基于Hadoop技术的挖泥船大数据平台架构研究
2021-01-21朱逸峰苏贞叶树霞
朱逸峰,苏贞,叶树霞
(江苏科技大学电子信息学院,江苏 镇江 212003)
疏浚装备越来越发展成为大国角力,是提升远海岛礁建设、海洋维权、港口航道、填海造陆和海洋工程建设能力的国之重器,更是贯彻落实国家“交通强国”、“海洋强国战略”和“一带一路”倡议的重要保障[1]。疏浚装备的升级使得挖泥船疏浚作业数据呈现爆炸式地增长,存储在计算机内的疏浚数据量日益庞大。来自船载服务器与岸端船舶管理平台中存储的海量历史数据,数据量可达数TB,甚至PB,如何高效存储、提取和处理这些宝贵的疏浚数据成为了疏浚大数据分析亟待解决的问题,目前对于船舶大数据的应用分析还在探索阶段,海量施工数据没有得到有效的分析和利用。我国作为疏浚大国,急需在疏浚大数据分析方面取得进展,为安全、高效和智能的疏浚提供支持,通过搭建大数据平台实现疏浚作业在线分析与决策,可有效解决因作业环境复杂和操耙手经验不足导致的疏浚效率不高等问题。
1 现状分析
疏浚行业飞速发展,挖泥船数据采集技术日益先进,使得挖泥船疏浚作业数据呈现爆炸式地增长。疏浚船舶上搭载的DTPM模块、SCADA监测模块、AMS报警模块、AIS识别模块和电子海图模块,在每日挖泥船施工时所采集的数据量非常之大,类型非常之多;这些挖泥船所采集的数据存储在挖泥船的船载服务器及各个航道局的服务器之中,这些服务器大多数仍使用传统的关系型数据库对数据进行存储[2]。面对海量的疏浚数据,传统的关系型数据库对于如何存储并处理疏浚大数据越来越力不从心;各个航道局的疏浚船舶相对的独立运行,使得海量的疏浚信息是相对封闭的,难以进行共享交换,无法整合所有采集到的数据并从中快速挖掘出疏浚规律。
针对上述的疏浚船舶数据现状,疏浚船舶大数据平台建设需要满足各个航道局存储并分析处理海量结构化疏浚数据的需求,同时遵循安全高效、高拓展性、低冗余性的原则,并且建立将各个航道局的疏浚数据进行更新与共享机制。
随着大数据技术的不断发展,基于Hadoop分布式框架平台的海量数据处理技术为解决疏浚船舶大数据处理提供了思路和方法[3]。Hadoop作为大规模分布式数据处理最广泛使用的平台,对于结构化、半结构化和非结构化数据都提供了一套安全高效的解决方案[4]。如何借助大数据技术帮助疏浚行业从海量疏浚数据中挖掘出隐藏价值,是该文需要解决的问题。
