指数等其他外部数据。典型的机器学习方法有人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine,SVM)、逻辑回归、决策树、邻近算法(k-nearestneighbor,KNN)和集成学习,其中ANN在医疗领域的预测中应用较多,该算法在包含非线性成分的复杂数据上具有更强的表达能力。
上述研究大多是基于时间序列数据进行建模,在机器学习算法中还有一类典型的分类算法为决策树算法,具有防止过拟合、泛化能力较强等优点,已被广泛用于预测问题中。为了提高决策树预测的稳定性,进一步引入了集成学习思想,目前比较流行的集成决策树算法有梯度提升决策树(gradient boosting decision tree, GBDT)和随机森林(random forest, RF)等。2018年Qiao等[9]将集成决策树模型应用于急诊室就诊情况(是否就诊)的预测,结果表明该方法取得较好的预测效果,但此研究仅对就诊情况进行分类预测,并没有进行就诊人数的预测。集成决策树算法在其他预测领域进行回归预测的应用较多,比如电力负荷预测[10]、交通流的预测[11-13],这类研究都取得较好的预测效果。
为了提高医院日门诊人数预测精度,本文拟引入机器学习算法GBDT和RF,同时引入外部环境数据,并且挖掘出时间、天气、假期等新的特征,将其应用到宁波市某妇幼保健院日门诊量的预测中,建立多特征集成决策树的预测模型,为医疗需求预测提供新的建模思路。
1 集成决策树原理
1.1 RF算法
RF[12]是利用Bagging集成学习方法的典型算法,是用Bagging的思想建立一个决策树森林。将每一棵决策树得到的预测值进行算术平均作为最终预测结果,以提高预测结果的准确性和稳定性。具体算法流程如下。
假设输入样本集D={(x1,y1),(x2,y2),…,(xm,ym)},其中xi表示特征,yi表示标签值。
决策树迭代次数为T,输出为最终随机森林模型f(x)。
(1)对于t=1,2,…,T,训练集进行t次随机采样,共采集m次,得到包含m个样本的采样集Dt。
用采样集Dt训练第t个决策树Gt(x),在训练决策树模型的节点时,在节点上所有特征选择nsub个特征,在这些随机选择的部分特征中选择一个最优特征来分割决策树。这样一共得到T棵决策树。
(2)对于回归算法,将T棵决策树得到的回归结果进行算术平均,所得到的结果为最终模型输出:
(1)
1.2 GBDT算法
GBDT是在2001年由Friedman等[14]提出的一种基于Boosting方法的集成决策树算法,该算法的基本思路是根据损失函数的负梯度在当前模型下的值作为下一次训练的目标,从而模型的输出结果将沿着损失函数减小的方向移动,这样通过迭代不断提高预测准确性。算法中的损失函数有很多选择,常见的有平方损失函数、指数损失函数等。具体的算法流程[15]如下。
