图的度量维数问题的0-1 蚁群条件着色分辨算法研究
2021-01-09赵海霞
武 建, 赵海霞
(1- 太原理工大学信息与计算机学院,太原 030600; 2- 山西财经大学应用数学学院,太原 030006;3- 山西财经大学统计学院,太原 030006)
1 引言
设图G = (V(G),E(G))是顶点集和边集分别为V(G)和E(G)的简单连通图.任意顶点u,v ∈V(G)的距离是指顶点u, v 之间最短u −v 路径的长度,记作dG(u,v).任意两个顶点u,v ∈V(G)构成的顶点对记作p(uv = vu).若u 与v 相邻,则uv ∈E(G).否则,uv /∈E(G).经典图着色理论的本质是对顶点进行分类,即用不同颜色组成的颜色集对顶点进行分类.因而,将图顶点分为两类的一种途径是:给定颜色集{0,1}(两种不同颜色的标号),为所有顶点分配颜色0 或颜色1.本文称这样的顶点着色为图的一个0-1 着色.其他术语见文献[1].
化合物分子分类问题是化学领域的一个重要研究课题.化合物分子分类研究的一个基本问题是如何表征每个化合物分子[2].图是研究这一问题的有力工具.每个化合物分子按照内部化学结构可以转化为一个图,简称分子图.根据化合物分子的性质,通过建立适当的距离度量,各个化合物分子之间的关系可以转化为各个图之间的关系.在选定的距离度量下,若两个图之间距离为1,则在两个图之间连接一条边.按照这种连接关系,大型的化合物分子库就构成了一个以每个分子图为顶点的大型复杂网络,简称分子网络.化合物分子分类研究的基本问题就是表征分子网络的每个顶点.解决该类问题的一种途径是为分子网络建立一个表征系统.
假设化合物分子库中有n 个化合物分子.其对应的分子图分别为G1,G2,··· ,Gn.选定距离度量dH,并建立分子网络H.在分子网络H 中,按照一定顺序选择k(< n)个分子图构成有序分子图簇S = {Gi1,Gi2,··· ,Gik}, ik∈{1,2,··· ,n}.分子网络的每个分子图Gj(j ∈{1,2,··· ,n})依据其到有序分子图簇S 中每个元素的距离度量dH,与一个k-维距离向量rdH(Gj|S)对应.即
rdH(Gj|S)=(dH(Gj,Gi1),dH(Gj,Gi2),··· ,dH(Gj,Gik)).
对于任意的分子图Gl, Gm, l ̸= m ∈{1,2,··· ,n},若rdH(Gl|S) ̸= rdH(Gm|S)成立,则每个分子图与一个唯一的k-维距离向量对应.分子图簇S 即可作为分子网络的一个表征系统.如何找到一个包含元素最少的表征系统即为图的度量维数问题.本文在一般简单连通图上研究图的度量维数问题,即在一般图上建立图的最优表征系统.
图的度量维数问题是在机器导航、声呐系统布置、化学等多个领域有着广泛的应用背景的组合优化问题[2-6],也是关于图的距离主题的研究热点之一.特殊图类上的度量维数研究见文献[7-14].度量维数问题在研究内容和研究方法上的拓展见文献[15-23].图的度量维数问题的算法研究较少.为了解决该问题,本文提出了反映图的分辨特性的分辨表结构,并导出了图的顶点分辨域、分辨度概念(见第2.2 节).与图的顶点邻接关系相比较,实际复杂网络的分辨表是易得的.因而,图的分辨表是研究图的分辨特性的有力工具.同时,本文在拓展经典图着色分类思想的基础上,建立了图的度量维数问题的非线性计算模型(见第2.3 节).通过设计与问题背景相一致的运行参数(见第3.1 节至第3.6 节),建立了求解模型的0-1 蚁群条件着色分辨算法(见算法3.2).
本文通过数值对比分析验证算法的有效性:
1) 通过求解特殊图类的度量维数,验证了本文提出的分辨域限制条件、修补技术、局部搜索对提高算法求解质量有较大影响;
2) 通过与整数规划算法计算结果的对比验证了本文算法具有较好的表现;
3) 在特殊图类和随机图上的计算结果比较分析表明全局搜索和局部搜索的结合策略较大程度的改进了算法求解质量,但在规则图上提高算法求解质量具有一定挑战;
4) 与遗传算法[24]计算结果相比较,本文提出的算法不仅在求解质量方面有所提升,而且在最坏的情况下能为图提供极小分辨集;
5) 通过定义评价指标,主要探索了蚂蚁候选顶点集选取比例系数对算法求解质量的影响,并给出了进一步研究课题.一般蚁群算法及其参数分析见文献[25-28].
2 图的度量维数问题及其0-1 着色分辨模型的建立
2.1 问题描述
给定简单连通图G=(V(G),E(G)).对任意顶点u, v, x ∈V(G),若它们满足则称顶点x 可分辨顶点对u, v,或称uv 是顶点x 的一个可分辨顶点对,记作x®uv.若任意顶点对u, v ∈V(G)可由有序顶点子集S ⊂V(G)中的至少一个顶点分辨,则称S 是图G 的一个分辨集.基数(所含顶点数)最小的分辨集为图的一个基,其对应的基数为图的度量维数,记作dim(G).确定任意连通图的度量维数及其基的问题就是所谓的图的度量维数问题.
dG(u,x)̸=dG(v,x),
2.2 顶点的分辨域
假设图G 的所有不同顶点对构成的集合为PG,即

对于任意顶点x ∈V(G),顶点x 的分辨域RN(x)为
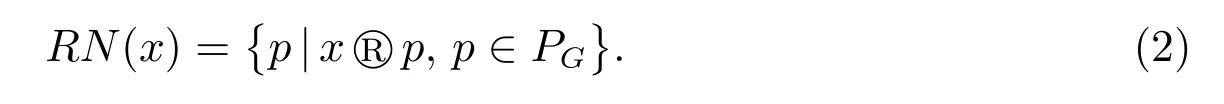
顶点x 的分辨度RD(x)为

将所有顶点及其分辨域按行排列在一起构成的表为图的顶点分辨表RT(G),见表1. 其中i ∈{1,2,··· ,n}, j ∈{1,2,··· ,mi}.