2 挖泥船大数据平台架构设计
基于对大批量疏浚数据统计和分析处理的考虑,挖泥船大数据平台有如下3个模块,分别为疏浚数据采集模块、疏浚数据存储模块和疏浚数据分析模块;其中疏浚数据采集模块用于对疏浚数据进行采集与加工;疏浚数据存储模块用于对疏浚数据进行存储与处理;疏浚数据分析模块用于对疏浚数据进行分析计算。疏浚数据分析模块分析处理过的数据系统会将其推送给不同的用户终端,并将这些信息进行汇总、整理,实现业务应用层面的数据共享,并提供共享的数据接口服务,从而实现疏浚数据的共享与服务。挖泥船大数据平台架构如图1所示。
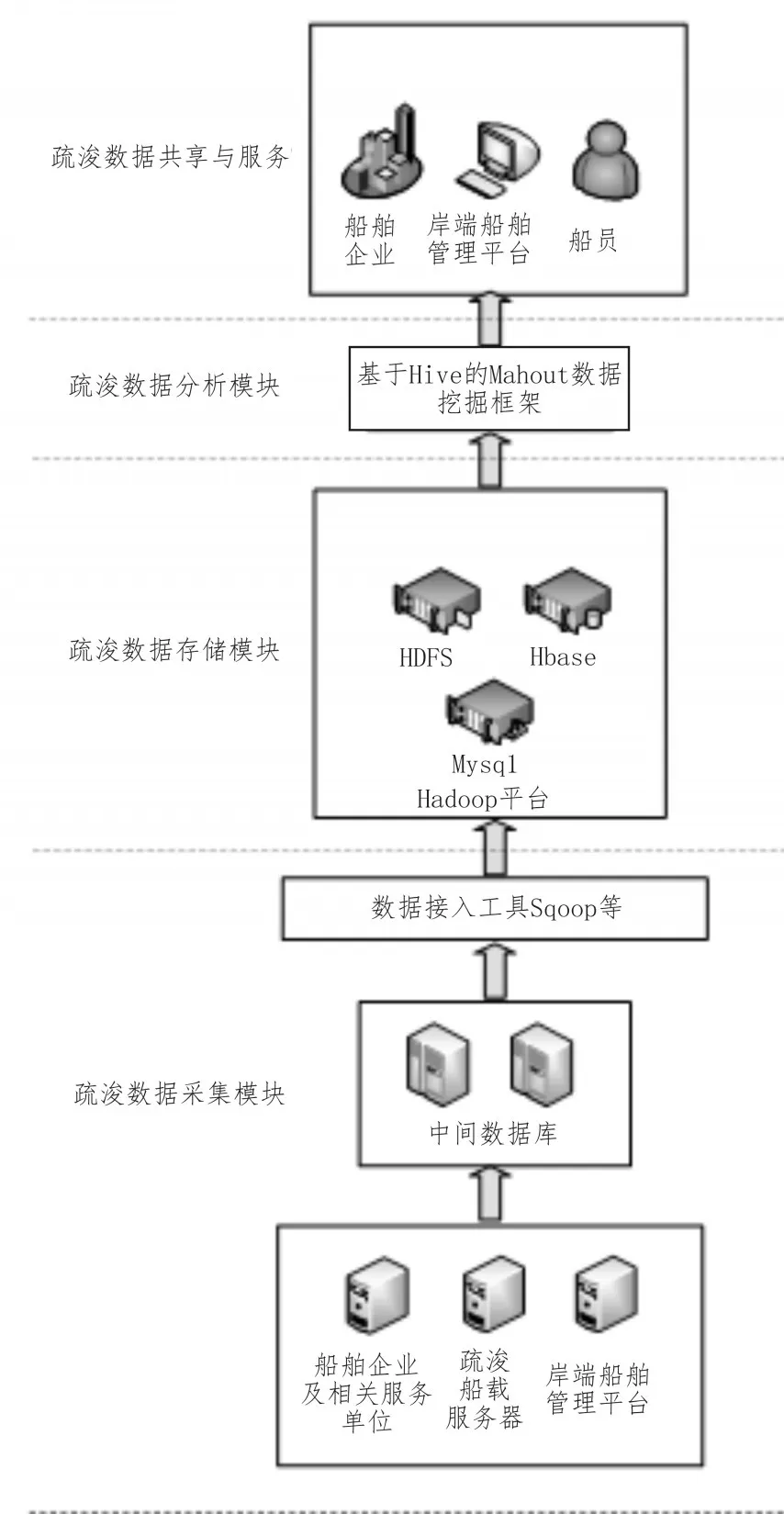
图1 挖泥船大数据平台架构图
3 挖泥船大数据平台数据采集模块
挖泥船大数据平台数据采集模块的任务是对挖泥船施工作业、航行等时刻的数据进行采集,由两个子模块组成:挖泥船端数据采集模块与异源数据库采集模块;挖泥船端数据采集模块主要是船载服务器;异源数据库采集模块则负责采集各个航道局、船舶企业及相关单位服务器中的数据,进行实时或者定期的数据同步与交换。
3.1 船端大数据采集
在挖泥船进行施工过程和航行过程中,数据采集系统会实时进行数据采集。传感器信号通过以太网络将数据发送到船载服务器;船载服务器一方面在本地经分析处理后存储到本地数据库[5],另一方面经过筛选压缩处理后的有效数据通过4G或卫星通讯与云端服务器通讯连接,实时地将数据发送至云端服务器[6]。
3.2 异源数据库采集
对于来源于分布在各地、各单位的异源数据库中的海量数据,需要进行实时或者定期的数据同步与交换,然而这些异源数据库任然是传统的关系型数据库RDBMS,需要用专门的数据接口进行数据接入[7]。基于对上述原因的考虑,挖泥船大数据平台数据采集模块集成了Sqoop、Flume等数据接入工具对多源异构数据进行接入。Sqoop与Flume是基于Hadoop生态圈的数据接入工具,专门用于传统数据库和Hadoop之间传输数据,通过数据库技术描述数据架构,从而在关系数据库、数据仓库和Hadoop之间转移数据[8]。
