基因组选择在林木遗传育种研究中的进展与展望*
2021-01-05黄敏仁
朱 嵊 黄敏仁
(1. 南京林业大学 江苏省杨树种质创新与品种改良重点实验室 南京 210037; 2. 南京林业大学生物与环境学院 南京 210037; 3. 江苏省农业种质资源保护与利用平台杨树种质资源圃 南京210014)
基因组选择(genomic selection or genome-wide selection, GS)研究在家畜和农作物遗传改良中已取得了重要进展,其中应用于奶牛的遗传改良成效显著。美国农业部从2009年开始对奶牛开展GS研究,配种公牛和配种母牛的育种周期都减少到2.5年,大大加速了育种进程(Garcia-Ruizetal., 2016)。中国农业大学联合全国畜牧总站等单位完成的中国荷斯坦牛GS分子育种技术体系的建立与应用的研究成果,使我国荷斯坦奶牛(Bosprimigeniusf.taurus‘Holstein cattle’)年产奶量从4 500 kg提高到5 500 kg,显示GS在我国奶牛遗传改良中取得了重大进展(http:∥www.most.gov.cn/kjbz/201703/t2017-132048.htm)。相较于家畜GS,农作物研究起步较晚,但近年来发展迅速,在水稻(Oryzasativa) (Onogietal., 2016; Xuetal., 2018)、玉米(Zeamays) (Fritsche-Netoetal., 2018; Milletetal., 2019)、小麦(Triticumaestivum) (Huangetal., 2016; Bassietal., 2016)、大麦(Hordeumvulgare) (Schmidtetal., 2016; Thorwarthetal., 2017)、苹果(Malus×domestica) (Kumaretal., 2012; Murantyetal., 2015)和梨(Pyruspyrifolia) (Iwataetal., 2013; Minamikawaetal., 2018)等农作物和果树的遗传改良研究中获得一定进展。
林木生长周期长,早期选择是缩短林木育种周期、加快林木育种进程的有效策略和方式(Diaoetal., 2016),长期以来一直是林木遗传改良研究中持续关注的热点。最早基于性状表型值早晚期相关(phenotypic correlation between juvenile and mature period)的早期选择研究,其选择精度往往受限于试验样本量不足。基于分子标记辅助选择(marker assisted selection, MAS)的早期选择研究,由于筛选出的分子标记数量有限,早期选择效率不高。GS利用全基因范围内的所有分子标记估计目标个体育种值,并以此为依据筛选优良基因型(superior genotype)。相比于前2种早期选择技术,基因组选择具有更高的育种效率和更准确的选择精度。随着二代/三代测序技术与高通量SNP基因分型技术的快速发展,GS技术应用于林木重要性状早期选择已成为可能。
相比于家畜与农作物,林木树种的GS研究进展相对缓慢,主要是由于多年生林木树种的遗传学研究基础薄弱、研究技术平台不完善、基础型数据匮乏(例如,基因组数据、转录组数据、表观组数据和表型组数据)和独特生物学特性(世代间隔长、体型巨大和幼龄期长)。为了加快GS技术在林木树种遗传育种中的应用进程,本文对GS原理与方法进行全面介绍,并通过林木基因组选择案例的阐述和分析,对GS技术在林木遗传改良中应用的影响因素及发展前景进行讨论。
