一种基于依存句法和WRD 的句子相似计算方法*
2021-01-26石元兵金贵涛
周 俊,石元兵,魏 忠,金贵涛,郭 红
(卫士通信息产业股份有限公司,四川 成都 610041)
0 引言
在自然语言处理技术中,句子相似度计算是一项重要的基础研究技术,被广泛应用于很多领域。比如,在信息检索领域中,可以使用句子相似计算技术计算输入查询句的相似检索句子,从而得到更准确的检索结果;在敏感数据检测领域,可以使用句子相似计算技术来检测目标文档的句子与指定敏感句是否相似,从而判断目标文档是否是敏感文档。因此,句子相似计算技术的发展与很多领域的技术应用密切相关,成为自然语言处理技术中的一个研究重点。
目前,主要的句子相似计算技术可以分为以下几类。
(1)基于统计的相似度计算[1],即对两个句子的字、词语、短语等不同成分维度的不同特征(如字频、词频、TF-IDF[2]等)进行统计,统计结果越相近表示两个句子越相似。这种方法的弱点是没有考虑语义维度上的相似性。
(2)基于语义词典的相似度计算[3]。因为语义词典(如同义词词林、知网等)能够表征两个词语之间的语义相似关系,所以可以使用语义词典(如同义词词林、知网等)检测两个句子的语义相似词语。语义相似词语越多,表示这两个句子越相似。这种方法的弱点是语义相似词典的词语太少,无法满足层出不穷的新词语。
(3)基于向量空间模型的相似度计算,即把句子转化为向量来表示,从而使两个句子的相似计算转变为对应的两个向量的距离计算。常用的向量模型有VSM、LSA、Word2vec 等[4]。这种方法的弱点是假设句子中的所有词语都是独立的,没有考虑词语之间的内部关联。
针对上述3 种方法的不足,本文提出一种基于依存句法分析和Word Rotator’s Distance 语义距离技术的句子相似度计算方法。该方法首先使用依存句法分析技术对句子的词语进行依存关系分析,提取出句子中的主谓、定中以及状中等结构词语组成特征集,然后使用Word Rotator’s Distance 语义距离技术计算两个句子的特征集的相似关系。本文提出的句子相似度计算方法充分考虑了句法结构关系,消除了多词语混杂计算的弊端,能够充分理解句子的完整语义,且实验效果证明了其是一种比较准确的句子相似计算方法。
