基于高斯混合聚类的风电出力场景划分①
2021-01-22张发才李喜旺樊国旗
张发才,李喜旺,樊国旗
1(中国科学院 沈阳计算技术研究所,沈阳 110168)
2(中国科学院大学,北京 100049)
3(国网金华供电公司,金华 321001)
近年来,中国风力发电发展速度快,风电场的规模以及风电并网比例不断增大.与传统的发电方式相比,风力发电最根本的不同点在于其有功出力的随机性、间歇性和不可控性[1].由于地理地貌和季风变化影响着风电资源分布,风电出力的随机性变化具有一定的季节周期性[2],用典型场景集反映周期内风电出力的变化特征,对含有风电电力系统的规划和调度具有重要意义.
目前,风电出力典型场景的选取主要采用聚类划分方法.文献[3]介绍了聚类算法大致可以分为层次聚类算法,划分式聚类,基于密度和网格的聚类算法和其他算法.文献[4]提出基于改进K-means 聚类的风电功率典型场景.文献[1]采用改进的模糊C 均值聚类算法和分层聚类算法,实现对风电出力场景的选取.文献[5,6]采用K-means 算法对风电出力样本进行聚类划分,得到具有代表性的典型风电出力场景.文献[7]提出基于Wasserstein 距离和改进 K-medoids 聚类算法,构建覆盖调度空间的典型场景.文献[8]提出主成分分析法和分层聚类算法相结合的方法,计算出年度典型风电出力场景.文献[9]采用模糊C 均值聚类法,完成对所研究区域风电功率典型场景的提取.
以上聚类算法都是以欧氏距离作为样本相似度判断,欧氏距离能反映样本曲线间的远近程度,不能反映曲线形态的相似程度.文献[10]提出基于考虑序列互相关性的“形态距离”的聚类算法,并提取春,夏,秋,冬的风电出力典型场景,避免了基于欧式距离聚类的缺点.文献[11]比较得出GMM (Gaussian Mixture Model)聚类质量优于层次聚类,K-means,K-medoids,SOM 聚类.文献[12]提出基于高斯混合模型的公交出行特征分析.文献[13]通过应用高斯混合模型对伊朗西南部某水域进行分区,取得很好的效果.文献[14]提出基于EM 和GMM 的朴素贝叶斯岩性识别,结果表明高斯混合模型有很好的拟合效果.文献[15]采用GMM聚类进行汉语数字识别.此外,GMM 聚类不仅具有灵活的类簇形状,还能够很好的捕获属性之间的相关性和依赖性[16].
本文提出了一种基于概率分布的高斯混合聚类模型GMM,通过样本属于某一类的概率大小来判断其归属类别,本文选取某地区的风电出力情况,与传统的基于欧式距离的聚类算法的划分结果对比分析,验证本文提出的风电出力场景划分方法的有效性.
1 基于高斯混合聚类对风电出力场景的划分方法
1.1 高斯混合聚类模型
高斯混合模型是由有限个独立的多元高斯分布模型线性组合而成,每一个多元高斯分布成为混合高斯模型的成分,而多元高斯分布则是一元高斯分布在高纬度空间中的扩展[17].
假设一天内每个小时的风电功率为xi(i=1,2,···,24),则高斯混合模型可以表示为:
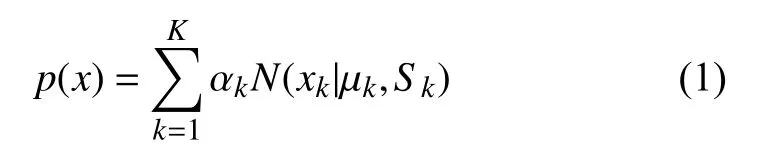
高斯混合模型有3 个参数需要估计,分别为µ,α和S,其中,µ 表示模型的期望,α表示各个分布的权重,S表示模型的方差.
上式可化为

下面采用最大似然法(EM)进行参数估计.
算法步骤如下:
(1)指定µ,α 和S的初始值.
