基于卷积神经网络的短文本情感分类①
2021-01-22樊粤湘
代 丽,樊粤湘,陈 思
(浙江理工大学 经济管理学院,杭州 310018)
随着Web2.0 和移动设备通讯地不断发展,越来越多的人喜欢在微博、购物网站等社交平台上参与互动与交流,互联网上的文本信息也因此呈现出迅猛增长的趋势.大量文本信息通常体现了个人的观点和情感的表达,若能够利用分析技术准确挖掘出其中所包含的信息价值并充分利用,无论是对国家在舆情控制方面还是对企业在决策制定方面都有着巨大的作用.因此,在当前充斥着海量文本数据的网络环境下,文本情感分析是一项十分重要的工作.
面对文本情感分析问题,很多学者都提出了十分有效的方法.根据研究的思路不同,主要可以分为基于情感词典的方法和基于机器学习的方法[1,2].基于情感词典的方法需要构造一个较为完善的词典对文本特征词进行情感色彩地判断,比较适合应用于传统的规范性文本,而对于网络上的频现新词和缩略词的短文本分析效果则不够理想,需要耗费大量的人力、时间以及财力等诸多成本去更新、维护词典;而基于机器学习的方法则需要人工构造特征,无法得到文本包含的句法和语义信息,是一种较为浅层的研究方法,无法学习复杂的函数,泛化能力较弱[3,4].随着互联网中的海量文本信息和语言多样化的表达的变化,以上这两种方法已经难以有效地解决企业决策的需求了.在2006年Hinton 等人提出了深度学习方法经过改进以后能够较好地弥补上述方法的缺陷,它是一种端到端的技术,无需人工参与便能够以大脑处理信号的机制自发的从原始数据中学习到特征信息,从而从更高层面上对文本进行抽象表达[5].深度学习还被广泛地运用到中文分词[6]、机器翻译[7]等NLP 领域中.Kim 首次运用深度学习中的卷积神经网络模型(Convolutional Neural Network,CNN)实现了英文文本的情感分类,实验的最终效果要明显优于传统的机器学习算法[8].文献[9]在普通CNN基础上提出了动态池化,构建了DCNN 模型来学习句子结构以优化情感分类器的性能.文献[10]在CNN 模型中引入注意力机制(Attention Mechanism)构建WACNN模型,在MR5K 和CR 数据集上证明了此方法可提高模型的情感分类准确率.文献[11]将CNN 模型同长短期记忆神经网络模型(LSTM)进行结合,采用了联合深度学习方法对影视评论进行情感分类,此方法对训练语料存在着极大的依赖性.文献[12]研究了不同表达方式的文本对CNN 模型情感分类性能的影响.
基于以上分析发现,很多学者在基于CNN 模型进行改进后对文本进行情感分类研究时只考虑了特征词语语义信息对文本情感分类的作用,而忽略了词语本身所具备的与情感信息紧密相关的特征影响,如词语本身的情感色彩、词性等.此外,对于中文文本数据的研究都需要经过分词操作,不同于英文文本中各词语以空格形式隔开,中文文本中各词语是连接在一起的,这就导致对中文文本分词时存在着分词错误的问题,从而进一步影响词向量的训练质量.因此,本文将在经典CNN模型的基础上,提出了一种融合情感特征的双通道卷积神经网络模型SFD-CNN (Double channel Convolutional Neural Network model fused with Sentiment Feature),在设置实验文本数据的向量化的同时考虑了文本特征词本身的情感信息和分词错分的影响,从而获取更多的情感信息,以期在情感分类任务中达到更好的分析效果.
1 词向量模型
在使用相关算法对文本数据进行情感分类时需要先把文本转换成数值型使其能被工具识别.在进行文本数值化表示时应当满足以下要求:该表示方法既可以很好地表示文本语义内容又可以将各文本内容区别开来.目前,常用的文本表示模型有布尔模型、向量空间模型(Vector Space Model,VSM)以及词向量模型等[13].布尔模型较为简单,也容易让人理解,但是其只关注某项特征是否在文本中出现过,而忽视了其与上下文词语之间的相关性;向量空间模型在一定程度上表达了特征词项间的语义信息,但其维度大小同文本特征集个数线性相关很容易造成维度灾难.Hinton 提出的Word Embedding (词向量)方法正好弥补了上述方法的不足.
