基于卷积神经网络的小麦产量预估方法
2020-12-29王曼韬刘江川
鲍 烈,王曼韬,*,刘江川,文 波,明 月
(四川农业大学 a. 信息工程学院;b. 农业信息工程重点实验室,四川 雅安 625000)
我国是农业大国,小麦作为主要粮食之一,在农业生产中有着相当重要的地位,其产量是评估农业生产力的重要指标之一。对小麦产量的预估是农业生产中不可或缺的一步,准确的产量预估可以给农业生产管理决策提供较好的参考。小麦产量一般用单位面积内麦穗的个数来表征。对于单位面积内麦穗个数的统计,可分为2种方式:一种是人工计数,结果较为准确,但是人力资源开销大,并且缺乏统一的计数标准;另一种是利用数字图像处理技术进行计数,方便且省时省力,缺点是精确度不够高。
近年来,随着计算机技术水平的提高,农业信息技术紧随其后,传统农业生产技术与信息技术的结合将成为农业发展的必然趋势。数字图像处理技术也与农业生产结合得越来越紧密,在植物病虫害[1-4]、植物计数[5-6]、草类识别[7-10]等领域应用广泛。在小麦计数[11-12]上也有一些应用,比如刘哲等[13]改进机器学习算法kmeans,对麦穗图像进行聚类,然后通过划分连通域进行计数;该方法的缺点是对于密集程度较高的小麦无法起到很好的效果,特别是对于重叠部分的小麦,无法准确识别,并且该算法对于正样本和负样本的对比度要求较高,若对比度太低,聚类的效果就相对较低。李毅念等[14]利用特定装置以田间麦穗倾斜的方式获取田间麦穗群体图像,通过转换图像颜色空间RGB→HIS,提取饱和度S分量图像,然后把饱和度S分量图像转换成二值图像,再经细窄部位黏连去除算法进行初步分割,然后由边界和区域的特征参数判断出黏连的麦穗图像,并利用基于凹点检测匹配连线的方法实现黏连麦穗的分割,进而识别出图像中的麦穗数量。范梦扬等[15]采用SVM学习的方法,精确提取小麦麦穗轮廓,同时构建麦穗特征数据库,对麦穗的二值图像细化得到麦穗骨架,最后通过计算麦穗骨架的数量和麦穗骨架有效交点的数量,得到图像中麦穗的数量。此外,张领先等[16]利用卷积神经网络建立麦穗识别模型,但其使用的滑窗尺寸固定,并且是依靠经验设定;而麦穗经常大小不一、形状各异,会使得检测效果大打折扣。其他类似的应用比如张建华等[17]改进VGG卷积神经网络建立棉花病虫害识别模型,陈含等[18]利用Sobel算子进行边缘检测,对麦穗进行图像分割,从而进行麦穗识别计数。
河南省新乡、漯河两地盛产小麦,并且平原面积大,舒坦辽阔,易于试验的施展。小麦预估产量作为生产指导的重要参考,对当地农户有着重要意义;但由于自动化技术相对落后,只能进行人力统计,工作繁琐且结果误差较大。为解决该问题,在当地农户提供场地、设备的基础上,利用大疆无人机“御”Mavic在河南省新乡、漯河两地进行图像采集,构建研究样本数据集。针对麦穗计数任务提出一种CNN模型,简化CNN结构,减少模型参数,提高模型检测速度。实现对复杂背景下麦穗的快速计数和产量预估。本研究的优势在于不用进行繁琐的人工提取特征,并且算法对光照等环境条件具有较强的适应性和鲁棒性。