1 基因组选择原理与方法
Meuwissen等(2001)首次提出了基因组选择(GS)的概念和原理。GS是一种新型遗传评估手段,对缩短育种世代间隔、加快遗传进展和提高选择效率等均具有积极作用(Meuwissenetal., 2001)。基因组选择技术已成为动植物育种领域中最具潜力的技术热点,期刊《GENETICS》和《G3:Genes|Genomics|Genetics》将GS相关研究论文归档(https:∥www.genetics.org/collection/genomic-selection)。
GS是利用覆盖全基因组的高密度分子标记估计个体的基因组育种值(genomic estimated breeding value,GEBV),并以基因组育种值为依据选择优良基因型/品种。GS一般需要构建参考群体(reference population/training population)和候选群体(candidate population/testing population)2个群体;利用参考群体中已知的表型(phenotype)和基因型(genotype)记录估计出GS线性模型中每个分子标记SNPs(single nucleotide polymorphisms)的效应值;然后,通过候选群体中个体的已知基因型数据和SNPs效应估计值估算GEBV;最后,根据GEBV排序从候选群体中选择出保留个体。
1.1 线性模型
GS线性模型的一般形式:
Y=Xb+Mg+e。
(1)
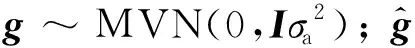
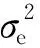
个体的基因组估计育种值(GEBV):
(2)

1.2 GS统计学估计模型

(3)
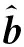
1.2.2 GBLUP模型 GBLUP(genomic BLUP)相比于传统的BLUP模型的主要改进:个体亲缘关系矩阵的改变,即使用基于全基因组标记构建的G矩阵(genomic relationship matrix)替代基于个体系谱关系构建的A矩阵(numerator relationship matrix)。G矩阵(VanRaden, 2008)为:
(4)
式中:M为m×n的基因型矩阵,n为个体总数,m为标记总数,pj为第j个标记位点的最小等位基因频率(minor allele frequency, MAF)。
1.2.3 Bayesian模型 维度灾难(The curse of dimensionality)是线性估计方法直接应用于标记数(m)>>样本数(n)的GS研究时常常面临的挑战之一(Altmanetal., 2018)。为此,遗传方差同质性是RR-BLUP和GBLUP这2种线性估计模型的核心假设,但是该假设与现实情况存在一定出入。非线性估计方法Bayesian模型主要基于马尔科夫蒙特卡洛链(Markov chain Monte Carlo, MCMC)和最大似然(expectation maximization, EM)方法估计基因组育种值,可以在一定程度上弥补线性估计方法的缺陷。