针对ASR系统的快速有目标自适应对抗攻击
2021-01-29张树栋高海昌曹曦文
张树栋,高海昌,曹曦文,康 帅
(西安电子科技大学 计算机科学与技术学院,陕西 西安 710071)
神经网络的快速发展,使其应用于多种领域,如自动驾驶、面部识别、目标检测、语音识别和图像分类等。但是,最近的研究[1-3]已经表明神经网络容易受到对抗样本的影响。攻击者可以通过在输入中添加一些人类不容易感知的微小扰动,使得神经网络输出任何想要的结果。对抗样本的发现对深度神经网络在现实生活中的应用构成了极大的安全威胁。攻击者可以通过生成对抗样本来欺骗面部识别系统,入侵移动设备,获取相关的隐私信息;或是对道路标识符进行篡改,促使自动驾驶汽车将右转弯的交通标志识别为笔直,由此引发交通事故。
对抗样本的研究最初主要集中在图像空间上,除了少部分目标检测,语义分割,人脸识别和强化学习的研究内容外,大部分都是针对图像分类任务[1]。在其他领域,对抗样本也有相应的研究,如:文本分类,恶意软件检测[2]和语音识别[4]等。本文着重于语音识别领域的对抗样本攻击研究。
通常,根据攻击者攻击目标的不同,对抗攻击可以分为两种类型。一种常见的攻击方式是找到使目标模型分类错误的最小扰动。第二,在最大允许扰动范围内,最大化目标模型将扰动样本分类为目标类别的概率。最近,在获得具有最小扰动的对抗样本的攻击下,CARLINI等人[3]证明,对于任何音频样本,仅添加少量扰动就可以使自动语音识别模型将音频转录为攻击者指定的任意短语。尽管这种攻击产生的样本具有较低的噪声,但它需要进行大量的迭代,这对于实际场景中的自动语音识别攻击是不切实际的。
为了产生使对抗扰动范数值最小的攻击,需要优化两个目标,即在模型对输入进行了错误分类的同时还要保证尽量小的添加的扰动范数值。当前最先进的方法C &W[3]通过设计使用两个损失函数项来解决此问题,该方法攻击效果的好坏取决于平衡两个损失函数的超参数c的选择。在此基础上,还需要通过大量迭代来实现攻击。笔者提出了一种A-FTA方法,该方法基于最大化对抗样本和目标类别相似度的策略。具体来说,使用投影梯度下降法来生成目标音频对抗样本。在每次迭代中,针对每个音频值在损失函数中进行梯度下降操作,以使损失函数最小化,同时根据样本是否具有对抗性来改变最大扰动范数值。攻击的步长则随着迭代次数的增加而逐渐减小。最后,将生成的扰动音频映射到固定的可行解空间中。所提出的方法可以大大减少攻击所需的迭代次数,并且还可以避免由于扰动范数较小而导致最优解在两点之间振荡的问题。大量实验表明,在300次迭代中,A-FTA方法的攻击效果要优于现有的方法。即使仅进行100次迭代,依然能保证非常高的攻击成功率。
1 背景及相关工作
1.1 对抗样本
给定模型f(·)和输入样本x∈Rn,其对应的标签y∈Rm。存在微小扰动δ,使得x'=x+δ在某个距离度量d(x,x')中与x相似,但分类结果f(x')≠y。这样的样本x'称为无目标对抗样本。除此之外,还有一种更强大的攻击,称为有目标对抗样本。它不仅可以使目标模型针对x和x'输出不同的结果,而且还可以使模型对输入样本x'误分类为特定的标签t(由攻击者选择),即y≠f(x')=t。在图像领域,研究人员选择lp距离作为d(x,x'),最常使用l距离来评估添加的扰动的大小。根据攻击者是否对分类器f(·)的参数和结构有足够的了解,对抗样本的攻击方法可以进一步分为白盒攻击和黑盒攻击。在白盒攻击中,攻击者知道分类器f(·)的所有知识。在黑盒攻击中,除了输入和输出外,攻击者对分类器f(·)一无所知。
