图像卷积实时计算的FPGA实现
2021-01-21张帆
张帆
(中国科学院长春光机所,吉林 长春 130033)
卷积运算普遍应用在图像模糊、图像锐化以及卷积神经网络、目标识别等数字图像处理中,是图像预处理的关键步骤。根据卷积计算操作单一化、算法简便的特点,结合FPGA资源循环复用和并行处理结构,实现了基于FPGA的图像卷积计算[1-4]。但是图像卷积计算要求遍历图像所有像素点,图像像素越多,计算时间越长;同时在图像处理中涉及多级联卷积计算,例如卷积神经网络计算时,其并行性差,导致图像处理实时性很难得到保证,因此对基于FPGA的图像卷积计算方式的研究显得尤为重要[5-6]。
目前对于提升FPGA图像处理中卷积计算时间的研究主要分为硬件和软件两个方面。其中基于硬件电路的设计方法简单,根据图像卷积处理目的设计出特定的电路结构,以满足图像处理需求[7-8]。这种方法能够有效地实现卷积计算,但是不具有通用性,实用价值不高。所以基于FPGA算法处理图像数据的方法更具有研究意义。结合FPGA的高速处理能力和并行计算特点,设计算法框架以实现降低资源消耗,提升图像处理速率的目的[9-10]。文献中提出多种方法,包括基于FPGA设计一种卷积计算IP核,通过对IP核参数设置,实现对不同窗口大小、不同系数的卷积计算[11]。利用FPGA的并行机制以及分布式,用查找表代替乘法器,降低图像运算量[12]。采用异步接收发送以及流水线结构,实现图像数据准确传输及计算[13-16]。文献中提出的基于FPGA卷积计算是根据系统获取图像数据后,通过不同的卷积计算方法减少图像处理时间,提高图像处理效率。在此基础上设计一种实时图像卷积计算方法,实现在图像数据采集过程中完成图像预处理卷积计算功能,提高图像处理速率;同时针对多级联卷积计算,图像输出计算结果实时性不受卷积次数影响,图像输入输出同步化。
基于FPGA实现多级联卷积计算步骤主要包括:首先,应用乒乓FIFO的方式对输入的数字图像数据进行异步缓存及同步操作;然后,输入到循环复用的RAM存储器中,对数据进行逐行卷积计算并将结果直接输出到下一级卷积计算模块。整个计算过程中,数据并行处理及传输,系统不需要存储整幅图像数据,节省了FPGA的存储空间。通过比较MATLAB图像处理结果和ISIM仿真结果,验证了该方法的可行性以及正确性。同时搭建了硬件操作系统,对相机获取的图像进行卷积图像操作,实现图像处理的并行性以及实时性的验证。
1 FPGA多级联图像卷积计算
数字图像卷积计算广泛应用于图像平滑、图像锐化、形态学处理、模板匹配、卷积神经网络、目标识别等。根据实际要求,选择不同卷积核,将输入图像处理成期望结果。常见的卷积操作包括图像平滑中选用均值滤波、高斯滤波等方法实现噪声滤除;图像锐化中边缘提取的Roberts算子、Sobel算子、Prewitt算子、Laplacian算子以及Canny算子等,卷积神经网络中获取图像特征的卷积计算。