词向量主要思想就是将词语从高维稀疏的空间中映射至低维空间,并在这一过程中充分考虑词语的语义信息,非常适合用来表示文本的抽象特征[14].2013年,Google 工程师Mikolov 等人将词向量训练工具Word2Vec进行了开源,由此词向量逐渐为人们熟知.Word2Vec中主要包含了两种训练词向量的模型:CBOW 模型与Skip-Gram 模型,这两种模型都是基于Bengio 的3 层神经网络语言模型NNML 而提出的.相比于NNML,Word2Vec 对词向量的训练结果进行了一定的优化,同时还通过采用Negative Sampling 或Hierarchical Softmax等方法使得模型的计算复杂度在一定程度上得以降低[15].CBOW 模型与Skip-Gram 模型都是由3 层结构构成:输入层、映射层和输出层,其模型结构如图1所示.

图1 CBOW 和Skip-Gram 模型
从图1可以看出,CBOW 模型是以输入某一词语的上下文词向量来计算词向量的.而Skip-Gram 模型的思想则与CBOW 模型相反,其是通过输入某一词语向量来计算出其上下文词语的词向量.但它们总体上的思想相同,即上下文相似,其目标词汇也会相似[16].
2 融合情感特征的双通道卷积神经网络情感分类模型
综合考虑现有的情感分类研究常常忽略特征词本身所携带情感信息和中文分词总存在着被错分两方面问题,本文对经典CNN 模型加以改进,构造了一个融合情感特征的双通道卷积神经网络情感分类模型,以期在情感分类任务中达到更好的效果.具体的改进措施如下:首先在预先训练好的语义词向量上加入该特征词语自身所携带的情感信息特征,使得融合后的特征词向量更能准确表达其所含有的情感信息;然后在原有的CNN 模型基础上构造出另一条输入通道,并把相应的以中文文本中最小单位字为基础训练出来的字向量为输入源,以使模型能够在解决分词错误问题的同时又能进一步地从不同方面提取到更多的有用信息特征.
2.1 融合情感特征的词向量
以词向量表示的文本所包含的原始文本信息是CNN模型进行情感分类的基础,为了进一步丰富词向量所携带的文本情感信息,本文将在词语的语义向量 上引入会对文本情感类别判定产生一定影响的诸如词语的情感极性、词性等相关情感特征,形成融合情感特征(sentiment feature)的词向量.对于额外的情感特征信息本文将使用一个 维的向量 来表示,各维度分别代表着某一情感特征属性,而且只有0、1 两个取值,0 表示该词语没有该维度相对应的特征,1 代表的含义则与0 相反.其中,各情感特征设计方法如下.
1)词语情感极性特征.词语情感极性特征是针对那些本身就能够表达某些情感的词汇.因为词汇所携带的情感信息在一定程度上会影响句子的情感倾向性.对于词语这一情感特征的提取,本文主要是依据情感词典.而情感词典的形成主要是以现有情感词典资源为基础,然后向其中加入一些未包含在内而在网络中进行商品评论时又常用的情感词语,具体形成过程如图2所示.
2)词语词性特征.在无监督的情感识别或抽取的任务中,许多学者通常都是以形容词、动词、副词、名词及其相应的短语作为特征来展开研究的.涂海丽也指出上述词性的词语在对中文文本进行情感分析时发挥着十分重要的作用[17].所以本文也将以上谈及的词性纳入词语的情感信息特征当中,并借助jieba 分词中的词性标注功能对实验文本数据在进行分词的同时也进行词性的标注,然后在构造情感特征向量时对词语的这些特征进行数值化表示.
