基于混合过滤的网络关联数据个性化推荐系统设计
2021-01-21王馨乐汪红
王馨乐,汪红
(中南民族大学计算机科学学院,湖北 武汉 430000)
混合过滤推荐是基于兴趣相同用户进行选择的处理技术,可帮助固定对象在最短时间内找到真正使他感兴趣的内容,并将这些数据推荐给此对象及与其相关的其他用户。此方法最大的应用优势在于对待推荐对象不设置特殊要求,仅按照非结构化原理处理用户之间的复杂度关系。国外学者依据该项技术手段先后开发出原型推荐等多个实用型系统,并已经在实际应用中取得了较好的效果[1-2]。Typestry是最早应用于互联网环境的混合过滤推荐系统,能明确标注出处置行为较为类似的目标用户,从而快速调节数据节点间的连接占用关系。
普通推荐系统同时搜索目标用户与邻居对象节点,再通过改进相似度度量的方式,处理信息节点间的关联应用关系,但与此方法匹配的按需占比与混乱占比数值始终不能达到预期化水平。随着互联网传输数据总量的提升,关联数据对象间出现了明显的混乱占比现象,进而引发了“信息孤岛”问题。为解决此问题,引入混合过滤技术,在J2EE架构、MVC主机、存储数据库等软硬件执行结构的支持下,该文设计一种新型的网络关联数据个性化推荐系统,并通过对比实验的方式,突出说明传统系统与新型系统间的实用差异性。
1 网络关联数据个性化推荐系统硬件设计
1.1 J2EE网络架构
J2EE是一种标准化的开放型网络数据平台,由APPLET主机、JSIP主机、Senvlet主机、EJB主机、Client主机五部分共同组成。其中,APPLET主机存在于J2EE架构的网络阶层,可判断处于混合状态的关联型数据是否具备推荐应用的能力。JSIP主机、Senvlet主机、EJB主机同时存在于J2EE架构的信息阶层,可按照关联数据的网关传输状态,改变信息数据的存储连接形式,从而满足系统在个性化推荐方面的执行需求[3-4]。Client主机在J2EE架构的存储阶层,与系统个性化数据库直接相连,可采集网络环境中待过滤的混合信息,再将数据信息转化成递归推荐的应用形式,直接存储于数据库之中。J2EE网络结构图如图1所示。
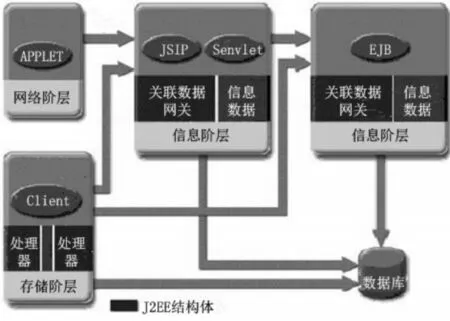
图1 J2EE网络结构图