1 材料与方法
1.1 材料
利用大疆无人机“御”Mavic在河南省新乡、漯河两地进行图像采集,无人机工作高度为距地10 m。为了增强模型对小麦接近成熟前形态的泛化能力,在小麦泛黄前进行为期3个月的图像采集工作,经过筛选累计采集麦穗图像1 691张,新乡、漯河分别为867和824张,图像分辨率为4 056 pixel×3 040 pixel,采集得到的原图如图1所示。为了进行产量预估,将图像裁剪至红框内边,1个红框覆盖的面积为1 m2,即数据集中每张图像所代表的是1 m2内所有的麦穗。随机抽取100张作为测试图像,再分别对余下1 591张图片中的麦穗、叶子和背景进行采样。每张图像约采集20~30个麦穗,共计31 505张作为模型的正样本集。同样的方式采集叶子和背景共计29 987张作为负样本集,并且统一像素为64 pixel×64 pixel。研究中将数据集划分为训练集、验证集和测试集,数据集的构成如表1所示。

图1 无人机所拍摄的图像Fig.1 Images taken by UAV
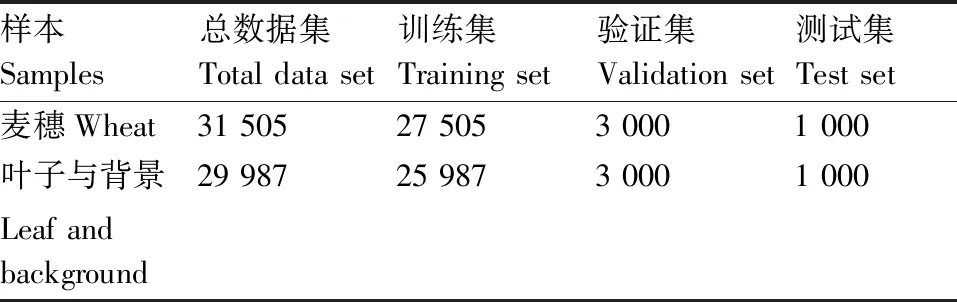
表1 数据集结构
1.2 方法
1.2.1 试验环境与模型训练
试验硬件环境为:Intel i7处理器(内存8GB),NVIDIA GeForce GTX1060 GPU(显存6GB),64位Windows10系统。软件环境为:Python3.6,TensorFlow深度学习框架。使用随机梯度下降进行优化,动量为0.9,总共训练100 000次,初始学习率设为0.001,每隔3 000次进行衰减系数为0.1的学习率衰减,batch size设为128,采用K折交叉验证。
1.2.2 CNN网络模型
本文设计的CNN模型由卷积层、池化层、全连接层和SoftMax层组成[19]。输入图像是多张从无人机拍摄的图像上截取的单一麦穗,统一像素为48 pixel×48 pixel。整个网络分为5个卷积层、4个池化层、2个全连接层,以及最后的SoftMax层。网络结构为:卷积层1、2各包含32个大小为3×3的卷积核,卷积层3包含64个大小为3×3的卷积核,卷积层4、5各包含128个大小为3×3的卷积核,卷积步长皆为2。4个池化层皆为最大池化,大小为2×2,穿插在卷积层之间,可以极大程度地减少参数量,降低计算成本。2个全连接层将特征进行矢量化,全连接层1包含512个神经元,全连接层2包含100个神经元;全连接层之后加入Dropout层,随机丢弃1/2的神经元,减少过拟合的风险。最后利用SoftMax层将向量划分为麦穗和背景2个类别,网络结构如图2所示。
1.2.3 基于高斯图像金字塔的多尺度滑窗