表1 分辨表RT, pij =uv ∈PG, mi =RD(vi)
本文提出了图的分辨域概念,进而建立了图的一种新的存储形式:分辨表.分辨表直接反映了图的分辨特性.与图的顶点邻接关系相比较,实际复杂网络的分辨表是易得的.因而,图的分辨表是研究图的分辨特性的有力工具.
2.3 度量维数问题的0-1 着色分辨模型
给定颜色集{0,1},与顶点集对应的1×n 阶着色分辨向量函数为

设
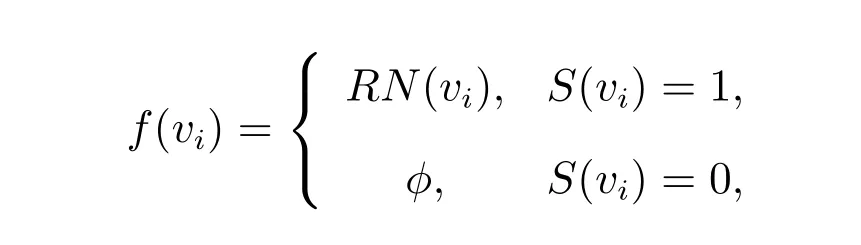
则图度量维数问题的0-1 着色分辨模型可描述为

0-1 着色分辨模型(4)从图本身的分辨特性角度寻找图的一个基,并计算图的度量维数.模型(4)是非线性的,反映了问题的组合特性,拓展了经典的顶点着色分类思想.与顶点集对应的1×n 阶着色分辨向量函数S 也是图G 的一个解向量.即元素值为1 的对应顶点构成了图G 的一个近似分辨集或基,元素值1 的个数为图G 的近似度量维数.
3 模型求解算法研究
算法1 0-1 随机条件着色分辨算法
步骤0 算法初始化.建立图G 的分辨表RT (表1)和顶点对集合PG(式(1)).初始化与顶点集对应的着色分辨向量S =(0)1×n.着色为1 的顶点对应的分辨域构成的无重复元素集合R=φ.
步骤1 选取顶点v ∈V(G),为顶点v 分配颜色1,即S(v) = 1.令R = RN(v),若R=PG,算法终止运行并输出图的度量维数1 及其对应基.否则,转到步骤2.
步骤2 选取顶点v ∈V,使得顶点v ∈V 满足分辨域限制条件
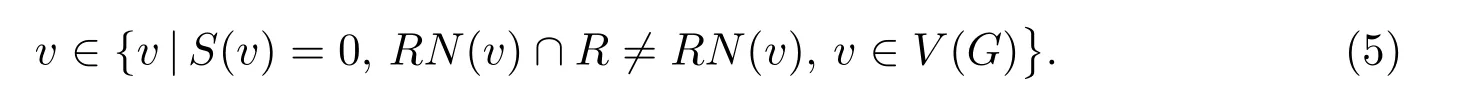
同时,对满足分辨域条件(5)的候选顶点,验证是否满足分辨域限制条件

对于满足分辨域条件(6)的候选顶点,令

对于不满足分辨域条件(6)的候选顶点,令

转到步骤3.
步骤3 判断算法终止条件是否满足.若R ̸= PG,则转到步骤2.否则,转到步骤4.
步骤4 输出结果.即对0-1 着色向量S 施加修补技术并输出图的度量维数和基.
注1 算法1 的步骤4 上施加的修补技术为:对每个顶点v ∈{v|S(v) = 1, v ∈V(G)},验证是否满足
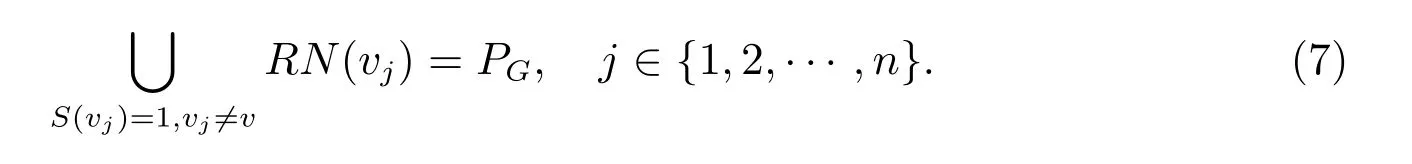
若满足,则令S(v) = 0.对着色向量重复施加修补技术,直到没有顶点满足式(7),即直到分辨集是极小分辨集为止.
算法1 在随机选择顶点时加入了对顶点分辨域的限制条件,并且为属于分辨集的顶点分配颜色值1,不属于分辨集的顶点分配颜色值0.因而算法1 是一种有条件的着色分辨算法,简称0-1 随机条件着色分辨算法.同时,修补技术的采用使得算法所得分辨集至少是一个极小分辨集.这一点优于一般的遗传算法.经过多次迭代后,取最优的着色向量(分配颜色值1 的顶点数最小的着色向量)作为图的着色向量.其对应的分配颜色值1 的顶点构成的顶点子集作为图的一个近似的分辨基或基,分配颜色值1 的顶点数为图的近似度量维数.算法1 可作为其他近似算法的局部搜索策略.
算法2 0-1 蚁群条件着色分辨算法
步骤0 基本参数列表初始化,如表2 所示.

