基于CNN的图像分类中激活函数的研究
2021-01-18张琴
张琴
(福州职业技术学院信息技术工程系,福州 350108)
0 引言
2012年Hinton教授小组在ImageNet视觉识别竞赛[1]中通过卷积神经网络(CNN)将错误率从原来的25%降到了16%之后,CNN的应用越来越广泛,主要包括计算机视觉、自然语言处理、语音识别等领域[2]。激活函数作为CNN中的一个重要模块,不仅为卷积神经网络提供了学习复杂分布所必需的非线性,而且可以有效抑制残差衰减并提高收敛速度,这也是CNN取得成功的关键[3]。研究者对CNN的研究工作高度重视,但其中存在一些困难和问题仍然没有很好的解决方法。例如,在网络结构设计和模型训练方面尚未形成通用的理论,需要依靠经验并花费大量时间进行调试,不断探索优化算法和最佳的参数;反向传播算法中存在“梯度消失”、“神经元坏死”等现象,导致模型无法进行有效的训练。本文通过分析各种常用激活函数的优缺点,结合激活函数在训练过程中的作用,给出激活函数在设计时需要考虑的要点,据此设计出了一种新的非线性非饱和的激活函数SReLU,该函数兼具Softplus函数和ReLU函数的优点,具有较强的表达能力和稀疏能力[4],且收敛速度快,识别率高。
1 常见的激活函数及特征
1.1 饱和非线性激活函数
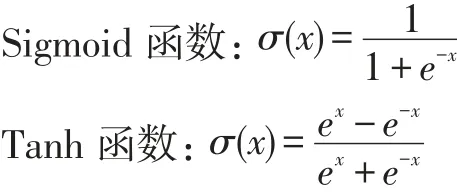
Sigmoid函数及其导数的图像如图1所示,从函数图像可以看出该函数能够把输入的连续实值变换为0和1之间的输出,即输出恒为正值,不是以零为中心的,这个特性会导致后面网络层的输入也不以零为中心,从而影响收敛速度。x为0附近的值时,激活函数对信号增益效果明显,但是当|x|的取值越来越大时,σ'(x)越来越小,容易导致梯度消失。Tanh函数也是一种常用的S型非线性激活函数,函数及其导数的图像如图2所示,它是Sigmoid函数的改进版。Tanh函数克服了Sigmoid非0均值输出的缺点,收敛速度较快,但是仍然无法解决梯度弥散的问题。由于这两个函数本身及其导数的计算都是指数级的,计算量相对较大。
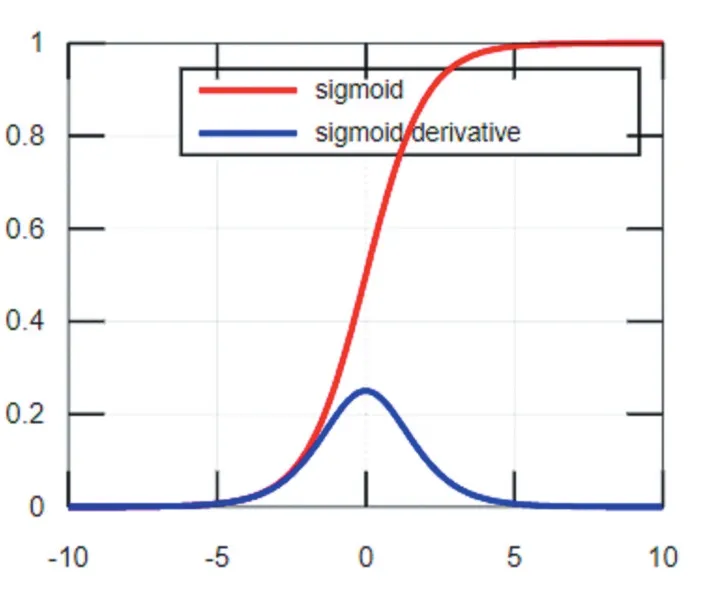
图1 Sigmoid函数及其导数
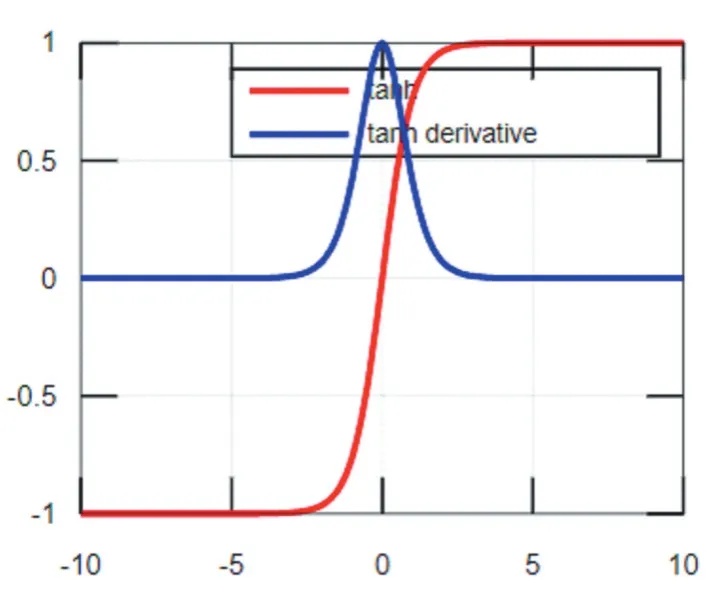
图2 Tanh函数及其导数