卷积核是卷积运算的核心,形式多为二维矩阵,矩阵中各位置权重不同,对图像的处理结果也存在差异。对于输入的数字图像F,宽度和高度分别为w、h,卷积核H的维度参数为wH、hH,卷积核的长度和宽度多为奇数。其中wH、hH<=w、h。卷积计算示意图如图1所示。
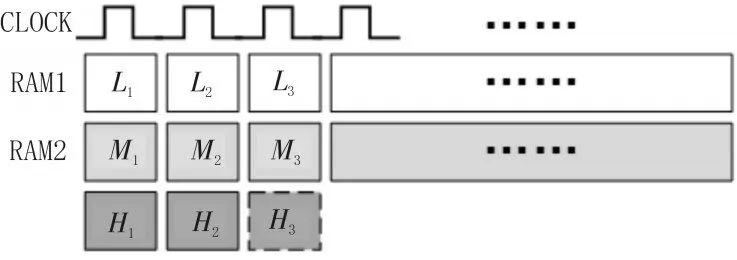
图1 卷积核内部计算示意图
将卷积核中心像素点与数字图像中待计算的像素点重合,图像F中邻域区间与卷积核中数据一一对应,根据公式(1)计算中心像素点对应在输出图像G中像素点的灰度值。应用卷积核遍历整幅图像,获取相应操作的输出图像。
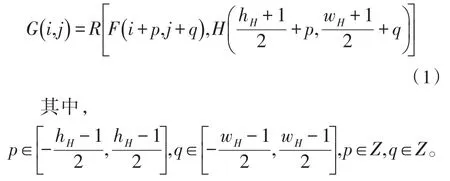
可以看出图像的卷积计算方法简单,可重复性强,但是计算数据量大。对于图像需要多次卷积计算的处理时间更长。对此,文中结合FPGA并行性,提出了高效实时计算图像多级联卷积计算的方法。
1.1 基于FPGA的图像卷积计算设计
基于FPGA的图像卷积计算主要是通过循环利用RAM存储器实现的。由于图像的卷积计算算法简单,每个像素点操作方法相同,依据FPGA硬件的并行算法能够有效实现数值的实时运算。
图像数据按照FPGA内部数字时钟逐行顺序输入。FPGA内部设定(2hH-2)个RAM存储器,其中hH表示卷积核的高度。每个RAM存储器位长为M bit,位深为w,M等于图像数据的位长,位深w即为图像每行的数据量。下面以3×3的卷积核为例,详细介绍图像卷积计算的实现。
当卷积核是3×3大小时,FPGA预先设定4个RAM 存储器,其中 RAM1、RAM2为一组,RAM3、RAM4为另一组,实现相邻两行图像数据的缓存。如图1所示,RAM1、RAM2中分别存储前两行数据,当第三行数据按顺序依次输入时,根据数字输入时钟节拍读取RAM1、RAM2同一列数据,先后得到L1、M1、H1以及 L2、M2、H2;FPGA新读入第三列数据时,获取 L3、M3、H3数据,原图像中以 M2为中心点的八邻域数据全部获得。将该邻域数据与卷积核进行相应计算,结果作为卷积处理后图像M2位置处的像素值输出。
对整幅图像进行操作时,循环使用RAM1、RAM2和RAM3、RAM4对数据进行缓存,其过程如图2所示。首先将图像前两行数据F(1,:)、F(2,:)依次存入RAM1、RAM2中;在第三行数据 F(3,:)输入过程中,求出卷积处理后图像的第二行数据G(2,:)并输出,同时将RAM2中数据和新输入的行数据(即F(2,:)和 F(3,:))存入 RAM3、RAM4中。