数据采集模块设置有中间数据库,在将海量数据从异源数据库中接入之后,中间数据库起到将所有数据从传统数据库导入到疏浚数据存储模块的过渡作用[9];疏浚数据采集模块将分布的、异构数源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到疏浚数据存储模块[10]。
4 挖泥船大数据平台数据存储模块
疏浚数据存储模块对采集到的船舶自身信息、设备状态信息、环境信息、工程管理信息等进行存储处理。疏浚数据存储模块具有高扩展性的分布式存储结构,存储模块以Hadoop分布式系统HDFS为底层存储,是具有分布式可扩展、高容错、高吞吐量的体系结构,提供层次化的存储和计算服务[11],可提高大数据管理平台的可扩展性和可靠性。此外,疏浚数据存储模块集成了分布式数据库Hbase和数据仓库Hive,具备了海量非结构化数据存储能力和结构化数据挖掘能力[6]。疏浚数据存储模块使用mysql存储用户信息;利用高度容错性能并且能提供高吞吐量的数据访问,非常适合大规模数据集上的HDFS文件系统存储文件;使用高可靠性、高性能、面向列、可伸缩的分布式数据库HBase对不同数据类型的异构数据进行加载存储[12],并用一种<key,value>形式处理不同数据,并且高效解决数据后台处理需求,同时集成分布式应用程序协调服务Zookeeper为HBase提供了稳定服务和失效转移机制。
5 挖泥船大数据平台数据分析模块
疏浚大数据在经过初步的ETL之后存储到存储模块,此时分析模块将对海量数据进行分析计算与数据挖掘。基于对大批量数据统计和分析的考虑,选用建立在Hadoop生态圈上的Hive进行离线分析[13]。分析任务大致有性能指标计算、分区计算、标准化计算和工艺点提取等;经过HIVE分析处理后提取出来的工艺点选用建立在Hadoop生态圈上的Mahout进行数据挖掘,并基于KMeans算法进行疏浚评估分析工作。
5.1 基于Hive的挖泥船大数据离线分析
Hive作为数据仓库的同时,也提供了对于海量数据进行统计分析的技术。Hive的核心机制是HQL语言,其原理类似于SQL语言,并将这些语言转化为MapReduce程序,从而在分布式计算机集群上进行执行。因此,Hive十分适合对于海量数据集进行统计计算。基于Hive的挖泥船大数据离线分析的步骤为:1)分区处理;2)产量指标计算;3)工艺点提取;4)标准化计算。