1.2 MVC关联主机
MVC关联主机是J2EE网络架构的下级附属结构,为适应网络关联数据的个性化推荐需求,与上级执行元件的存储阶层处理器相连,可同时处理数据信息的连接与响应请求。关联数据浏览器支配MVC主机的过滤控制器,可在混合信息的环境下,根据个性化推荐指令,调取其中的必要对象占比节点,从而满足网络关联数据与按需数据间的统筹调节关系[5-6]。在传输信息处于有效连接状态的情况下,MVC关联主机的过滤控制器会输出多个混合模型,一部分用于构建与数据响应相关的个性化推荐连接,另一部分则辅助网络信息连接通路的构建。MVC关联主机结构如图2所示。
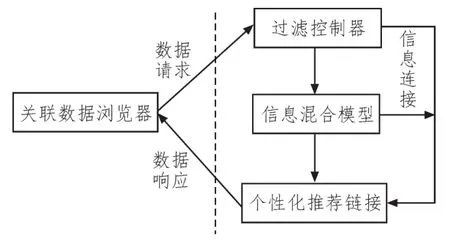
图2 MVC关联主机结构图
1.3 Portlet模块
Portlet模块是网络关联数据个性化推荐系统中唯一的处理指令生成元件,由内部基本框架和外部联合结构两部分共同组成。内部互联设备同时支配Server主机与Container主机,可在调取网络关联数据个性化指令的同时,分析与混合过滤处理相关信息连接请求的应用可行性,从而实现对网络数据参量的管理与维护[7]。互联架构下属的API设备是Portlet模块中的核心元件,由6个完全相同的个性化推荐节点组成,可在满足系统信息配置需求的同时,建立与存储数据库的物理连接,达到监测MVC关联主机行为状态的目的。Portlet模块外接的数据混合过滤设备主要负责检测关联数据的个性化水平,并为其匹配一定数量的应用型推荐节点[8-9]。Portlet模块结构如图3所示。
2 网络关联数据个性化推荐系统软件设计
在相关硬件设备结构的支持下,按照个性化数据库连接、网络数据预处理、混合型过滤链路设计的操作流程,完成系统的软件执行环境搭建,两相结合,实现基于混合过滤网络关联数据个性化推荐系统的研究。
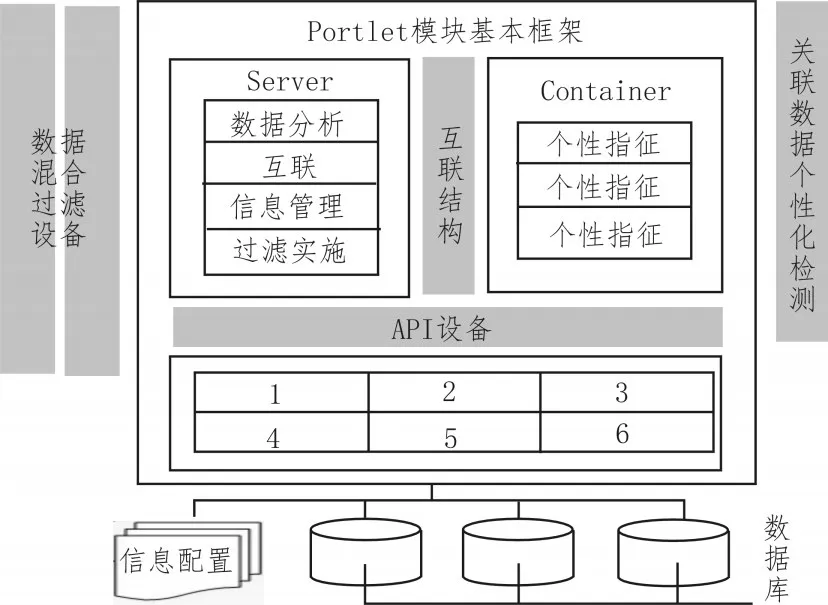
图3 Portlet模块结构图
2.1 个性化数据库