Bayesian模型具有BayesA(Meuwissenetal., 2001)、BayesB(Meuwissenetal., 2001)、fBayesB(Meuwissenetal., 2009)、BayesCπ(Habieretal., 2011)、BayesDπ(Habieretal., 2011)、Bayesian LASSO(Yietal., 2008)、emBayesB(Shepherdetal., 2010)等变型,而这些变型之间的主要区别是先验分布假设(SNP效应与方差)和估计方法的不同(王重龙等, 2014)。关于基因组选择中的Bayesian模型,详细内容可参考文献(Habieretal., 2011; Gianolaetal., 2009; Karkkainenetal., 2012; 王重龙等, 2014; 尹立林等, 2019)。
1.3 GS分析工具
伴随着GS统计学估计模型的提出,很多应用这些GS模型的分析工具也被同步开发出来,例如rrBLUP(Endelman, 2011)、synbreed(Wimmeretal., 2012)、BGLR(Perezetal., 2014)、GVCBLUP(Wangetal., 2014)、GAPIT(Lipkaetal., 2012)、sommer(Covarrubias-Pazaran, 2016)和BLUPGA(Kaineretal., 2018)等,具体见表1。目前GS分析工具的主要特点:1)缺乏针对林木特点(多年生、异交和全同胞家系成员庞大)的分析工具;2)主要基于GBLUP和Bayesian 2类统计学估计模型;3)C++、Fortran、Julia和R是开发GS分析软件所使用的计算机语言,而R语言是最常用的GS软件开发语言。由于R语言运行速度较慢,因此基于R语言的GS分析工具分析速度比较慢,该缺点在分析海量分子标记(例如100k级以上)时进一步地放大。因此,具备快速处理海量分子标记数据的能力必将是GS分析软件开发的重要方向之一。
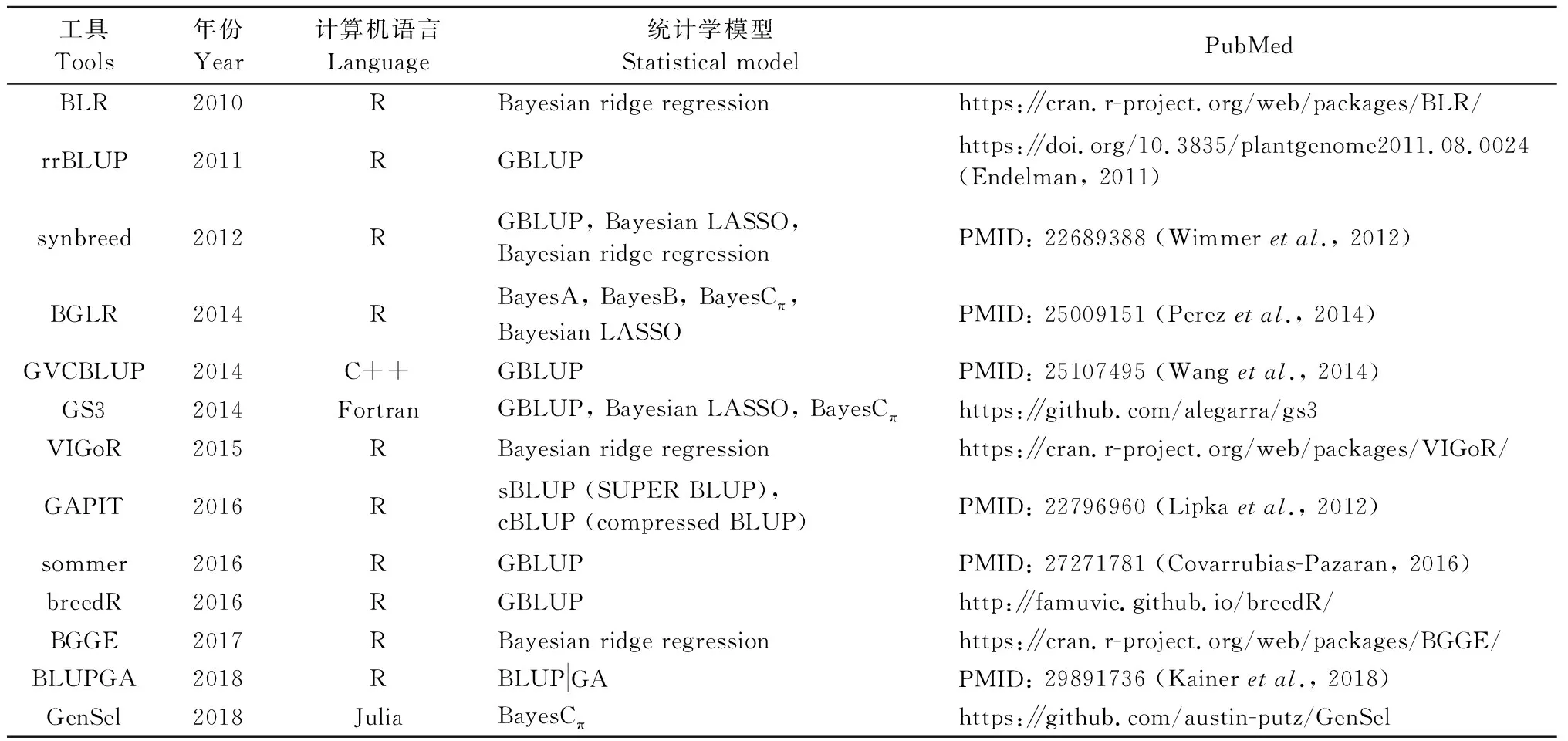
表1 GS分析软件①Tab.1 List of genomic selection tools
2 林木基因组选择研究进展
2.1 GS技术在林木育种中应用的优势
相比家畜和农作物,林木GS研究起步不晚,但进展缓慢。Wong和Bernardo(2008)利用油棕(Elaeisguineensis)模拟数据系统地评估表型选择、分子标记辅助选择(MAS)和基因组选择(GS)3种选择方式后发现:GS的效果要明显好于表型选择和MAS,GS技术在世代间隔长和样本量小的育种群体中仍可获得一定的遗传增益。2012—2019年间,GS研究陆续在油棕属(Elaeis)、桉属(Eucalyptus)、橡胶树属(Hevea)、云杉属(Picea)、松属(Pinus)、杨属(Populus)等树种开展,取得重要进展(表2)。以上研究结果都表明:GS技术可以应用于林木遗传改良,有助于缩短林木育种周期、提高林木育种选择效率和加快林木遗传改良进程。GS技术在林木育种中应用的优势主要表现在:1)预测精度高,比表型选择和分子标记辅助选择2种策略具有更高的准确性;2)选择效率高,可以有效地缩短林木超长的育种周期(十几年甚至几十年)、增加单位时间内的遗传增益以及增强选择强度,最终实现加快林木育种进程的目标;3)可解释的遗传变异比例更高,这是由于GS使用全基因组范围内的高密度SNPs标记,遗传变异位点信息量巨大;4)子代测定成本相对较低(Grattapagliaetal., 2011; Isik, 2014; Iwataetal., 2016; Nyoumaetal., 2019)。
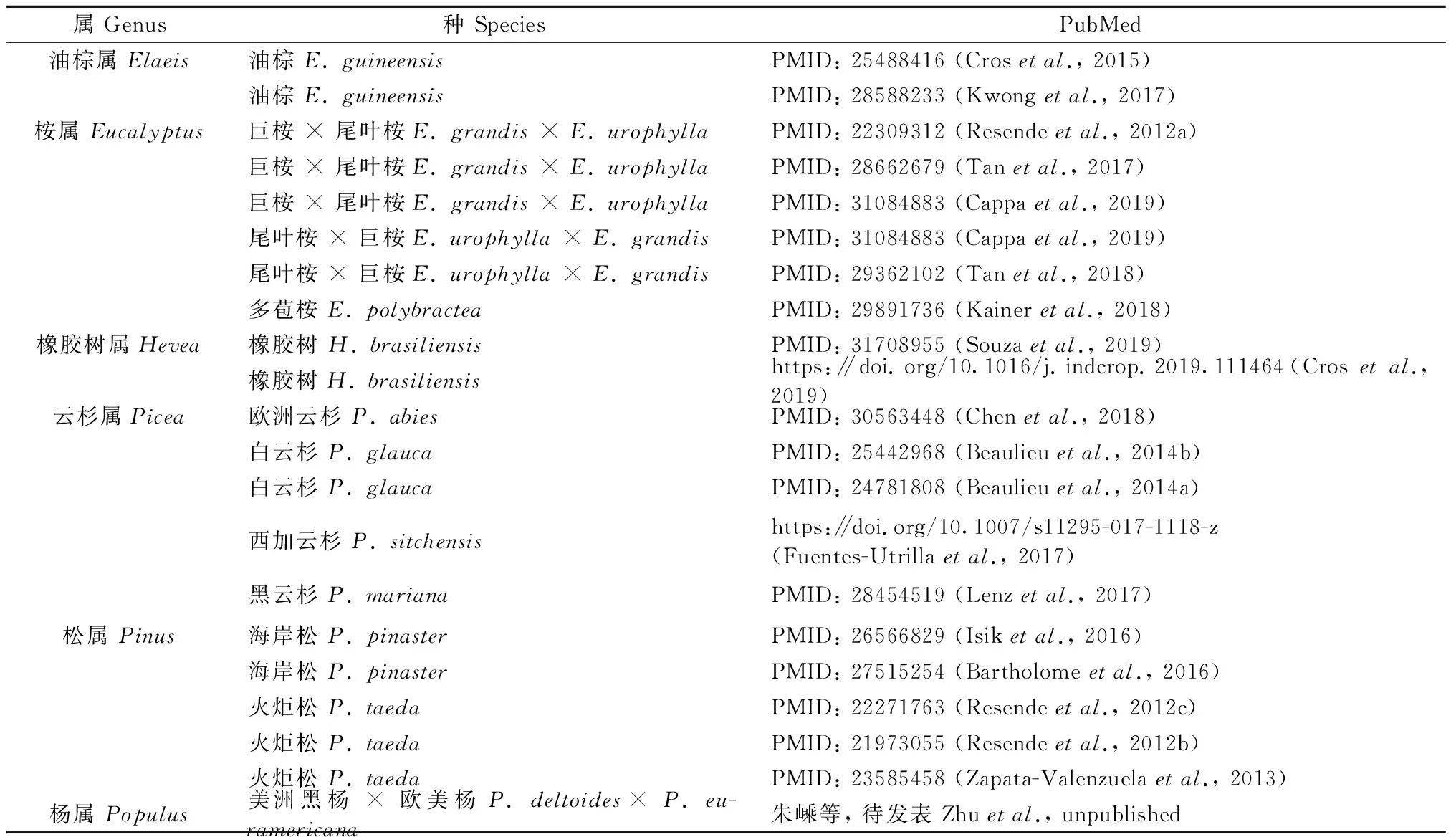