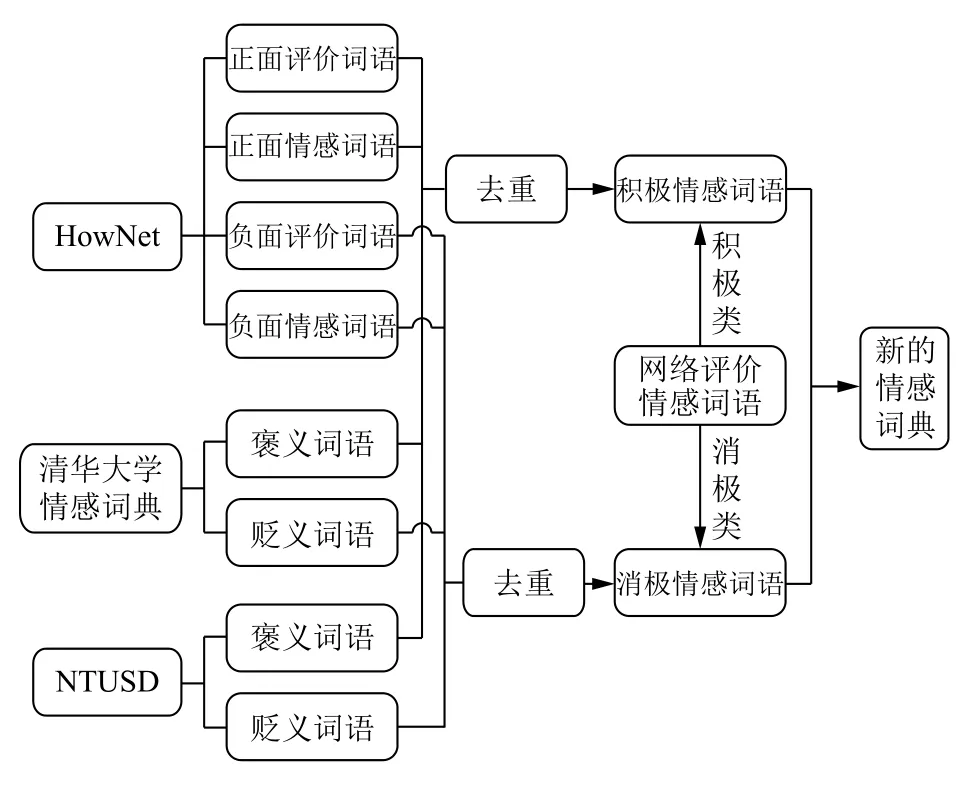
图2 新情感词典形成过程
3)否定词特征.否定词语在情感分析任务中发挥着十分重要的作用,它的使用甚至能使文本情感倾向发生彻底转变.对于否定词的判别,本文将借助HowNet情感词典中的否定词表.
4)转折词特征.包含有转折词的评论文本语句通常表达的情感信息都是不单一的.转折词将文本分成了前后两个部分,它们所要表达的含义往往是相对或者相反的,而且后部分分句一般才是表达者的重心.邸鹏等也通过实验证明了对转折句式的考虑提高了基于NB 算法的情感分类器的精度[18].因此本文将转折词也作为词语的情感属性特征,并结合文本语料整理出常用的转折词表.
经过前文内容的分析,代表特征词项 额外的情感特征信息向量可以简单地被表示成一个8 维的向量:[积极情感词,消极情感词,形容词,副词,动词,否定词,转折词,名词],而各维度下的具体取值则分别代表着该特征词项x是否拥有此情感属性:取值为1 说明其本身具备有此属性,取值为0 则相应地表示其不含有此属性.词语情感特征向量xsen的示例如图3所示.

图3 词语情感特征向量示例图
得到词语的情感特征向量后,便需要将其与相应的词语语义向量进行融合.本文采取前后串接操作将两者融合,得到拓展后的词向量xexpand.具体的表达式如式(1)所示.

其中,x可通过词向量模型训练文本语料库后获得.
2.2 字向量
对于字向量xunigram的获取,同样采用词向量模型对分词后的评论文本数据进行训练,不同的是此处的分词操作不是将评论文本划分为由若干词语构成的序列,而是将它们划分成了由一个个单独的汉字构成的序列.经模型训练后便可得到这些单字词汇相对应的字向量,其中字向量的维度大小与相对应文本的词向量维度保持一致.