5.1.1 数据分区处理
挖泥船在进行疏浚作业的过程中,有两个最重要的阶段:装舱阶段和溢流阶段[14]。这两个阶段的施工工艺不同,性能指标不同,因而需要进行分区处理,即分为装舱区数据和溢流区数据。然而从挖泥船端采集来的数据是连续的,即挖泥船从开始挖泥到抛泥结束的全阶段数据,需要对存储在平台中的全阶段数据进行分区计算,并将数据分区之后再进行下一步分析。
Hive提供了允许用户扩展HQL的强大功能,即用户自定义函数(UDF)。用户通过JAVA编写用户自定义函数,从而满足自身的需求。一旦将UDF加入到Hive的交互式界面,就可以和使用内置函数一样地使用用户自定义函数。针对上述的分区需求,通过编写用户自定义函数来判断溢流筒的位置,当满足溢流的条件时即判断疏浚过程进行到了溢流阶段并将数据放入到溢流分区。Hive的分区表通过指定partition字段进行分区,在创建表的时候就创建了两个分区,即装舱区和溢流区。经过分区处理的数据以一种符合逻辑的方式进行组织,并且也提高了查询的性能,从而为进一步分析及后面的数据挖掘做好了准备。
5.1.2 产量指标计算
经过分区处理后的数据需要进行产量指标计算,用于后面基于Mahout的数据挖掘的聚类得到的簇评价分析、质量评估等。产量指标为干土吨生产率、泥沙存储率、干土吨质量比[15]。
根据上述的产量指标,通过JAVA编写对应的用户自定义函数,计算得到的指标值作为新列存储在原表中。
5.1.3 工艺点提取
依据疏浚作业判定,以分钟为单位从分区表提取以下工艺点信息:船速、泥泵转速、泥泵吸入真空、溢流筒高度和耙头对地角度。通过HQL的Select查询语句从分区表中获取工艺点信息的字段并创建一张新表用于存储工艺点。提取出的工艺点与原表中的数据分开存储,从而提高后续基于Mahout数据挖掘时查询与计算的效率。
5.1.4 归一化处理
提取出来的工艺点在进行数据挖掘之前需要进行归一化处理,从而消除工艺点信息之间的量纲影响,并解决数据指标之间的可比性。原始工艺点数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价[16]。以提取出的左泥泵压力(bar)、左泥泵真空(bar)、左泥泵转速(rpm)、左波浪补偿器压力(bar)、左耙头对地角度(°)、右泥泵压力(bar)、右泥泵真空(bar)、右泥泵转速(rpm)、右波浪补偿器压力(bar)、右耙头对地角度(°)为10个分析维度,使用Z分数法进行归一化处理,处理后的数据格式如图2所示。