1.2 非饱和非线性激活函数
ReLU函数:σ(x)=max(0,x)
Softplus函数:σ(x)=ln(ex+1)
ReLU函数及其导数的函数图像如图3所示,由图可知ReLU函数具有分段线性性质,因此其前传、后传、求导都具有分段线性,相比于传统的S型激活函数,ReLU收敛速度更快。当输入值小于0时,ReLU函数强制将输出结果置为0,使训练后的网络模型具有适度的稀疏性,降低了过拟合发生的概率,但是稀疏性使模型有效容量降低,从而产生“神经元坏死”现象[5],导致模型无法学习到有效特征。Softplus是对ReLU近似光滑的一种表现形式,其函数图像如图4,它不仅可以把输入的数据全部进行非线性的映射,而且不会把一些有价值的信息隐藏掉,但是用Softplus函数作为激活函数,收敛速度很慢。
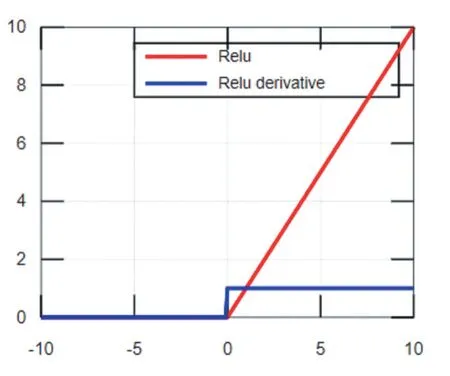
图3 ReLU函数及其导数
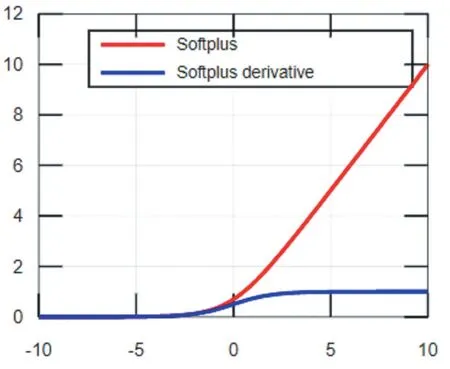
图4 Softplus函数及其导数
2 激活函数设计方法分析
前向传播和反向传播是卷积神经网络模型训练的两个主要步骤。前向传播是指数据从低层向高层传播,从输出层输出结果的过程。当前向传播得到的结果不符合预期的时侯,开始执行将误差从高层向低层传播训练,推导参数的学习规则,迭代改变参数,直到误差损失满足设定的精度的过程。通过对卷积神经网络训练过程进行分析,可以更好的理解激活函数在模型训练中的作用,帮助我们选择更加适合的激活函数。
(1)在前向传播过程中,对卷积层每一种输出的特征图xj有:

式中Mj表示选择输入特征图组合,σ是激活函数,是卷积核,bj是第j种特征图的偏置。由式(1)可知,在前向传播过程中,激活函数对上一层卷积操作的结果进行非线性变换,增强特征的表达能力。所以激活函数必须为非线性函数,此外,为了模型的训练速度,激活函数的计算应尽可能简便。
(2)反向传播的主要任务是对卷积核参数k和偏置b进行优化。根据BP算法,将损失函数分别对卷积核参数k和偏置b求偏导然后乘以学习率,可以得到参数的变化量Δk和Δb。误差代价函数对卷积核k求偏导:

误差代价函数对偏置b求偏导:

由(1)到(3)式可知,激活函数在卷积神经网络前向传播和反向传播中均起到巨大作用。在选择激活函数时应综合考虑激活函数自身及其导数的特点,具体如下:①激活函数必须为非线性函数。②激活函数自身及其导数的计算不可过于复杂。③为了保证网络参数能正常更新,应尽量避免选择软饱和激活函数,即具有性质的激活函数。④为了加快模型的收敛速度,参数的更新方向不应该被限制。选择一个取值即可以为正数也可以为负数的激活函数,可以加快收敛,参数更新也更加灵活。
3 改进的激活函数SReLU
改进后的激活函数SReLU是一种非线性非饱和的激活函数,兼具Softplus函数和ReLU函数的优点。在大于0的部分使用ReLU激活函数;为了激活负值,在小于0的部分,使用向下平移ln2个单位的Softplus激活函数。SReLU表达式为:f(x)=max(ln(1+ex)-ln2,x),函数图像如图5所示,SReLU激活函数保留了ReLU函数收敛快的优势,同时激活了负值,向前一层传播的信息也更多,缓解了“神经元死亡”的现象。
4 试验及结果分析
为了验证提出的SReLU激活函数在不同数据集中的有效性,分别在数据集MINIST和CIFA-100中使用SReLU及其他常见的激活函数进行训练分析。本试验基于Keras深度学习框架,通过损失函数下降曲线和在训练集、测试集、验证集上的准确率分析实验的运行状态。最终的实验结果表明:在MINIST和CIFA-100这两个数据集中使用SReLU激活函数均能够达到比其他常用激活函数更快的收敛速度和更高的准确率。
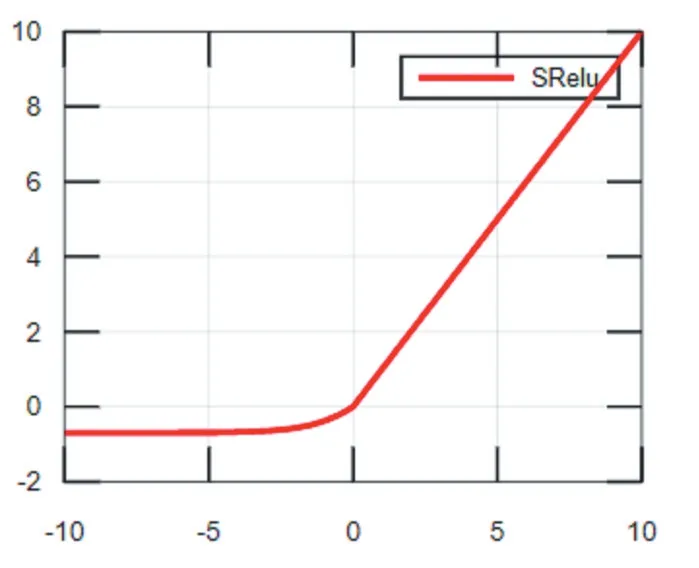
图5 SReLU函数
4.1 在MINIST数据集上实验结果及分析
MINIST数据集是一个简单的手写数字数据集,该数据集包含70000张28×28像素的灰度手写数字图片[7]。本次针对MINIST数据集的试验设计的网络模型结构由2个卷积层,1个池化层,1个全连接层和一个输出层组成。第一个卷积层通道数为32,Filter大小为3×3,,卷积步长为1。第二个卷积层通道数为64,Filter大小与卷积步长与第一个卷积层相同。池化层Filter大小为2×2,全连接层神经元个数为128,输出层使用Softmax回归,学习率设为0.001。实验结果准确率如表1所示,由表1可知,相比于经典的激活函数,提出的激活函数SReLU在训练集、测试集和验证集上均具有最高的精度。实验损失函数下降曲线如图6所示,在整个训练过程中Sigmoid函数的损失率最高,ReLU函数在前1000次迭代中损失下降最快,之后SReLU函数迭代损失下降速度逐渐高于ReLU,最终SReLU函数的损失最小,说明在MINIST数据集上基于SReLU激活函数的模型分类性能最好。