(2)计算后验概率γ (znk):

(3)求解µk的最大似然函数:

(4)求Sk的最大似然值

(5)求解 αk的最大似然函数

(6)循环重复计算步骤(2)~(5),直至算法收敛.
1.2 最佳聚类数目确定方法
对于最佳聚类个数确定,GMM 聚类往往是采用BIC 准则[18].贝叶斯信息准则(Bayesian Information Criterion,BIC),1978年由Schwarz 提出,用于实际中选择最优的模型,如式(7):

其中,k为模型参数个数,n为样本数量,L为似然函数,kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象.
对于K-means 聚类,采用肘部法则和轮廓系数相结合的方法确定最佳聚类数目.肘部法则的核心指标是误差平方和(Sum of the Squared Errors,SSE),如式(8):
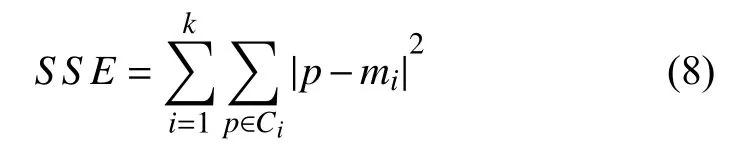
其中,Ci是第i个簇,p是Ci的样本点,mi是Ci的质心,SSE是所有样本的聚类误差,代表了聚类效果的好坏.
当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数
轮廓系数是类的密集与分散程度的评价指标,如式(9):

其中,a表示样本到彼此间距离的均值,b表示样本到除自身所在簇外的最近簇的样本的均值,s取值在[−1,1]之间,如果s 越接近1,代表所在簇合理,如果s越接近−1,s应该分到其他簇中.对于使用轮廓系数确定聚类的数量,应该选取较大的轮廓系数.
2 实验和结果分析
风电出力通常具有明显的季节分布特性,与单风电场相比,一个地区的风电功率具有更明显的季节性规律.
首先选取某地区2017年至2019年3年春季3 个月的每1 小时实测地区风电出力数据进行分析,验证该方法的有效性,然后再对该地区其他季节风电出力特性进行分析.
2.1 最佳聚类数目确定
使用BIC对高斯混合模型进行选择,既涉及协方差的类型,也涉及模型中聚类的数量.如图1所示,其中spherical,tied,diag,full 分别对应球面协方差矩阵,相同的完全协方差矩阵,对角协方差矩阵,完全协方差矩阵,GMM 应选择聚类数目为4 的和相同的完全协方差矩阵.
针对K-means 聚类,综合考虑SSE和轮廓系数,如图2所示,蓝色曲线表示SSE随着k变化的曲线,红色曲线表示轮廓系数随着k变化的曲线.一般来说,平均轮廓系数越高,聚类的质量也相对较好.在这,最优聚类数应该是2,这时平均轮廓系数的值最高.但是,聚类结果(k=2)的SSE值太大了,根据肘部法则,当k=4 时,SSE的值会低很多,但此时平均轮廓系数的值较高.因此,k=4 是最佳的选择.