表2 林木树种GS研究报道①Tab.2 Study reports of genomic selection on forestry trees
2.2 林木GS研究概述
目前,林木基因组选择(GS)研究都是以多年生异花授粉树种为研究对象,这些树种的生长周期较长且遗传杂合度高。针叶树种和阔叶树种在开展GS研究的树种中几乎各占一半。开展GS研究的针叶树种主要集中在云杉属[例如,欧洲云杉(Piceaabies)、白云杉(P.glauca)、黑云杉(P.mariana)、西加云杉(P.sitchensis)]和松属[例如,火炬松(Pinustaeda)和海岸松(P.pinaster)](表2)。针叶树种一般拥有一个杂合度和重复序列比例极高的10 Gb级基因组,这为开展针叶树种GS研究带来了极大的挑战,特别是在覆盖全基因组的高密度标记(SNPs)开发方面(Nystedtetal., 2013; Biroletal., 2013; Nealeetal., 2014; Ziminetal., 2014; 2017)。
与针叶树种类似,已开展基因组选择研究的油棕属[油棕(Elaeisguineensis)、美洲油棕(E.oleifera)](Singhetal., 2013)、橡胶树属[橡胶树(Heveabrasiliensis)](Rahmanetal., 2013; Lauetal., 2016; Tangetal., 2016)、桉属[赤桉(Eucalyptuscamaldulensis)、巨桉(E.grandis)](Hirakawaetal., 2011; Myburgetal., 2014)以及杨属[毛果杨(Populustrichocarpa)、胡杨(P.euphratica)](Tuskanetal., 2006; Maetal., 2013)均有一个以上的物种完成了全基因组测序。由于杨树作为林木模式物种的重要性,毛果杨是第1个完成全基因组测序的树种,推动了林木基因组研究的广泛开展。南京林业大学杨树研究组以美洲黑杨×欧美杨(P.deltoides×P.euramericana)全同胞家系为材料,结合该家系100多个体的生长性状24年生的表型数据,通过基因组重测序获得100k级的SNP位点,估计育种值和遗传力的动态变化,并在此基础上开展GS研究(朱嵊等, 待发表)。

图1 林木GS案例的词云Fig.1 Wordcloud of the genomic selection cases in forestry trees育种群体、标记数据、目标性状和统计学方法的关键词分别用紫色、红色、黑色和黄色表示。字体的大小代表其在林木基因组选择案例中出现的频率。此词云图是由Python软件包wordcloud(https:∥pypi.org/project/wordcloud/)所绘制的。The keywords for breeding population, the amount of markers, the target trait and the statistical methods are denoted in purple, red, black and yellow, respectively. The font size represents the frequency of those keywords in the studies on the tree genomic selection. This wordcloud chart is drawn by the Python package wordcloud (https:∥pypi.org/project/wordcloud/).
