结构状态覆盖导向的灰盒模糊测试技术
2021-01-29刘华渊苏云飞李瑞林唐朝京
刘华渊,苏云飞,李瑞林,唐朝京
(国防科技大学 电子科学学院,湖南 长沙 410073)
1 代码覆盖导向的模糊测试问题分析
代码覆盖率导向的模糊测试技术是一种灰盒模糊测试技术,其通过提高代码覆盖率来发现程序中的漏洞。AFL[1](American Fuzzy Lop)是典型的代码覆盖导向的模糊测试工具,FairFuzz[2]、AFLFast[3]等工具都是基于AFL实现的。AFL通过轻量级的代码插桩,在运行时收集程序代码覆盖信息,并以此为依据保留提升代码覆盖的种子文件。此类工具主要区别在代码覆盖率的计算方式、种子筛选和能量调度策略[4]等方面。灰盒模糊测试技术[5-8]和静态分析[9-10]、符号执行[11-13]、污点分析[14-16]等技术结合,能够有效地增加代码覆盖率。
以图1所示代码来说明笔者关注的问题。该代码来自于RHG比赛中的heap buffer over flow BRHG-A006。此类程序包含while-switch-case结构,不同的输入会导致不同的case语句被执行。

图1 BRHG-A006简化版代码
该程序依据opt的值执行不同的堆操作模块,包括堆申请、堆内存写、堆内存读、堆内存释放模块。漏洞触发条件为堆申请空间小于堆内存写空间。

图2 崩溃样本控制流图
图2给出BRHG-A006中触发堆溢出漏洞的一个最简化的崩溃样本的控制流图。add会分配0x20长度的堆块,edit可以往堆块中写入任意长度的数据。触发漏洞的状态覆盖条件并不复杂,但AFL、FairFuzz、AFLFast在一个小时内均无法发现存在的堆溢出漏洞。
1.1 测试用例的结构状态分布

1.2 基本块跳转作为反馈指标的局限性
基于AFL实现的模糊测试工具将基本块跳转的覆盖次数作为评价变异效果的指标。考虑两个结构状态序列长度为4的测试用例的执行迹 case1-case4-case2-case2 和case1-case2-case2-case4,这两个测试用例在AFL的测试用例评价策略中是等价的,因此后变异出来的测试用例会被丢弃。