利用高斯金字塔[20-21]进行多尺度检测,可以模仿图像的不同尺度,也是模仿人类的视觉,比如先近距离观察一幅图像,然后在远距离观察,看到的图像效果是不同的。前者会比较清晰,后者会比较模糊,前者比较大,后者比较小,通过前者能看到图像的细节信息,通过后者能看到图像的轮廓信息。为了降低数据集图片缩放带来的影响,并且实现多尺度检测麦穗,本文采用基于高斯图像金字塔的多尺度滑动窗口来对图像进行检测,金字塔缩放因子为1.2,即对原始图像(第0层)依次进行1/1.2缩放比例进行降采样,得到共计8张图片(包括原始图像)。然后利用不同大小的滑动窗口在图像上滑动,每滑动一个步长,就对窗口进行一次麦穗检测。由于是对整张图像进行滑动,所以不会漏掉可能出现麦穗的位置,这样可以极大地降低算法的漏检率。并且,利用图像金字塔可以实现多尺度检测麦穗,当模型漏检时,图像进行缩放以后可以提高漏检目标的检出率。
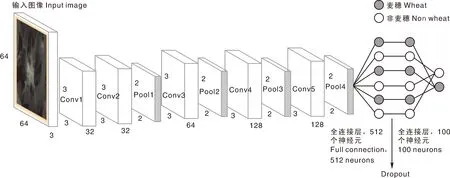
图2 CNN网络结构Fig.2 CNN network structure
高斯金字塔构建过程如下:
(1)先将图像放大1倍,在放大的图像上构建高斯金字塔。
(2)对扩大的图像进行高斯模糊,8幅模糊的图像构成一个八度[八度即在特定尺寸(长宽比)下,经过不同高斯核模糊化之后的图像集合,八度的集合就是高斯金字塔],然后对该八度下最模糊的一幅图像进行下采样。
(3)下采样的过程为长和宽分别缩短1倍,图像面积变为原来四分之一,这幅图像就是下一个八度的初始图像。
(4)在初始图像上完成属于这个八度的高斯模糊处理,以此类推,完成整个算法所需要的所有八度构建,构建完所有的八度,高斯金字塔就构建完成。构建出的金字塔如图3所示。
1.2.4 具体检测方式
先对整张图片建立图像金字塔,然后以3种

图3 图像金字塔Fig.3 Image pyramid
不同纵横比的滑动窗口[22]在整幅图像上滑动,滑动步长取为16。3种纵横比的滑动窗口如图4所示。每种颜色代表一种纵横比。每滑动一次,对3个滑动窗口进行一次检测,并且整个滑动过程以绿色框为主要滑动窗口,即每次滑动计算都以绿色框为单位,其他2个框随之相对滑动。最后取其中判为麦穗的概率值得分最高的框作为最终的结果。

图4 三种纵横比的滑动窗口Fig.4 Sliding windows by three aspect ratios
对于一张像素为464 pixel×464 pixel的麦穗图像,根据图形金字塔需要检测8种尺度,加上滑动窗口的3种纵横比,步长16,则每张图像总共需要分类15 000次,如图5所示。
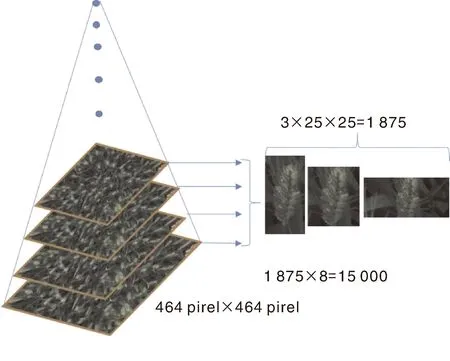
图5 滑动窗口效率Fig.5 Efficiency of sliding window
1.2.5 非极大值抑制(NMS)