GS是以育种群体(参考群体)的基因型数据(即标记数据)和目标性状表型数据作为基础数据,通过统计学方法构建目标性状的GS预测模型。为了更好地理解以上所列的林木GS研究案例,从育种群体、标记数据、目标性状以及统计学方法这4个方面对这些案例进行简单的概括和分析(图1)。1)育种群体:多采用由全同胞家系(full-sib)或半同胞家系(half-sib)组成的育种群体,这些研究案例中的林木树种均属于异花授粉植物,一次杂交可以获得数量巨大且性状分离的F1子代。2)分子标记数据:绝大部分研究案例都采用SNPs分子标记,这是因为SNPs标记在全基因组上分布广泛且数量巨大(Shastry, 2009),此特点与GS技术的“全基因组范围内的高密度标记”理念十分契合;基于SNPs芯片和基于重测序的SNP分型技术是为这些GS研究案例产生SNPs基因型数据的2种方式,针叶树种(云杉属和松属树种)案例的SNPs基因分型数据来自于SNP芯片,而阔叶树种(橡胶树属、油棕属和桉属)案例采用2种方式产生SNPs基因分型数据。3)目标性状:林木GS研究案例的目标性状可以简单地分成生长性状(树高、胸径、材积等)、木材性状(木材密度、纤维夹角、细胞壁厚度、弹性模量等)、果实性状(果/枝比、浆/枝比、核/果比等)、代谢性状(单株榨油率、精油总浓度、1,8-桉叶油素比例等)、发育性状(分枝数、萌芽率、生根率等)、纸浆性状(木质素含量、五碳糖和六碳糖含量、纸浆产量等)、抗性性状(冠瘿瘤体积、是否患锈病等)这几类;树高、胸径、木材密度、材积和纤维夹角(MFA, microfibril angle)是最常用的研究性状。4)基因组育种值(GEBV)的估计模型:GBLUP、Bayesian LASSO regression(BLR)、RR-BLUP和Bayesian ridge regression(BRR)是这些研究案例中常用的统计学估计模型。
基因组育种值(GEBV)估计精度是评价GS模型优劣的重要指标,也是GS研究的核心问题之一。GEBV估计精度受到多种因素的影响,包括标记类型与密度、标记抽样方法、数量性状位点(QTLs, quantitative trait loci)效应的分布、连锁不平衡(LD, linkage disequilibrium)、参考群体与测试群体之间遗传亲缘关系、参考群体样本量、样本间的亲缘关系、目标性状的遗传力与遗传结构、估计GEBV的统计学方法等(Habieretal., 2007; Grattapaglia, 2014)。在林木GS研究案例中,GEBV的精度范围为-0.41~0.95,目标性状内在属性(例如,遗传力和遗传结构)、LD、标记密度和统计学估计模型等影响因素均被探讨。
然而,这些研究都存在一个共同的不足:忽略树龄与目标性状GEBV估计精度之间的关系。多年生木本植物的很多性状(例如,生长性状和木材性状)遗传力与其树龄存在一定联系。遗传力与基因组预测精度存在正相关(Resendeetal., 2012c),因而树龄与目标性状GS精度也是存在一定关系的。
2.3 典型案例分析——以油棕GS研究为例
