基于Bert语义的图书馆自动咨询方法研究
2021-01-09段苏凌






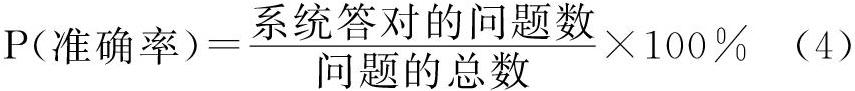
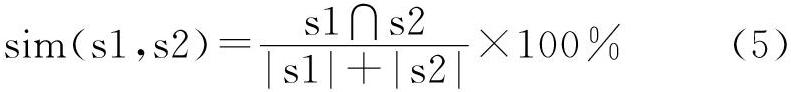
摘要:自动咨询服务是实现图书馆自动化的重要手段,而传统的图书馆咨询服务系统面临咨询服务满意度较低的问题。针对问题,文章提出基于Bert语义的图书馆自动咨询方法,该方法首先利用问句理解模块对问句进行语义分类,其次采用问句检索模块对读者提出的问题进行匹配,随后通过预训练模型Bert进行答案句生成。在真实的问题数据集上进行测试,文中所提出的方法咨询性能优于传统的咨询方法,准确率有了较大提高。
关键词:图书馆; 自动咨询; Bert语义; 答案生成
中图分类号:G250.7 文献标识码:A
DOI: 10.13897/j.cnki.hbkjty.2021.0097
0 引言
自动咨询服务是实现图书馆自动化的重要手段,它是图书馆开展信息服务、普及专业知识的重要工具[1]。在传统的信息咨询服务模式下,图书馆员能否为读者提供满意的咨询服务,往往取决于图书馆员对图书馆各方面的了解以及沟通能力。由于不同馆员的沟通能力和知识水平不同,往往导致咨询服务不满意甚至有投诉现象的发生。此外,读者经常询问一些重复的问题,导致咨询服务的图书馆员工作量过大。可见,构建一个高效的图书馆自动咨询系统是解决这类问题的有效途径。
近年来,人工智能技术的快速发展,逐渐改变了传统的信息咨询服务模式,特别是深度学习技术在自然语言处理领域的成功应用,为图书馆智能咨询系统的设计和开发提供了新的思路。针对传统图书馆咨询服务的不足,本文提出了基于Bert语义的图书馆自动咨询方法,构建了图书馆智能咨询系统,为国内图书馆智能咨询服务提供了一种新的解决方案。
1 研究现状
随着互联网和数字技术的发展,图书馆的信息咨询服务也有了长足的进步[2 3]。图书馆不同类型的咨询服务系统实现方法存在一定差异。目前,传统咨询系统中主要包括问题理解、信息检索和答案生成3个模块[4],这些模块的实现方法属于传统模型。例如,问句理解模型常用基于支持向量机的分类模型[5]、KNN模型[6]以及最大熵模型[7]等,信息检索模型通常使用BM25模型[8]、向量空间模型以及语言模型[9]等。答案生成模块通常使用基于QANet的序列标注模型[10]以及候选答案验证过程中使用的BIDAF[11]问答匹配模型等。这种基于传统模型的问答系统往往需要人工进行特征标注,因此这种方法缺少针对不同领域数据处理的泛化能力。由于传统模型的缺点,在面对不同种类的咨询问题时,图书馆馆员不得不对数据进行人工标注,并且标注的准确度直接依赖图书馆馆员的经验,这就造成了传统的咨询系统满意度较低的现象。
近年来,随着深度学习技术的发展,为图书馆自动咨询系统提供了新的思路和解决方案,深度学习模型的优势在于能够自动捕获文本的有效信息,使得图书馆咨询系统中很多语义鸿沟问题得到一定程度的改善或解决。端到端的深度学习模型减轻了人工标注的大量工作,灵活多变的深度网络结构提供了强大的文本建模能力。本文借助深度学习方法对咨询系统中的各个模块进行建模,试图缓解图书馆咨询系统中的语义鸿沟问题,提升图书馆咨询系统的性能。
2 方法描述
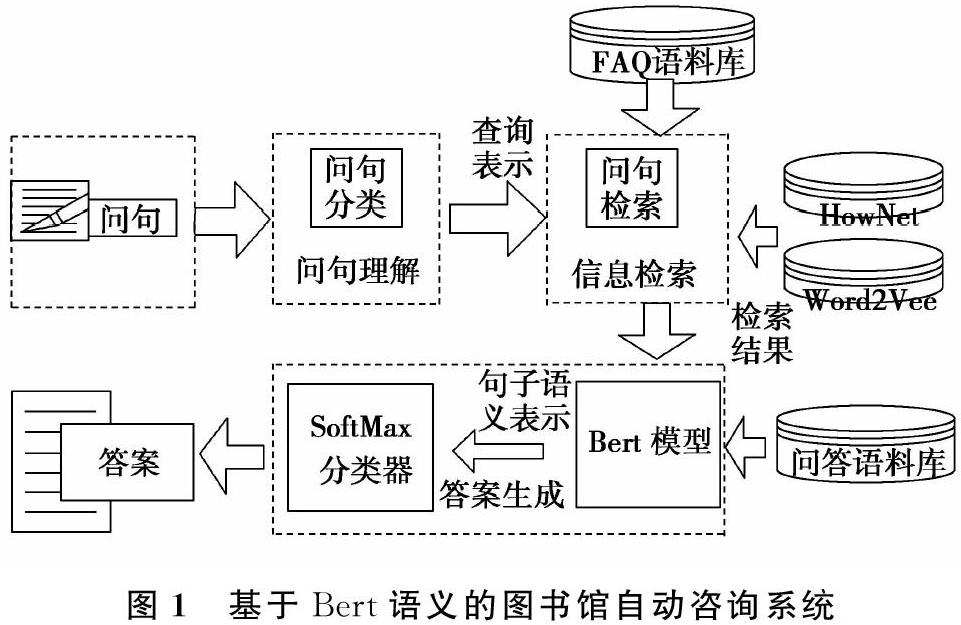
依据数据流在图书馆领域咨询系统中的处理流程,本文所构建的图书馆自动咨询系统主要包括3个模块,包括问句理解、信息检索、答案生成三个功能组成部分,如图1所示。首先,问句理解模块采用问题分类的方法对问题进行语义理解和划分。随后,根据问句理解得到的查询表示,信息检索模块借助语义词典HowNet和词向量知识库,从FAQ语料库中检索相关信息,传递给后续的答案生成处理模块。通过检索模块得到的信息,答案生成模块利用BERT模型对本文进行语义理解和推理,实现候选答案的抽取和答案的生成。最终,根据读者提出的问题返回简洁性、正确性的答案。