为了生成对抗样本,攻击者通常需要预先设置损失函数,然后通过执行基于梯度的优化过程来最小化损失函数。根据不同的目标,生成对抗样本的方法可以表示为在成功攻击的前提下保证扰动模值‖δ‖最小,或者在最大扰动预算范围‖δ‖≤ε中最大化对抗样本被分类为目标类别的概率。例如,获得具有最小失真的目标对抗样本的优化过程可以表示为
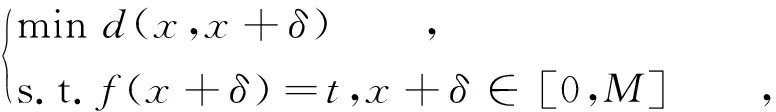
(1)


(2)
其中,c是平衡攻击成功率和扰动δ大小的超参数,c>0。
还有另一个更简单的目标函数,该函数最小化模型关于对抗样本的预测与目标标签之间的差异。与最小扰动优化不同,基于p范数的扰动固定为小于指定的阈值。对应的优化公式为

(3)
其中,ε是预设的添加的最大扰动值。与前面的式(2)相比,此优化更为简单有效,因为它不需要搜索其他超参数c。
1.2 音频对抗样本
CISSE等人[5]成功生成了语音对抗样本,导致Google的语音应用模型对输入的音频进行了错误的转录。2018年,针对MOZILLA对于DeepSpeech端到端的实现[4],CARLINI等人[3]使用基于优化的最小扰动白盒攻击方法来构建目标音频对抗样本,生成的样本作为输入可以被模型转录为他们想要的任何目标短语。文献[6]通过使用“心理声学掩膜”对KALDI上的ASR系统进行了人耳难以察觉的攻击。上述方法都直接将wav音频文件输入到模型中,而这在实际应用中是不现实的。YUAN等人[7]提出“CommanderSong”的方法来评估Kaldi模型,并使用歌曲作为载体来构建对抗攻击,所生成的对抗样本在空气传播中也同样有效。YAKURA等人[8]生成了可以无线播放的对抗样本。该攻击对短的两个单词或三个单词的短语非常有效,但对较长的句子短语则没有什么效果。QIN等人[9]将基于优化的最小扰动攻击与听觉掩盖的心理声学原理[10]结合,并针对Lingvo ASR系统[11]生成了难以察觉的音频对抗样本。LIU等人[12]提出了加权采样音频对抗攻击方法,该方法可以在几分钟内生成低扰动和高鲁棒性的音频样本。LI等人[13]提出了对抗音乐的方法,并成功地欺骗了Amazon Alexa唤醒词检测系统。
1.3 威胁模型
可以针对音频领域中自动语音识别任务进行有目标的音频对抗攻击。给定一个音频输入x,目标是生成一个听起来类似于x的新音频x'=x+δ,但是f(x')=t。仅当目标模型预测的短语与攻击者选择的目标短语完全匹配时,攻击才会成功。选择攻击DeepSpeech模型,这是由Mozilla使用TensorFlow实现的开源语音文本引擎。该模型使用Mel频率倒谱(MFC)转换作为输入的预处理,然后是递归神经网络(RNN)使用LSTM[14]将音频波形映射到单个字符上的概率分布序列。与大多数以前的工作中使用的威胁模型一样,笔者假设白盒攻击设置,其中攻击者可以完全访问模型,并且知道模型的所有参数和体系结构。此威胁模型用于评估最坏情况下的系统安全性。
2 方 法
2.1 动 机
目前,针对ASR系统的最先进的音频对抗攻击来自CARLINI等人[3],他们通过求解式(2)来获得最小扰动,成功地攻击了DeepSpeech模型。该方法以可微的方式实现了MFC的预处理,并将l设置为Connectionist Temporal分类(CTC)损失[15],然后在整个音频输入上对其进行优化来获得对抗样本。找到最接近的对抗样本是困难的,因此,有必要找到一个合适的参数c来共同优化分类项lctc(f(x+δ),t)和扰动δ的范数。在约束优化的一般情况下,这种基于惩罚的方法是众所周知的一般准则。解决式(2)中最优化问题的主要困难是如何找到合适的参数c来平衡扰动δ和分类损失lctc。如果c太小,则增加的对抗扰动将非常小,但是生成的样本可能不是具有对抗性的。如果c太大,攻击总是会成功,但是添加的对抗扰动不是最佳的。此外,惩罚方法通常会导致收敛缓慢。在图像领域,CARLINI等人使用改进的二分搜索来选择c。这种方法可以找到最佳的c,但以降低攻击效率为代价。在音频领域中,c设置为固定常数。尽管它可以节省二分搜索带来的额外计算量,但由于针对ASR对抗攻击的内在复杂性,该方法仍然效率不高。此外,参数c的选择对于这种攻击的成功至关重要。