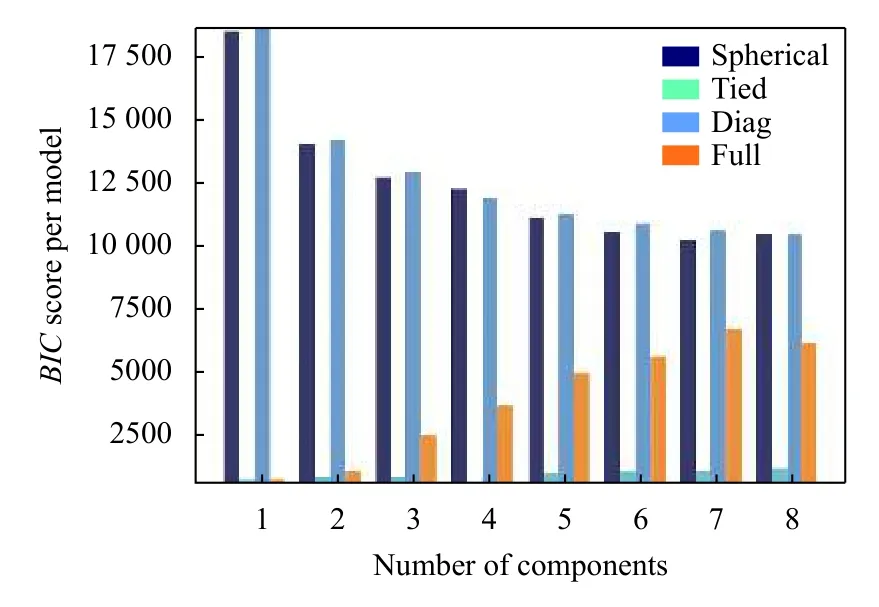
图1 混合高斯模型参数选择

图2 K-means 聚类模型的k 选择
2.2 基于概率的聚类划分
图3中,红色曲线为聚类中心,代表该地区风电风力的典型场景.在4 种形态的样本簇中,每一簇的风力出力功率范围明显不同,大部分的类内样本都与聚类中心相似,只有少数曲线的形状与中心曲线的形态不同.
2.3 基于欧式距离的聚类划分
采用K-means 聚类算法对同一组数据进行聚类划分,得到的风电出力曲线簇如图4所示.
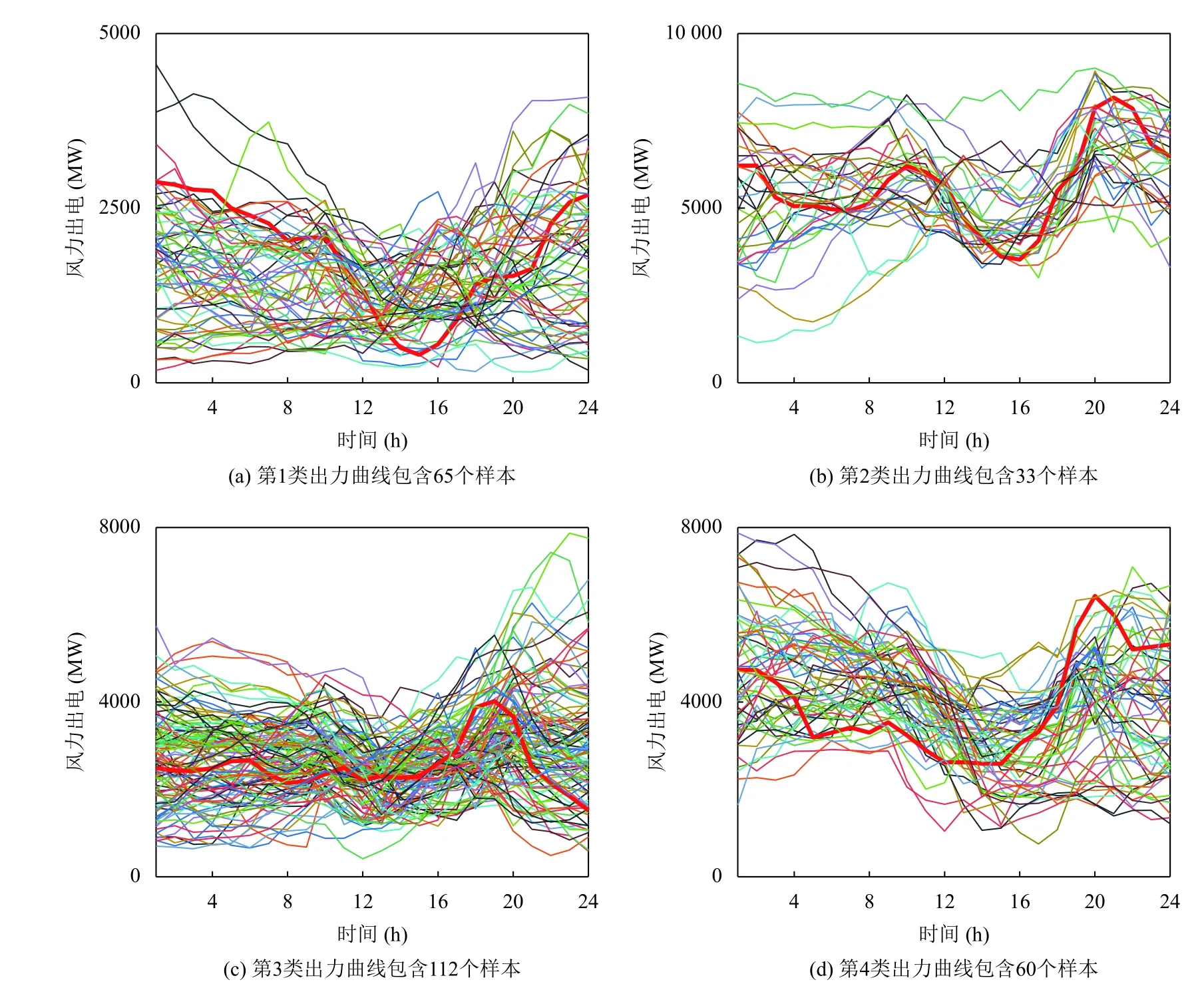