一些漏洞(诸如堆溢出、释放后重用等)状态激活时对内存状态有严格要求。在图1所示这类程序中,内存状态跟结构覆盖状态有对应关系,队列中种子的结构状态分布不均匀,导致模糊测试过程中总是针对少数几种特定结构状态进行变异。FairFuzz通过加大覆盖较少分支的变异次数来均匀化分支分布,提升总体代码覆盖速度,同样无法解决完全结构状态不均匀的问题。
使用AFL、FairFuzz对BRHG-A006(简化版)、BRHG-A007、BRHG-A0014测试24 h,并收集队列中序列长度为4的结构状态,结果如图3所示。
在图3中,(a)为BRHG-A006(简化版)、(b)为BRHG-A007、(c)为BRHG-A0014的结构状态覆盖对比图。在雷达图中,圆周上的坐标(如1222)表示测试用例的结构状态(case1-case2-case2-case2),半径标度为结构状态的覆盖次数。为了消除case语句中基本块数量不同导致的误差,将BRHG-A006(改)的代码中各个case的代码修改成完全一致,以保证基本块数量一致。不难发现,AFL和FairFuzz在队列中的结构状态覆盖分布不均匀,导致模糊测试过程中有价值的结构状态覆盖变异次数过少甚至被丢弃。收集全部变异产生的测试用例的结构状态序列进行分析,在队列内种子越多、代码覆盖越充分的情况下,新的结构状态覆盖种子被丢弃的现象越明显。
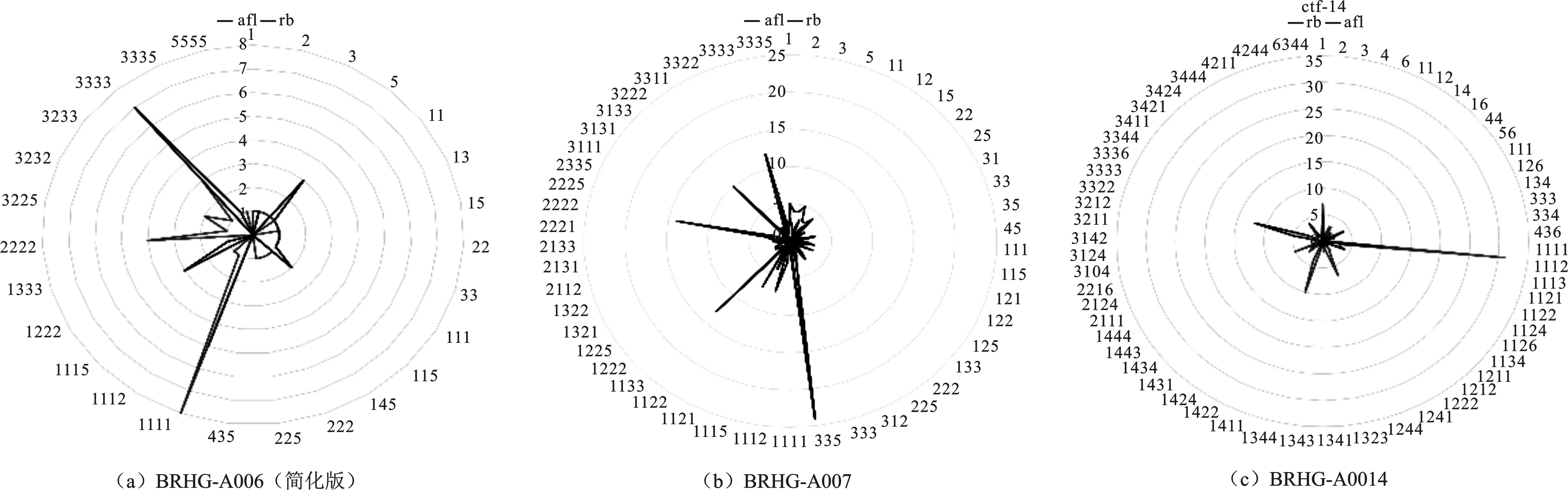
图3 用AFL、FairFuzz 测试24 h的队列结构状态覆盖对比图
1.3 特定结构的普适性分析
在DARPA公布的CGC测试集中,60个包含堆类型漏洞(51个堆溢出,9个释放后重用)中有12个程序是while-swtich-case结构,22个是while-嵌套if结构(可以转换成while-switch-case结构)。
真实软件中存在的一部分漏洞符合图1描述的代码结构特点,如 cve-2018-20623(use after free)、cve-2020-6224(heap based buffer overflow)、cve-2020-9273(double free)。这类程序包含对图片、音频的解析功能,涉及大量的堆内存申请访问释放操作。软件设计者出于代码复用的考虑,通常采用switch-case区分不同类型的文件格式。

