基于OCR的数字仪表自动识别在工业现场中的应用
2021-01-15刘志勇鲁乾鹏施方展王得磊杨鲁江
周 曼,刘志勇,鲁乾鹏,施方展,王得磊,杨鲁江
(浙江中控技术股份有限公司,杭州 310053)
0 引言
在流程工业现场的配方控制中,配方比例控制尤为重要,但因为各种因素,该环节难以直接自动化进行。在很多工业现场,各种原料均由工人使用电子称计重。需记录投料前重量,投料后重量并计算差额以计量投料量,最后在需要留档时人工录入电脑,这在一定程度上影响了效率和准确率。本文主要解决针对这些难以使用自动化计算投料量的场景,在不改动现场仪表的情况下,基于光学字符识别(Optical Character Recognition,OCR)对图像文件进行分析识别处理后,使用EAST全卷积神经网络进行文字检测,再使用CNN-LSTM-CTC进行文字识别,将图像数据经过模型运算后转换为数字数据,从而实现数字仪表的数据识别和记录。
1 OCR光学字符识别
计算机文字识别,俗称光学字符识别,英文全称是Optical Character Recognition(简称OCR),它是利用光学技术和计算机技术把印在或写在纸上的文字读取出来,并转换成一种计算机能够接受,人又可以理解的格式[1]。OCR技术是实现文字高速录入的一项关键技术,是对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。
传统上,图像预处理采用数字图像处理和机器学习(HOG)提取特征,但对复杂环境的泛化能力不强,本文中使用CNN的神经网络进行特征提取。
文字检测即使用先验知识对图像中的文本区域进行框选,常用的检测方法有:Faster R-CNN(基于区域的快速卷积网络方法)、FCN(Fully Convolutional Networks,全卷积神经网络)、RRPN(Rotation Region Proposal Network,旋转区域提议网络)、TextBoxes(文本框)、DMPNet(Deep Matching Prior Network,深度匹配先验网络)、CTPN(Connectionist Text Proposal Network,连接文本提议网络)、SegLink(Segment link,切片链接)、EAST(Efficient and Accurate Scene Text Detector,高效文本检测),本文采用EAST高效文本检测方法。
文本识别是将当前字符提取的特征向量与特征模板库进行模板粗分类和模板细匹配,识别出字符的算法。本文采用CNN(Convolutional Neural Network,卷积神经网络)-LSTM(Long Short Term Memory,长短期记忆网络)-CTC(Connectionist Temporal Classifier,联接时间分类器)相结合的方法,即CNN-LSTM-CTC进行文本识别。
1.1 EAST全卷积神经网络文字检测
EAST[2]的网络结构总共包含3个部分:特征提取分支(feature extractor stem),特征合并分支(feature-merging branch) 以及输出层(output layer)。
在特征提取分支部分,主要由四层卷积层组成。在特征合并分支部分,这里采用的是反池化的操作,首先经过一层反池化操作,得到与上一层卷积特征图(feature map)同样大小的特征,然后将其余进行拼接,拼接后再依次进入一层和的卷积层,以减少拼接后通道数的增加,得到对应的特征图。在特征合并分支的最后一层,是一层的卷积层,卷积后得到的特征图(feature map)最终直接进入输出层。之所以要引入特征合并分支,是因为在场景文字识别中,文字的大小非常极端,较大的文字需要神经网络高层的特征信息,而比较小的文字则需要神经网络浅层的特征信息。因此,只有将网络不同层次的特征进行融合才能
满足这样的需求。在输出层部分,主要有两部分:一部分是用单个通道的卷积得到分数图(score map),另一部分是多个通道的卷积得到几何形状图(geometry map),在这一部分,几何形状可以是旋转盒子(RBOX)或者四边形(QUAD)。对于RBOX,主要有5个通道,其中4个通道表示每一个像素点与文本线上、右、下、左边界距离(axisaligned bounding box,AABB),另一个通道表示该四边形的旋转角度。对于QUAD,则采用四边形4个顶点的坐标表示,因此总共有8个通道。
1.2 CNN-LSTM-CTC文字识别
CNN-LSTM-CTC[3-5]基于卷积神经网络的长短期记忆连接时间分类器是处理不定长文字的常用方法之一。不定长文字在现实中大量存在,由于字符数量不固定、不可预知,因而识别的难度也较大,这也是目前研究文字识别的主要方向。常用的不定长文字识别方法有:CNN-LSTM-CTC、CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络)、chinsesocr(基于yolo3:用于文字检测、crnn:用于文字识别的自然场景文字识别项目),本文采用CNNLSTM-CTC方法。