表2 基本参数
步骤1 迭代初始化.建立图G 的分辨表RT (表1)和顶点对集合PG(式(1)).初始化与顶点集对应的着色分辨向量S =(0)1×n.着色为1 的顶点对应的分辨域构成的无重复元素集合R=φ.
步骤2 将蚂蚁k 随机放到遍历网络的顶点上.蚂蚁k 开始为其第一个访问顶点v ∈V(G)分配颜色1.即S(v) = 1.令R = RN(v).若R = PG,算法终止运行并输出图的度量维数1 及其对应基.否则,转到步骤3.
步骤3 首先,根据式(11),(12)计算与当前访问顶点对应的启发因子向量,并且每隔一定迭代步数N,按照(11)-(14)计算并调整期望启发因子向量.其次,按照转移概率计算公式(15)选择下一访问顶点v ∈V(G),其中顶点v ∈V(G)满足顶点分辨域限制条件(5)和(6).转到步骤4.
步骤4 判断蚂蚁k 是否着色完毕.若R ̸=PG,则转到步骤3.否则,记录蚂蚁k 的着色向量,转到步骤5.
步骤5 判断是否满足k ≤m.若满足,则当前蚂蚁数k 增加1,转到步骤2.否则,转到步骤6.
步骤6 在m 只蚂蚁的着色向量中选择最优着色向量.按照一定概率在所选最优着色向量附近运行算法1,即进行局部搜索.所得或所选0-1 着色向量为本次迭代图的最优着色向量.根据公式(9),(10)和迭代最优着色向量更新信息素向量,迭代步数增加1. 若迭代步数小于或等于最大迭代步数,则转到步骤1.否则,转到步骤7.
步骤7 输出图的最优着色向量,并确定图的最优度量维数和基.
算法2 保留了0-1 随机条件着色分辨算法中的分辨域限制条件、修补技术、着色分辨向量(解向量)函数,并加入了蚁群遍历寻优的思想,用概率的方法选择着色顶点.通过设计与问题背景相适应的遍历网络,信息素向量及其更新策略,动态期望启发因子向量及其调整策略,具有动态特性的转移概率,从全局和局部两个角度出发建立了一般图度量维数问题的0-1 蚁群条件着色分辨算法.算法将全局搜索和局部搜索相结合,在保持搜索多样性的同时,保证求解质量和较好的收敛性.为了避免算法过早收敛,算法采用局部搜索的次数不宜太多.蚁群算法的较早研究见文献[25,26].下文进一步给出算法2 的设计细节.
3.1 解向量
假设着色分辨向量函数S(见2.3 节)与图G 的顶点标号集V(G) = {1,2,··· ,n}对应.其初值S = (0)1×n.在算法运行过程中,为属于分辨集的顶点分配颜色值1,不属于分辨集的顶点保持颜色值0 不变.每只蚂蚁对应一个着色分辨向量(函数).称每次迭代所得最优解向量为图G 的一个迭代最优着色分辨向量.算法运行结束后所得解向量即为图的最优着色分辨向量.其中分配颜色值1 的顶点构成图G 的近似最优分辨基或基.颜色值1 的个数为图G 的近似最优度量维数.
3.2 蚂蚁遍历网络
给定图G,在图G 中添加边,使得G 成为一个完全图.称所添加的边为人工边,所得图为人工网络.例如,假定图1 给定一个具有8 个顶点和9 条边的供蚂蚁遍历的图G.通过添加人工边,得到人工网络图2.其中,实线表示原始边,虚线表示人工边.蚂蚁在人工网络上按照一定概率到达任何一个顶点,而不受其他顶点的阻碍. 从而增强了蚂蚁搜索行为的多样性.
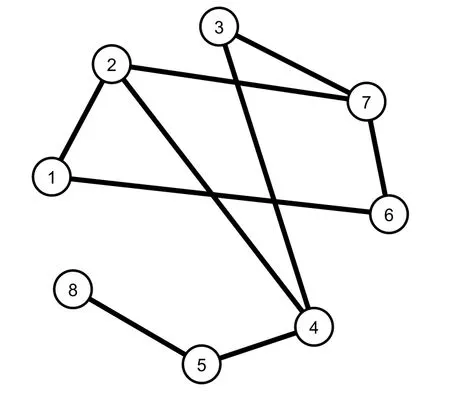
图1 图G

图2 人工网络
3.3 信息素向量及其更新与限制策略
蚁群算法已经广泛应用于组合优化问题的研究中.目前,利用蚁群算法求解的大部分组合优化问题均十分关注最优解以及整个网络的拓扑结构.在传统的蚁群算中,当前蚂蚁遍历网络时,其选择下一顶点的行为会受到与当前访问顶点相关联的网络边上信息素的影响,同时蚂蚁也要释放一定数量的信息素.因而,信息素的存放方式对算法的运行效率具有重要的影响.传统的蚁群算法将蚂蚁释放的信息素保存到网络的边上,进而构成了一个存储规模较大的信息素存储矩阵(其阶数为网络的顶点数),简称信息素矩阵.在蚂蚁遍历网络搜索最优解的过程中,蚂蚁要查阅信息素矩阵,获取与当前访问顶点所关联边上的信息素存储量,并将其作为选择下一网络顶点的重要影响因素.信息素矩阵及其更新的进一步论述见文献[25-30].对于信息素的更新和限制,本文采用最大最小蚁群算法[26,27]中的信息素更新和限制策略.
不同于经典组合优化问题,图的度量维数问题只关注图的分辨集及其所含顶点的个数,而不关注分辨集的拓扑结构. 因而本文尝试将蚂蚁释放的信息素存放到网络顶点上,进而建立了一个存储规模较小且便于查阅的与网络顶点相对应的信息素存储向量
实现整机闭环测试环境的自动构建,整机智能测试系统需要对测试线把座进行控制,而控制需要动力源来提供支持。智能测试系统对测试把座自动控制的特点是:水平直线移动,移动位移较小。因此,动力源的选择可以采用以下两种方案:1是采用气动系统作为控制源,2是采用伺服电机作为控制源。考虑到测试系统对测试把座的控制数量较多,气阀与伺服电机相比,气阀体积小,布局较为容易。所以采用气动系统作为动力源,较为合理。

