基于MongoDB的数据密集型云存储系统设计
2021-01-21郑海清
郑海清
(广东南华工商职业学院,广东 广州 510507)
数据存储是目前研究的热门话题之一,比较常用的存储方式有非结构化存储模式和半结构化存储模式两种,当前使用的传感器、位置服务和社交网络都会应用许多半结构化空间数据,同时也会应用非结构化空间数据[1]。传统的数据存储系统采用的实现方式主要有两种:从空间上扩展关系型数据库,在数据库的上层增设空间引擎,从这两种思路出发,可以很好地改善数据库存储的一致性问题和完整性问题。但是,面对海量数据,关系型数据库很难完整地实现存储、访问、维护问题,更难以实现数据库扩展问题[2]。
NoSQL数据库是一种新型模式,不仅能够快速存储数据,同时也可以快速查询数据,除此之外,NoSQL数据库的容错性很高,灵活的分布方式更适合存储海量数据[3]。MongoDB是NoSQL数据库的一种,是文档型数据库系统,每一个MongoDB实例都会包括多个数据库,每个数据库都是完全独立的,由不同权限控制[4]。MongoDB的存储引擎为内存映射,内嵌的方式不仅能够提高I/O性能,内嵌的方式可以将每一条记录都转化成复杂的层次结构,由于数据库没有固定模式,所以不会受到环境约束,即使在不同环境下也可以完成存储[5]。
文中针对密集型数据存储问题,利用MongoDB数据库适应能力强的特点在云平台上提出了一种新的数据密集型云存储系统,该系统不仅能够解决数据云存储问题,同时也可以实现数据处理,从而满足用户对密集型数据的使用要求和网络服务要求。
1 系统硬件设计
为了同时实现存储系统的存储、访问、管理和处理功能,文中设计的系统包括3个层次,分别是数据层、业务层和表现层[6]。基于MongoDB的数据密集型云存储系统硬件框架如图1所示。
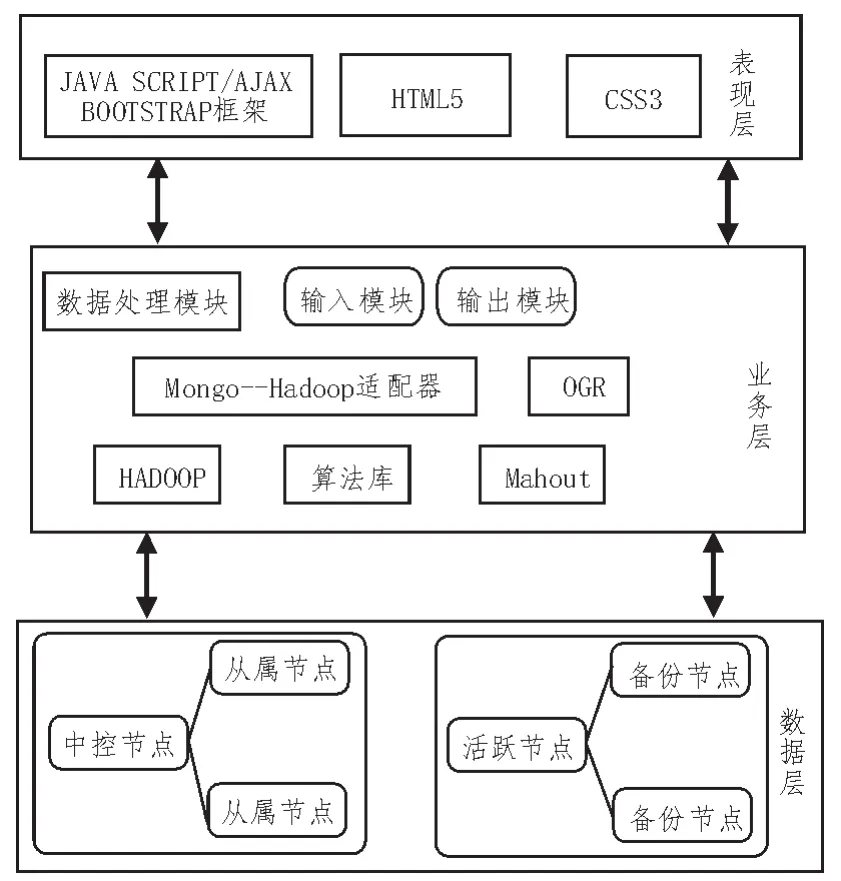
图1 数据密集型云存储系统硬件框架
数据层会将用户上传数据统一存储到MongoDB数据库,利用HDFS分布式文件系统计算存储的数据[7]。数据的类型和结构都拥有不同的特点,因此数据层的存储集合主要有两类:第一类负责存放空间数据,第二类负责存储云数据。由于数据层会向不同的用户提供存储服务,所以被存储的数据必须进行分类,共享数据和私人数据要清楚划分,共享数据被存储到统一数据库后,启动过滤器维护数据安全;私人数据被存储到用户单独的数据库中,启动权限控制维护数据的安全[8]。数据层的存储结构如图2所示。