2.2 损失函数
根据在图像领域中生成对抗样本的经验和式(3)的定义,很容易找到在固定扰动范围内最差的对抗样本。在式(3)中,两个约束都可以用δ表示,并且可以使用投影梯度下降法(PGD)来优化所得的公式。 笔者依照CARLINI的设置,并将损失函数l设置为CTC损失。最终,优化公式为
(4)
可以使用标准的PGD方法来解决式(4)中的优化问题,构造目标音频对抗样本。 具体地,在每次迭代中,该方法基于攻击者选择的输出短语,对每个音频值在损失函数中执行梯度下降步骤,以使损失函数最小化。接下来,再将产生的扰动音频投影到可行解空间内(在每个原始音频预设的最大扰动范围ε内)。迭代过程可以表示为
xi+1=Clip{xi-α·sign(xlctc(f(xi),t))} ,
(5)
其中,α是步长,xi是第i次迭代生成的对抗样本。
坐在办公室里,我沉浸在悲伤中,怎么都提不起精神。“老师!”我突然听到一个稚嫩的声音,原来是班长来了,她手里还拿着一朵栀子花。她把手中的花递到我的面前,说:“老师,您不要不教我们了,我把这朵栀子花送给您,您笑一笑,不要生气了好吗?我们喜欢看您笑,您发脾气的样子我们好害怕。”
2.3 自适应的快速有目标攻击
尽管标准的PGD方法可以解决式(4)的优化问题,但发现生成的扰动大小和攻击成功率受到最大扰动预算和步长α的限制,即使对于凸优化问题,也不能保证得到一个最优解。如果扰动预算太大,则产生的扰动也将相应较大,使得人耳很容易察觉。如果扰动预算过小,则因为固定步长的设置可能导致梯度下降法在两点之间振荡,优化将不会收敛。
输出:音频对抗样本x'。
高校新进教师的岗位是不同的,一般包括科研岗、教学岗和行政管理岗三大类。不同岗位对教师的工作任务期待与专业素养也是不同的。科研岗的工作任务重点是承担科学研究任务,教师负责组建科研团队,指导学生从事科研项目,对其要求是具备科研创新能力;行政管理岗主要包括诸如班主任、科任教师、大队辅导员等等,这类工作的重点是帮助学生树立正确的人生价值观,关心学生的思想政治状况,加强学生心理健康教育和指导工作等,所需能力主要为人际交往与学生沟通的能力。而教学岗的教师要求最高,需身兼科研创新能力、沟通能力以及教学能力。
1.4.3 支气管肺泡灌洗液(bronchoalveolar lavage fluid,BALF)的收集、蛋白测定、细胞计数 对大鼠左肺进行支气管肺泡灌洗。用16G插管针气管插管,用注射器取1.5 mL无菌冷PBS行支气管肺泡灌洗术3次。收集的BALF于4 ℃离心机250×g离心10 min,留取上清液于-20 ℃冻存。用BCA法(试剂盒购自碧云天公司)测定大鼠BALF上清液中总蛋白浓度,以观察大鼠肺泡内蛋白渗出情况。操作方法严格按照说明书进行。
返回具有最小扰动的对抗样本xi
“意象”是中国传统美学当中的一个重要范畴,更是中传统艺术的本体与审美旨归。中国的舞蹈在这种“天人合一、虚实相生”的思想关照下蓬勃发展,形成了较为丰富的“舞蹈意象”理论。从《爱莲》到《稻禾》可以看出,在意象类舞蹈作品中基本的人物形象塑造手法是必需且重要的,但创新也同样是重要的,无论是中国传统古典舞还是现代舞中的意象类舞蹈作品,其中的人物形象塑造必定会朝着更加多元化,国际化的方向发展。
算法1A-FTA攻击。