1 依存句法分析
句法分析是对句子进行分析以得到句子的句法结构或词语之间关系的处理过程。句法分析技术是语言理解的重要一环,也能够为其他自然语言处理任务提供支持。
最常见的句法分析任务可以分为两种。
(1)句法结构分析(Syntactic Structure Parsing),又称短语结构分析(Phrase Structure Parsing),也叫成分句法分析(Constituent Syntactic Parsing),作用是识别出句子中的短语结构以及短语之间的层次句法关系,用短语结构来描述句子语法结构并理解句子语义。
(2)依存关系分析,又称依存句法分析(Dependency Syntactic Parsing),简称依存分析,作用是识别句子中词语与词语之间的相互依存关系,用词语与词语之间的依存关系来描述句子语法结构并理解句子语义。
依存句法由法国语言学家Tesniere L最先提出。在依存句法理论中,句子成分之间普遍存在支配和被支配的关系,叫做依存关系。依存关系和语义紧密关联,可以反映出句子各成分之间的语义修饰关系,因此可以通过解析词语之间的依存关系来分析句法结构,实现对句子语义的准确理解[5]。
通常一个依存关系发生在两个词语之间。这两个词语构成了一个依存对:一个词语是核心词(Head),也叫支配词;另一个词语是修饰词,也叫从属词(Dependent)。依存关系通常用一个有向弧表示,叫做依存弧。依存弧的方向由从属词指向支配词。根据两个词语之间的不同句法关系,可以将依存关系细分为不同的类型。常见的依存关系类型如表1 所示。
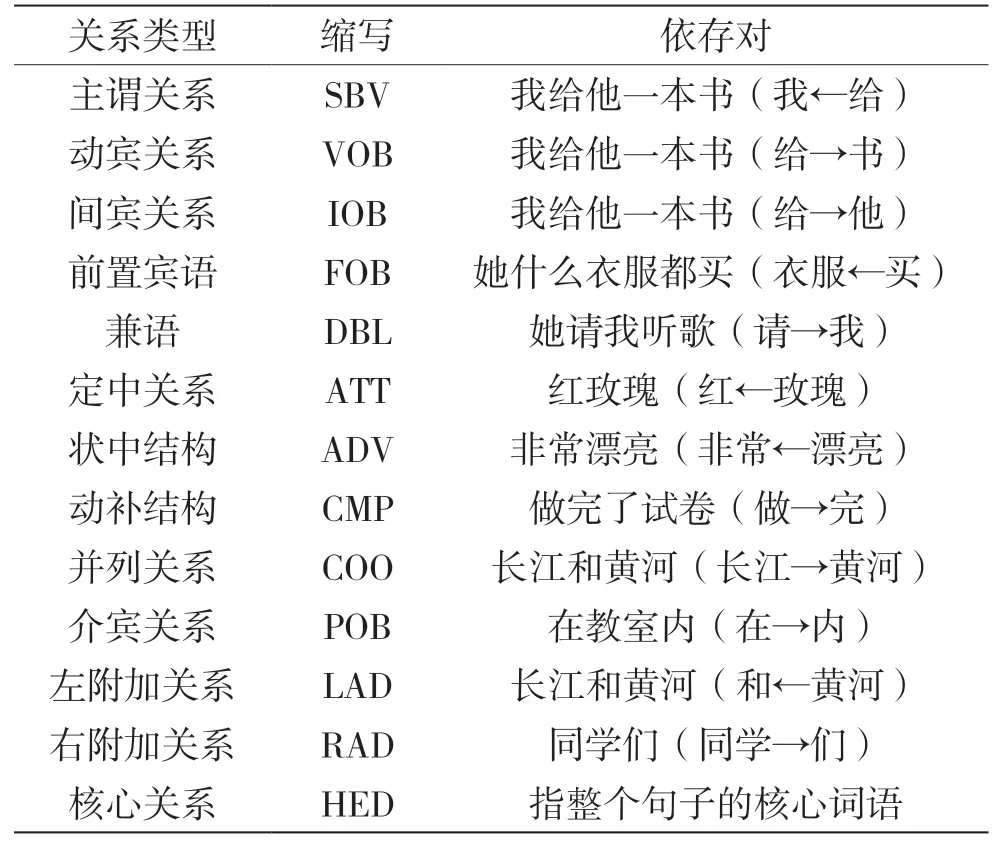
表1 常见的依存关系类型
与短语结构句法相比,依存句法具有以下优点:
(1)在依存句法中,所有的依存关系都是以动词为核心,能够突出句子中的核心词语;
(2)在依存句法中,依存关系强调了句子各词语之间的功能关系,更易于进行句子的语义表示。
例如,“句子相似计算是自然语言处理技术的一个重要研究方向”的依存关系图如图1 所示。
对应的依存关系如表2 所示。