图4 队列结构状态覆盖对比图
图4 (a)是jhead-3.03中AFL和FairFuzz测试24 h的队列中结构状态覆盖分布图。两种引擎的结构状态分布类似。受真实软件中程序功能限制,结构状态覆盖的雷达图分布无法成圆环状分布,分布优化目标呈圆弧状分布。图4(b)是CGC中Modern_Faimly_Tree 利用Angora[10]测试24 h的队列中结构状态覆盖分布图。此时程序总体的代码覆盖率仅为23%,switch结构只覆盖了20%。这种结构覆盖率不足的软件不能进行结构状态覆盖分析。
基于上述两个观察实验,需主要解决代码覆盖导向的模糊测试技术中的两个问题:
(1) 在代码覆盖足够的情况下,解决产生新的结构状态覆盖的测试用例被丢弃的问题;
(2) 结构状态覆盖变异次数不均匀的问题。
2 解决方案
对现有的代码覆盖率导向的灰盒模糊测试方法进行分析。通过对源码进行结构状态插桩分析和运行时统计结构状态覆盖分布分析,设计并实现了原型系统SFL,均匀化了程序状态分布,加速了漏洞发现过程。
2.1 源码结构状态插桩分析
程序中会包含许多的while-switch-case结构。为了避免switch-case嵌套导致的结构状态爆炸,每次只对一个目标结构进行插桩。插桩完成后获得一组目标程序,依据软件历史cve的补丁信息,优先选择包含历史漏洞的目标结构进行模糊测试。
转换while-if-else程序,在while-if-else结构中找到能够跳转回while语句的基本块,以此作为插桩点。
2.2 结构状态分布的统计度量
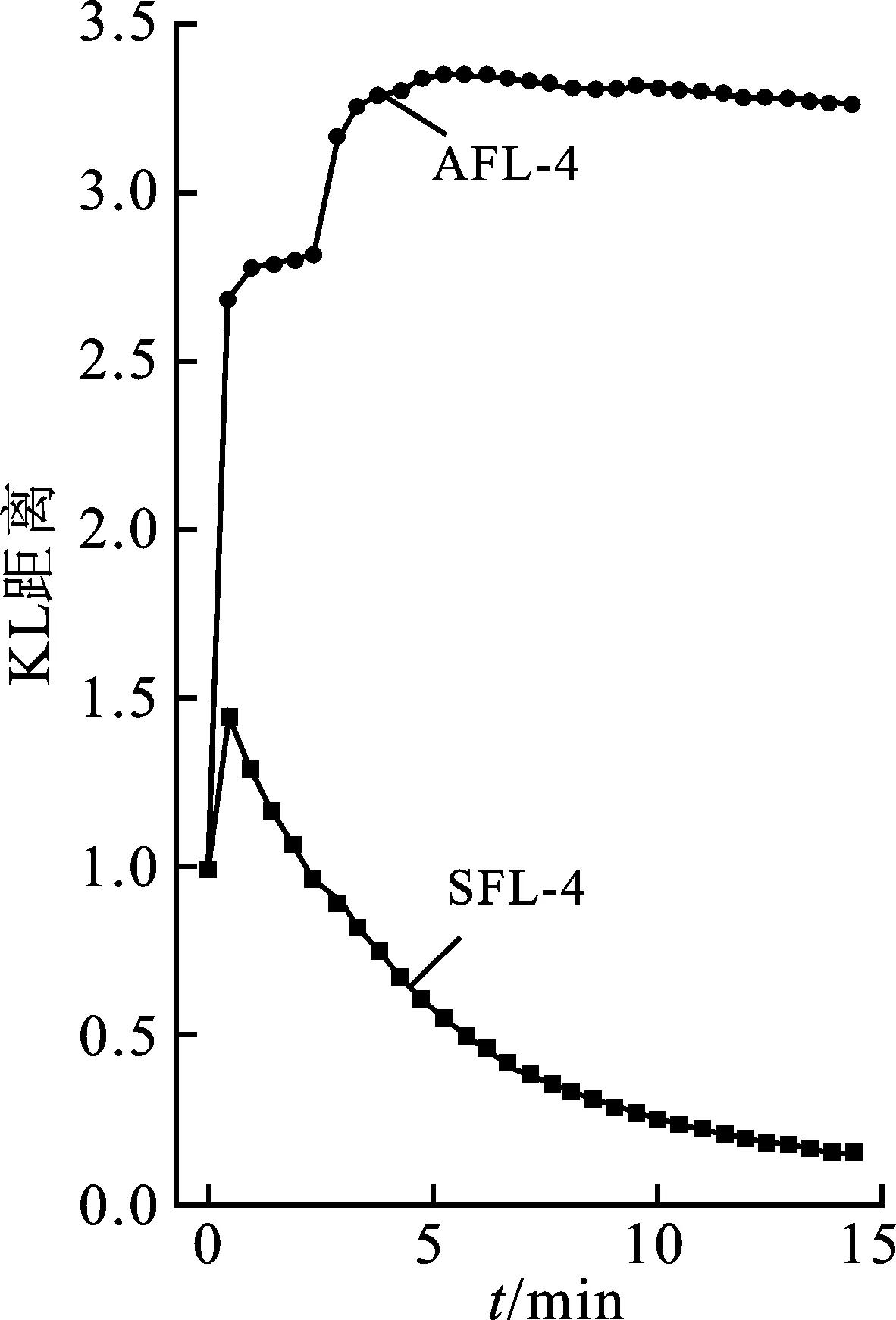