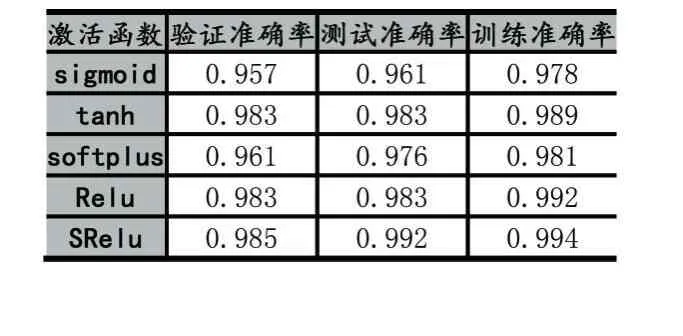
表1 SReLU在MINIST数据集上的准确率
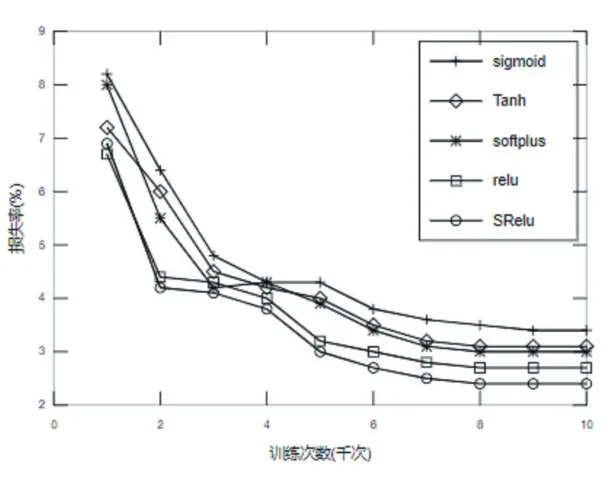
图6 SReLU在MINIST数据集上的损失率
4.2 在CIFA-100数据集上实验结果及分析
CIFAR数据集是一组用于普通物体识别的数据集,该数据集由来自100个分类的60000张32×32像素的彩色图片组成,每个分类包含500个训练样本和100个测试样本[8]。本次针对CIFAR-100数据集的试验设计的网络模型结构由4个卷积层,2个池化层,1个全连接层和一个输出层组成。第一、二个卷积层通道数为64,第三、四个卷积层通道数为128,四个卷积层Filter大小均为3×3,卷积步长均为1。2个池化层Filter大小均为2×2,全连接层神经元个数为512,输出层使用Softmax回归,学习率设为0.001。实验结果准确率如表2所示,由表2可知,在CIFA-100数据集上,相比于常见的激活函数,提出的激活函数SReLU在训练集、测试集和验证集上均具有最高的精度。实验损失函数下降曲线如图7所示,由图可知,相比于其他激活函数,SReLU函数在前2000次迭代中就达到了最快的收敛速度,最终SReLU函数的损失最小,说明在CI⁃FA-100数据集上基于SReLU激活函数的模型分类性能最好。
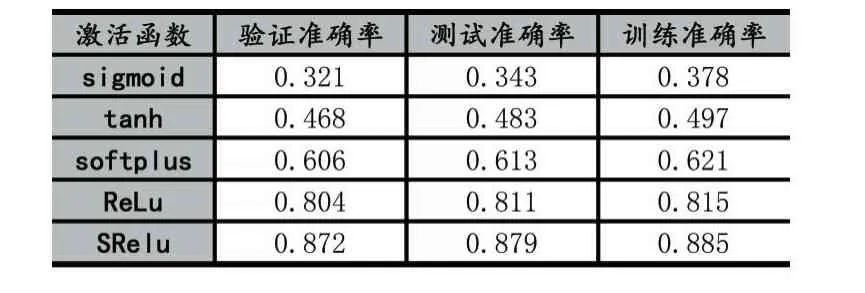
表2 SReLU在CIFA-100数据集上的准确率
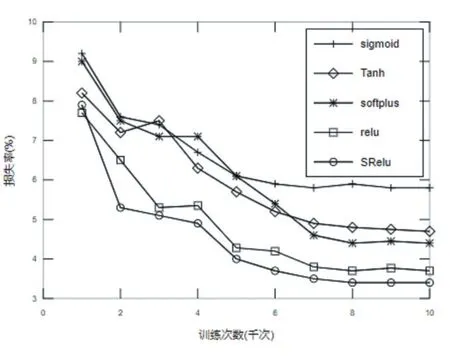
图7 SReLU在CIFA-100数据集上的损失率
5 结语
激活函数是卷积神经网络模型的重要组成部分,“激活的神经元”使卷积神经网络具备了分层的非线性特征学习能力。首先通过分析激活函数在前向传播和反向传播中的作用,给出了激活函数本身及其导数需要具备的一些特性,然后针对卷积神经网络中经典激活函数存在“梯度消失”、“神经元坏死”或不易收敛等缺陷,设计了一种新的非线性非饱和的激活函数SRe⁃LU,该函数保留了ReLU函数收敛快的优势,同时激活了负值,缓解了“神经元死亡”的现象。