此外,在产业升级改革的过程中,其上下游产业及与之相关产业的改革和升级,也需要考虑到。以农业为例,其涉及到的产业包括餐饮、零售业、物流业为例,服务业的转型与发展更具有灵活性,其转型考虑到的不仅限于如何满足供需调整要求,还需要突破市场化较高所带来的压力。
输入:音频样本x,扰动预算ε,迭代次数K,步长α,目标短语t,余弦下降函数cosine(·),调整扰动范数的超参数λ,ASR模型f(·),损失函数lctc(x,y)。
私人、个体医疗机构可以作为我国医疗体系的重要组成部分,是公有制医疗机构的补充和完善,不能与公有制医疗机构享有同等地位。在医疗领域,不能以市场经济的观念来对待公有制医疗与私营、个体医疗。生病、看病不能看作是商品,不能由市场来主导,不能通过价格竞争、独特服务,让私人或个体医疗来引导或冲击公有制医疗。
算法1描述了完整的攻击过程。从原始音频输入x开始,根据目标模型的预测结果迭代更新最大干扰参数ε。在第i次迭代中,如果xi仍然不是对抗样本,则通过公式εi+1=(1+λ)×εi来增加扰动约束ε;如果xi已经是对抗样本了,则通过x0←x,ε0←ε,αi←α公式:εi+1=(1-λ)×εi来减小ε的值。在两种情况下,都从点xi开始来进行式(5)的迭代操作,将扰动音频投影到可行解空间中,并得到xi+1。然后,通过余弦退火的方法减小步长α。
鉴于上述的缺点,提出了一种自适应快速有目标攻击(A-FTA)方法来解决这两个问题。首先,根据目标模型的预测结果动态更改A-FTA方法的最大扰动范数值,而不是像标准PGD这样使用一个预设的固定扰动约束。具体地,通过在原始音频x周围的最大扰动范围内投影对抗性扰动δ来约束规范。然后,根据二分决策的结果对范数约束值进行修改。如果样本xi在步骤i中不是对抗样本,则增加步骤i+1下的约束值;否则,会相应减少。其次,在优化过程中,动态调整步长,而不是固定不变。具体来说,在迭代开始时,将初始化较大的步长α,通过扰动范数约束ε的动态转换,可以快速找到成功的对抗样本。接着,随着攻击的不断迭代,更多的对抗样本成功生成,扰动范数约束值ε和步长α也在动态调节下变得越来越小。最终,可以成功生成具有微小扰动的对抗样本。
Initialize
Fori=0 toK-1 do
grad←xi(lctc(xi,t))
xi+1←xi-αi·sign(grad)
xi+1←clip(xi+1,xi-εi+1,xi+εi)
信息化管理是市政工程造价控制与管理的重要实现途径,而且我国政府也比较重视信息化,也相继推出了一系列的优惠政策来推动信息化管理的实施和信息化工程的建设。但在我国现阶段的实施过程中,往往会出现工程造价不能得到真正意义的普及,而其中则存在两方面的原因:①信息化工程造价居高不下;②缺乏完善、系统的工程信息化的配套政策;有很多市政施工单位的经营理念、施工方法技术、管理模式都比较传统,也比较落后,这也导致其管理机制比较僵化,很难适应当下社会;很多施工单位都没有进行信息化管理,也没有相应的技术水平,缺乏信息化管理系统等,这些都是信息化管理问题出现的原因。
对于所有实验,如果在迭代结束时未生成成功的对抗示例,则会记录最后一次迭代的次数和扰动。所有实验均在配备Intel Xeon CPU E5-2620 v4、64 GB内存和一个GTX TITAN XP GPU的Ubuntu 16.04工作站上进行。
Iff(xi+1)==tthen
εi+1←(1-λ)×εi
else
εi+1←(1+λ)×εi
end if
αi+1←cosine(αi)
其中,n表示数据点个数,ci和ui分别表示实际聚类标签和求得的聚类标签.δ(c,u)表示当c=u时,函数值为1;否则δ(c,u)=0.map函数将求得的聚类标签与实际标签进行映射,映射可采用Kuhn-Munkres(最大权匹配)算法[18]获得.ACC的值越大表示聚类越准确.