其中iter-max 是算法的最大迭代步数,τ0为根据问题选择的常数,τj(t)为迭代步t 顶点j 上的信息素量,n 为网络顶点数.
在算法迭代运行过程中,网络顶点上的信息素随着迭代时间(步数)的推移不断的挥发.一般地,参数ρ 表示信息素挥发的强度.ρ 的值越大,网络顶点上的信息素挥发的越快.算法每次迭代运行完成后,只有一只蚂蚁按照其对应的着色向量和式(9)更新其对应分辨集中顶点上的信息素,即与当前迭代最优着色分辨向量对应的蚂蚁更新其分辨集(颜色值为1 的顶点构成分辨集)对应顶点上的信息素.

其中dimbest是当前迭代步的最优度量维数,(9)式体现了当前迭代最优分辨集单位顶点上信息素的增量.对于不在当前迭代最优分辨集的顶点,由于信息素的挥发,其上的信息素存量变为

式(9)表明迭代最优分辨集所含顶点数越少,其对应蚂蚁在此分辨集的每个顶点上释放的信息素越多.为了防止迭代中出现停滞现象,本文将顶点上的信息素限制在一个区间[τmin,τmax]内.顶点上的信息素量τj(j =1,2,··· ,n)满足
若τj≥τmax,则令τj=τmax; 若τj≤τmin,则令τj=τmin.
在实验中,计算τmax和τmin的公式如下
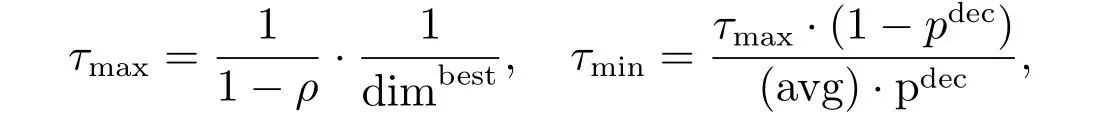
其中
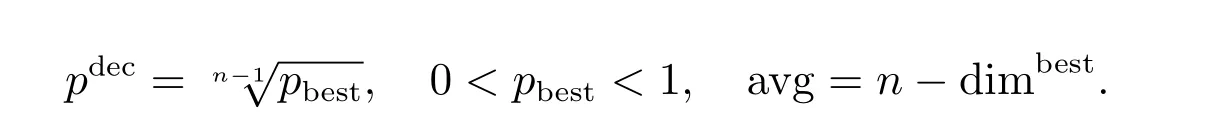
3.4 动态期望启发因子向量及其调整策略
根据传统蚁群算法原理[25,27,28],蚂蚁遍历网络并选择下一访问顶点的行为不仅要受到边上信息素的影响,还要受到网络拓扑结构的影响.例如,在旅行商问题(TSP 问题)中,当前蚂蚁在候选顶点集合中选择下一个访问顶点的行为要受到当前访问顶点与候选顶点之间最短距离的影响.若某个候选顶点与当前访问顶点之间的最短距离较大,则该候选顶点被当前蚂蚁选择的可能性较小.反之,则较大.因而,传统蚁群算法引入了存储规模较大且固定不变的期望启发因子矩阵(其阶数是网络的顶点数,除主对角线元素为0 外,其它元素是网络两点间最短距离的倒数)来引导蚂蚁在候选顶点集中选择下一个可能的访问顶点.关于启发因子矩阵的详细描述间文献[27-29].
本文尝试建立与图的度量维数问题相适应的,存储规模较小且具有一定动态特性的期望启发因子向量,进一步通过具体的启发因子向量调整策略,增强蚂蚁搜索解空间的多样性.假设当前蚂蚁k 访问顶点vi∈{v|S(v) = 0, v ∈V(G)},即令S(vi) = 1,得解向量S′.在迭代步t,与当前访问顶点vi对应的所有可访问顶点构成的候选顶点集合为Jk(vi) = {v|S′(v) = 0, v ∈V(G)}.由于图的度量维数问题不关注最优解及整个网络的拓扑结构,所以本文假设人工蚂蚁在选择下一访问顶点vj∈Jk(vi)时会受到顶点分辨度(式(3))的影响:分辨度较大的顶点被访问的可能性也较大.本文依据蚂蚁候选顶点集动态变化的特点,利用顶点的分辨度构造期望启发因子

由式(11)可得到期望启发因子向量为
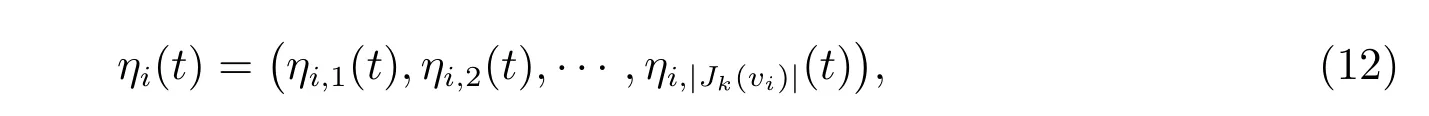
其中,式(11)对顶点分辨度进行归一化处理,有助于提高算法的搜索速度.
当前蚂蚁选择下一访问顶点时,在式(12)的影响下,分辨度较大的候选顶点被选择的可能性也较大.然而,图的分辨集或基不一定仅仅由分辨度较大的顶点构成.因而,算法每隔一定迭代步数N 利用公式(12)将向量ηi(t)中的部分最大分量减去某个常数,即令


3.5 转移概率设计
在蚂蚁释放到顶点上的信息素和与顶点分辨度相关的动态期望启发因子的共同作用下,蚂蚁k 从当前访问顶点i ∈V(G)依据概率pkij(t)(式(15))独立地选择下一可达顶点j ∈Jk(i).