图1 依存关系图例子

表2 依存关系例子
可以看出,对句子进行依存句法分析能够比较准确地反映句子的结构,且依存对的词语能够比较准确地反映出句子的语义。
因此,通过依存句法对句子进行语法结构分析后得到的依存关系和词语,能够用来进行句子相似计算。两个句子同类型的依存关系越多,每类依存关系的词语越相近,这两个句子就越相似。
2 WRD 语义距离
词语旋转距离(Word Rotator’s Distance,WRD)是2020 年Yokoi S、Takahashi R 等人提出的计算两个文档之间距离的方法[6]。WRD 是对词移距离(Word Mover’s Distance,WMD)算法的改进,是在词向量Word2vec 的基础上用来衡量两个文档相似度的算法。它综合两个文档中所有词语(去除停用词)来计算文档相似度,适用于文档相似度和短文本相似度的计算。
Word2vec 是2013 年谷歌提出的一种将词语表征为向量的工具[7],是目前应用最广泛的词向量技术之一。Word2vec 将词语表示为N维空间中的点。在该N维空间中点的距离可以表征词语间的相似度。距离越小,相似度越高。在Word2vec 词向量空间中能够展现词语的语义特性如:

可见,利用Word2vec 能够提取出词语的语义关系,为计算文本相似度提供了条件。
WMD 是于2015 年由Matt J.Kusner 等人提出的一种利用词向量计算多个词语之间距离的算法[8],用于表征两个文档之间的语义相似度(WMD 距离越大,文档之间相似度越小)。WMD 算法基于搬土距离(Earth Mover’s Distance,EMD)模型计算文档间的距离。EMD 模型是一种两个概率分布间距离的度量方式,一个典型的实例是运输问题,即从仓库1、仓库2 运送货物到用户A、用户B 最优运送方式的问题,综合考虑仓库货物的存储量、用户需求量以及仓库到用户距离,通过线性规划可以找出最小代价的运送方式。WMD 计算两个文档之间的相似度,是将文档A 中的词语视为货物,将文档B 中的词语视为用户,将词语间的相似度视为距离,将词语在文档中的权重视为货物的数量,以此将文档A 中的词语“转移”到文档B,使用EMD 模型求解最小的“转移”代价。“转移”过程如图2所示。
WMD 计算文档A 与文档B 之间距离的步骤如下。
(1)去除停用词。对文档进行分词,并去除文档中的停用词。
(2)计算词语权重。采用归一化词袋模型(normalized Bag-Of-Words,nBOW)计算文档词语权重,其中第i个词语词频权重表示为:

式中,ci表示词语i在文档中出现的次数。
(3)利用EMD 模型计算文档距离。依据前文对EMD 的介绍,使用EMD 模型需要先构建权重矩阵和距离矩阵。
①构建权重矩阵。文档的权重矩阵由文档中词语权重向量组成,在第(2)步中已经对文档词语权重进行了计算,记文档A 的权重矩阵为d∈Rn,文档B 的权重矩阵为d´∈Rn。
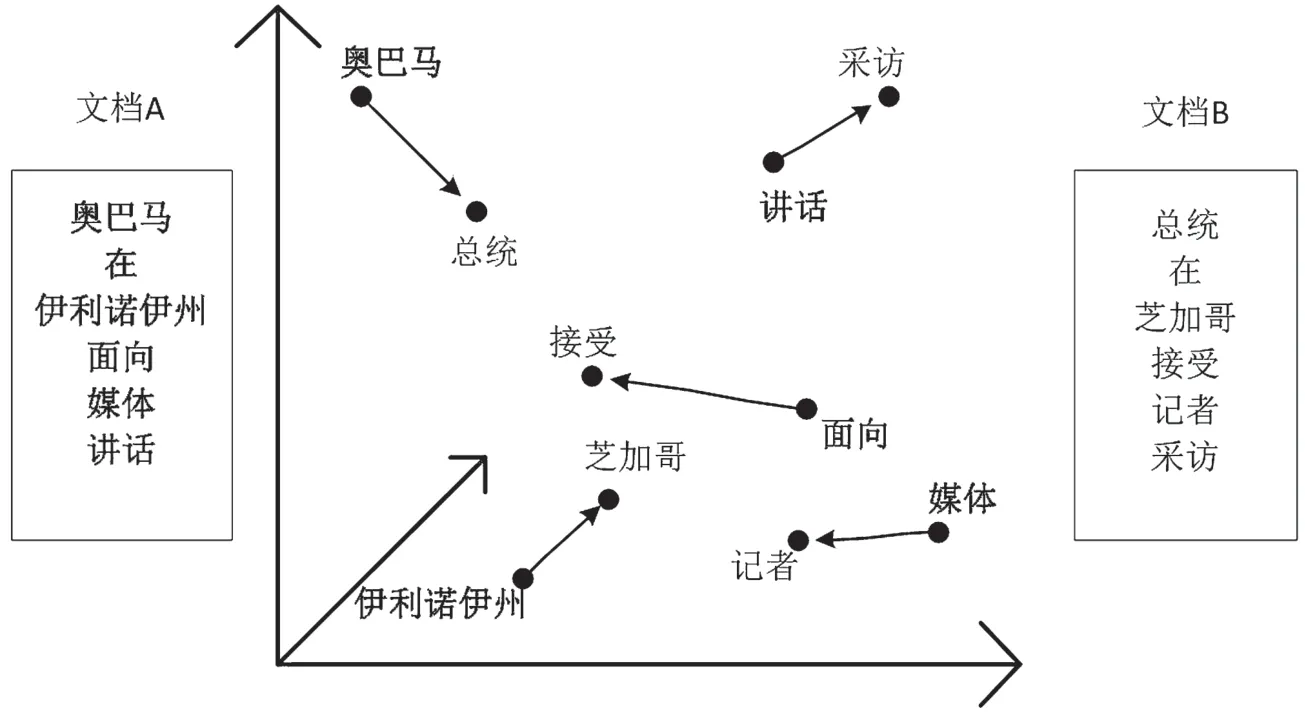
图2 WMD 例子
②构建距离矩阵。Word2vec 向量空间中提供了一种天然的距离计算方式,即欧式距离。记词语i到词语j的距离为:

式中,c(i,j)表示从一个词语i转移到词语j需要的代价。
记文档A 中词语i到文档B 中词语j的转移量为Tij≥0。为了使文档A 中的词语能够完全转移到文档B 中,则文档A 中词语i的转出量必须等于词语i自身的权重(仓库的出货量等于储存量),即:

同理,文档B 中词语的转入量必须等于自身的权重(用户的收货量等于需求量),即:

因此,文档A 到文档B 的距离为:

使用EMD 模型求解,可得文档A 与文档B 的距离。
WRD 算法在WMD 算法上做了两点改进。
(1)对权重矩阵的改进。在WMD 中以词频作为权重,而WRD 以词向量模长作为权重矩阵,即权重矩阵为:
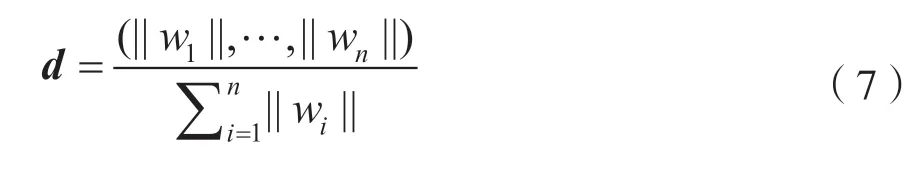
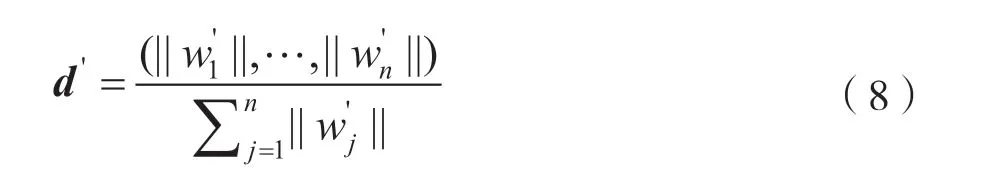
(2)对距离矩阵的改进。在WMD 中以词向量的欧式距离作为词语的距离,而WRD 以词向量的cosine 距离作为词语的距离,即:

改进后的WRD充分利用了词语语义上的特点,结合Word2vec 计算词语间的语义相似度,从而更大程度地挖掘了文档间的语义相似。WRD 以cosine距离作为距离的度量方式,使WRD 算法的取值范围为[0,2],利于文档相似结果的判断。
WRD 与WMD 对比如表3 所示。

表3 WRD 与WMD 例子对比
从表3 计算结果可以看出,WRD 语义距离在取值范围[0,2]之间,更便于进行辅助决策。
3 算法流程
本文提出的基于依存句法分析和WRD 语义距离技术的句子相似计算方法流程,如图3 所示。