2.3 模型结构
在前面两小节的介绍下,本文基于卷积神经网络算法所设计的情感分类模型结构如图4所示.模型由输入层、卷积层、池化层以及输出层构成.

图4 SFD-CNN 模型结构
1)输入层:此层的作用主要是将评论文本数据用Word2Vec 训练出来的向量数值化,在本文所提出模型中主要表现为将评论文本分别转换成融合情感特征的词向量矩阵xexpand和字向量矩阵xunigram,并把它们分别作为模型两个通道的输入.在此次研究中,由于评论文本集经过预处理后最大的文本词序列长度为215,转换为单个字序列的最大长度为446,因此设置n=215,N=446,v的具体取值则依据文本向量化后的维度而定.若假设文本向量化后的维度取值为100,则设置v=100.对于文本长度低于设定数值的其他文本序列,本文将进行后向补零操作,使其等于规定的长度.
2)卷积层:卷积层的作用就是通过对输入的文本矩阵进行卷积运算获取能够代表文本信息的特征,降低向量的维度.在经典的CNN 结构中,该层一般只含有一种类型的卷积核,由于本文研究的是文本数据,前后的特征词语都存在着一定的联系,为了能够同时获取不同粒度下文本所表现的特征,本文将在模型各通道下的文本矩阵上使用窗口大小不同的卷积核组合.如在图4所示的模型中采用的是窗口大小分别为3、4、5 的卷积核组合对评论文本进行卷积操作.
3)池化层:池化层是以卷积层输出的特征图为输入的,本文在该层分别对两个通道下的特征图进行最大池化处理,得到更低维度的文本特征,然后将两个通道下池化后的文本特征进行拼接形成最能代表文本的最终特征向量.
4)输出层:输出层的功能则是根据池化层输出的最终特征向量对文本进行情感类别的划分,本文在此层主要是将池化层后得到的特征图以全连接的形式进行连接然后输入到Softmax 分类器中,将文本分别划分为积极情感和消极情感两种类别.
此模型分类结构在预先训练好的语义词向量中融入了情感信息特征,从特征词本身所携带的情感信息和正确识别中文分词方面出发进行了改进和综合分析,即在原有的CNN 模型基础上构造了另一条输入通道,并把相应的以中文文本中最小单位字为基础训练出来的字向量为输入源,以使模型能够在解决分词错误问题的同时又能进一步地从不同方面提取到更多的有用信息特征,从而得到了在情感分类任务中更好的预期效果.
3 实验及分析
3.1 实验环境
本文在进行情感分类实验时的环境主要如下:操作系统是64 位的Windows 10 家庭中文版,CPU 为Intel core i5-8250U,RAM 为8 GB,使用的编程语言为Python3.6,主要涉及到的类库有Tensorflow、sklearn、numpy 等,开发工具为Pycharm.
3.2 实验数据
在本文此次研究中,所使用到的数据可分成两部分:一部分是用来训练和测试情感分类器模型的评论文本数据,并且带有情感色彩标注.另一部分则是用来训练词语语义向量的大规模无标记的Wiki 中文数据集.其中,评论文本数据是通过Python 语言编写相应爬虫程序从京东商城的官网上获取的,主要包括了手机、笔记本电脑、水果、书籍、服装、洗发水6 个领域的评论文本,共有12 000 条,并且各领域下积极评论和消极评论都为1000 条;而Wiki 中文数据集是从Wiki官网上下载的中文压缩包,大小为1.64 GB.文献[19]指出使用大规模的文本语料集训练出来的词向量较符合中文语言模型;文献[20]也表明通过此种方法训练出来的词向量可以使模型的性能得到有效改善.因此,本文将使用Word2Vec 工具中的Skip-Gram 模型训练Wiki 中文数据集以获得高质量的词向量,然后以此对评论文本中的特征词项初始化.
经过对语料库的训练后,便可以得到相应维度下的词语特征语义向量,各词向量间在语义上具有一定的关联性.如在维度为100 的情况下,根据训练后的词向量模型,可获取到词语“购买”的语义相似词列表和对应的相似度,具体如表1所示,该词语的向量表达如图5所示.接下来,则在语义向量的基础上根据2.1 小节介绍的方法构造融合情感特征的词向量,同时根据2.2 小节的介绍使用Skip-Gram 模型训练评论文本的字向量.