当第四行数据 F(4,:)输入时,依照上述方法,结合RAM3、RAM4存储器中数据和新输入的数据计算图像G(3,:)对应的输出结果,同时将RAM4中数据和第四行数据(即F(3,:)和 F(4,:))存入 RAM1、RAM2中。以此类推,在行数据输入过程中,完成该行的卷积计算以及下一行卷积计算数据的预存储。循环利用RAM1、RAM2和RAM3、RAM4组合,交替存储数据,逐行计算图像卷积结果,当最后一行数据写入结束时,对应的G图像数据也计算完成,实现了图像卷积计算结果的实时输出。
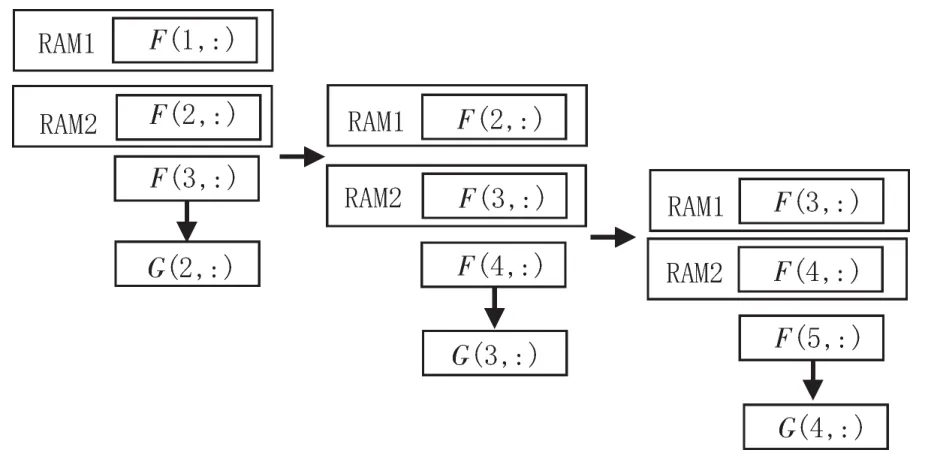
图2 图像卷积计算过程
对于图像首末行、列空缺数据,根据计算要求采取相应的方法。对于图像滤波等操作,可以采用补值方法,将原图像数据直接输出补充该位空缺值;对于卷积神经网络、目标识别等图像操作,可以直接输出计算结果,忽略空缺位置。
此外结合FPGA运算准则对卷积核与图像数据间的函数计算进行分析,如果仅涉及到加减法或者乘法运算,例如边缘梯度计算,FPGA内部提供相应IP核可以直接实现数值计算。但是对于均值滤波这种需要实现数据除法计算时,FPGA内部没有直接使用的IP核,考虑到在FPGA中实现二进制除法的复杂性,文中采用倒数求解法来实现除法的计算。首先将除数取倒数后转换为二进制的小数格式,整数保留一位(考虑到除数为1的情况)。然后,将被除数与该二进制倒数相乘,计算结果的整数部分即为除法运算的商。倒数求解法将除法运算转换为乘法运算,使卷积计算的操作过程更简便。
1.2 多级联卷积实时计算
对于图像处理中存在多级联卷积计算时,采用并行处理的方式实现图像数据的实时传输。如图3所示。
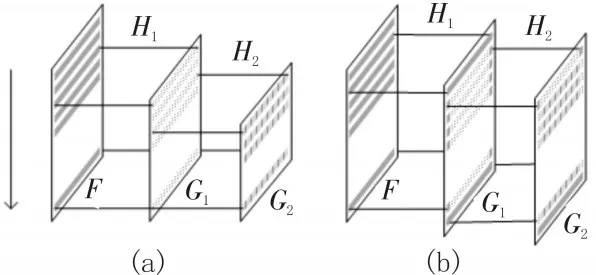
图3 多级联卷积计算过程
当忽略图像首末行、列数据缺省现象,即图3(a)所示,原始图像F逐行输入卷积计算模块,根据上节原理进行计算,当第三行数据输入时,经过卷积核H1计算出的结果G1中第一行数据输出,同时将图像G1首行数据输入卷积核为H2的卷积计算模块中。依此类推,随着图像F的逐行输入,F与卷积核H1的卷积计算结果G1实时逐行输出;同时得到的G1图像数据直接输入下一级卷积计算模块,实现与卷积核H2的计算。由此可以看出,最终输出图像G2的最后一行数据与输入的原始图像F最后一行数据同时结束,实现了多级联图像卷积计算的实时性。
当图像首末行、列数据空缺处填补数据的情况下,如图3(b)所示,当原始图像F第二行数据输入到卷积计算模块时,直接作为图像G1首行数据输出,同理其余行首末列数据直接输出。当图像F最后一行数据输入时,经过卷积核H1计算得到G2倒数第二行数据,然后将F最后一行数据直接输出,填补G1最后一行数据空缺。从图中可以看出,G1输出时间相比于原图F延迟一行数据传输的时间;G2输出时间相比于G1延迟一行数据输出时间,相比于F延迟两行数据输出时间。所以对空缺行列数据进行补位的图像卷积计算过程中,第N层卷积计算结果输出图像相比于原始图像延迟N行数据输出时间。该延迟时间相对于图像数据的输入时间可以忽略不计,因此该系统实现了多级联图像卷积计算的实时性。