图3 句子相似计算流程
3.1 步骤1:句法分析
对两个句子A、B 分别进行依存句法分析,得到各类依存关系的依存对。例如,句子A 的主谓关系依存对SBV_A、句子A 的定中关系依存对ATT_A 等,同一类型的依存对可能会有多个。例句A“数据安全是信息安全领域的一个重要环节”、例句B“对敏感数据进行识别和保护是数据安全的一个重要研究方向”,对应的依存对如表4 所示。
3.2 步骤2:提取词集
提取每个依存对中的支配词和从属词,组成各类依存关系的支配词集(Word set of Head)和从属词集(Word set of Dependency),如表5 所示。
3.3 步骤3:计算WRD 语义距离
分别对两个句子的同一种依存关系的同类词集进行WRD 语义距离计算,如果支配词集或者从属词集的WRD 语义距离小于某个阈值(一般设置为0.8),表示支配词集或者从属词集相似,则这两个句子具有部分相似的该种依存关系;如果该种依存关系的支配词集或者从属词集都相似,则这两个句子之间具有完全相似的该种依存关系。

表4 例句A 与B 的依存对
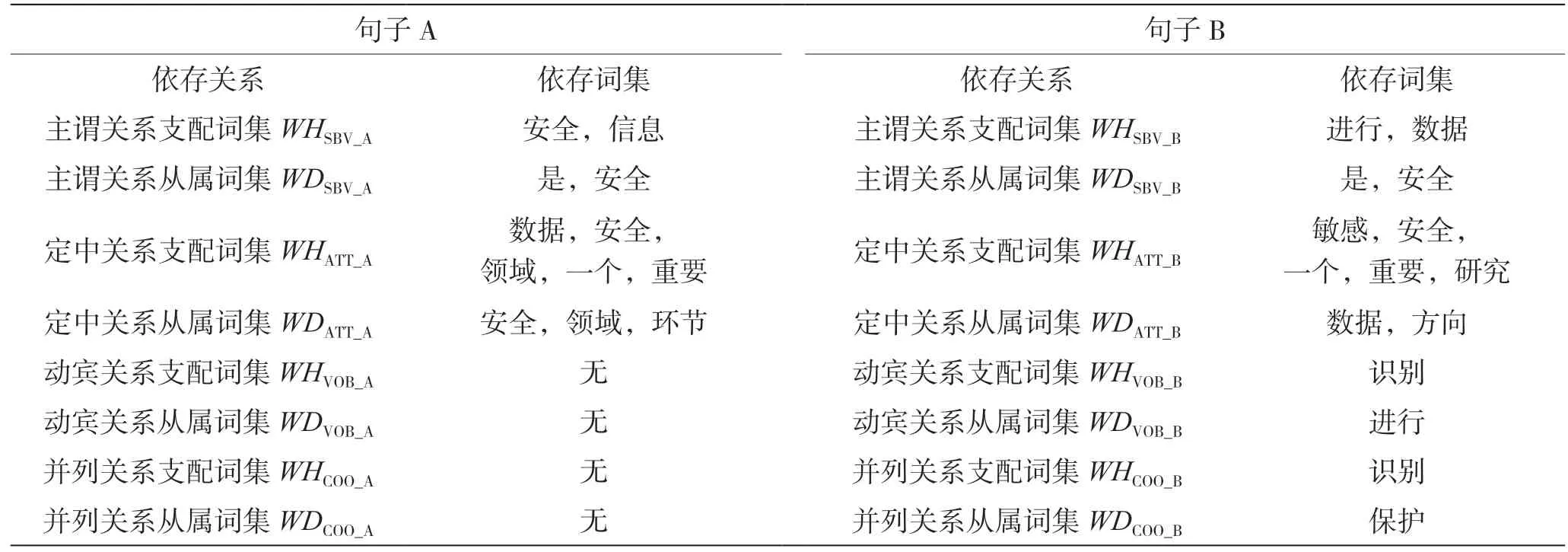
表5 例句A 与B 的依存词集

表6 例句A 与B 的依存词集相似结果
3.4 步骤4:句子相似指数
通过对大量语言材料的统计分析发现,不同类型句子进行相似技术应该重点关注不同的依存关系,如在对政府报告、技术报告、科技文献等比较正式场景的语言材料要较多关注主谓、动宾、间宾等依存关系,而在对新闻、社交等比较非正式场景的语言材料要较多关注定中、附加等依存关系。因此,本文给每个依存关系词集设计了一个权重,可以根据业务要求进行调整,初始值都为1。将相似依存关系词集的权重值进行累加,并根据式(1)计算得到一个介于0 和1 之间的句子相似指数Indexsim。句子相似指数越接近0,表示两个句子越不相似;越接近1,表示两个句子越相似。