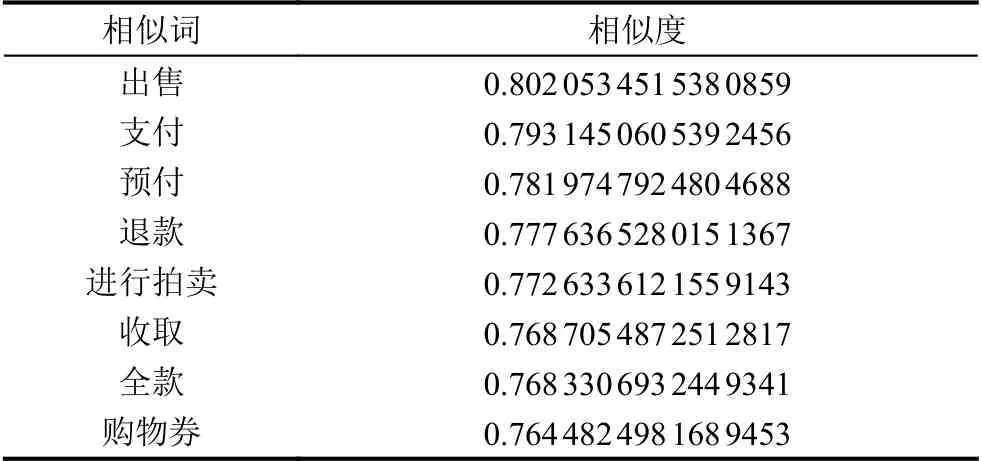
表1 “购买”语义相似词列表
图5 “购买”词向量表达式
3.3 实验参数
实验时对模型中各个参数值的设定直接影响着实验结果,为了使模型达到较好的性能,就需要对模型中的各个参数进行不断地调整与优化.表2展示了本文在进行调优时的各参数取值范围和最终的取值.其中,参数取值范围表示在研究卷积神经网络模型不同参数对中文文本情感分类效果的影响时所取的数值,模型参数值则是依据网格搜索的调参方法得到的本文所提出模型分类准确率最高时的取值.各参数在本文实验数据集中的表现具体如图6所示.
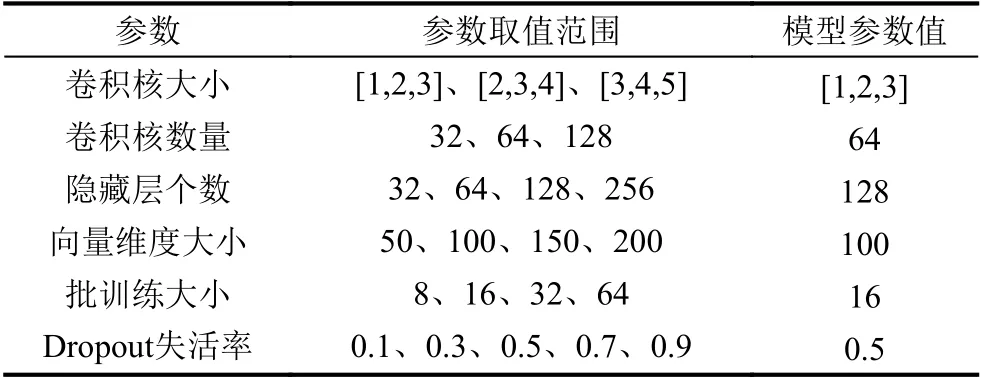
表2 模型参数
3.4 实验设置及结果分析
为了验证本文所提出模型的有效性,本小节将依据传统的卷积神经网络模型、融合情感特征信息的卷积神经网络模型、双通道卷积神经网络模型以及本文所提出模型在相同的评论数据集上进行文本情感分类实验,而且各模型的参数值设定一致,如表2所示.此外还会将经典传统机器学习方法支持向量机的实验结果纳入对比分析范围中.其中,各模型的实验介绍如下所示:
1)支持向量机模型:记为SVM.此模型的输入文本以预先训练好的词向量初始化.