2.1 问句分类
问句理解模块是问答系统了解用户意图的重要环节,问题分类就是对于给定的问题,根据问题的答案类型把该问题映射到给定的语义类别中。问题分类作为问答系统的一个重要子模块,是咨询系统所要处理的第一步,对咨询系统的后继模块答案抽取和答案选择有很好的指导作用。首先,问题分类能够决定答案选择策略,根据不同的问题类型调节对不同问题的答案分析策略。其次,问题分类能有效地减少候选答案的空间,提高咨询系统返回答案的准确率。
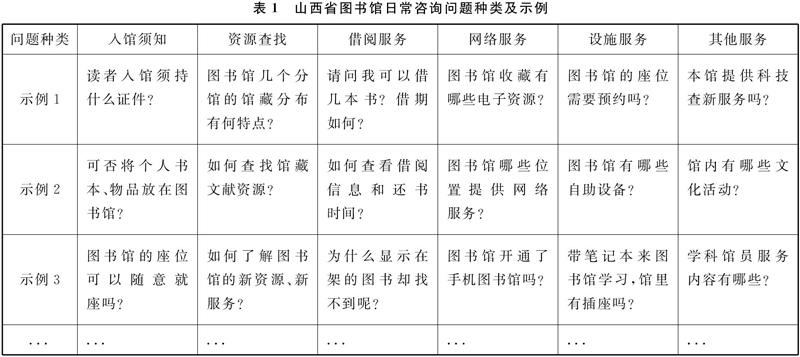
为了测试本系统问题分类模块的功能,本文整理了近5年山西省图书馆的日常咨询问题,将常见问题分为6类,如表1所示:
本文采用目前在分类问题上应用较多的卷积神经网络CNN[12](Couvolutional Neural Networks)模型对问题进行语义层面的表示,完成对问题的有效分类。将问句以字的形式输入模型中,通过卷积层、池化层和全连接层,最后通过softmax 函数确定每个类别的概率,最终输出每个问题所对应的语义类型,CNN网络结构如图2所示。
2.2 问句检索
当读者提出的问题进入信息检索模块,检索模块检索常用问题集合(FAQ语料库),通过计算FAQ知识库中问题与用户提出问句的相似度,将相似度大于一定阈值的问句作为结果。如果找到相似的问句,则返回FAQ知识库中对应的候选答案,如果没有找到相似的候选句,则将检索结果输入答案生成模块。
在进行问句相似度计算时,传统的方法采用关键词浅层匹配,导致与问句语义相关的候选问句相似度很低。例如,用户提出问题“带电脑来图书馆工作,是否可以接外接電源?”,与常用问题集合中“带笔记本来图书馆学习,馆里有插座吗?”问题语义相关,但是在关键字层面匹配度较低。在语义词典和词向量空间中,“电脑”与“笔记本”、“学习”与“工作”、“插座”与“电源”等词语的语义距离较近。
2.3 答案生成
通常读者提出的问题种类繁多,涉及到图书馆或者日常生活中的方方面面,经常有一部分问题不在常用候选数据集中出现。对于这些问题,检索模块无法将答案检索出来。针对该问题,文本提出一种基于BERT的答案生成模型,对不常见问题进行答案生成。首先利用问答语料库中的问题—答案对模型进行训练,Bert模型可以对问题和答案进行语义表示和推理。随后,将读者提出的问题输入训练好的模型,通过Bert语义模型对读者的咨询问题进行答案生成。该问题不仅包含分词后的问句,而且包含问题的语义类别,本文认为,问题的语义类别可以帮助Bert模型进行语义理解和推理,提高问答系统返回答案的准确率。
2.3.1 Bert模型
Bert模型的输入特征:每个句子首部都会添加一个特殊符号“[CLS]”。文本将问题理解模块中预测的语义类别加在符号“[CLS]”前面。为了对不同的句子进行区分,在输入序列中每个句子的末尾加入了特殊符号“[SEP]”。由于本文的任务是进行图书馆咨询解答,因此输入序列是由两个句子组成的句子对,即问句—答案候选句。Bert模型的输出特征:经过多层编码器对应的融合问句和答案候选句信息的语义表示。
3 实验
3.1 实验数据及评价指标
本文的主要工作是设计并实现一种基于深度学习的自动咨询方法,辅助图书馆馆员解决读者在获取和使用图书馆资源或者学术知识时遇到的疑问。根据山西省图书馆办证咨询台近五年读者提出的常用问题,本文构建了常见问题库(FAQ语料库),该问题库包括常用问题以及问题解答532对,内容覆盖入馆须知、资源查找、借阅服务、网络服务以及设施服务等。此外,为了弥补常见问题库不能覆盖所有读者提问的不足,本文使用大规模中文语料库对答案生成Bert模型进行训练,选取了百度发布的大规模中文问答语料 DuReader[16]数据集。该数据来源于百度知道和百度搜索中的真实问题及回答,本文的实验选取了观点类型和描述类型的数据,总计包括98 215个问答对,设计内容包括日常生活中的方方面面。