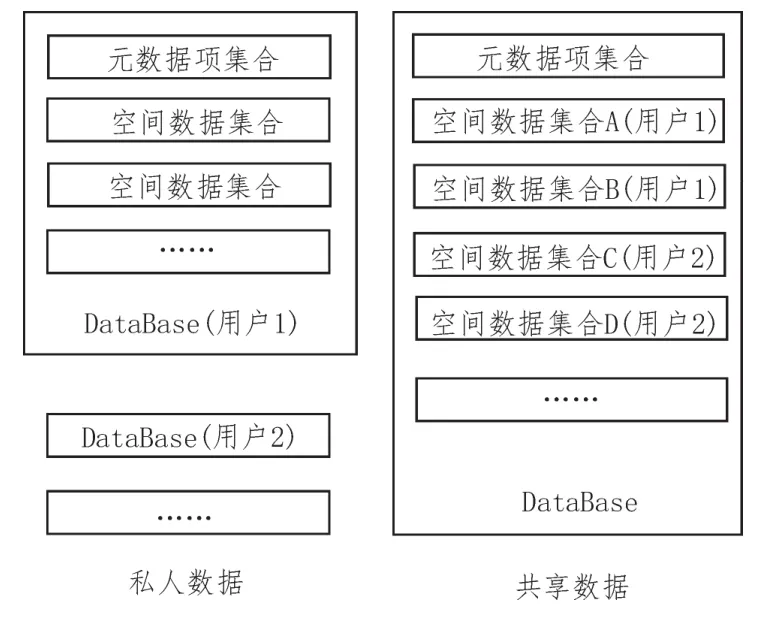
图2 云数据存储结构
通过空间数据集合存储各种不同的数据,用户在进行数据存储时,既可以选择已经存在的存储结构内部数据集,也可以重新建立数据集,为取得更好的存储效果,每一个空间对象都会对应一个json对象,同时在存储时,还要增设“file”、“layer”属性,方便用户在查询时,更好地确定该空间对象所属的源文件和对应的不同图层。系统数据层通过元数据集合来记录空间参考系、数据信息和用户描述,从而确定文件和数据库集合之间的关系[9]。当数据集需要新字段时,用户在上传的文档中直接添加就可以,不需要再次设计,这样不仅能够减少数据结构的使用次数,同时也可以防止大量数据集合,避免存储冗余,利用分片副本架构实现集群架构设计[10]。
业务层位于存储层上方,通过业务层来访问数据。在业务层中,MongoDB数据库都要封装,只有这样才能有效保障用户日常需要的应用功能能够顺利运行[11]。为优化系统工作效率,数据存储层内部的复杂逻辑运算被隐藏,用户数据的读写功能和管理流程同时被简化,业务层仅包括输入模块、下载模块、搜索模块、更新模块、处理模块和删除模块,所有的数据模块都利用MongoDB中的Java程序完成数据交互,在自身算法库中不断挖掘和分析数据[12]。业务层结构如图3所示。
表现层负责展示系统功能,选取B/S架构作为表现层的整体架构,并在浏览器中存储、更新、上传各种不同的数据,为方便用户界面与后台更好地交互,在设计系统表现层时还引用了HTML5、CSS3、AJAX等技术,通过这些技术使系统更好地运行[13]。
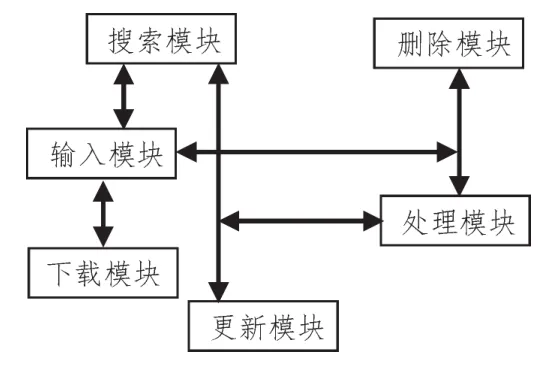
图3 磁盘信息导入与导出模型图
利用访问接口将数据层和表现层连接到一起,访问接口可以向客户端提供必要的接口函数,在获得接口函数命令后,所有的服务程序完成删减、更新、修改、查找等工作,获得的结果要及时反馈给客户端[14]。
系统选用MongoDB—Hadoop作为适配器,完成数据库与外部计算框架的交互工作。适配器实物图如图4所示。