图3 4 类风电出力曲线簇(GMM)
红色曲线为聚类中心,代表该地区风电风力的典型场景.如图4所示,类内包含多种形态的出力曲线,很多曲线形态与聚类中心曲线形态不一致,仅能反映出风电出力的幅度大小.
为进一步比较这两种聚类方法,分别提取其聚类中心曲线.
在图5中,从峰谷差分布范围来看,基于K-means算法风电功率峰谷差分布范围集中在1700-3300 MW之间,不能反映出风电峰谷差特点,对调度安排实用价值较小.基于GMM 聚类算法风电功率分布范围从2400-4600 MW 之间,较能反应该地区风电峰谷差波动范围.
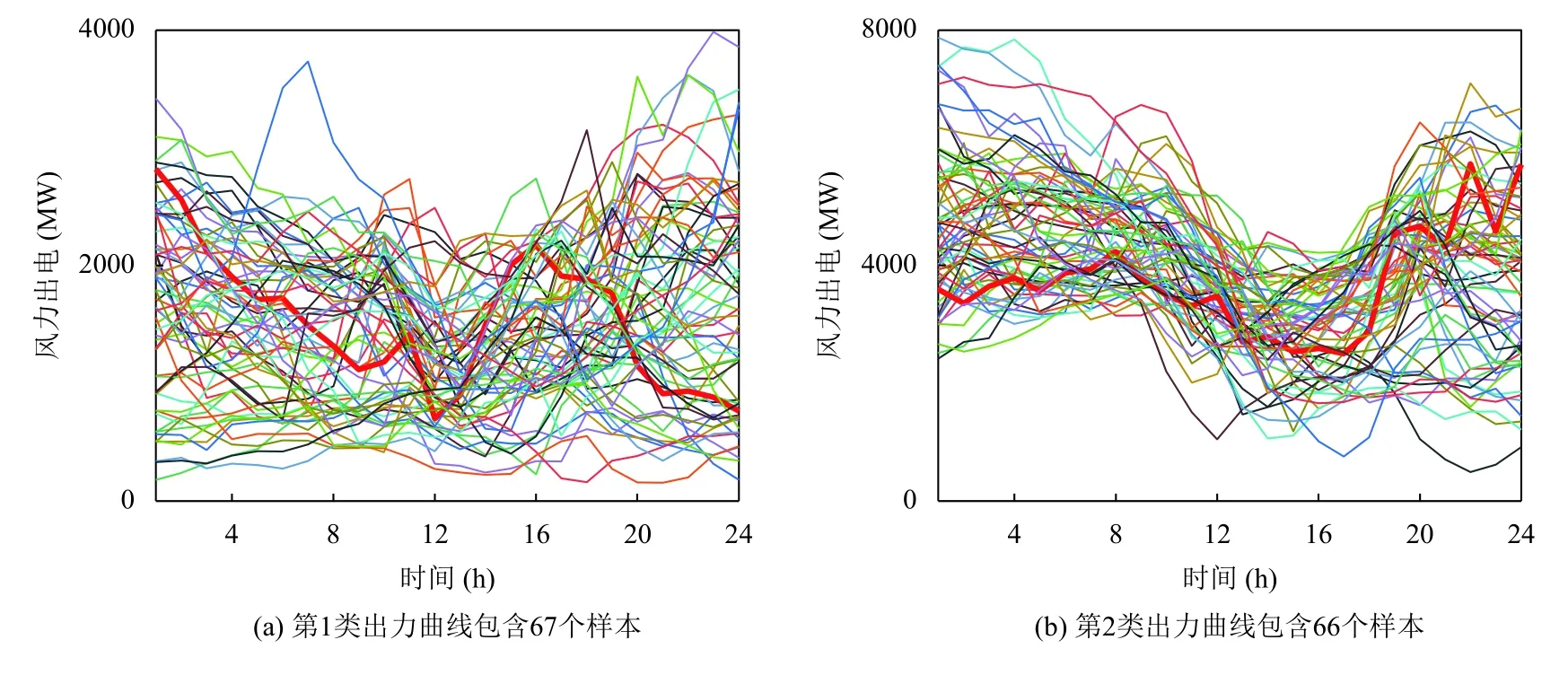