个性化数据库负责存储与网络关联数据相关的信息参量,并按照混合过滤的标准分类处理数据信息,最终生成多样化的应用表单,以满足系统的推荐需求。常见的网络关联数据有关键词、解析词、特征词3类,而关联数据对象占比混乱是指同一时间至少有两类信息占据同一个推荐节点,致使部分数据参量堆积在某一固定位置,从而使相邻节点处出现明显的“信息孤岛”现象[10-11]。个性化数据库结构如图4所示。
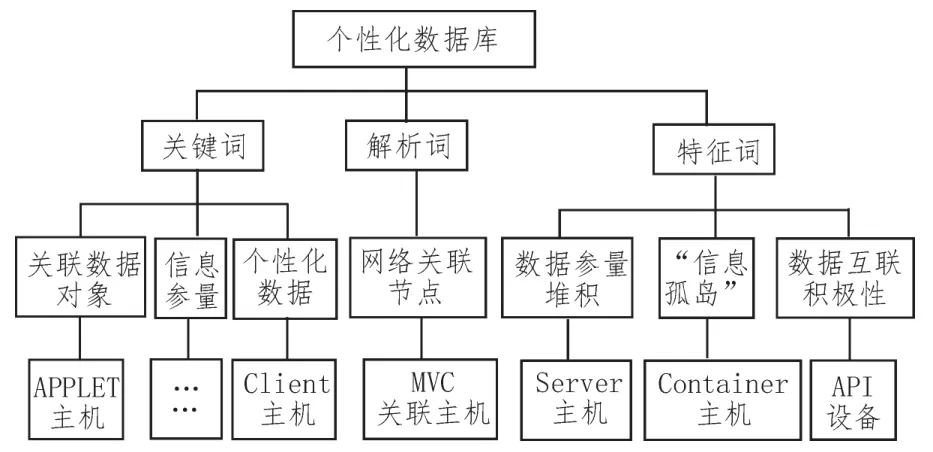
图4 个性化数据库结构图
2.2 网络数据预处理
网络数据预处理是确定个性化推荐系统节点实时位置的必要步骤,通过调取网络关联数据来确定关键词、解析词、特征词3类数据参量间的混合程度,并遵循一定的过滤原则,去除非必要“孤岛”节点内的暂存信息[12-13]。处于混合状态的网络关联数据兼容性程度较高,彼此之间的个性化水平较低,很难完全满足系统的推荐应用需求。而经过预处理后的网络数据能在保持高度完整性的同时,过滤处于混合状态的信息参量,并快速聚集已处于“孤岛”状态的数据节点,提升网络关联数据的个性化水平[14]。
2.3 混合型过滤链路
混合型过滤链路构建是网络关联数据个性化推荐系统设计的末尾处理环节,可调取数据库中存储的预处理数据参量,并针对个别“孤岛”节点进行过滤与清除处理。为降低关联数据对象间的混乱占比率,混合型过滤链路只调取按需分配的信息节点,并联合J2EE网络架构中的EJB主机,建立必要的信息阶层结构,一方面可实现对信息按需占比与混乱占比实值的平衡,另一方面也可避免不必要的数据跨越传输[15-16]。表1反映了混合型过滤链路所必备的搭建要素。

表1 混合型过滤链路搭建原理
至此,完成各项软硬件执行结构的搭建,在混合过滤原理的支持下,实现网络关联数据个性化推荐系统设计。
3 系统应用性检测
为验证基于混合过滤网络关联数据个性化推荐系统的实际应用性能,设计如下对比实验。在网络传输环境中,截取两段等长的关联数据信息作为实验对象,分别以搭载所设计推荐系统和传统推荐系统的应用主机作为实验组、对照组检测元件,在相同实验环境下,记录信息顺次通过主机时,关联数据对象间混乱占比率及按需占比率的具体变化情况。
将图5所示数据生成设备接入图6所示检测环境,同时连接实验组与对照组应用主机,使其获取等量的网络关联信息参量,详细记录各项实验指标的具体变化数值,用于后续的结果研究与分析。

图5 数据生成设备