(1)假设输入的训练样本集T={(x1,y1),(x2,y2),…,(xN,yN)},损失函数为L[y,f(x)],输出回归树为F(x)。
(3)对于m=1,2,…,M(M为迭代次数,即决策树的棵树)按以下3步循环。
① 对于i=1,2,…,N,计算rmi,即:
(2)
式中:rmi是损失函数的负梯度在当前模型的值将它作为残差估计;N为样本数。
② 对于{(x1,rm1),…,(xN,rmN)}拟合一颗决策回归树,得到Tm(x)。
③ 更新fm(x)=fm-1(x)+Tm(x)。
得到最终回归树为:
(3)
其中,损失函数采用的是平方损失函数,当L[y,f(x)]=[y-f(x)]2时,r=y-fm-1(x)。此时,损失函数负梯度方向的值是当前模型的残差,之后的每一棵树只需要拟合当前模型的残差即可。
2 多特征集成决策树的预测模型在日门诊量中的应用
2.1 算例说明
选择宁波某妇幼保健院日产前检查访问量数据进行应用。数据选取2016年1月4日至2018年3月30日产前检查科每日就诊人数,该数据来源于宁波市某妇幼保健的信息系统。训练数据为2016年1月4日至2018年2月28日共537条数据,预测数据为2018年3月1至2018年3月30日共22条数据,并用训练数据分别拟合ARIMA(1,0,1)模型、RF模型以及GBDT模型。
2.2 特征工程
由于在集成决策树预测模型中不同的特征对预测结果产生的影响不同,为了提高模型的预测精度同时降低模型的计算复杂性,需要选择与目标变量最为相关的特征。根据妇幼保健院门诊数据的特征和每日就诊人数的历史数据,通过分析选取以下属性作为模型的特征。
2.2.1 前n天的门诊人数
日产前检查人数是一个时间序列模式,且具有自相关性,所以下一天的就诊人数必然会与当天或者前n天的就诊人数有关。根据上文拟合的ARIMA模型可知,取n=1,即前一天产前检查人数作为一个特征。
2.2.2 时间特征
由于该问题是一个时间序列回归,必然与时间相关,需要在时间上做一些特征,参考文献中所提到的方式,构造时间特征“day”“year”“month”。这些特征都可以通过Python中的时间函数将每天的时间特征分离出来。时间特征描述见表1。

表1 时间特征描述
2.2.3 节假日特征
由于该妇幼保健院属于事业单位,根据国家规定节假日放假,节假日医院不接诊。根据搜集的数据特点来看,周末的就诊人数都为0,并且每次妇幼保健院放假后门诊访问人数根据假后天数的增加而增加,直到下一次节假日后呈现同样的规律。根据这个规律构造一条节假日特征“holiday”,该特征表示当天为放假后的第几天。
2.2.4 天气特征