图4 4 类风电出力曲线簇(K-means)

图5 GMM 与K-means 聚类中心曲线对比
从功率波动范围来看,K-means 波动范围较小,不能反映某些情况下风电的大范围波动特点、多峰谷特点(如GMM 第2 类出力)以及正反调峰特点(K-means风电波动特征选取较差).
3 其余季节风电出力场景
对于夏、秋、冬季节,使用BIC对高斯混合模型进行选择,得到最佳聚类数目应为3.提取这3 个季节的风电出力场景,图6到图8分别为夏、秋、冬季的场景曲线簇,其中,红色曲线代表该季节风电出力的典型场景.


图6 夏季地区风电出力场景曲线簇
由图9可知,该地区夏秋季节风电出力功率较大、功率波动范围分布变化较小、功率波动范围较大,夏季上半日相比秋季风电波动较小;冬季风电波动与春季相似,但呈现多峰谷特点更加明显.
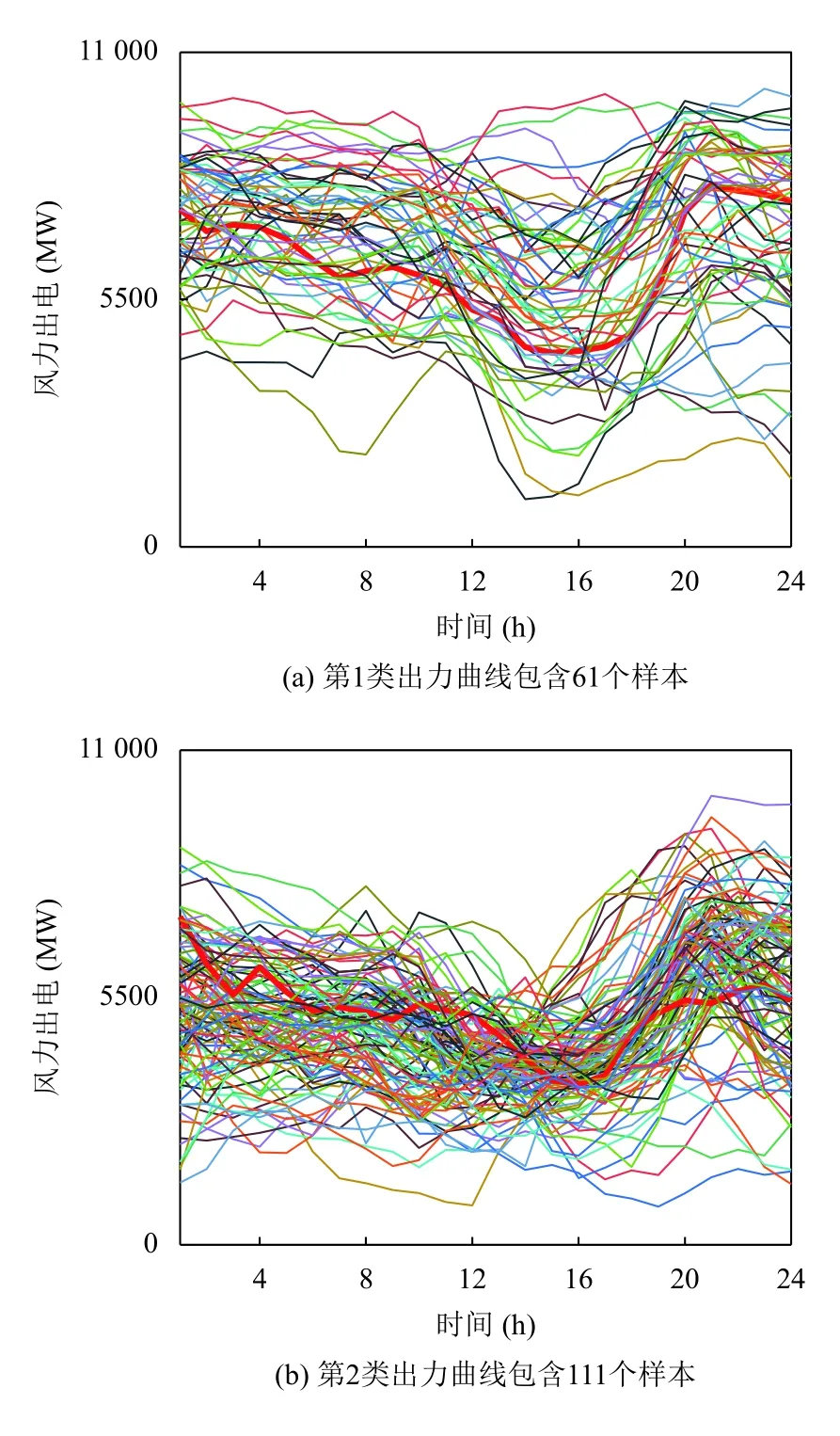
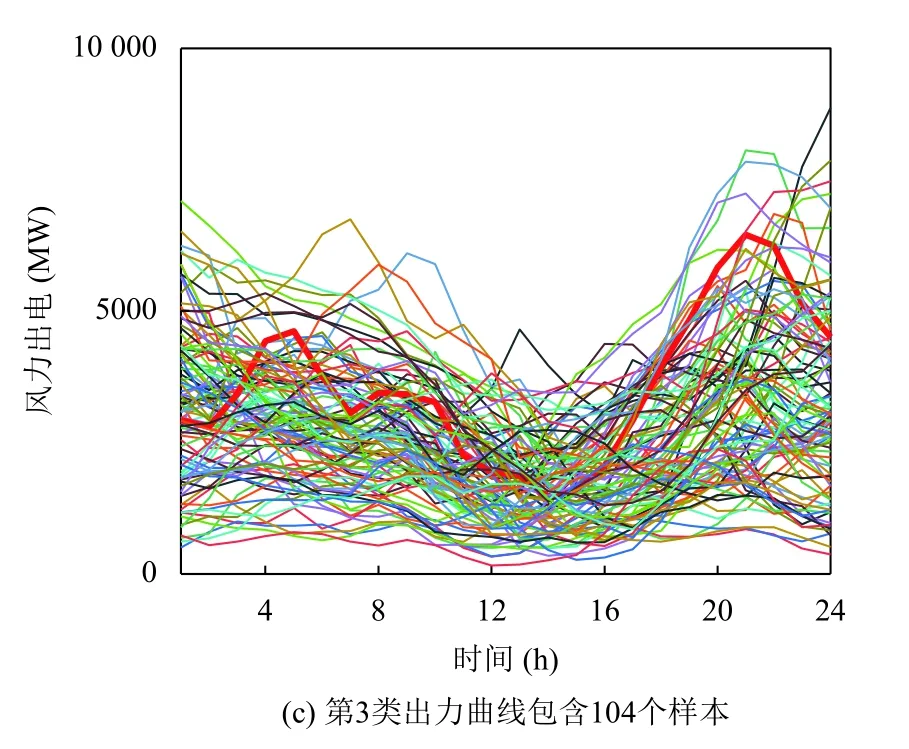
图7 秋季地区风电出力场景曲线簇
在调度计划中,夏秋季节应安排调峰能力较强机组和其他调峰资源,应对风电功率大范围波动,且秋季上半日应多安排爬坡性能较高机组或灵活性调节资源,应对风电功率频繁波动.针对春冬季节风电多峰谷特性对峰谷电价合理优化,通过负荷参与电网调度减少风电峰谷差.