图4 适配器实物图
利用云端技术的强大处理能力分析不同数据,同时使用存储资源和计算资源,完成各项不同的任务,让数据可以大规模地传输,从而缓解网络数据带来的宽带压力,使客户端能够更好地处理数据[15]。
2 系统软件设计
根据系统硬件设计软件,不同的数据使用的转换接口和存储接口都不同,通过注册驱动、获取数据名、获取数据信息、访问数据要素来实现存储流程。基于MongoDB的数据密集型云存储系统软件存储过程如图5所示。
通过云计算获得数据组信息,如式(1)所示。

式(1)中,x代表获取到的数据组信息,∂代表存储层信息,ℑ代表数据层信息[16]。
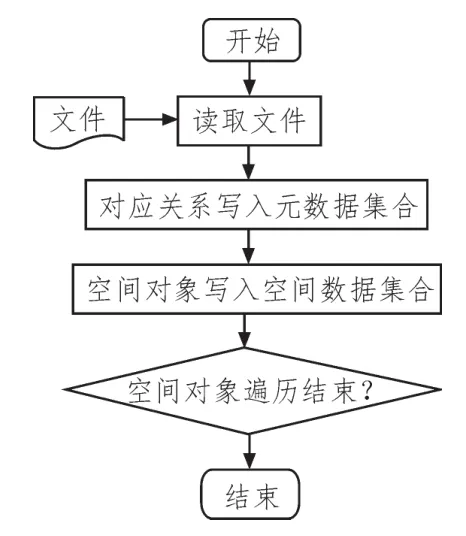
图5 数据密集型云存储系统存储流程
存储系统在MongoDB—Hadoop适配器中获得相关参数后,会对这些数据分片处理,将得到的数据转移到mapper,在MongoDB中处理数据,通过读取来定义得到的程序语言,不断索引过滤新的数据,通过云计算实现批量计算,批量计算工作流程如图6所示。
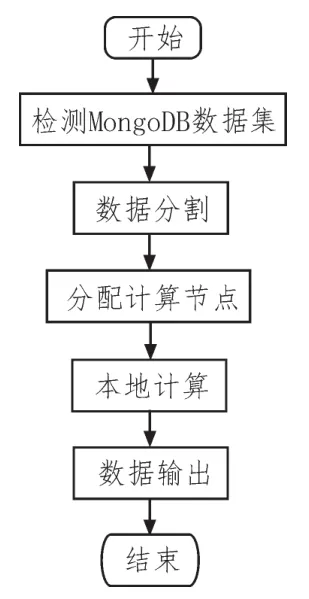
图6 批量计算工作流程
1)利用MongoDB—Hadoop适配器检测得到的MongoDB数据集,并分割所有得到的数据;
2)将得到的数据分割,分配在不同的计算节点中;
3)在Hadoop中计算节点中分割数据,分析分割后的情况,在MongoDB中得到数据,在Mapper中实现本地计算;
4)在Recuder中合并计算,计算的结果输出到MongoDB数据中,最终实现批量计算。
3 实验研究
3.1 实验环境
在一个由3台物理机构成的集群环境下构成操作系统,通过分析基于MongoDB的云存储系统和Sqlite的云存储系统之间的区别来判定系统性能。实验过程的应用参数如表1所示。
3.2 实验结果与分析
数据批量存储性能对比实验结果如图7所示。
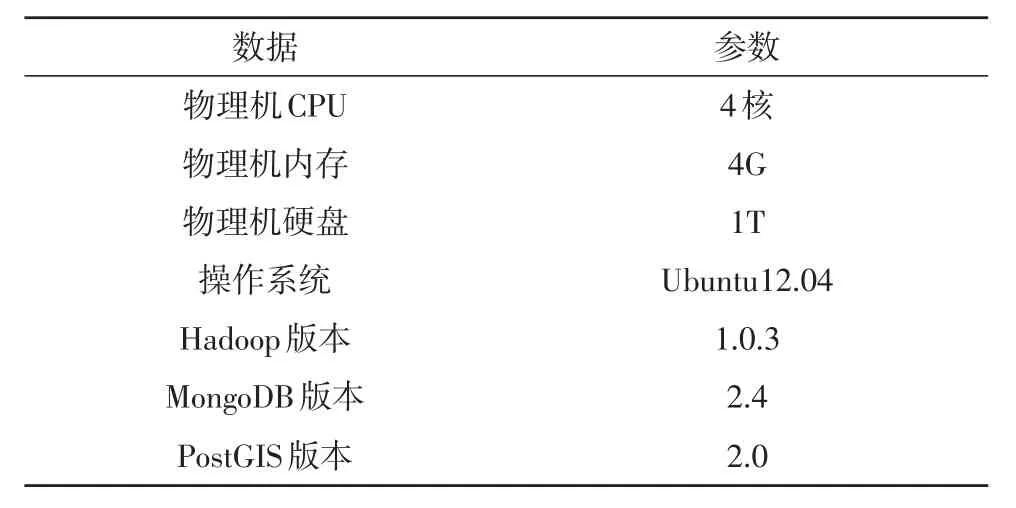
表1 实验参数
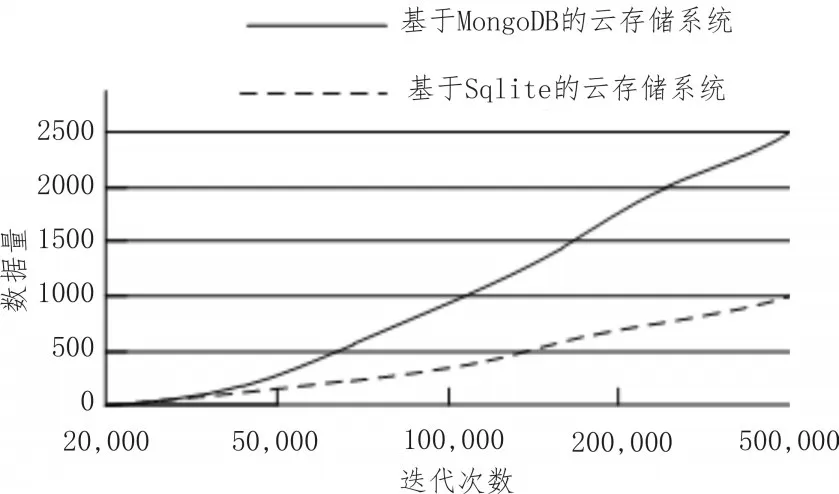
图7 数据批量存储性能对比实验结果