采用五倍交叉实验,将语料平均分成五份,使用其中一份作为测试集,其他四份作为训练集,重复五次实验,取平均值作为最终结果。在实验中,将测试集中的问题提交给咨询系统 ,让系统自动地给出答案。然后把系统自动找出的答案和测试集中的答案进行对比。如果问答系统给出的答案通过人工的对比基本正确 ,则可以判断这个答案是正确的 ,否则可以判断这个答案是错误的。这样就可以计算出咨询系统的回答准确率 ,公式如下:
3.2 模型参数设置
在问句检索模块,β1:β2=0.4:0.6用来调节语义字典和词向量权重对句子相似度影响。在答案生成模块,BERT预训练模型是Google开源的BERT-base模型,网络结构共12层,隐藏层有768维,采用12多头注意力机制,学习率设置为0.00004,句子最大长度设置为40,迭代轮数epoch设置为10,批量大小Batch_size设置为128。
3.3 实验结果及分析
3.3.1 不同问句检索方法比较
为了验证本文所提出的问句检索方法的有效性,同时为了与其他问句相似度计算方法进行比较,本文将基于关键字匹配作为基线方法(baseline),公式如下所示:
即计算两个句子共现的关键词个数与两个句子词个数的比值,数值越大,表示两个句子越相似。本文将各种方法在常见问题库数据集上进行实验对比,实验结果如表2所示。
在表2中,本文將各种问句检索方法进行对比。当分别使用基于HowNet和Word2Vec进行句子相似度计算时,咨询系统的准确率都比基于关键词匹配的准确率高,说明两种方法都可以克服关键词匹配方法的不足。当使用本文所提出的方法,综合利用两种相似度匹配方法时,系统的准确率进一步上升,说明语义词典和词向量可以相互弥补各自的弱点。此外,在咨询效果最好时,β1:β2=0.4:0.6,说明词向量要比语义字典的权重更大,这是由于词向量是在真实语料库中训练的,比语义字典更加适合句子相似度计算。
3.3.2 Bert模型与其他答案生成模型比较
为了验证本文所提出的Bert答案生成模型的有效性,同时为了与答案生成方法进行比较,我们选取 BIDAF 模型[11] 和 QANet模型[10]与本文方法进行对比。实验结果如图4所示。
BIDAF模型使用字符嵌入和词嵌入相结合的方式,并且在模型中引入双向注意力,最后通过指针网络输出答案片段。 QANet模型引入位置编码来表示序列关系,编码层将自注意力机制和卷积神经网络相结合,将三个与编码层相同的结构模块叠加,输出答案片段。
在大规模中文问答语料库DuReader上进行测试,Bert模型的咨询效果优于其他两种答案生成模型,准确率达到了74%,这是由于Bert模型采用了目前流行的特征提取器Transformer,同时还实现了双向语言模型,集成了深度学习模型的优点,从而使该模型在对答案句进行筛选、理解和推理方面更加具有优势。此外,本文将山西省图书馆的常见日常咨询问题分为6类,把问题的语义类别进行预测并将其融入Bert模型后,咨询系统的准确率进一步上升,准确率达到了76%。说明本文对问题进行语义划分是有意义的,同时在系统中引入问题的语义类别对答案生成具有一定的促进作用。
5 结语
本文提出了基于Bert语义的图书馆自动咨询方法,该方法首先利用问句理解模块对问句进行语义分类,其次采用问句检索模块对读者提出的问题进行匹配,随后利用预训练模型Bert生成答案句。该方法可以有效弥补传统图书馆咨询系统所面临的语义鸿沟问题,在一定程度上提高了图书馆咨询服务满意度。目前,图书馆咨询问题语料较少,针对图书馆咨询问答任务的预训练模型还不够完善。在未来的工作中,一方面要利用数据增强的方法扩充数据,另一方面还要将语言学知识融入预训练模型Bert中,进一步提升系统咨询效果。
参考文献
[1]刁羽. 基于小数据的高校图书馆智库型信息咨询服务模式研究[J]. 图书馆工作与研究, 2019 (8):84-88.