2 FPGA卷积计算系统仿真
该文借助ISEM14.7仿真软件对FPGA卷积计算过程进行仿真。将原始图像数据逐行排列转换为txt文件。通过仿真程序依次读取图片数据,同时按照Camera Link接口协议模拟FVAL、LVAL以及DVAL信号输入。卷积计算中RAM复用仿真图如图4所示。
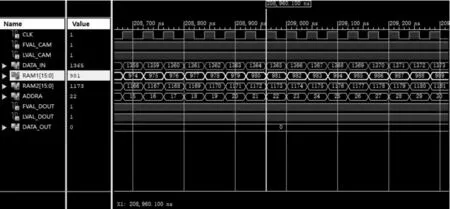
图4 卷积计算系统信号仿真图
分别计算基于FPGA卷积图像处理中均值滤波和拉普拉斯边缘两类卷积计算结果。将仿真结果与MATLAB软件处理结果进行比较,其结果如图5所示。
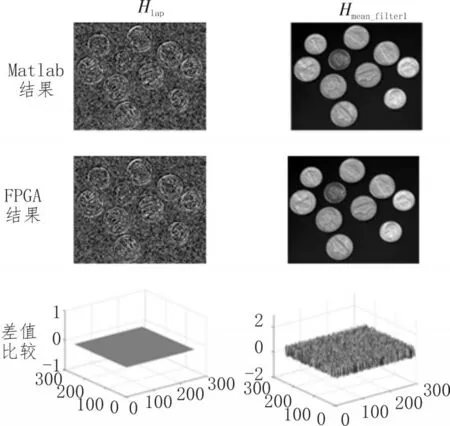
图5 FPGA、MATLAB卷积计算结果比较
通过比较FPGA仿真和MATLAB处理结果,可以看出FPGA系统设计有效地实现了图像的卷积处理。其次对于类似拉普拉斯算子类型的仅包含图像加法、乘法计算的卷积处理,FPGA处理结果与MATLAB计算结果一致;对于涉及除法运算的卷积处理,例如均值滤波算子,FPGA计算结果与MATLAB处理结果相近但是存在差值。由于FPGA除法计算时进行了除数取倒数操作,其倒数小数位有效位选取影响图像计算结果。下面对FPGA图像计算结果误差进行分析。
对于图像数据位数和除法计算中倒数小数位数选取的不同,卷积计算结果存在差异。以均值滤波为例,卷积精确结果与FPGA除法运算后的计算误差为2n/10x,其中n是图像数据位宽,x是小数有效位宽。误差结果随图像数据位数和除数小数位数变化情况如图6所示。
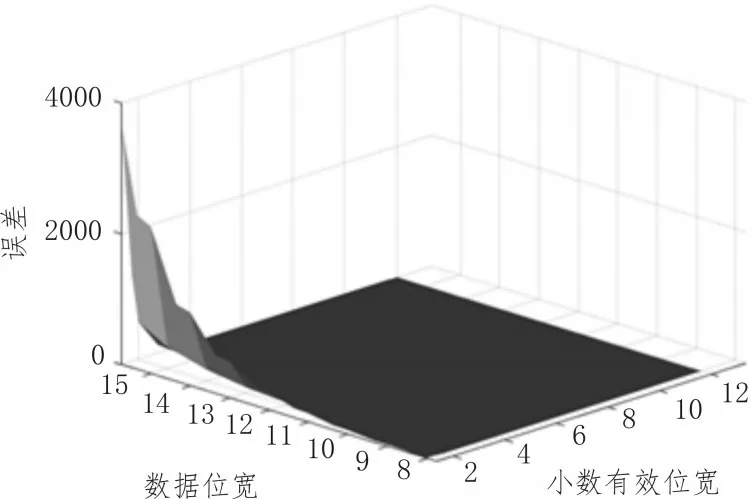
图6 FPGA卷积计算误差
从图中可以看出,为了满足系统误差精度,对于图像处理过程中不同位长的数据,其除数小数位数选取也存在差异。对于文中相机输出16位图像数据,除数倒数选取5位小数,FPGA图像处理卷积计算结果与计算真值误差在一个灰度值内。
通过仿真软件对基于FPGA的卷积计算输入输出信号进行分析,可以看出:整个系统实现了图像卷积计算输入输出同步化的目的;同时对于包含除法类别的卷积计算,其误差在一个灰度值之间。
3 FPGA卷积计算系统实验验证
3.1 卷积计算系统组成
图像采集及卷积计算处理结构示意图如图7所示,主要包括相机数据采集、FPGA图像处理以及结果输出。系统的工作流程是:根据相机成像要求,FPGA生成控制指令,设置相机工作参数并发送摄像指令;经过相机曝光后采集到的数据通过Camera Link接口传输到FPGA;FPGA接收到数据信号后,同步相机数据并进行相应的卷积计算,结果通过Camera Link接口输出。其中相机与FPGA之间、FPGA与PC之间均通过Camera Link接口连接。