根据图7可知,文中基于MongoDB的云存储系统对数据的整体集群效率都要优于传统的基于关系型数据库Sqlite的云存储系统,多次统计下,文中系统的存储性能是传统系统存储性能的2.8倍,集群效率不会随着实验样本的增加而发生明显波动。由此可见,基于MongoDB的云存储系统与基于关系型数据库Sqlite的云存储系统相比,有着明显的优势,即使数据量增大,系统的插入效率也能得到有效保障。
对1 000条拥有特定性能的数据进行分析,根据数据层级信息和行列号信息显示结果,对比不同系统的查询性能,如图8所示。
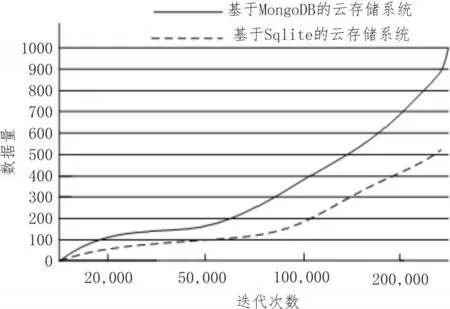
图8 特定数据查询性能实验对比
当数据量较小时,传统的云存储系统和文中研究的云存储系统二者相差不大,但是随着数据量的增加,基于关系型数据库Sqlite的云存储系统花费的查询时间越来越大,上升坡度十分明显,相比之下,基于MongoDB的云存储系统上升坡度比较平缓,由此可见,基于MongoDB的云存储系统查询性能更好。
3.3 实验结论
进一步分析图8实验结果可知,随着数据量的增加,基于MongoDB的云存储系统在数据存储方面和检索方面表现出的性能要明显优于基于Sqlite的云存储系统,能够很好地适应云平台系统。
MongoDB具备降低客户端、存储服务端和各个站点耦合性的能力,基于MongoDB的云存储系统不再将数据存成一体化结构,从逻辑上将共享数据和私人数据分离,使存储服务端和客户端不再完全依靠站点,即使站点不能正常工作,存储服务端和客户端也能正常地执行开发和存储功能。基于MongoDB的云存储系统降低了服务站点的压力,使服务站点能够同时处理大量订单,不同的存储点同时工作,使系统的存储空间更丰富,系统更加灵活,在数据库工作时,系统可根据自身特点适当调整MongoDB集群。除此之外,MongoDB还具备容错性好的优势,从整体上强化系统性能。
4 结束语
通过分析MongoDB数据库特点,研究了一种适用密集数据的云存储系统,该系统硬件结构包括输出存储层、业务展示层和表现功能层3个层次,针对不同用户使用不同的访问接口,系统更加灵活,能够更高效地完成存储任务。文中研究的云存储系统虽然具备很好的云存储和处理能力,但是读取能力相对较差,未来需要在这一方面进一步研究。