进行滑动窗口预测后的结果中存在着大量重叠率较高的目标框,为了避免重复计数,本文利用非极大值抑制[23]去掉重叠率较高的框。非极大值抑制实际上就是一个迭代的过程,算法的具体过程如下:
(1)将所有的框以概率得分的大小进行排序。
(2)选取得分最大的框,并计算它与相邻的框的IOU,得分高于阈值则删除。
(3)从剩下的框中选取概率得分最大者,重复迭代2、3过程,直到找到所有目标区域。
IOU的计算公式为
(1)
式(1)中:A、B代表2个相邻的框,RIOU代表这个2个框重叠的比率,Area()为面积函数。目标检测任务中,一般设定IOU阈值为0.5,也有设置梯度阈值的算法比如IOUNet。而在本研究中,麦穗作为检测目标,其密度较大,数量较多,体积小,并且相对其他数据集(如VOC、COCO等)来说,有着更加复杂的背景。所以本文设置IOU阈值为0.2,以适应其大密度,避免留下过多的重复计数框。
1.2.6 小麦产量预估方法
对小麦产量进行预估时,与数据集构建的步骤一样,同样利用红框对无人机进行参数(飞行高度、聚焦等)调整,使镜头刚好能将红框包含进去;然后利用无人机对大田进行随机采样,将采样的图像根据像素值(根据红框像素值范围,可以定位到红框)截取红框内部部分图像作为数据集,再进行麦穗计数,取每次采样中麦穗个数的平均值,得到每平方大田麦穗数量的预估值。设总的麦穗数量为N,每m2大田麦穗数量的预估值为t,大田总面积为a(m2),则计算公式为
N=t×a。
(2)
此外,如需要对麦穗产量进行预估,则需要对每个麦穗的质量进行随机采样,取其平均值。设总的麦穗产量(质量)为M,每个麦穗的平均质量为m,则麦穗的预估产量(质量)为
M=N×m=t×a×m。
(3)
2 结果与分析
2.1 试验结果评估
对麦穗检测模型进行训练,该模型在验证集上的分类准确率为99.3%,在测试集上的分类准确率为98.7%。为了验证整个检测模型的精度及其有效性,利用预留的100幅单位面积的麦穗图像做测试,试验结果如表2所示。人工统计所有麦穗目标的数量和正确位置,麦穗目标共计12 530个,通过算法检测共计12 632个麦穗目标,其中正确找出麦穗的目标框为12 288个,错误把背景或叶子当作麦穗的目标框数为298个,遗漏43个正确目标,与人工统计的误差数为341个,正确检测率为97.30%。图6为实验结果中的样例图。

表2 试验结果统计
VGG-16是一种很经典的轻量级网络,与本文网络量级接近,因此,利用麦穗数据集训练VGG-16模型与本文网络模型进行对比,验证本文网络的有效性,试验结果如表3所示。VGG-16的误检率比本文网络高0.29%,漏检率高2.04%,总误差率高2.33%。说明Wheat-Net检测精度高于VGG-16,并且由于Wheat-Net的网络参数少于VGG-16,Wheat-Net检测一张图像只需要0.115 s,而VGG-16需要0.433 s。之所以会得到这个结果,在于VGG-16的输入图像像素为224 pixel×224 pixel,单个麦穗根本无法达到这么大的尺寸,必须对图像进行相应的缩放,从而导致图像一定程度的失真。而本文的模型是针对麦穗常见尺寸并遵循卷积神经网络结构而设计,能够提取真实尺寸的麦穗目标特征,所以分类效果更好;并且因为参数量小,所以速度更快。