定义2给出了程序的结构状态分布的概念,现给出模糊测试过程中统计结构状态分布的方法。由于不同插桩点A:{ai}之间可能存在约束,因此程序的结构状态分布中随机变量X的个数N 对一个确定的程序P,很难预先分析出P的全体结构状态。因此,在一个模糊测试周期中,将概率分布为p(x′)的全体测试用例的结构状态空间X′近似为概率分布为p(x)程序的结构状态空间X,记均匀分布概率为Q(x)。使用KL(Kullback-Leibler)距离[17-18]衡量结构状态分布和均匀分布的差异: (1) 测试周期越长,全体测试用例的结构状态空间X′中随机变量的个数越多,X′越逼近X。即使在样本空间不断变大的情况下,KL距离也能够很好地描述结构状态均匀分布的差异。 在样本空间变化的过程中KL距离的变动特性:一般而言,发现新的结构状态会使KL距离突然升高,分布均匀化的过程就是KL距离逐渐降低的过程。 图5表示SFL的系统组成。在对源代码进行静态分析并标记出特定结构中的程序状态点之后,将收集结构状态覆盖的信息代码插桩到目标程序中。提供两种插桩的方式:结构状态覆盖和堆内存状态覆盖。在模糊测试的过程中,首先从队列中选取结构状态覆盖分布最少的种子作为候选者,根据全局结构状态分布补偿能量;然后通过变异生成测试用例,使用插桩后的目标二进制运行测试用例检查是否有新的状态覆盖和代码覆盖,通过检查的种子加入下一轮变异队列中。 图5 SFL系统结构框图 算法1表示插桩方式的具体细节。算法的输入是原始程序P和目标结构基本块集合T,输出是已插桩的程序P。插桩算法主要有两个步骤:① 使用共享内存case_map 记录目标结构的命中次数;② 使用Seq_map记录结构状态基本块跳转序列。所有的共享内存和序列长度被初始化为0(Line 1)插桩的具体实现流程,遍历所有的基本块,进行基础工具的插桩算法(Line 3)。首次遇见目标结构集合T中的基本块bi时,产生一个随机数Id作为不同结构状态点的标记(Line 5)。程序执行到bi时,case_map[Id]自增1(Line 6),随后在Seq_map的末尾插入当前基本块的id记录执行序列。 算法1结构状态信息收集插桩。 输入:原始程序P,目标结构集合T。 输出:已插桩程序P′。 ① Share_memory Seq_map,Share_memory case_map,Basick Block B,Sequence Length L。 ② For each﹤b0,…,bn﹥∈B do ③ AFL_Instrumention( ); ④ If bi∈T do ⑤ Id=get ID( ); ⑥ case_map[Id]+=1; ⑦ Seq_map[L]=Id; ⑧ L+=1; ⑨ End。 评估测试用例的目的是选取下一轮变异时的基准。在模糊过程中,代码覆盖导向和结构状态覆盖导向的切换时机非常重要。笔者采取的切换标准为全局case_map覆盖率超过80%时,开启结构状态覆盖导向模式。当使用AFL的评价标准要丢弃测试用例时,分析此测试用例序列状态。如果是新的序列状态,则加入下一轮队列中。 能量调度依据种子的结构状态覆盖分布分配变异机会。现有的代码覆盖导向的模糊测试采用如下方式分配能量[10]: E(i)=a(qi) , (2) 其中,i为等待变异的种子,qi为种子的评价得分。计算方式为种子长度、运行时间、代码覆盖等综合计算。SFL依据全局结构状态覆盖分布为种子提供补偿能量,计算方式如下: ec=ebα, (3) 其中,ec为异种子的补偿能量,eb为能量补偿基准,α为补偿系数。αi的计算方式为 αi=1-p(Xi) , (4) 其中,p(Xi)为种子的结构状态序列在全局变异中的分布比率。 为了验证笔者提出方法的有效性,基于AFL实现了原型系统SFL,并与AFL进行对比实验。 测试集选取bctf漏洞自动化攻防比赛中的赛题BRHG-A006、BRHG-A007、BRHG-A0014,测试时间为1 h,重复测试4次。测试环境为Intel Xeon 6154 CPU@3.0GHz(72核)和512 GB内存,64位Ubuntu 18.04 LTS系统。min KL距离的计算的基准分布为均匀分布,采样间隔为4 min,取4次重复实验的平均值,测试初始种子采用零种子测试(AAAA)。实验结果如图6和图7所示。 如图6所示,KL距离突然增高的原因是发现新的结构状态。在这种情况下,KL距离会随着时间逐渐平稳。实验数据表明,SFL能有效地稳定KL距离,使模糊测试过程中结构状态分布更加均匀,从而提升发现漏洞的速度,如图7所示。