油棕是最早开展系统性GS研究的林木树种之一,其GS研究案例极具代表性。油棕GS相关研究主要分成2个方面:基于模拟数据和真实育种数据。Wong和Bernardo(2008)使用3个不同群体大小(N=30, 50, 70)的油棕模拟数据系统评估3种早期选择技术的效率发现:相比于表型选择和分子标记辅助选择(MAS),基因组选择(GS)具有更高的选择效率和更好的选择效果,即使对规模较小的育种群体(Wongetal., 2008)。Cros等(2018)基于连续4个育种周期的油棕果穗性状模拟数据,分析GS轮回选择和传统轮回选择在多世代育种中的选择效率发现:GS轮回选择具有更好的选择效果,GS模型的准确性随着模型校准数据的世代增加而提高。
Cros等(2015)使用油棕Deli和Group B 2个群体(每个群体均由131个个体组成)的265个SSR标记数据构建8个含油量重要性状的GS模型,研究证实:1)GS模型的预测精度要高于基于谱系模型;2)对于群体较小且育种周期较长的育种程序GS模型是比较有效的,这与油棕模拟数据的评估结果(Wongetal., 2008)一致。Kwong等(2017)利用油棕UR×AVROS商业群体1 218个体的SNP基因分型数据(SNP芯片OP200K)和6个含油量相关性状表型数据进行GS研究发现:1)GS预测精度与目标性状的遗传力有关;2)不同GS模型(例如RR-BLUP、BayesA、BayesCπ、Bayesian LASSO regression(BLR)和Bayesian ridge regression(BRR)等)具有近似的预测精度,类似结果也在多苞桉(Eucalyptuspolybractea)(Kaineretal., 2018)、火炬松(Resendeetal., 2012c)和橡胶树(Crosetal., 2019)等中发现;3)GS预测精度伴随着标记数的增加而提高。相比2015年油棕GS研究案例(Crosetal., 2015),2017年油棕GS研究(Kwongetal., 2017)的最大改进之一:标记数量从265个SSR标记升级到9万个有效SNP标记,真正意义上实现GS技术理念“使用覆盖全基因组范围的高密度分子标记”。
3 林木基因组选择研究的影响因素
3.1 参考基因组
参考基因组(质量与大小)是GS应用于目标物种遗传改良的前提条件。高质量的参考基因组是通过二代测序技术或SNP基因分型芯片技术获得覆盖全基因组的高密度SNP基因分型数据的基本保障。目前,已经完成的林木树种基因组质量普遍较低,例如20 Gb白云杉基因组(v4.1)拥有3 033 322个scaffolds,423 Mb毛果杨基因组(v3.0)拥有1 446个scaffolds,都还远未达到拟南芥(Arabidopsisthaliana)和水稻染色体水平的基因组质量。因此,林木参考基因组质量低必将是GS在林木遗传改良中应用的一个重要限制因素。
基因组庞大是针叶树种最显著的特点之一,例如20 Gb级的白云杉、欧洲云杉和火炬松基因组。庞大基因组致使针叶树种需要巨大的DNA测序成本和数据分析成本,这也是针叶树种GS研究仅采用SNPs基因分型芯片获得标记数据的原因之一。举个例子,假设一个样品DNA重测序的深度10×,一份欧洲云杉(20 Gb)和杨树(0.5 Gb)材料分别需要200 Gb和5 Gb测序数据,即欧洲云杉DNA重测序所需的测序费和数据分析费是杨树材料的40倍。
3.2 全基因组关联分析
全基因组关联分析(genome-wide associated study, GWAS)是一种从覆盖全基因组的高密度SNP标记中鉴定出目标性状相关标记的统计学方法,也将有助于为基因组育种值(GEBV)估计提供更精炼的候选标记。然而,随着基于测序或芯片的高通量SNP基因分型技术发展及其在林木遗传研究领域的不断深入运用,单标记成本不断下降和标记数据规模不断扩大是林木GS研究的发展趋势。SNP分子标记密度骤增不仅增加GEBV的计算成本,同时大量目标性状无关的标记必将给估算GEBV带来不可避免的背景噪音,一定程度上影响GEBV的估计精度。因此,在估算GEBV前筛选性状相关标记是十分必要的。