End for
关于婚姻无效的申请权利人,因情况而异。在俄罗斯,因未达到法定婚龄且未依法得到允许而结婚,当事人、当事人的父母、当事人的监护人、监护机构、检察官可以提起婚姻无效之诉。当事人已成年的,只能由其本人提出,删除了原来关于这种情况下也可由检察官提出的规定。[5](P599)在我国,未达到法定婚龄的一方及其近亲属可以提起婚姻无效之诉。
3 实验
3.1 数据集和评估指标
数据集:在实验中使用两个开源的语音数据集,Mozilla Common Voice (MCV)和LibriSpeech (LS)。对于MCV数据集,选择干净测试集的前100个音频样本以生成目标音频对抗样本,并从测试集标签中随机选择100个不正确的转录文本作为目标转录文本。对于LS数据集,从测试集中选择50个样本,并从测试集标签中随机选择50个不正确的转录文本作为目标转录文本。确保所选择的目标转录文本长度不会超过目标音频转录长度的最大值。为了保证攻击的多样性,根据音频帧的长度和目标文本的长度将攻击分为四类,即短到短,短到长,长到短,长到长。 所有音频样本均以16 kHz采样。表1中展示了原始短语和目标短语的示例。
能够用多种方法解题本是好事,值得提倡.但需要进行比较,找出最佳方法.就四则运算而言,竖式运算和长除法乃前人反复钻研的结果,已为学界所公认.学生必须集中精力于这样的标准方法,反复练习,以掌握运算技能.发现式数学用一些莫名其妙的方法挤掉了标准方法,结果学生什么也学不到.

表1 原始/目标短语示例
其中,[0,M]是有效输入的阈值范围。但是,由于约束f(x+δ)=t,是高度非线性的,因此,现有的基于梯度的算法很难直接求解式(1)。因此,研究人员将其表达为更适合优化的另一种形式[ 1,7],即
北医三院党委书记金昌晓向《中国医院院长》表示,“两个允许”充分考虑了医疗行业特点以及医疗机构人事管理的现状,“任何医疗服务的流程都涉及诸多环节,医院是各类岗位的综合体,各岗位都要充分发挥专业特长,为更高效、更优质的医疗服务贡献力量,夯实服务链条形成闭环是关键。”
3.2 实现细节
对于C &W实验,将c设置为0.1,1.0,10,100和1 000;相应地,将学习率设置为10,迭代次数设置为 5 000,分别对MCV和LS数据集进行攻击。在成功攻击的前提下,记录最小扰动的迭代次数及其对应的扰动值δ,用于计算平均迭代次数和dB δ。
细分问题度取决于我们的知识储备量,我们对一个事情了解得越多,越能把问题细分。因此作为妈妈的我们需要阅读大量儿童生理和心理发展以及社会文化等相关书籍进行知识储备。唯有懂得才能详细。