对于BRHG-A007和BRHG-A0014,SFL比AFL挖掘效果更明显。 为了验证方法的泛化性,选取libtiff-4.09软件中的tiff2pdf进行测试。为了满足路径覆盖率足够的要求,输入采用AFL进行120 h测试后产生的队列文件。测试时间12 h,测试结果如图8至图10所示。采样间隔为1 h。 图8表示SFL和AFL测试时的路径覆盖率随时间的变化趋势图。实验表明,笔者提出的方法对路径覆盖速度影响不明显,7.5 h后均达到分支覆盖最大值。 图8 AFL和SFL的分支覆盖率对比图 图10 AFL和SFL 的unique crash数量对比图 图9表示SFL和AFL测试时的KL距离随时间的变化趋势。这里与有效性验证实验采用的零种子不同,由于初始种子已经覆盖了目标结构,目标结构状态覆盖的调度更有助于发现漏洞。AFL的KL距离较低的原因是对大量不在目标区域的种子进行变异,因此初始值较低。KL距离的初始值高,则表明更多的能量分配给针对目标结构状态覆盖的变异上,这也是SFL能发现漏洞的主要原因。如图10所示,在实验中,SFL在7 h 30 min发现首个crash,而AFL没有发现,经人工验证,该crash是堆溢出造成的。 对Fuzzing模糊测试过程中种子收集方法和能量分配进行了改进,均匀化程序的结构状态覆盖,可以增强模糊测试对状态相关漏洞的挖掘能力。通过实验,证明这种方法能够有效地提高模糊测试中结构状态的覆盖均匀程度,加速漏洞挖掘速度。现有的模糊测试引擎擅长解决路径突破的问题,针对已覆盖的代码区域,没有考虑到结构状态覆盖的问题,导致很难发现一些与程序状态相关的漏洞。但是盲目地变异很难完成结构状态序列的增加,因此在下一步工作中,将与导向性的模糊测试集合起来,导向性产生新的结构状态覆盖。3 系统实现
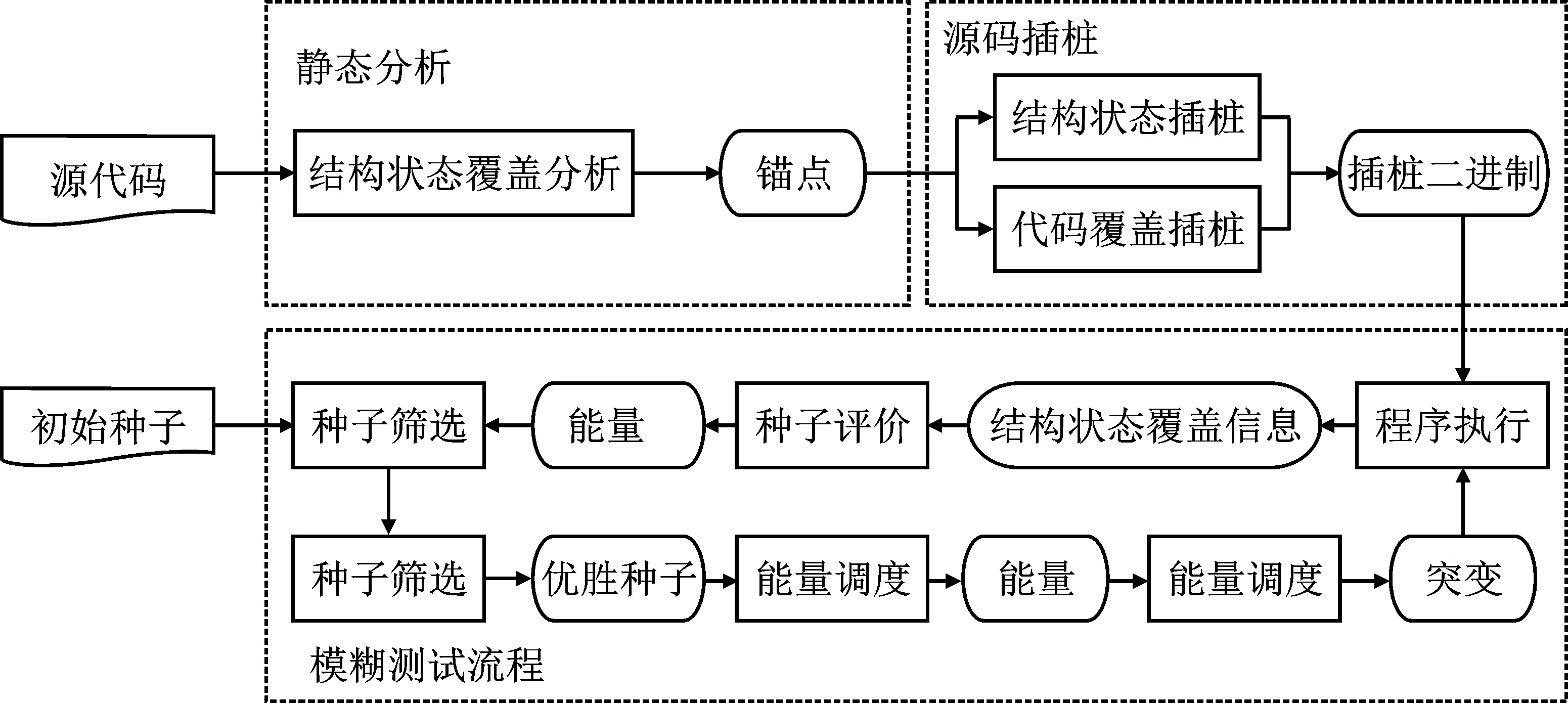
3.1 结构状态覆盖插桩算法
3.2 测试用例评估策略
3.3 能量调度策略
4 实验与评估


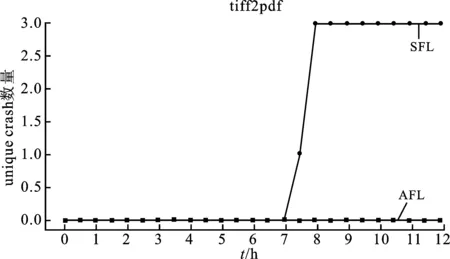
5 结束语