例句A“数据安全是信息安全领域的一个重要环节”和例句B“对敏感数据进行识别和保护是数据安全的一个重要研究方向”,都是从科技文献语言材料中摘取出来的,因此将主谓关系支配词集和主谓关系从属词集的权重都设置为2,其他权重保持不变,得到两个句子的相似指数:

它表示句子A 与句子B 之间部分内容相似。
4 实 验
下面讨论本文的技术方法与前文论述的3 种方法的比较。
4.1 实验数据说明
本文实验数据选取两个教育新闻进行相似计算,使用维基中文百科和新闻语料训练的具有超800 万词语量的词向量模型。
文件1:“针对最近我国赴比利时留学人员接连发生入境时被比海关拒绝或者办理身份证明时被比警方要求限期出境的事件,教育部23 日提醒赴比利时留学人员应注意严格遵守比方相关规定。据记者了解,发生以上问题的主要原因是:部分留学人员未能按大学或者语言培训中心录取通知书规定的时间报到,在入境时被比海关扣留,一旦学校答复不予注册,就被拒绝入境;有的留学人员听信网上发布的信息或传言,花钱购买所谓‘合法’经济担保,办理身份证明;有的甚至使用假经济担保办理身份证明,比政府有关部门发现查证后,留学人员被要求限期离境。为防止类似事件再次发生,教育部提醒赴比利时高校或者语言培训中心学习的留学人员,必须严格遵守比利时的相关规定,要按照通知的入学注册日期到学校报到。如果因故延迟,请事先与学校联系并获得批准。另外,不要轻信网上或者其他人发布的可以‘有偿提供合法经济担保或合法身份证明’的信息,以免遭受不必要的损失。”
文件2:“在3 月24 日的法国文化开放日活动的留学专题讲座中,法驻穗总领事馆文化处文化教育领事穆沙琳、法国驻华大使馆语言与学术评估中心CELA 广州地区主任沈伊莎贝尔、法国教育国际协作署广州办事处负责人刘媛媛就有关留学法国进行解答。据介绍,法国的留学政策会优先考虑理工科、商科或管理类专业、硕士及硕士以上学历以及校级交流和获得奖学金的学生。虽然去法国读书的大部分是经济类专业的学生,艺术类专业学生也不少,这些学生法国都欢迎,但更欢迎理工科学生。法领馆的人士强调,对学生没有明确的分数线要求,主要看各个学生的具体情况。有关人士表示,面试时会了解学生在中国读书的情况、专业,去法国留学的计划,希望拿到一个什么样的文凭,以后想找什么样的工作,从事什么职业等。据介绍,有的学生到法国后可能会换专业,法国方面会考虑学生本身的条件,看他选的专业对不对,并提出一些建议。”
4.2 实验分析
本实验使用句子相似计算中3 种常见方法TFIDF、语义词典、词向量加权平均以及本文提出的依存句法+WRD 方法进行相似度计算,结果如表7所示。

表7 4 种句子相似结果对比
从表7 的结果来看:TF-IDF 和语义词典的相似结果错误,因为这两种方法都无法准确度量相似词语;词向量加权平均虽然得到了正确的相似计算结果,但是相似计算得分不高,因为这种方法对所有词语一视同仁,没有考虑不同句法结构上的词语应该区别对待;依存句法+WRD 方法得到了较高的相似计算得分,体现了这两个文档的高度相似关系。
5 结语
准确的句子相似计算对数据安全业务非常重要,可以给分类、自动摘要等应用提供准确的决策辅助。本文通过融合依存句法分析技术和WRD 语义距离技术,设计了一种增强的句子相似计算方法。实验结果表明,该方法得到的句子相似结果更加准确和全面,能够为数据安全防护应用提供更好的辅助决策和更全面的业务分析手段。