对于PGD实验,针对MCV数据集进行了评估。首先将最大扰动预算ε设置为300、500、800、1 000、1 500和2 000,固定步长α=10,以评估不同预设扰动对所产生的扰动的影响。然后,确定最大预设扰动,并将步长分别设置为10,20,…,100,以评估不同步长对所产生的扰动的影响。由于PGD的目的不是寻找最小的扰动,而是使模型预测短语和目标短语在最大允许扰动范围内尽可能相似,因此,将记录第一次成功攻击的迭代次数和扰动大小。
对于所提出的A-FTA方法,对两个数据集分别进行100、300、500和1 000次迭代的攻击,以证明攻击的有效性。在所有情况下,设置初始化参数:ε0=1 000,λ=0.2和α=20。在成功攻击的前提下,记录下最小扰动的迭代次数及其对应的扰动值大小。
xi+1←clip(xi+1,-215,215-1)
3.3 实验结果
(1) 对C &W方法的评估。为了说明所提出方法的有效性,笔者将A-FTA与C&W方法进行了比较。对于C &W方法,使用了作者发布的源码,并用与笔者提出方法相同的测试集进行了评估。表2显示了在不同c值的情况下5 000次迭代的评估结果。从表2中可以看出,随着分类损失值的比例增加,dB δ的值也逐渐增加,攻击成功率显著提高。Wer分别从最初的102.92%和135.23%降低到0.29%和0.00%,这表明随着c值的增加,预测短语与目标短语越来越相似。成功攻击所需的平均迭代次数也随着c的增加而逐渐减少。根据表2中的结果,选择c=1 000的结果作为基线与笔者提出的方法进行比较。
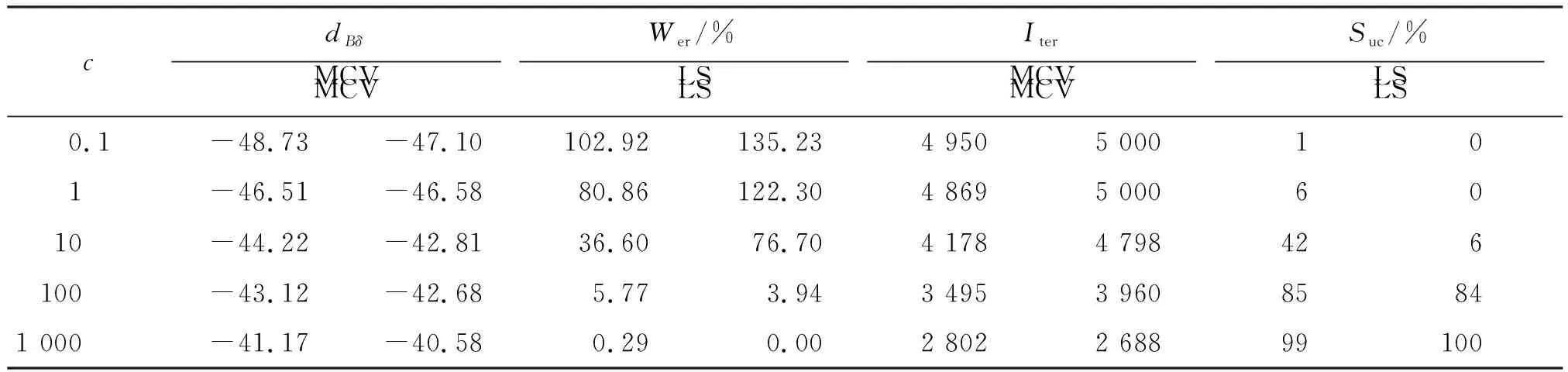
表2 不同c值的5 000次迭代评估结果
(2) 对PGD方法的评估。在这里,展示了在标准PGD攻击中常用的参数变动(步长,最大预设扰动)相对应的评估结果。对于最大预设扰动ε,将其设置为300、500、800、1 000、1 500和2 000,并固定步长α=10。从表3中可以看出,dB δ的值与ε呈正相关,而迭代次数与ε为负相关。不难理解,ε的数值越大,所产生的扰动也就越大,损失收敛的速度也会更快。两个值都在ε=1 000左右时,逐渐稳定。对于所有不同的ε值,PGD方法均达到了100%的成功率且Wer值为0%。C &W方法在dB δ上则要优于PGD方法。这是因为C &W方法的目的是找到具有最小扰动的对抗样本,而PGD的目的是在最大预设扰动中最小化损失函数,从而高效地获取成功的对抗样本。

表3 不同扰动预算ε的评估结果
对于步长α,选择ε=300和ε=2 000作为最大预设扰动,并设置α在范围10~100之间观察相应的结果。如表4所示,对于ε=300,随着攻击步长α的增加,生成的音频对抗样本的Wer值也不断增加,攻击成功率则持续降低。攻击所需的平均迭代次数有所波动,但总体上是逐渐增加的。因为最大扰动ε限制为300,所以样本的dB δ值几乎保持不变。对于ε=2 000,在所有不同步长α的情况下,攻击成功率均为100%,并且成功进行一次攻击所需的迭代次数也随着α的增加而降低,并逐渐趋于稳定。dB δ值则是逐渐增加,最终同样也趋于稳定。