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的循环神经网络;(Recurrent Neural Networks,RNN),用于解决RNN的长期依赖问题。由于随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或是“梯度爆炸”的现象。LSTM单元由输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)组成[3,4]。
CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。由于文字存在不同间隔或变形等问题,导致文字有不同的表现形式,但实际上都是同一个文字。在识别时会将输入图像进行分块后再去识别,得出每块属于某个字符的概率,其中对于无法识别的标记为特殊字符“-”。由于字符变形等原因,导致对输入图像分块识别时,相邻块可能会识别为同一个结果,从而导致字符重复出现。因此,通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同一个字符连续出现,则表示只有一个字符,如果中间有间隔字符,则表示该字符出现多次)。因此,通过CTC就解决了输入特征与输出标签的对齐问题。
1.3 数据增广
数据增广常用的方法有:镜像(flip)、旋转(rotation)、缩放(scale)、裁剪(crop)、平移(translation)、高斯噪声(gaussion noise)、图像亮度、饱和度和对比度变化,PCA Jittering,Lable shuffle,SDA,生成对抗网络(generative adversi network)等。本文中主要用到的数据增广方法有旋转、平移、加阴影、加高光、加模糊、加畸变与加色彩转换等方法。

图1 现场称重仪表图像Fig.1 Image of the on-site weighing instrument
2 工业现场应用与结果分析
本文中以某涂料厂的电子称重仪为例拍摄相关的图像,由于现场存在多种称重设备,拍摄角度和光照情况以及仪表屏幕常有反光、阴影和畸变,各类仪表字体字形颜色差别较大,如图1所示。
针对原始图像进行预处理,本文中采用的预处理方法为Canny边缘检测后采用闭运算即先膨胀后腐蚀的方法后,进行灰度化和二值化到预处理后的图片。此后通过EAST文本检测和CNN-LSTM-CTC基于卷积神经网络的长短期记忆连接时间分类器处理得到最后的识别数据,如图2所示。
使用基于RESNET的EAST网络进行训练。在测试中发现,对已经预训练好的EAST网络进行迁移训练,根本无法达到预期效果,有可能是因为已经陷入局部最优点无法在使用场景下工作。之后只加载了RESNET[6]的特征提取网络,再重新训练了EAST网络,效果能达到预期,在测试集中可以达到95%以上准确率。在训练中数据扩增十分重要,加入随机的旋转与截取,使数据集扩增3倍以上,使最终结果更加稳定。使用两路泰坦GPU,训练时间在7个小时左右收敛。
识别模型负责从已经截出的文字区域中识别出数字,采取CNN-LSTM-CTC的结构。CNN负责提取数据,LSTM从左向右扫描特征序列之后用CTC[7]进行解码,获得识别结果。
本文采用现场采集的仪表原图,随机选取80%,经过数据增广后得到共8000张图片用于文字检测模型训练,剩下的20%原图即2000张图片用于进行文件检测的测试。文字识别时采用14000张图片进行模型训练,1500张图片用于测试。经测试该模型有较好的准确率,对小数点也比较敏感,整体识别率95%以上。为了使结果更加稳定,依旧采用了图像扩增,扩增包括旋转、平移、加阴影、加高光、加模糊、加畸变与加色彩转换。使用两路泰坦GPU,训练时间在两个小时左右收敛。
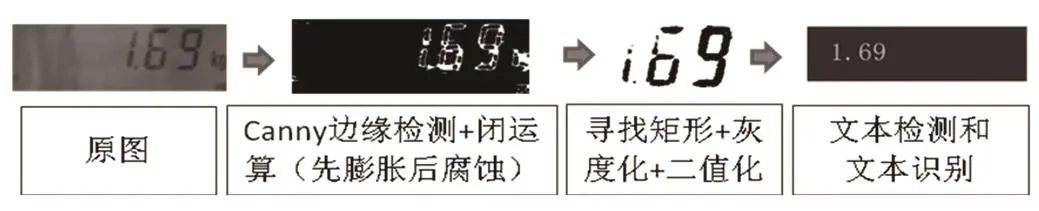
图2 图像处理过程图Fig.2 Image processing process diagram

图3 现场PDA采集图像和解析识别图Fig.3 On-site PDA image collection and analysis and recognition diagram
在终端部署时,由于现场采集图像的PDA计算能力有限,必须选用“终端采集,服务端计算”的模型。值得注意的是为了运行java版本的tensorflow与opencv,java需要到1.8以上,需要安装vcredist组件。在接口设计中,提供了多种调用模式,可以直接将BASE64编码的照片传入或将文件的路径传入之后直接返回识别结果,示例如图3所示。由于现场处理器性能充足,从PDA上传到得到结果在1s以内完成。
3 结束语
基于OCR的数字仪表自动化识别在工业现场中存在较大需求,本文针对某涂料厂的数字称重仪上采集的图像进行图像预处理后,再采用EAST全卷积神经网络进行文本检测后,通过CNN-LSTM-CTC基于卷积神经网络的长短期记忆连接时间分类器进行文本识别,得到较好的识别效果,采用“终端采集,服务端计算”的方式实现快速解析识别结果,满足现场应用需求。