表3 VGG-16和Wheat Net方法的结果对比
最后从100幅图像中随机抽取10张图像的统计结果进行展示,结果如表4所示。算法计数与人工统计的误差率最高为7.46%,最低为1.87%,并且误差来源多数为误检,说明算法的误差多为错把背景或叶子判定为麦穗,而漏掉的麦穗目标并不多。后续优化可以考虑从减少错判的方向入手,通过适当增加背景和叶子的样本量等方式提高模型的泛化能力。表4还罗列出了算法在每张图中正确框出麦穗目标的数量、错误识别数量,遗漏的麦穗目标数量、误差数(误差数=误检数+漏检数)和误差率。

图6 试验结果样例Fig.6 An example of test results
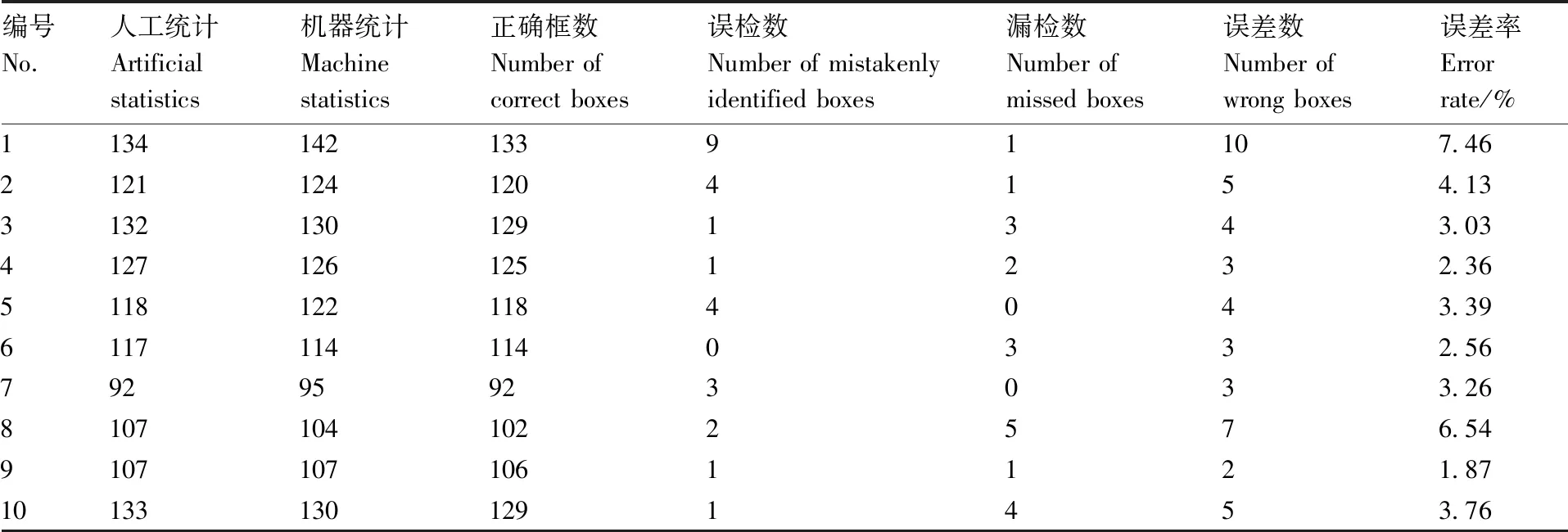
表4 随机10幅图像测试结果
为了验证在不同光照条件下,本算法的实际应用效果,随机选取50张中午拍摄和50张傍晚拍摄的图像进行检测,检测结果如图7和表5所示。在随机选取的50张测试图像中傍晚拍摄的检测误差率为3.25%,中午拍摄的检测误差率为4.71%,差异不显著,说明本文算法对光照条件敏感度较低。原因在于样本集中包括了不同光照条件下的麦穗样本,所以对光照条件不敏感;并且为了使样本多样化,从而使模型更鲁棒,在进行样本筛选时,尽量选择了背景不同、光照不同的样本。

表5 在不同光照条件下的照片测试对比

a,傍晚拍摄;b,中午拍摄。a, Pictures taken at nightfall; b, Pictures taken at noon.图7 不同光照条件下拍摄的照片Fig.7 Pictures takenunder different lightingconditions
2.2 与其他算法的对比分析
当前基于传统计算机视觉算法实现麦穗计数的方法很多,也有基于深度学习的方法。张婷婷[24]提出改进堆叠沙漏网络对小麦群体图像的小麦麦穗计数的方法,能提高对存在遮挡、交叉的麦穗的检测效果,并且引入了注意力机制来提高麦穗的分类准确率,检测平均准确率为91.37%;但是该方法引入了大量的参数,降低了网络检测速度,同时未对小目标麦穗做出对应的处理;而在现实场景中,小目标麦穗所占比重很大,这也导致了该算法精确度无法进一步提高。高云鹏[25]对比了目标检测算法YOLOv3与Mask R-CNN对大田小麦麦穗的检测效果,其中YOLOv3的识别准确率为87.12%,单张检测时间为0.12 s,Mask R-CNN的识别准确率为97.00%,单张检测时间为0.94 s,YOLOv3准确率低,速度快,Mask R-CNN准确率高,速度慢。