表4 不同步长α的评估结果
从PGD方法的实验结果可以看出,通过这种方式生成的对抗样本受预设扰动和不同固定步长的影响。对于较大的预设扰动值,使用较大的步长可以在短时间内生成对抗样本,但最终会给音频样本带来更大的扰动。而较小的预设值虽然可使所生成的对抗样本的dB δ变小,使得人耳难以察觉,但是生成一个成功的对抗样本需要更长的时间,并不高效。
(3) A-FTA方法的评估。前两个实验的评估结果表明,标准的PGD方法可以在ε=300的设置下,通过250次迭代生成有效的目标音频对抗样本,但所产生的噪声大小和攻击成功率会受到最大扰动预算和步长选择的影响。
我们总是喜欢苛责别人的过错,用各种条件去要求他人,自己却不遵守准则。我们能轻易发现他人的错误,却很少能揪出自己的不足。这正是因为我们缺失了责己的自觉性。
在A-FTA的实验中,为了证明A-FTA方法的有效性,分别选择迭代次数为100、300、500和1 000次来评估攻击。实验结果如表5所示。对于MCV数据集,所提出方法的攻击成功率平均只需要迭代97次,就能达到98%的攻击成功率,且dB δ= -31.17,这与PGD方法在ε=300情况下进行了237次迭代的结果相近。随着迭代次数的增加,dB δ值逐渐减小。在仅迭代300次的限制下,dB δ值可以达到-44.00,要优于C &W方法中的-41.17,而这是该方法在平均迭代2 802次的情况下才得到的。在迭代次数仅有100次的条件下,A-FTA在LS数据集下依然达到了68%的攻击成功率,虽然低于MCV数据集的98%成功率,但依然远优于C &W方法。同样在迭代300次的限制下,达到了与C &W方法相近的效果。实验表明,A-FTA方法在不同数据集上都有着良好的攻击效率与效果,证明了笔者提出方法的泛化性。

表5 A-FTA评估结果
4 结束语
文中分析比较了两种生成对抗样本的方法,并提出了A-FTA攻击。这是一种高效快速可以生成具有最小扰动的目标音频对抗样本方法。实验结果表明,与当前最先进的方法相比,A-FTA方法在成功攻击原始音频样本的前提下,所添加的扰动更小,同时效率更高,需要更少的迭代次数就可以实现有目标攻击。同时,笔者提出的方法具有良好的泛化性,不受数据集的影响。
由于设备的限制,笔者并没有进一步尝试将该方法改进应用在物理攻击(如所生成的对抗样本在空气传播的过程中依然具有对抗性)中。但是,通过计算环境噪声转换的期望值,理论上 A-FTA方法可以轻松地应用于物理攻击。
在后续的工作中,将专注于不同类型的音频对抗攻击及其相应的防御方法的研究。