GWAS已被应用于解析林木树种复杂性状的遗传结构,例如毛果杨(Chhetrietal., 2019)、巨桉与尾叶桉的种间杂种(Mulleretal., 2019)以及欧洲云杉(Baisonetal., 2019)。然而,由于受限于林木生物学特性及其相对不稳定的遗传转化体系,功能性解析林木GWAS所鉴定的候选位点/基因仍然面临不少困难和挑战(Duetal., 2018)。
3.3 育种群体
双亲杂交是林木树种产生育种群体的方式,其育种群体主要可分为全同胞家系(full-sib)、半同胞家系(half-sib)以及轮回杂交群体(recurrent hybrid population)。然而,由于林木树种一般具有世代周期长(long generation time)、幼龄期长(long juvenile phase)、个体十分巨大(giant plant size)(子代测定时单株种植面积极大)等特点,因而很难在多世代(2个以上世代)家系内开展良种选育(Iwataetal., 2016)。另外,不同于家畜的单胎产仔量较少,异交林木树种的一个杂交组合(全同胞家系或半同胞家系)可以产生成百上千个F1子代,并且子代个体间的差异较大。因此,单个或少量几个全同胞/半同胞家系组成的F1群体是林木遗传改良中的常见育种群体,该群体内个体间的谱系关系几乎是没有区别的(即个体间亲缘关系非常近)。
基因组育种估计值(GEBV)的准确性是GS在动植物育种中应用的核心问题之一。GEBV准确性是利用GEBV与真实育种值(true breeding value, TBV)相关系数(r)来评估,GEBV准确性的理论公式(Daetwyleretal., 2008; 2010)如下:
(5)
式中:Np为参考群体样本量,h2为目标性状的遗传力,nG为独立标记/位点数。
根据该公式,参考群体样本量与基因组选择的准确性(r)存在一定的联系,样本量的增加也将有助于基因组育种估计值准确性的提高。另外,用于构建基因组选择模型的参考群体与候选群体之间的亲缘关系也会一定程度影响基因组育种估计值的准确性,2个群体之间亲缘关系越近基因组育种估计值可能越精确(Habieretal., 2010; Liuetal., 2015; Maetal., 2018)。因此,在F1子代样本量大且个体亲缘关系较近的林木全同胞/半同胞家系内进行基因组选择,很可能获得准确性较高的基因组育种估计值。
3.4 连锁不平衡(LD)
连锁不平衡(LD)是指分子标记与相邻QTL位点的非独立遗传,决定了基因组选择的精度及其所需标记密度/数量(Liuetal., 2015)。LD程度的高低决定了基因组选择所需的标记密度,即LD程度与所需标记数量呈正相关(Iwataetal., 2016)。林木遗传改良的目标性状(例如,生长性状和木材性状)很大一部分都是由大量的微效QTL位点共同控制的复杂性状,这就需要足够高的标记密度来满足GS的基本假设:所有QTL位点与至少1个标记存在强的连锁不平衡关系(Rabieretal., 2016)。
3.5 林木多年生属性