其中,常数α, β 分别反映信息素和动态期望启发因子的相对重要程度,t 为当前迭代步.
与传统蚁群算法中的转移概率计算公式相比较,转移概率计算公式(15)具有几个较为显著的特点:
1) 用存储规模较小的信息素向量和启发因子向量代替了传统转移概率计算公式中的信息素矩阵和启发因子矩阵,在降低存储规模的同时,避免了大量的矩阵遍历搜索,大大提高了转移概率的计算速度;
2) 启发因子的动态变化使得转移概率具有一定的动态特性.而与具有扰动特性的公式(13)有效结合,转移概率计算公式(15)在一定程度保证了在候选顶点集合中分辨度较小且启发因子较低的顶点成为下一个访问顶点的可能性,提高了算法搜索的多样性;
3) 在每次迭代的初始阶段,转移概率的计算速度较慢,这是由初始阶段蚂蚁候选顶点集的规模较大导致的.随着算法的继续运行,转移概率的计算速度将逐步加快.
3.6 局部搜索设计
在算法运行前期,对蚂蚁的候选顶点施加了顶点分辨域限制条件(式(5),式(6)),而没有对迭代最优解施加修补技术(式(7)).从而在提高解的质量的同时,保持搜索解空间的多样性.在算法运行后期,为了保证算法的收敛性,每隔一定迭代步数,当前迭代最优着色向量对应蚂蚁进行局部搜索.具体搜索算法或策略采用算法1.考虑到算法运行的时间复杂性,蚂蚁在局部迭代搜索过程中,只要求每次迭代的起始顶点取自当前迭代最优着色向量对应的分辨集.保证迭代最优解对应蚂蚁在当前迭代最优解的附近进行随机搜索,并搜索有限次.局部搜索既提高了解的质量,又保证了算法具有较好的收敛性.
4 数值分析
图的度量维数问题的研究一直以来都聚焦于特殊图类度量维数的计算.目前,仅有一类线性规划模型和遗传算法分别考虑了该问题的数值计算方面.文献[2]最早提出了计算时间和空间复杂度较高的线性规划理论模型.对于顶点规模较大的图而言,利用该模型求解其度量维数是困难的.文献[24]提出了计算图度量维数的遗传算法,并在图着色测试集上得到了一些图的度量维数近似计算结果.由于图的度量维数问题没有相应的算法测试图集,因而包括随机图在内的大部分图类的度量维数计算问题仍是一个开放课题,其精确度量维数有待进一步研究.算法1 作为一种简单随机搜索算法,其全局搜索能力有限.本文按照局部搜索设计(见3.6 节)将算法1 作为局部搜索策略与具有较强全局搜索能力的蚁群搜索策略相结合,建立了能够进一步提高求解质量的改进型蚁群算法2.
4.1 参数初始化
根据分辨域的定义(见第2.2 节)生成图的分辨表(表1),用来存储顶点的分辨特性.根据式(1)计算图G 的所有不同顶点对构成的集合PG.根据最大最小蚂蚁系统[26-28],信息素重要程度参数α 取值为[1,4],启发因子重要程度参数β 取值为[3,5],信息素挥发系数ρ 取值为0 ~1,信息素总量常数Q 的取值为依赖于与实际问题相关的参数α, β, ρ 的取值,蚂蚁个数的取值一般为10 ~50.根据问题的需要,动态期望启发因子向量的初值设置为空,信息素向量的分量设置为常数1.由于信息素总量Q 的取值一般会受到问题规模的影响,因而本文假定信息素总量Q 随顶点数的增加而增加,即

其中n 是网络的顶点数,常数W =100.信息素总量Q 随网络顶点数呈非线性变化.
最大迭代步数iter-max 设置为100 ~500.当蚂蚁对应的候选顶点集规模较大时,转移概率计算的时间复杂度也较大.因而,本文从当前候选顶点集中选取一部分顶点作为蚂蚁的实际候选顶点集.实际候选顶点集的选取比例系数记作Sample(0 < Sample ≤1),其中Sample = 1 表示当前候选顶点集就是实际候选顶点集,其它基本参数的详细分析见文献[26,27].
4.2 Jahangir 图上的计算结果
本节主要对模型求解算法2 进行数值分析,在Jahangir 图[31]上验证算法2 中分辨域限制条件和修补技术以及局部搜索设计的有效性.
轮图[32]W2k= K1+ C2k,其中,边e = uv ∈E(W2k)(u ∈K1, v ∈C2k)是轮图W2k的一根辐条.在轮图W2k上交替删除k 根辐条得到Jahangir 图,记作J2k.例如,图3 为有5 根辐条的Jahangir 图J10.
图3 J10
算法2 在Jahangir 图上运行的基本实验参数为:图的分辨表(表1),启发因子向量η(式(12)),蚂蚁个数m = 10,信息相对重要程度参数α = 1,期望启发因子相对重要程度参数β = 5,信息素挥发系数ρ = 0.95,初始迭代步iter = 1,最大迭代步数iter-max = 100,信息素向量Tau(式(8)),顶点上的初始信息素均为1.算法2 在每个Jahangir 图上的运行次数T = 20.算法每隔N1= 20 代进行一次局部搜索,局部搜索的最大迭代次数LN = 20.期望启发因子不进行调整.候选顶点集选取比例系数Sample=0.5.
在前期试验中,计算了大量Jahangir 图的度量维数.文献[31]证明了当k ≥4 时,图J2k的 度 量 维 数 是」.算 法2 在k 的 取 值 为4,5,··· ,50 的Jahangir 图 上 的 运 行 结果,如表3 所示.其中N, T, Odim, dim, GRN1, GRN2, LRN1, LRN2, LR, LS, t 分别表示Jahangir 图的圈上的顶点数(单位:个),算法运行次数(单位:次),Jahangir 图的精确度量维数,Jahangir 图的近似度量维数,分辨域限制条件(5)在全局搜索中的平均作用次数(单位:次),分辨域限制条件(6)在全局搜索中的平均作用次数(单位:次),分辨域限制条件(5)在局部搜索中的平均作用次数(单位:次),分辨域限制条件(6)在局部搜索中的平均作用次数(单位:次),局部搜索中修补技术的作用次数(单位:次),局部搜索成功次数(即通过局部搜索寻找到更好解的次数)(单位:次),算法在每个图上运行一次平均每代运算时间(单位:秒)等.特别地,Jahangir 图J10的基和度量维数见图4,其中方块顶点表示图的一个基.