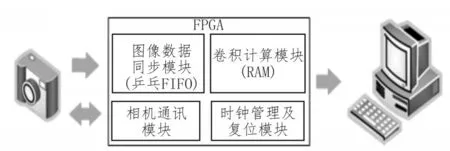
图7 FPGA卷积计算系统结构示意图
FPGA内部图像处理主要分为4个模块:时钟管理及复位模块、相机通讯模块、数据同步模块以及卷积计算模块。时钟管理及复位模块提供了全局时钟以及复位信号;相机通讯模块主要控制相机摄像参数;图像数据同步模块实现相机输入新号的同步操作;卷积计算模块实现图像卷积计算并输出处理结果。文中选用VHDL语言完成模块设计,设计流程采用自上而下的设计方法。具体设计如下:
1)时钟管理及复位模块
时钟管理及复位模块主要产生整个系统所应用到的时钟以及复位信号。时钟主要包括FPGA内部工作时钟、Camera Link接口通讯波特率时钟,选用FPGA内部时钟管理单元DCM生成相应频率时钟。复位操作在系统上电开始工作的同时,对内部信号及状态赋上初始值,避免因初始值不确定导致后续程序出现错误,增加系统可靠性。
2)相机通讯模块
文中应用EAGLE V 4240相机作为探测器,该型相机可以通过外部Camera Link接口实现对相机工作模式的控制,包括相机工作模式、工作温度、快门延时时间、曝光时间、数据读出速率、感兴趣区域、binning模式设定等。相机与FPGA通讯波特率为115 200 bps,通过Camera Link接口中 SerTFG、SerTC两路LVDS实现通讯,根据实际要求完成相机参数设定。
3)图像数据同步模块
相机输出图像通过Camera Link接口实时传输到FPGA。图像有效数据位长为16 bit,相机输出时钟频率为40 MHz,图像大小为2 048×2 048,数据读出速率为2 MHz。由于相机输出时钟、数据读出速率均与FPGA工作时钟异步,FPGA接收端口信号时需要对相机数据进行缓存及同步处理。针对这种数据读写有序、输入输出时钟异步的数据,FPGA内部采用乒乓FIFO的结构接收图像数据,实现数据的缓存及同步。
乒乓FIFO接收模块工作示意图如图8所示。FPGA内部设定两个FIFO,每个FIFO位长为16 bit,位深为w。输入时钟连接Camera Link接口提供的数据有效信号DVAL,输出时钟连接FPGA内部工作时钟。WEA1、WEA2信号控制 FIFO1、FIFO2读写状态。具体工作过程如下。
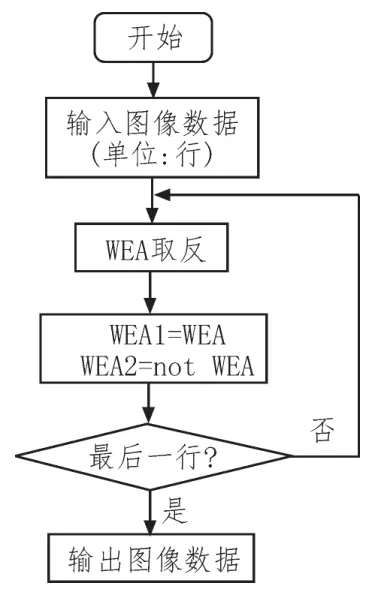
图8 乒乓FIFO流程图