2)传统的卷积神经网络网络模型:记为CNN.此模型为典型的CNN 模型,只有一个输入通道,并使用本预先训练好的词向量对实验文本数据初始化.
3)融合情感特征信息的卷积神经网络网络模型:记为SF-CNN.此模型结构同典型CNN 一致,但在对实验文本数据进行初始化时会加入文本特征的情感信息.
4)双通道卷积神经网络模型:记为D-CNN.此模型具有两个输入通道,其中一个输入通道初始化文本数据的方式同CNN 模型,另外一个则以预先训练好的字向量来初始化文本数据.
5)本文所提出模型:记为SFD-CNN.此模型结构与D-CNN 相同,其中一个输入通道的文本初始化方式同SF-CNN 模型,另一个通道则是以预先训练的字向量来初始化文本.
上述模型在同一评论文本数据集上进行十折交叉验证,并以10 次实验结果的平均值来衡量模型的情感分类性能,最终的实验结果如表3所示.

图6 模型参数取值对准确率的影响

表3 不同模型情感分类实验结果
为了更为清晰地表达各实验结果的对比情况,将表3中的数据图形化,具体情况如图7所示.其中,Precision+代表积极类文本的精准率,Recall+代表积极类文本的召回率,F1+代表积极类文本的F1 值;Precision−代表消极类文本的精准率,Recall−代表消极类文本的召回率,F1−代表消极类文本的F1 值;Accuracy 代表文本的整体准确率.
结合表3和图7的实验结果可知,常用的传统机器学习方法中基于词向量的SVM 模型情感分类性能最差,而且比同样基于词向量的CNN 模型准确率低了2.15%.这是因为CNN 模型比SVM 模型具有更高的学习能力,可从词向量中提取到更为抽象的深层次语义信息.可见,本文提出使用卷积神经网络模型对中文短文本进行情感分析是有效可行的.对比CNN 和SF-CNN 两个模型的结果易知,融入特征词语情感信息的SF-CNN 模型性能相较于CNN 模型有所提升,其在F1+、F1−和准确率上的取值分别高于CNN 模型的1.14%、0.67%、0.45%.这表明在文本特征词语的语义向量中融入的情感信息在模型进行情感分类时为其提供了额外的有效信息,使模型能够提取到更为有用的、辨别情感类别的文本特征.对于双通道输入的D-CNN 模型来说,其F1+、F1−和准确率分别为92.54%、92.38%、92.47%,所达到的情感分类效果也要优于CNN 模型,主要是由于该模型从字向量方面在一定程度上弥补了中文分词错误对模型带来的不利影响,而且以双通道的形式输入文本信息,可以提取到更为全面的敏感信息.进一步,从图7中易知,SFD-CNN 模型的情感分类性能最为优越,无论是在F1+、F1−的值上还是准确率上,其值都要比其他模型大.这说明综合考虑SF-CNN 模型和D-CNN 模型的改进之处可进一步提升情感分类效果.与最初的CNN 模型相比,其F1+值提高了2.07%,F1−值提高了2.32%,准确率提高了2.19%.

图7 各CNN 模型实验结果对比图
4 结论
本文针对在情感分类研究中传统机器学习模型的缺陷,提出使用深度学习中的卷积神经网络模型来实现对短文本的情感分类,同时也针对以往研究中文本情感特征提取的不足以及忽视分词错误对情感分类的影响,对经典的卷积神经网络模型进行改进,提出一种融合情感特征的双通道卷积神经网络模型SFD-CNN,并设置对比试验,将其与CNN、SF-CNN、D-CNN 以及SVM 模型进行比较.最终的实验结果表明SFDCNN 模型的情感分类性能最优,无论是准确率还是F1+、F1−值都要高于其他模型.由于本文所使用的CNN 模型都是单层结构,无论是卷积层还是池化层都只有一层,所以接下来可以进一步研究多层结构的CNN 模型对文本情感分类的效果.