表3 Jahangir 图的度量维数计算结果

续表3 Jahangir 图的度量维数计算结果
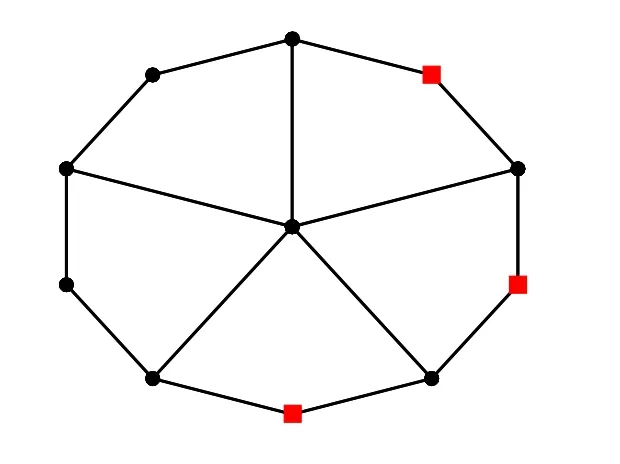
图4 J10 的基
4.3 随机图上的计算结果
假设Gn,p表示顶点数为n,边存在概率为p 的简单连通随机图类.本节采用与4.2 节相同的参数设置,在随机图上验证算法2 中分辨域限制条件和修补技术以及局部搜索设计的有效性:首先,利用算法2 计算了随机图G ∈Gn,p的度量维数,其中,顶点数n ∈{2,3,··· ,100},边存在概率p = 0.1.算法在随机图上的运行结果见表4.特别地,随机图G(n = 10, p = 0.1)的基和度量维数见图5.其中方块顶点表示图的一个基.其次,按照度量维数问题的线性规划模型[2],利用Matlab 内置的整数规划求解算法计算了随机图的度量维数.

图5 随机图G(n=10, p=0.1)的基
在表4 中,n 表示随机图的顶点;Ldim, Lt(单位:秒)分别表示随机图度量维数的整数规划求解结果及其平均用时;dim, t(单位:秒)分别表示基于算法2 的随机图的度量维数计算结果及其每代平均用时;参数GRN1, GRN2, LRN1, LRN2, LR, LS 的含义与4.2 节相同.