多年生是林木树种最突出的生物学属性之一,决定了树木生长发育过程受到多年环境因子(土壤、海拔、气候及栽培条件)和树龄等因素影响(林元震, 2019; 李安鑫等, 2019; 杨保国等, 2020; 伍汉斌等, 2019)。基于林木目标性状多年数据(纵向数据, longitudinal data)预测其目标性状的多年生长发育轨迹是林木GS研究的发展趋势。然而,当前并不存在满足此需求的统计学模型和分析工具,因此开发针对林木多年生属性的统计学模型和分析工具是林木GS研究面临的最大挑战之一。
多年生木本植物形态学和生理学等性状(例如,叶片形态、气孔导度、光合作用效率等)与树龄存在一定程度的相关性(Bond, 2000; Dayetal., 2002)。研究表明:日本落叶松(Larixkaempferi)(Diaoetal., 2016)、杨树(Pliuraetal., 2006; Dhillonetal., 2010)和桉树(Osorioetal., 2001)的生长性状和木材性状的遗传力随着树龄增加而变化,意味着这些目标性状基因组育种值的估计精度与树龄具有相关性。多年生生物的基因表达模式与其年龄也是存在一定联系。虽然目前尚未见到林木树龄相关基因的分子功能研究案例,但是不同树龄间基因表达差异谱已在银杏(Ginkgobiloba)、日本落叶松、侧柏(Platycladusorientalis)等树种被研究和分析(Lietal., 2017; Changetal., 2017; Wangetal., 2020)。Wang等(2020)比较银杏不同树龄微管形成层的基因表达谱发现:712个基因和233个miRNA呈现出差异性表达,它们可能与细胞分裂、细胞分化、植物激素代谢通路等有关。
4 问题和展望
目前,GS技术已经成功应用于动物(家畜)育种实践,并取得很好的效果,加速了动物育种进程;GS在植物遗传改良方面也取得一定的研究进展;林木GS研究进展表明该技术在林木育种中极具应用潜力。随着高通量基因组学数据的分析平台和快速海量表型组学数据的采集与解析平台逐步成熟以及应用研究深入开展,各类林木的基因组学、表型组学和遗传学等背景数据也将日臻完善,将为林木树种GS研究提供一个有力的技术支持和数据支撑。应用于林木遗传改良的GS技术,也将为林木功能基因组研究和林木优良品种(品系)选育提供坚实的理论基础。因而,GS技术体系是一种极具发展前景的、精准有效的林木育种策略,必将在林木育种实践中被逐步建立和完善;但在林木GS应用推广前,仍需要利用大量的模拟数据和真实数据评估和验证GS技术在林木育种实践中的可行性(Grattapagliaetal., 2011)。
鉴于林木GS技术的潜在应用前景和重要价值,林木GS研究重点为以下几个方面:
1)基因组组装质量是开展GS研究的基础。然而,目前林木树种基因组组装质量普遍不高,因此提升参考基因组的精度和质量仍将是开展高质量林木GS研究的一个重要条件。
2)合理试验方案是林木树种GS研究顺利实施的基本保障。设计GS试验方案时应考虑目标树种和目标性状的自身特点,例如,目标树种参考基因组的大小和质量、多年生属性、育种群体的遗传组成、目标性状的遗传结构等。
3)多性状复合选择将是林木GS研究的新趋势。目前林木GS研究案例仍然专注于单个性状的基因组育种值估计,但是随着社会需求的多样化,培育同时兼具生长、材性、抗性等优势性状的新品种已成为当前林木遗传改良工作的新趋势。
4)多年生属性是林木GS研究面临的主要挑战之一。多年生属性使得林木树种的目标性状数据具备纵向性(longitudinal),具备处理纵向性状数据能力的GS统计模型和分析软件仍处于空缺状态。
5)借鉴家畜和农作物GS成功案例,设计出适合林木树种特点(多年生、异交和全同胞家系成员庞大)的GS分析模型和工具,必将是构建林木GS研究技术体系的有效捷径。
