卷积神经网络中优化算法性能比较研究
2021-01-06牛磊,赵佳
牛 磊,赵 佳
(阜阳师范大学 计算机与信息工程学院,安徽 阜阳 236037)
人工智能自1956年诞生以来,经历了“推理期”[1]、“知识期”[2]、“学习期”[3]。进入21世纪,尤其是Hinton[4]在2012年将深度学习应用于ImageNet数据集并大获成功以来,借助于GPU算力的快速提升以及大数据技术的发展,深度学习在语音[5]、图像[6]、文本[7]、视频[8]等领域均取得了长足的进步。当前人工智能的侧重点也已经由模型转为大规模数据的收集,人工智能已经进入“数据期”[9]。而深度学习已经成为处理各类信息的首选工具,但深度学习仍存在如可解释性[10]等若干未解决的问题。魏秀参[11]总结了深度学习实现的若干细节,包括权值初始化、卷积因子及池化尺寸等参数的确定以及激活函数选择等。初始化权重通常使用正态分布,而偏移通常设为0。卷积因子及池化参数随图像尺寸大小而定。Simonyan[12]指出使用更小的卷积核能够得到更精确的结果,这点也在VGG[12]、ResNet[13]、GoogleNet[14]等网络结构中得到体现。Nair[15]通过实验证实使用线性整流函数(rectified linear unit,ReLU)作为激活函数,能够使得训练时间大幅缩短,当前的卷积神经网络的激活函数也大多选择Relu函数。但优化算法的选择也能够极大的影响函数的收敛速度,本文即从优化算法选择的角度,考虑针对不同复杂程度的图片运行时间的变化,为处理各类图片时优化算法的选择提供参考。
1 常用优化算法
本节将列举5个常用的优化算法,为统一符号,设损失函数为J(θ),其中θ为待求解的参数。
1.1 SGD
梯度下降(gradient descent)是优化理论中常用的算法,其迭代策略为:
θk+1=θk-α·∇J(θk)。
其中:α为学习率,在Mnist数据集实验中设为0.000 1,而在Cifar10数据集实验中设为0.001;k为迭代步数;∇为梯度算子。学习率设置过大会使得后期迭代不收敛,设置过小会使得前期收敛速度较慢。该算法一次循环仅调整一次参数,在样本量比较大时,需要计算所有样本的梯度之后才能调整参数,影响了迭代速度。随机梯度下降[16](stochastic gradient descent,SGD)使用批处理策略,设置包尺寸(Batchsize),计算每包所有样本的梯度后即可调整参数,大大提高了迭代速度。需要说明的是,Batchsize越大,算法迭代速度越慢,但损失函数下降越平稳,而Batchsize越小,算法迭代速度越快,但损失函数下降越不平稳。
1.2 Momentum
随着损失函数值的下降,其梯度也越来越小,SGD算法在后期的迭代速率也将变慢,动量[17](Momentum)方法可以积累之前迭代的下降速率,进而提高迭代速度,其迭代策略为:
vk=μvk-1+α·∇J(θk),θk+1=θk-vk。
其中:μ为动量系数,在本文实验中设置为0.9;v表示动量。
1.3 AdaGrad
如前所述,学习率的设置对算法收敛速度有较大影响,自适应次梯度[18](adaptive subgradient,AdaGrad)方法能够和Momentum一样累计历史梯度,且能够修正全局学习率,其迭代策略为:
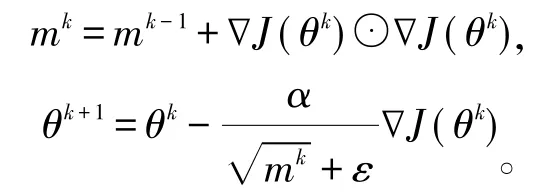
其中:mk为第k步的动量;ε为修正常数,防止mk太小出现数值溢出;⊙表示对应元素相乘。该算法引入了梯度的内积,能够大幅提高系数梯度的更新速度。
1.4 RMSProp
RMSProp[19]与AdaGrad类似,其迭代策略为:

其中:ρ为超参,在实验中常取0.9,0.95以及0.99等,在本文实验中取0.99。该方法使用超参平滑了动量与梯度平方,能够减少迭代中梯度摆幅过大的问题。
1.5 ADAM
自适应动量估计算法(adaptive moment estimation,ADAM)[19]结合了momentum和RMSProp,首先计算动量:
mk=β1mk-1+(1-β1)∇J(θk)
其中:β1为超参,在本文实验中取0.9。其次计算指数加权平均
sk=β2sk-1+(1-β2)∇J(θk)⊙∇J(θk)
其中:β2为超参,在本文实验中取0.99。在迭代初期mk、sk通常设置为趋于0,通过修正可解决此问题,修正公式为:

最终,ADAM算法的迭代策略为:
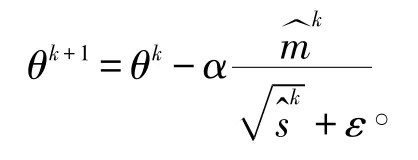
2 Mnist数据集实验比较分析
为可视化各优化算法运行时间,本节使用卷积神经网络处理Mnist数据集,分析在该类简单图片下各优化算法的性能。
2.1 Mnist数据集简介
Mnist[20]数据集为深度学习中最常用的数据集,该数据集为自动识别邮编而生成。数据集包含60 000张训练图片(共10类,每类约6 000张图片),10 000张测试图片(共10类,每类约1 000张图片)。图片示例如图1所示,需要通过图片识别该图片中的数字,每张图片为28*28的8位图片组成,即每张图片是28*28的矩阵,矩阵中每个元素的值在0~255之间。

图1 Mnist数据集图例,8行8列共64张图片
2.2 网络结构及参数
使用卷积神经网络处理Mnist数据,分别使用了两层卷积和两层降采样,以及两个全连接层,卷积核、池化尺寸以及网络结构如图2所示,激活函数使用ReLU函数,损失函数使用交叉熵损失,使用该网络结构在测试集上的识别率达到99%。

图2 处理Mnist数据集使用的卷积神经网络结构图
2.3 实验结果及分析
一般来说,Batchsize越大,每一轮次参数调整的次数越少,但损失函数越平稳;Batchsize越大,每一轮次参数调整的次数越多,但损失函数越不平稳。考虑到此影响,为更好的可视化各损失函数的性能,我们分别设置了Batchsize=64和Batchsize=256两组实验。
图3(a)表示Batchsize=64时各优化算法的性能比较,由图中可看出sgd收敛速度较慢;RMSprop收敛速度较快,但出现不平稳的现象;adam、Momentum以及adagrad效果类似。

图3 各优化算法运行效率的比较
图3(b)表示Batchsize=256时各优化算法的性能比较,可看出RMSprop的不平稳现象消失,这与Batchsize设置较大有关。由图3可看出,设置较小的Batchsize,能够使得算法更快收敛。事实上,鉴于Mnist数据集复杂度不高,除SGD收敛较慢外,其他算法收敛速度相差不大。
3 Cifar10数据集实验比较分析
为可视化各优化算法运行时间,本节使用卷积神经网络处理Cifar10数据集,分析在该类较复杂图片下各优化算法的性能。

图4 Cifar10数据集图例,8行8列共64张图片
3.1 Cifar10数据集介绍
Cifar10[21]数据集为深度学习中常用的彩色图片数据集,数据集共50 000张训练图片,10 000张测试图片,合计60 000张图片,共分为10类(分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车等),每类6 000张。每张图片为32*32的彩色图片,即每张图片的矩阵尺寸为3*32*32,图例如图4所示。
3.2 网络结构及参数
我们使用卷积神经网络处理Cifar10数据,分别使用了两层卷积和两层降采样,以及三个全连接层,卷积核、池化尺寸以及网络结构如图5所示,激活函数使用ReLU函数,损失函数使用交叉熵损失。鉴于该图像的复杂性,为获得较快的收敛速度,我们使用了较简单的网络结构以及较小的Batchsize,因此使用该网络结构在测试集上的识别率仅达到60%。

图5 处理Cifar10数据集使用的卷积神经网络结构图
3.3 实验结果及分析
图6表示各优化算法的性能比较,由图可以看出,SGD收敛速度虽慢,但收敛比较平稳且最终损失函数值较小;AdaGrad和ADAM收敛效果类似,两者相比AdaGrad收敛较快,但ADAM损失函数值较小;Momentum收敛速度较快但损失函数值不够平稳;RMSprop能够兼顾收敛速度和损失函数值。

图6 各优化算法运行效率的比较
4 小结
深度学习成为人工智能的热点,卷积神经网络则是处理图片的常用工具。本文基于卷积神经网络通过实验展示了各优化算法性能的差异。针对简单图像,我们认为可使用ADAM或Momentum获得较快的收敛速度以及较好的收敛效果。而针对较复杂图像,前期调整网络机构等参数时,可以使用ADAM、Momentum或RMSprop等算法,利用收敛速度快的优势测试网络的性能,而在确定网络结构以及卷积因子等超参后,可选择ADAM或SGD获得稳定的收敛效果。