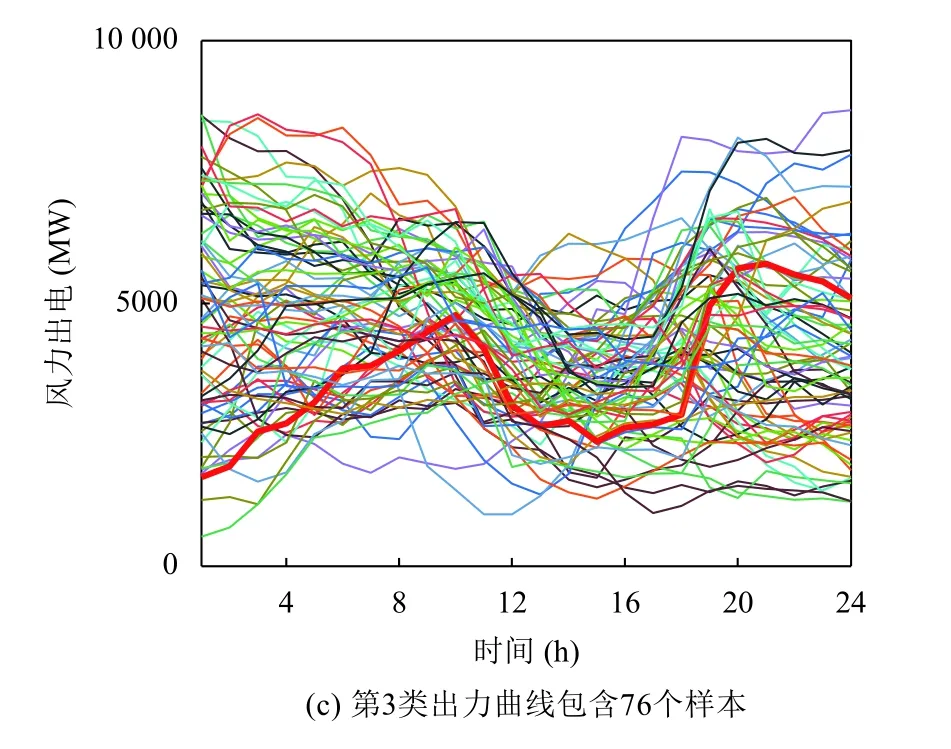
图8 冬季地区风电出力场景曲线簇
4 结论
随着清洁能源在社会发展中扮演越来越重要的角色,风能资源的利用也逐渐增多.本文针对风电出力场景进行研究,提出的高斯混合聚类模型,能够提取典型风电出力场景,并与K-means 聚类方法对比,该文提取的方法更能得到同类形态相近的曲线,反映出风电功率变化的特征,例如风电的正反调峰特性和波动特性,对电网的调度具有重要意义.