经过对数据分析研究发现,由于研究对象是妇幼保健院门诊人数而不是急诊,服务的对象大多数是孕妇,所以天气也是一个重要的影响因素,它会影响到她们是否去医院检查。根据中国气象网。统计2016年1月至2018年2月医院接诊日里,有278 d晴天,217 d小雨,33 d中雨,9 d大雨。此外,考虑到当天的空气质量对人们出行的影响,将PM2.5值也作为一个特征,根据PM2.5值,将空气质量划分为“优”“良”“轻度污染”“中度污染”。同时将每天的平均气温、平均风速也作为天气特征放入其中。
2.3 数据处理
选取门诊数据的前一天的访问量“前一天人数”,构造的时间特征“星期几”“年份”“月份”,假期特征“假后第几天”,天气特征“天气”“平均温度”“平均风速”“PM2.5”等一共9个因素作为特征,其中“前一天人数”“平均温度”“平均风速”“PM2.5”以“数值”属性输入,“星期几”“年份”“月份”“假后第几天”“天气”以“类别”属性输入。将“产前检查人数”作为目标变量。经过预处理后的样本数据如表2所示。

表2 多特征产前检查样本数据
2.4 特征重要度评估
2.4.1 RF模型特征重要性评估
在建立RF模型的同时,还可以根据袋外数据(out of bag,OOB)即自助法抽样时未被抽取的样本,N次自助抽样会产生N个OOB数据集)误差估计来评价模型特征的重要度。RF模型中各个特征的重要性如图1所示。从图中可以看出“t-1”“meantempi”“holidays”“PM2.5”4个特征得分较高。

图1 RF模型特征重要性得分
2.4.2 GBDT模型特征重要性评估
GBDT模型中通过迭代生成多棵决策树,特征j在模型中的全局重要性是通过它在所有决策树的平方误差减少量的平均值来衡量。图2表示各个特征的重要性得分。从图2可以看出“t-1”“meantempi”“holidays”“PM2.5”这4个特征最为重要。

图2 GBDT模型特征重要性得分
2.5 评价指标
以下指标作为模型预测效果的评价标准。
(1)均方根误差(root mean square error, RMSE):RMSE是通过若干个预测值对预测效果进行综合评价,其计算公式为:
(4)
RMSE越小,模型的预测精度越高。
(2)百分比误差(percentage error, PE):PE是对单个预测值进行预测精度的评价,其计算公式为:
(5)
(3)平均绝对百分比误差(mean absolute percentage error, MAPE):MAPE是通过若干个预测值对预测的PE进行综合评价,其计算公式为:
(6)
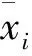
3 预测结果及分析