[2]李慧芳, 孟祥保. 近十年国内外图书馆资源发现系统研究与实践进展述评[J].图书情报工作,2020,64(6):122-131.
[3]姚飞, 纪磊, 张成昱,等. 实时虚拟参考咨询服务新尝试——清华大学图书馆智能聊天机器人[J]. 现代图书情报技术, 2011(4):77-81.
[4]莫少强. 数字图书馆参考咨询服务系统的建设与服务[J]. 图书情报工作, 2004(1):12-15.
[5]张宇, 余正涛, 樊孝忠, 等. 基于支持向量机的汉语问句分类[J]. 华南理工大学学报(自然科学版), 2005(9):25-29.
[6]贾可亮, 樊孝忠, 许进忠.基于KNN的汉语问句分类[J]. 微电子学与计算机, 2008(1):162-164.
[7]牛彦清. 中文问答系统的问句分类研究[D].山西:太原理工大学,2011.
[8]胡国平. 基于超大规模问答对库和语音界面的非受限领域自动问答系统研究[D].合肥: 中国科学技术大学,2007.
[9]杨海天, 王健, 林鸿飞. 一种基于主题类别信息问句检索的新方法[J]. 计算机应用与软件, 2015(2):24-27.
[10]Yu A W , D Dohan, Luong M T , et al. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension[J].Computational Linguistics,2018,13(3):55-75.
[11]Seo M , Kembhavi A , Farhadi A , et al. Bidirectional Attention Flow for Machine Comprehension[J]. Computational Linguistics,2016,15(2):32-52.
[12]MD Zeiler, Fergus R . Visualizing and Understanding Convolutional Neural Networks[C]// European Conference on Computer Vision.Springer International Pu-blishing, 2013.
[13]Dong Z , Dong Q , Ebrary I . Hownet and the Computation of Meaning[J]. Journal of Artificial Intelligence Research,2015,11(5):22-30.
[14]Ling W, Dyer C, Black A W, et al. Two/too simple adaptations of word2vec for syntax problems[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2015: 1299-1304.
[15]Devlin J,Chang M W,Lee K,et al.BERT:Pretraining of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Volume 1,2019:4171-4186.
[16]He W, Liu K, Liu J, et al. DuReader: a Chinese Machine Reading Comprehension Dataset from Real-world Applications[C]//Proceedings of the Workshop on Machine Reading for Question Answering. 2018: 37-46.
作者簡介:段苏凌(1987 ),女,硕士,山西省图书馆馆员。研究方向:读者服务、参考咨询、智能图书馆建设。
(收稿日期:2021-07-20 责任编辑:张长安)