图6 实验检测环境
关联数据对象间的混乱占比、按需占比均能描述“信息孤岛”事件的发生几率,通常情况下,混乱占比率越低、按需占比率越高,“信息孤岛”事件的出现可能性越小,反之则越大。在既定检测环境中,实验组、对照组实验详情如下。
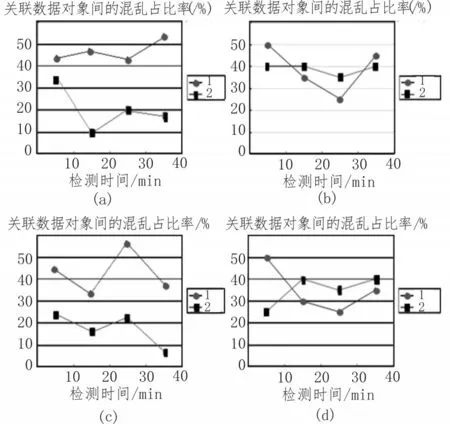
图7 关联数据对象间的混乱占比率
图7中,“曲线1”代表对照组关联数据对象间混乱占比率,“曲线2”代表实验组关联数据对象间混乱占比率。在整个实验过程中,对照组最大值达到58.4%,而实验组最大值仅能达到40.0%,二者差值为18.4%。以图7(a)图像为例,对照组数据对象间混乱占比率极大值达到54.9%,对照组数据对象间混乱占比率极小值低至10.0%,二者间差值达到44.9%,远高于平均极值差水平。综上可知,应用基于混合过滤网络关联数据个性化推荐系统,能够促使关联数据对象间的混乱占比率不断下降,可有效避免“信息孤岛”现象的出现。
对比表2、表3,横向对比实验组关联数据对象间按需占比率的最大值达到56.1%、最小值达到47.5%,二者间差值为8.6%;横向对比对照组关联数据对象间按需占比率的最大值达到41.7%、最小值达到33.5%,二者间差值为8.2%。提取第3组数值结果,纵向对比实验组、对照组指标参量可知,实验组关联数据对象间按需占比率极大值51.2%与对照组极大值41.9%相比,上升了9.3%。综上可知,应用基于混合过滤网络关联数据个性化推荐系统,确实能够大幅提升关联数据对象间的按需占比率,对抑制“信息孤岛”现象的出现起到促进性作用。
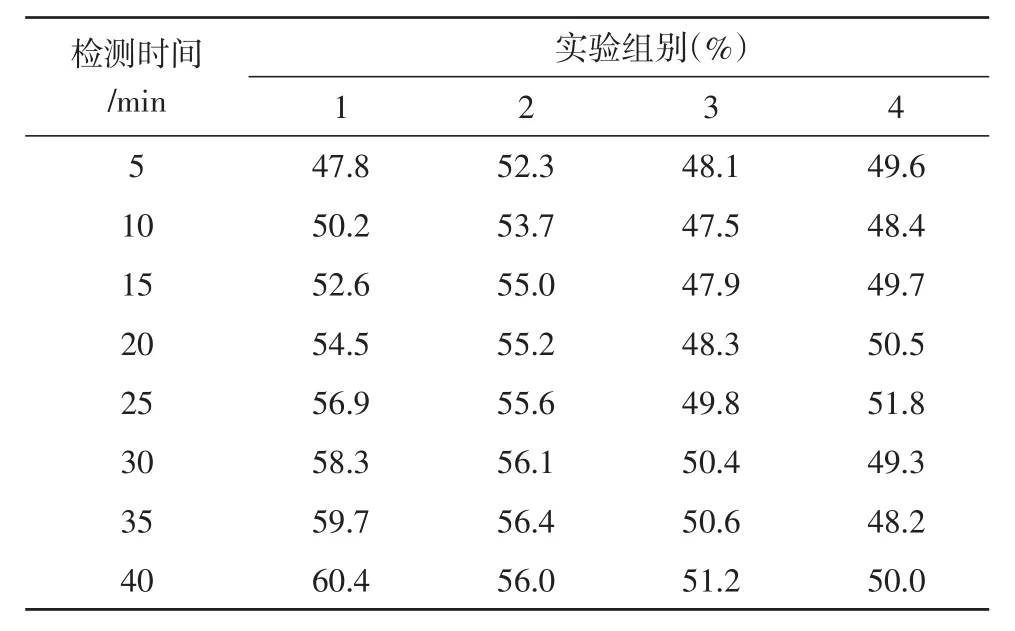
表2 实验组按需占比率
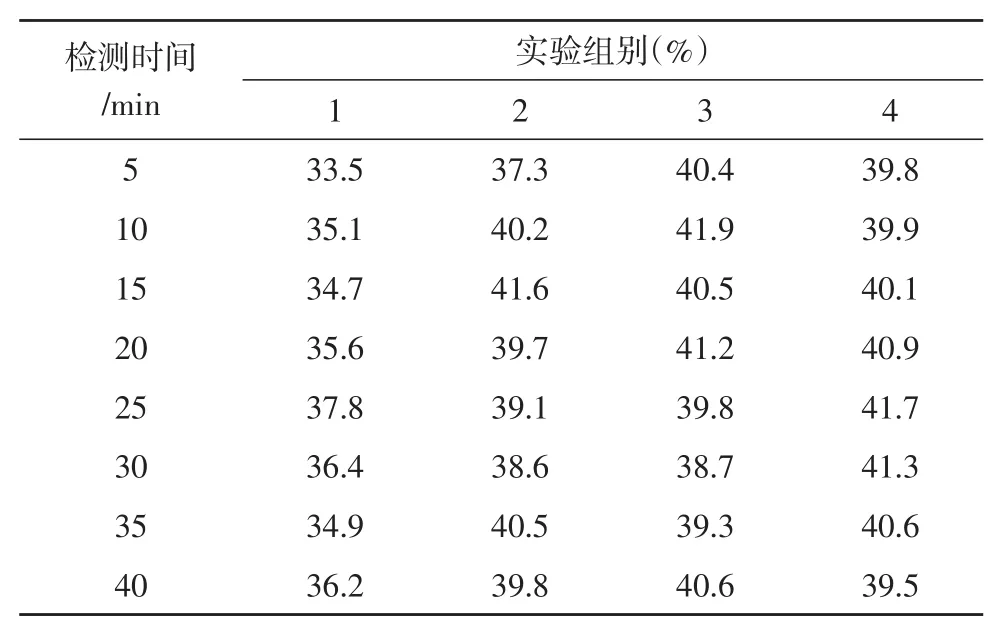
表3 对照组按需占比率
4 结束语
网络关联数据个性化推荐系统在传统推荐系统的基础上,融合混合过滤原理,借助MVC主机、Portlet模块等硬件执行设备,在实施网络数据预处理的同时,完善个性化数据库的存储模式。从实用性角度来看,混乱占比率的降低、按需占比率的提升,都表明关联数据对象间的占比混乱现象得到有效改善,对“信息孤岛”行为起到了明显的抑制作用。