表4 随机图的度量维数计算结果
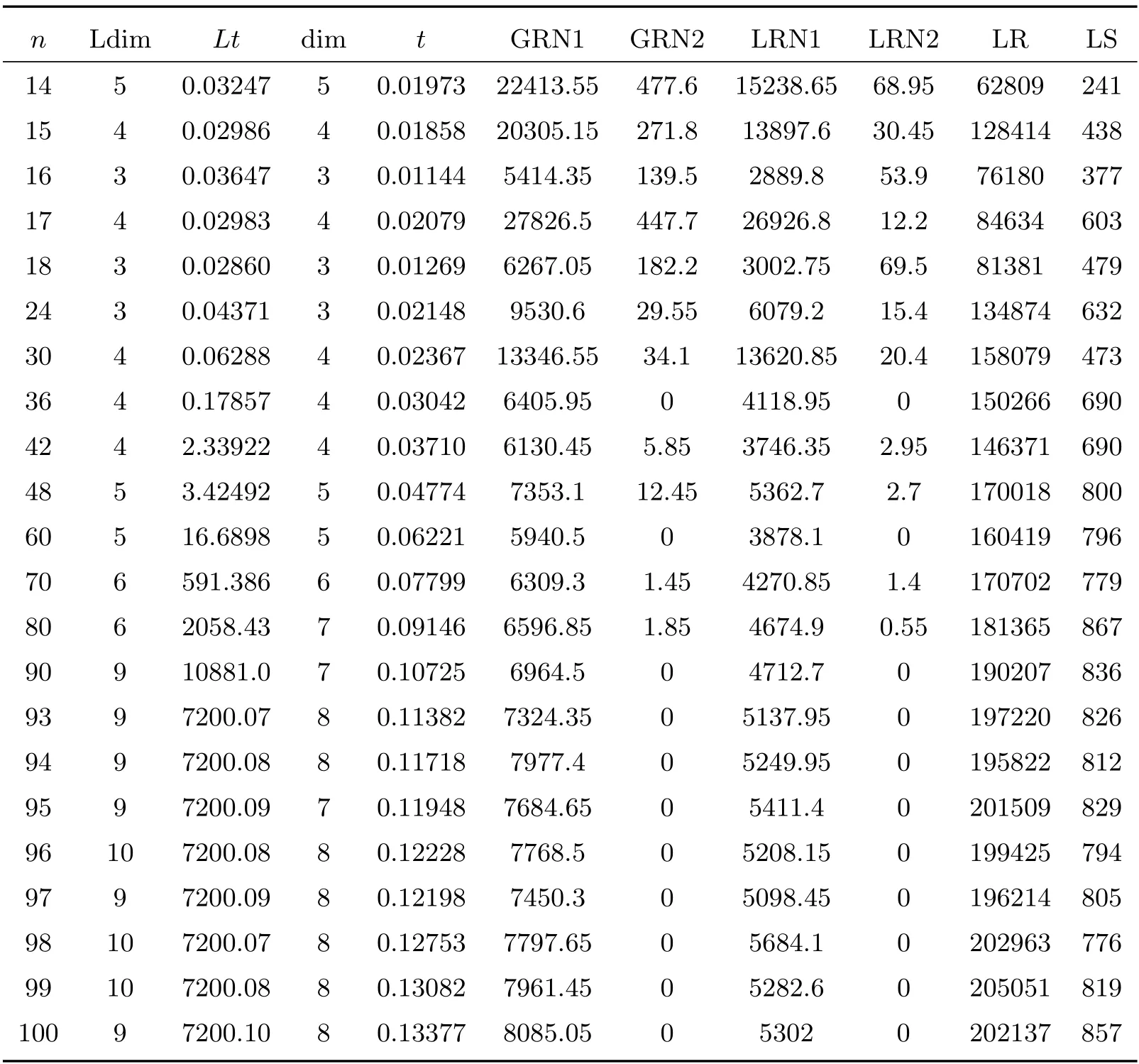
续表4 随机图的度量维数计算结果
4.4 Jahangir 图和随机图计算结果比较分析
表3 和表4 的GRN2 列、LRN2 列表明,分辨域限制条件(6)对算法在Jahangir 图上的运行结果影响较小,而在随机图上的运行结果有较大影响.结合前期试验分析,对于顶点数较大或边存在概率较大,顶点分辨度分布比较规则的图,算法在运行时可取消分辨域限制条件(6)的限制.
表3 和表4 的GRN1 列、LRN1 列表明,分辨域限制条件(5)在全局搜索和局部搜索中都起到了提高近似解质量的重要作用.LR 列表明了修补技术在局部搜索中的有效性.算法每隔一定步数启用一次局部搜索.LS 列表示当算法在某个图上运行一定次数时,局部搜索对近似最优度量维数的改进次数,即局部搜索成功的次数.LS 列表明局部搜索策略对提高算法的求解质量具有一定的有效性.
表3 和表4 的dim 列是算法的度量维数近似计算结果.表3 中的度量维数近似计算结果与精确度量维数较为接近,算法运行结果较好.Jahangir 图的顶点分辨度分布较为规则,顶点分辨度缺乏多样性,因而算法求解较为困难.表4 的Ldim 列、dim 列、Lt 列、t列从运行结果和运行时间方面表明算法2 的运行表现显著优于整数规划求解算法.一部分原因是随机图的顶点分辨度具有较大的多样性,有利于算法跳出局部最优.
4.5 ORLIB 图例的计算结果对比分析
ORLIB 开放图数据库存储了大量与实际图论问题相关的图例,但尚无与图的度量维数问题相关的测试图例.文献[24]利用遗传算法计算了图着色图例的近似度量维数,但这些图的精确度量维数仍然未知.本节利用算法2 计算了部分相同图类的近似度量维数,计算结果摘录于表5.