目前基于时间序列数据的ARIMA预测模型已经成功应用于医疗机构门诊人数的预测中。为了分析本文模型的预测效果,将本文的多特征集成决策树RF模型、GBDT模型以及ARIMA模型的预测结果进行比较。其中ARIMA模型采用MATLAB2014b实现,基于多特征集成决策树的预测模型采用Python3.5和sklearn模块实现,模型中主要涉及的几个重要参数取值见表3。
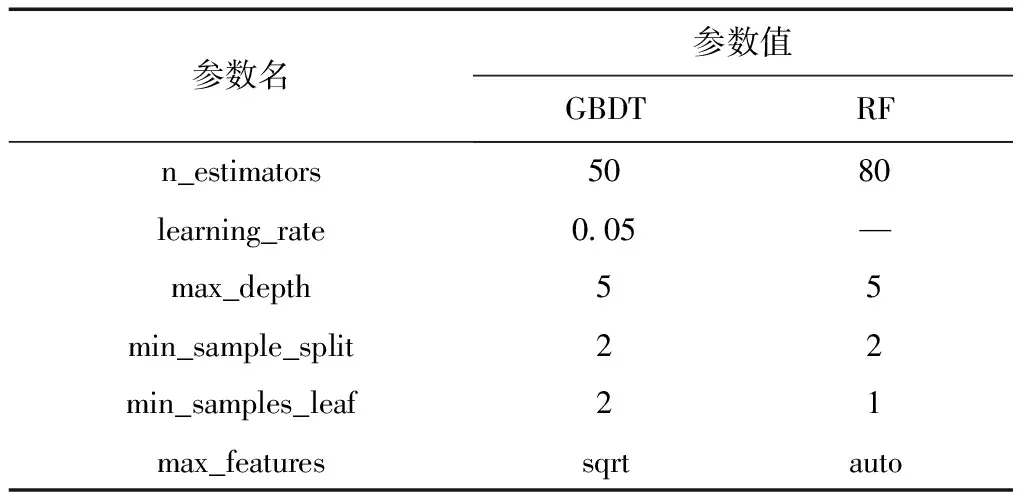
表3 各参数的GBDT和RF
通过参数的确定,保证GBDT模型预测精度尽可能达到最大化,将其应用到宁波妇幼保健院未来一个月每日产前检查人数和就诊人数。将训练集数据用10折交叉验证法[16]进行训练,训练后的拟合效果用RMSE评价,训练集和测试集RMSE值如表4所示。从表4中可以看出,两个模型测试集和训练集的MSE值相近,并且测试集的RMSE值大于训练集,说明模型没有过拟合,模型可靠。3种模型的预测结果如图3所示。由图3可以看出,GBDT和RF模型的预测趋势比ARIMA模型更加接近实际值的趋势。同时,本文计算3种模型预测结果的MAPE、PEmax、PEmin、PEσ,并且进行比较以评价3种模型的预测效果,结果如表5所示。结合表5和图3可得到如下结果。

表4 GBDT与RF模型训练集与测试集RMSE比较

表5 模型预测效果比较
(1)对于两种集成决策树算法的应用层面,GBDT算法和RF算法的平均百分比误差分别为14.95%和17.16%,预测误差均在87%左右,均满足该妇幼保健院的日产前检查人数预测的应用需求。
(2)从预测值的相对误差和模型拟合的MSE值来看,GBDT模型的预测效果均优于RF模型。针对预测值相对误差的标准差来看,预测误差的离散程度GBDT模型要小于RF模型。根据图3可知,GBDT预测值的趋势跟实际趋势一致,而RF模型的实际波动情况差异较大。
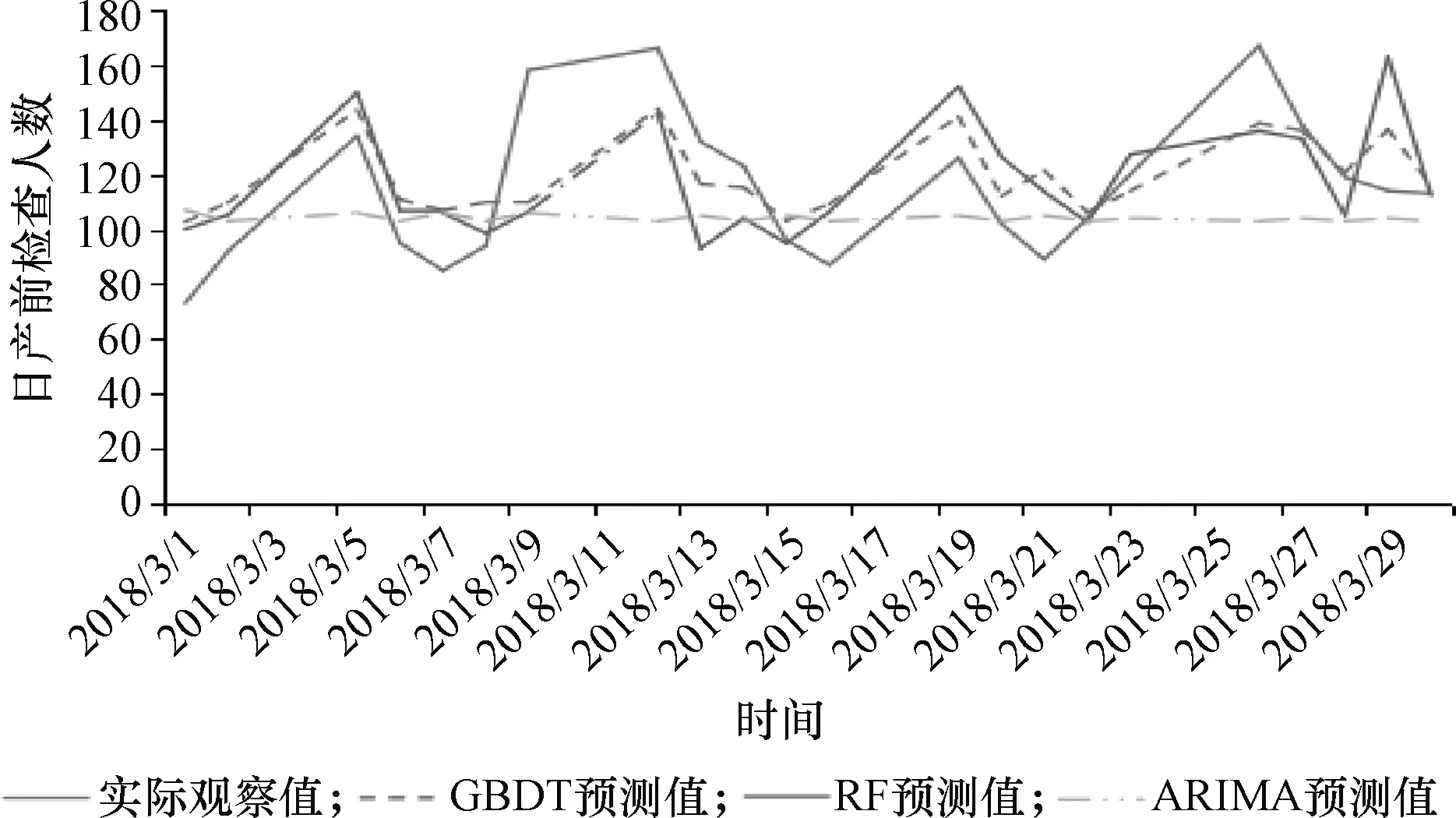
图3 2018年3月日产前检查人数预测结果
(3)与单数据时间序列模型ARIMA模型相比,针对该妇保院日门诊预测问题,两种多特征集成决策树模型的各项评价指标均优于传统的ARIMA模型。
4 结论
本文主要为解决医疗需求预测问题提供建模思路。首先分析与目标变量相关的外部因子,然后分析其相关性,形成多渠道数据集,建立多渠道数据预测模型。并将两种典型的集成决策树算法GBDT和RF模型,应用到宁波某妇幼保健院日产前检查人数的预测中,根据样本数据特征以及相关因素选择出历史数据、时间、节假日、天气四个方面的特征拟合模型,用以预测未来一个月每日检查人数。最后比较两种多特征集成决策树模型的预测结果,其预测结果具有实际参考意义。同时本文使用不同的指标将多特征模型与传统的时间序列ARIMA模型进行对比,结果显示,两种多特征集成决策树模型的预测效果均高于传统的ARIMA模型。本研究对优化医疗资源配置和管理决策具有积极的意义。