对于输入图像行数据,一个FIFO写入数据,另外一个FIFO读出数据;在下行数据输入时,两个FIFO读写互换,交替进行,直至最后一行图像数据同步结束。根据乒乓FIFO模块设置,Camera Link接口输入的相机数据逐行缓存同时输出同步图像数据。同步后的图像数据输入到卷积计算模块,进行后续图像操作。
4)卷积计算模块
通过乒乓FIFO同步后的图像数据输入到卷积计算模块,根据上节介绍的卷积计算方法,循环利用RAM存储数据及计算,获取卷积处理后的结果。对于多级联卷积计算,并行处理图像数据,实现实时图像的处理及输出。
3.2 系统实验结果
对于FPGA多级联卷积计算操作,以实现原始图像滤波后对图像边缘进行提取为例,完成图像两层卷积计算。将编译好的程序烧录至xc4vsx55芯片中,实现图像多级联卷积计算功能。FPGA内部资源如表1所示。
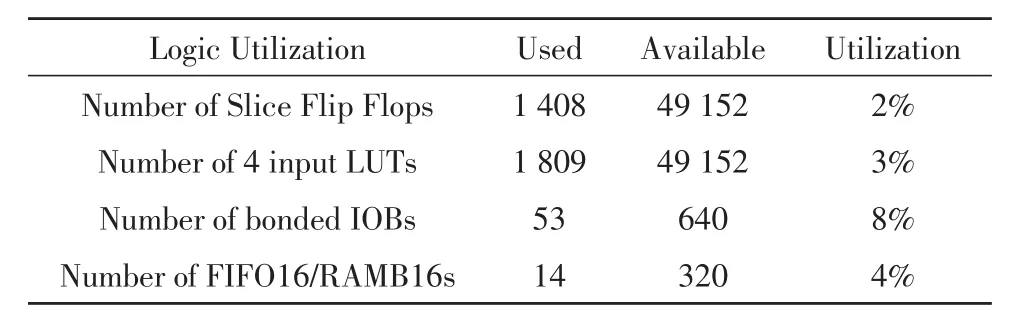
表1 FPGA内部资源
通过相机拍摄图像,对相机图像依次进行均值滤波和边缘检测操作,FPGA输出的结果如图9所示,实验证明基于FPGA实现了图像多级联卷积计算、输入输出同步化操作。

图9 图像多级联卷积计算实验结果
对于多级联卷积计算,随着卷积层数不同,FPGA内部资源利用率也存在差异。FPGA资源利用率与图像卷积计算层数之间的关系如图10所示。
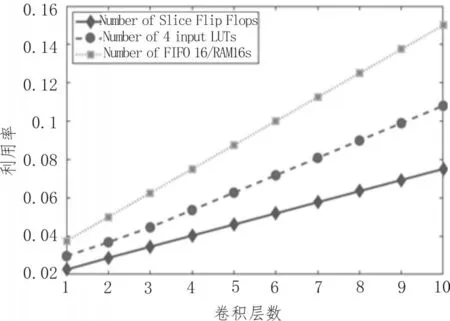
图10 卷积层数与FPGA资源利用率关系
从图中可以看出,FIFO/RAM数量随卷积层数增多均匀增加,每增加一层卷积计算,RMA数量增加4个;对于LUT以及FF利用率也随着卷积层数增加而增加。由于每层卷积计算所需的资源仅仅与图像列数相关,与图像行数无关,即使大尺寸图像卷积计算,其FPGA的资源利用率也不大。
通过FPGA内部FIFO以及RAM的复用,有效地实现了实时多级联图像卷积计算。在相机获取图像后的图像预处理中,能够同步获取包括滤波、边缘提取、特征提取等涉及卷积计算的图像处理结果,为后续图像处理做准备,同时节约了图像处理时间以及硬件资源。在整个图像处理过程中,不需要外部存储器对图像进行存储,可复用性好,不存在资源浪费现象。同时接口灵活,可编程性强,通过改变卷积核内部权重值,能够实现不同的卷积计算。对于多级联卷积计算,卷积层间互不相关,可单独使用,也可以叠加使用,系统设计操作简单;同时实现了输入输出图像同步化,满足系统实时性要求。
4 结论
文中提出一种基于FPGA实时对图像数据多级联卷积计算的系统方案。在图像数据采集阶段实现数据采集和图像预处理卷积计算一体化。整个系统不需要外部存储器来存储整幅图像,存储空间要求仅与卷积核的宽度相关,不需要考虑原始图像的宽度,大大降低了图像处理对FPGA存储空间的要求。同时可编程性强,可以实现不同类型卷积计算。对于多级联卷积计算,卷积计算结果实时输出,实现系统输入输出图像同步化。