表5 ORLIB 图例的度量维数计算结果
具体地,算法2 在gcol 图例上运行的基本实验参数为:图的分辨表(表1),启发因子向量η(式(12)),蚂蚁个数m = 10,信息相对重要程度参数α = 2,期望启发因子相对重要程度参数β = 5,信息素挥发系数ρ = 0.95,初始迭代步iter = 1,最大迭代步数iter-max = 100,信息素向量Tau(式(8)),顶点上的初始信息素均为1.算法2 在每个gcol 图例上的运行次数T = 20.算法每隔3 代进行一次局部搜索,局部搜索最大迭代次数为10.期望启发因子每隔20 代进行调整.当顶点数比较大时,候选顶点集选取比例系数Sample=0.5.
在表5 中,第一列(Graph)表示图例,第二列(Node)表示每个图例的顶点数(单位:个),第三列(Edge)表示每个图例的边数(单位:条),第四列(T)表示算法2 在每个图例上的运行次数(单位:次),第五列(dim1)表示利用算法2 所得图例的度量维数,第七列(LR),第八列(LS)分别表示算法2 的修补技术和局部搜索成功的次数(单位:次),第九列(t)表示算法2 在每个图上运行一次平均每代用时(单位:秒),最后一列(dim2)是文献[24]利用遗传算法所得图的度量维数.
第二列、第三列、第九列表明随着图的顶点数和边数规模的增大,算法运行的时间复杂度显著增加.因而,算法根据第六列(Sample)的设置从候选顶点集合中选择一定比例的顶点作为蚂蚁的实际候选顶点集合.考虑到算法求解质量和转移概率计算的时间复杂性,当图的顶点数较大时,比例系数Sample 取值为0.5.这在一定程度上降低了转移概率计算的时间复杂度,又不会使得求解质量最差.在实际应用中,可根据实际问题的求解质量容忍范围,比例系数Sample 可取不同的值.
第五列(dim1)和第十列(dim2)表明算法2 通过利用修补技术(LR)和局部搜索(LS)得到了较好的计算结果.修补技术和局部搜索确保了算法2 在最坏的情况下所得图的分辨集是图的一个极小分辨集.这一点优于文献[24]中的遗传算法.算法2 所得图例的最优分辨集(也是极小分辨集)见表6,其中顶点的标号与其在数据库(ORLIB)中顶点的标号一致.例如,200 表示图的标号为200 的顶点,其对应于邻接矩阵的第200 行,第200 列.Graph,Resolving set 分别表示图例和其对应的分辨集.
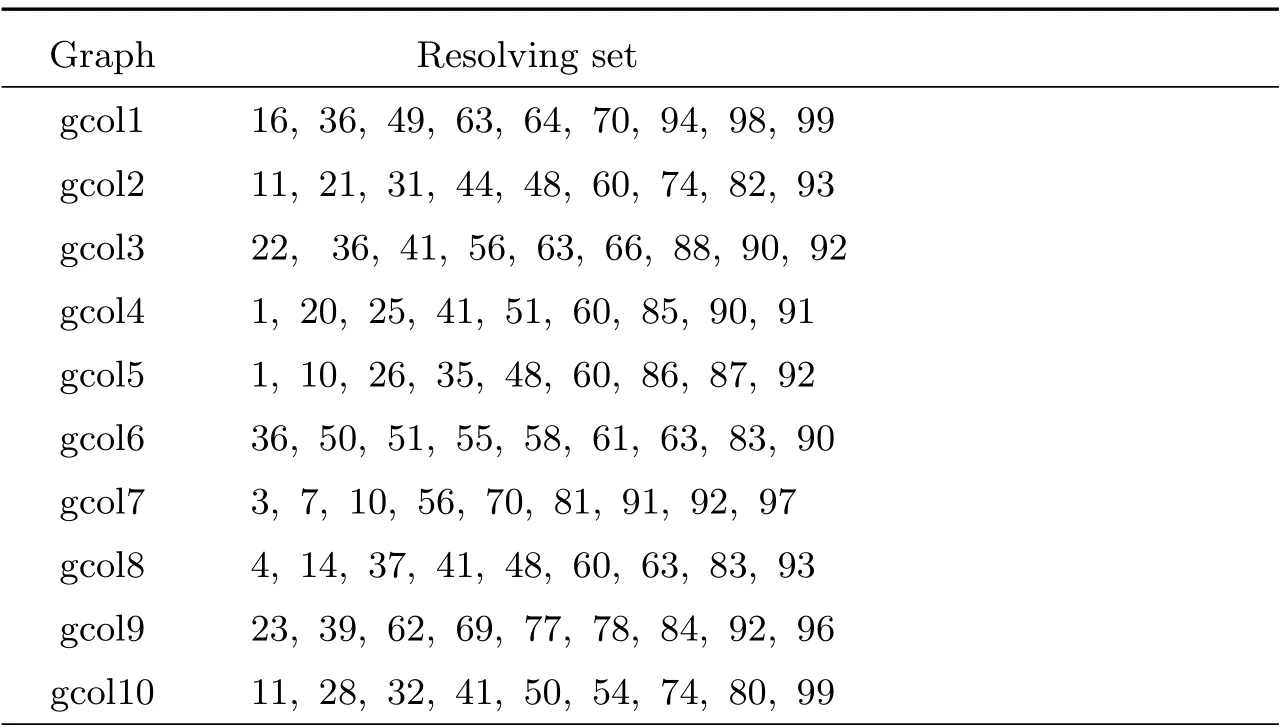
表6 gcol 图例的最优分辨集

续表6 gcol 图例的最优分辨集
4.6 算法参数分析
根据实际问题的特点,本文引入了图的分辨表作为存储图的分辨特性的数据结构.该参数与图的分辨模型结合充分体现了图的度量维数问题的组合特性.在算法设计方面,引入了人工遍历网络,信息素向量和动态期望启发因子,在较大程度上降低了蚁群搜索的空间复杂度和时间复杂度.在Jahangir 图,随机图和gcol 图例上的数值实验表明算法引入的分辨域限制条件一定程度上能够有效提高算法求解质量.对于算法设计中的基本参数,如信息素重要程度参数α,期望启发因子重要程度参数β,信息素挥发系数ρ,蚂蚁个数m,在文献[25-27]中已有详细的分析,这里不再赘述.算法引入的其它参数,如局部搜索间隔代数和动态期望启发因子调整的间隔代数要根据实际图例进行选定.由于Jahangir 图度量维数是已知的,因此下文基于Jahangir 图的数值实验对新引入的候选顶点集选取比例系数(Sample)进行分析,进一步研究其对算法求解质量的影响.
本节随机生成h 个Jahangir 图:J20, J30, J34, J48, J54, J60, J62, J68, J80, J82, J86,J100,分析候选顶点集选取比例系数对求解质量的影响.令Oi表示Jahangir 图的真实度量维数,Di表示算法输出的Jahangir 图度量维数,建立平均误差指标

根据比例系数的不同,算法在生成图上的平均误差指标数据见表7.从图6 中可以直观的看出平均误差随候选顶点选取比例系数的变化趋势.即在其它参数不变的情况下候选顶点选取比例系数Sample 取值0.7 ~0.8 较好.对于不同的图类,该参数的取值范围需要进一步的确定.

表7 比例系数与平均误差
图的顶点分辨度的分布情况对算法运行效果的影响具有一定的不确定性.与复杂网络的度分布研究类似[33],为了进一步认识图或实际复杂网络的内在分辨特性,刻画一般图或实际复杂网络的顶点分辨度的概率分布可作为图的度量维数问题的进一步研究课题:给定一般简单连通图或实际复杂网络,刻画其顶点分辨度的概率分布.

图6 平均误差随候选顶点选取比例系数的变化