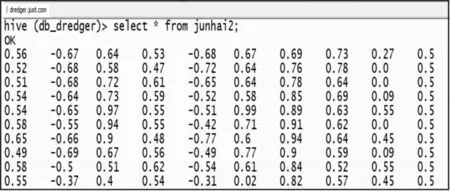
图2 归一化后的数据格式
5.2 基于Mahout的数据挖掘分析
Mahout是建立在Apache的Hadoop分布式计算上的一个分布式数据挖掘框架,它旨在当所处理的数据规模远大于传统数据分析软件所能够承受时,作为一种可选的机器学习工具。通过Mahout,可以实现许多数据挖掘领域的机器学习算法,如协同过滤、聚类和分类等,并且将其应用在处理大数据的分布式集群之上。
5.2.1 Mahout的K-Means算法简介
K-Means算法是数据挖掘领域的一个经典聚类算法。K-Means算法的任务是将给定的n个点聚到k个簇中。K-Means算法首先从包含k个中心点的初始集合开始,通过多次迭代并不断调整中心位置,直到符合算法的预期。
K-Means算法执行步骤流程图如图3所示。
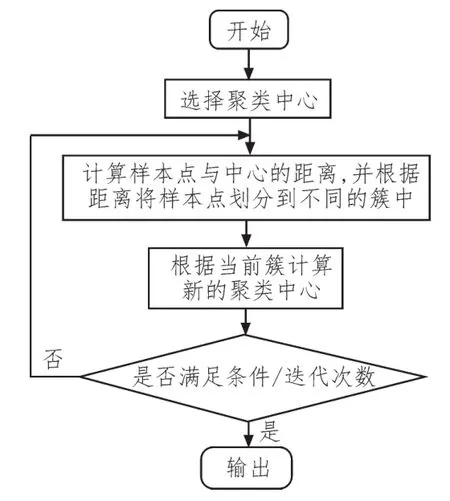
图3 K-Means算法流程图
因此,K-Means算法的核心可以归纳为:不断地计算寻找聚类中心,并计算样本点与聚类中心的距离,直到符合收敛条件时结束。其中距离是需要指定的,针对不同的数据类型选择不同的距离计算方法才能提高聚类的质量。下面以最常见的欧式距离为例,假设样本为n维向量,聚类内误差如式(1)所示:
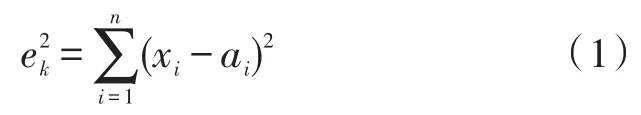
xi为第k个簇内样本点的第i维向量值,ai为中心点的第i维向量值,则整个K簇的聚类空间的收敛条件为:

当E的值最小时,即满足收敛条件,结束聚类。
5.2.2 基于K-Means算法的数据挖掘
在上述的基于Hive的离线分析部分中,挖泥船疏浚工艺点已经被提取出来并且进行了归一化处理。此时数据存储的格式是Hive默认的TextFile格式,由于Mahout要求输入的数据格式为向量格式,因此需要先对源文件进行序列化,序列化后的数据格式为SequenceFile格式。
选用JavaAPI的方式进行操作,具体步骤如下:
1)通过JDBC连接Hive数据库,获取归一化后的工艺点;
2)对工艺点序列化生成输入向量SequenceFile;
3)将工艺点向量写入HDFS文件系统输入目录;
4)写入初始簇的中心;
5)运行K-Means聚类作业;
6)从输出中读取簇。
5.2.3 基于K-Means算法的聚类结果分析
在K-Means算法作业完成后,聚类结果输出在result目录下,其中每次迭代的结果也在输出目录中;聚类的最终结果是序列化文件,需要通过反序列化读取聚类结果,如图4所示。
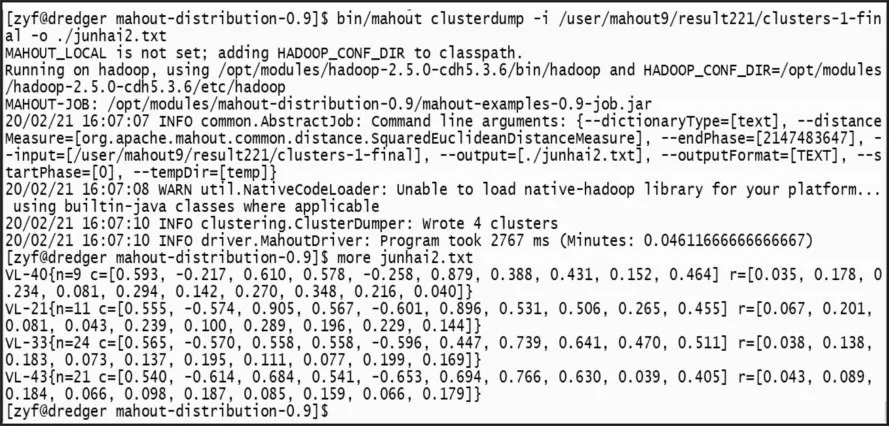
图4 聚类结果
通过查看最终次迭代完成的结果,可以看到聚类完成的4个簇,其中VL-21的21表示该簇的ID;c=[…]表示该簇的中心点;r=[…]表示该簇的半径;进一步查看各个簇及簇内的聚类结果,如图5所示。
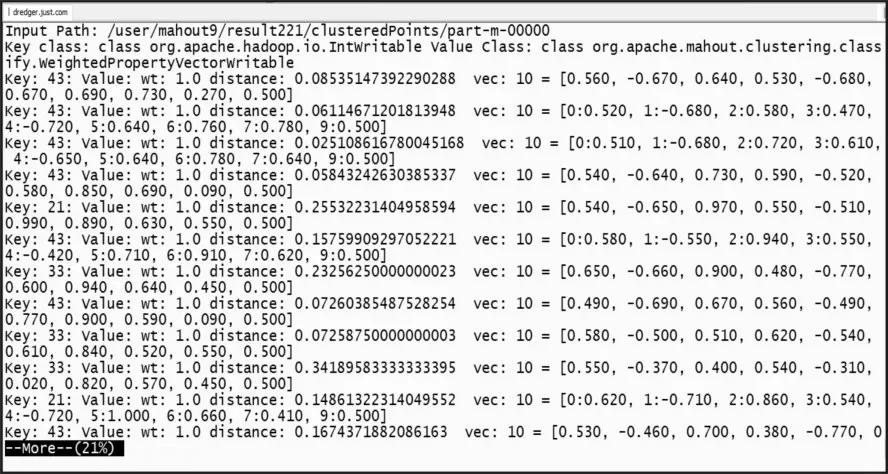
图5 簇内各点
聚类输出进行反归一化后4个聚类簇的中心如表1所示。
由聚类结果的簇中心进行分析,根据产量指标计算将不同的簇分为优、良、中、差。对所有数据进行聚类完成后,其中在优簇中的工艺点有17%,在良簇中的工艺点有32%,在中簇中的工艺点有37%,在差簇中的工艺点有14%。整理后的分簇工艺点分布如图6所示。
根据聚类结果以及工艺点在优良中差簇中的分布,对该船次疏浚性能评估按照多级分配权值方法进行计算。计算得到的疏浚性能分将存储在Hive表中。该表中记录了历史船次及其评分,并且将船次的评分进行排序,通过HQL查询语句可以将排名高的船次及评分展现出来,供操作人员参考。
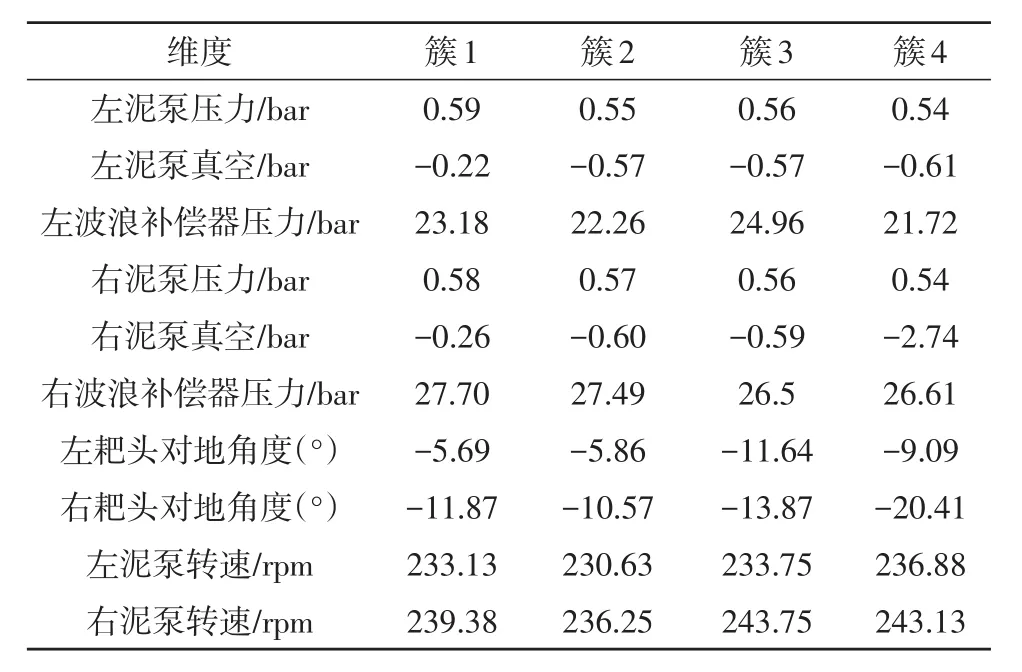
表1 疏浚工艺点聚类簇中心
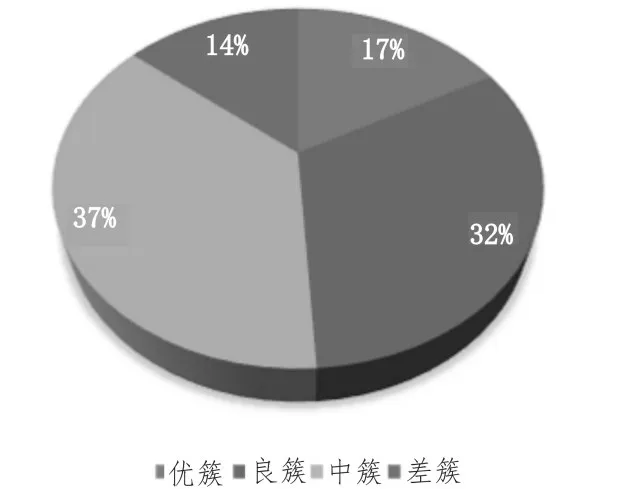
图6 疏浚工艺点簇分布图
6 结束语
文中基于Hadoop生态圈技术提出了一种挖泥船大数据平台架构,并对于构建挖泥船大数据平台的采集模块、存储模块与分析模块进行了研究。以工艺点聚类为例,实现了对挖泥船疏浚性能的分析评估。实验结果表明,基于Hadoop技术的挖泥船大数据平台对于海量挖泥船疏浚历史数据进行高效存储、提取和处理具有重要的现实意义。