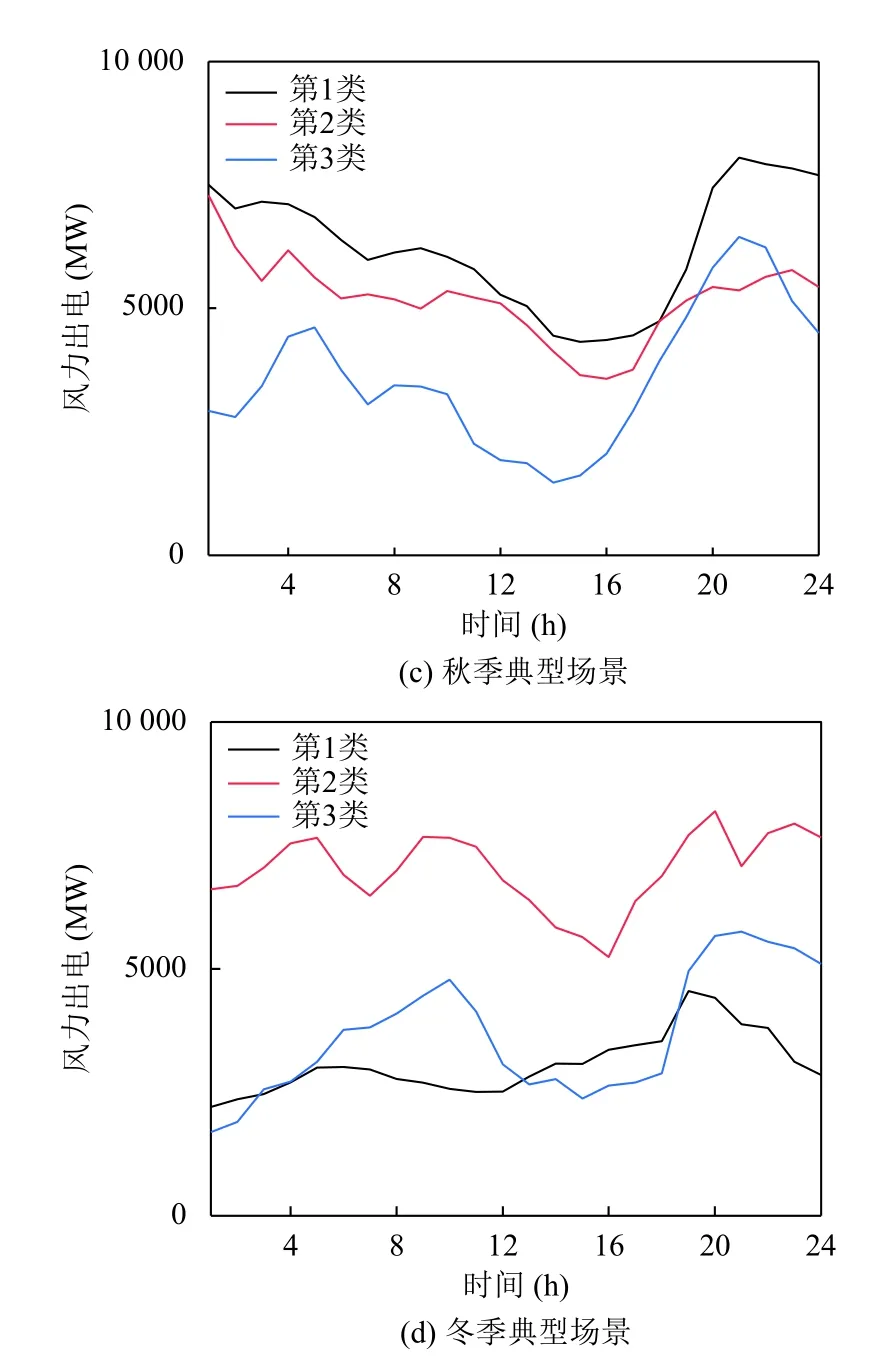
图9 四季曲线簇的典型场景