李鹏[26]在不同的颜色空间下,通过对比各个颜色通道的灰度图像与直方图,选取出分割效果较好的RGB-灰度图、Lab-L、HSV-V颜色空间,采用多阈值分割算法实现小麦麦穗与土地、麦叶的分割;同时结合小麦麦穗的形态学特征对其进行开运算处理,提取目标麦穗的平均准确度为96.55%。这4种算法是目前业界较为优秀的方法。本文方法与这4种方法进行比较,结果如表6所示。本文算法的漏检率0.34%,误差率2.70%,均为最低,误检率略高于Mask R-CNN,准确率为97.30%,高于其他算法,且检测1张图像所需要的时间为0.115 s,优于其他算法。
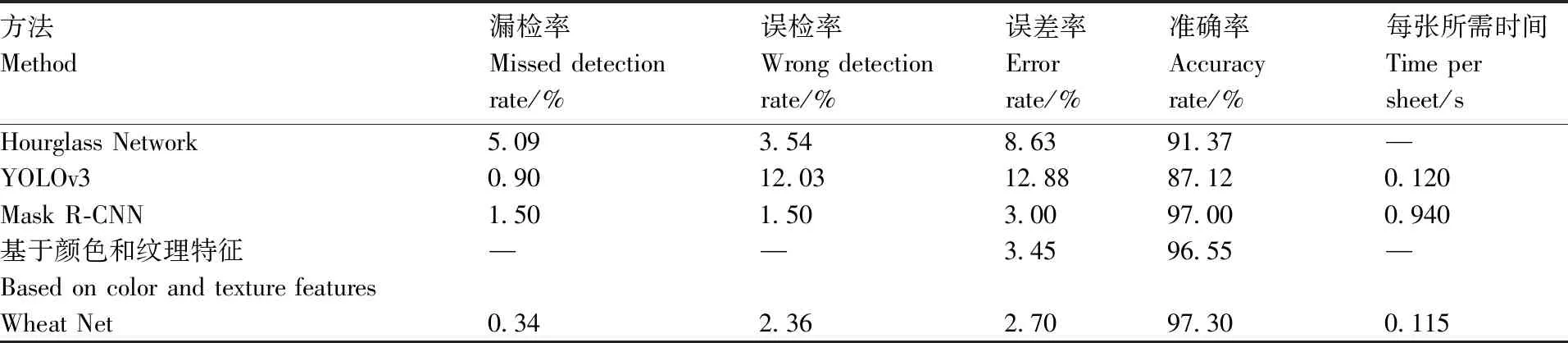
表6 不同算法的实验结果对比
2.3 麦穗估产试验评估
以新乡1号大田、新乡2号大田、漯河1号大田、漯河2号大田为例,分别进行图像采样,各采集100张图像进行麦穗计数任务,并随机在每片大田中各采样100株麦穗,统计各大田单株麦穗的平均质量m,设算法对每平方大田麦穗数量的预估平均值为t,大田总面积为a。计算得到新乡1号大田(42 000 m2)、新乡2号大田(30 000 m2)、漯河1号大田(18 000 m2)、漯河2号大田(24 000 m2)的预估产量分别为29 728.44、20 287.20、11 979.90、15 522.24 kg(表7)。预估产量单位为kg·m-2,4片大田预估产量的误差率分别为新乡1号大田2.90%、新乡2号大田3.03%、漯河1号大田3.08%,误差率最高为漯河2号大田,达到4.84%,误差产生原因是人工称量和随机采样可能造成误差。总体来说,产量预估误差在可接受范围内。

表7 大田小麦产量预估数据统计
3 结论与讨论
本文采集并制作了麦穗数据集SICAU-WHEAT,针对农业生产需求,以及小麦的形态特征,设计了神经网络模型,在保证精确度的同时尽可能地减少模型的参数,缩短计数所需的时间。利用滑动窗口结合图像金字塔的方式实现多尺度检测,提高算法对各种尺度目标的识别精度,降低麦穗的漏检率和误检率。从试验结果可以得出以下结论:(1)检测算法的误差多来源于误判,对叶子和麦穗的区分精度不够理想,说明模型对麦穗和叶子分类的泛化能力不足,后续可以通过增加叶子样本集和引入细粒度分类等方式进行优化;(2)对比中午和傍晚的检测结果可以看出,模型对光照条件不敏感,可以对不同光照条件下的麦穗图像进行检测;(3)与其他先进算法相比,本文算法检测精度为97.3%,漏检率0.34%,优于其他算法;(4)产量预估试验中,本文的预估方法平均误差率为2.7%,能够较为准确地对小麦产量进行预估。综上所述,本文算法可以适应光照条件的变化,克服叶子和其他杂物的干扰,对麦穗进行快速检测,并统计其数量,进而实现对麦穗的产量预估。
