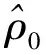不依从情形下因果效应的可识别性分析
2020-12-28文高
文 高
(广州大学 经济与统计学院,广东 广州 510006)
因果推断一直以来便是经济学、医学、生物学等领域研究的重点问题,其中,虚拟事实模型(Rubin Causal Mode,RCM)是因果推断中应用非常广泛的一种模型.然而,由于RCM不完全由观测数据间的相关性决定,导致在讨论因果效应时存在可识别的问题.
基于RCM 模型进行因果推断时,由于反事实效应的存在,个体的因果效应无法识别.但是,如果假设实验组和对照组的被研究个体是完全随机分配的,那么总体的平均因果效应(Average Causal Effect, ACE)是可以识别的.然而,在实际研究中,被研究的个体可能会出现不依从、提前离开等情况.例如,对于相对保守的病人,无论医生将其分配到实验组还是对照组,该病人实际上最终都选择在对照组,这就出现了不依从的现象;又比如,当采用双盲试验时,假如某些病人已经了解到实验组中病人的结果明显好于对照组,则该病人可能会提前离开试验,并去其他医院选择治疗.当被研究的个体不依从或者提前离开时,就会导致出现不依从和不可忽略缺失值的数据存在.
当存在不依从与不可忽略缺失值的随机对照试验数据时,基于“主分层(Principal stratification)”潜在框架分析依从者的平均因果效应(Complier Average Causal Effect, CACE)是相对成熟且比较流行的方法[1].当使用“主分层”潜在框架分析CACE时,关于 CACE的可识别性引起了广泛的关注.并且,不同缺失数据的机制对于CACE的可识别性以及CACE模型的估计具有相当大的影响.在可忽略缺失机制下,O′Malley等[2]以及Zhou等[3]给出了在某些宽松的假设条件下,CACE是可识别的.在不可忽略机制下,Chen等[4]研究了当因变量是离散的情形下,CACE是可识别的.在2016年,Chen等[5]研究了当因变量是连续的情形下,CACE是可识别的.然而,他们研究的重点都在于CACE本身的可识别问题,并没有对CACE进行参数化建模,进而说明模型中的参数是可识别的.模型中的参数可识别是指,若有两组参数向量θ,θ*描述了同样观测数据的概率分布,即似然函数L(θ)=L(θ*)=L(θ),则这两个参数向量必须相等,即θ=θ*.模型的可识别是估计量满足相合性和渐近正态性的前提条件.
在基于似然方法的不可忽略缺失数据研究中,Kim等[6]于2011年提出了指数倾斜似然的方法,假设了缺失模型是Logistic 模型.Yang等[7]与 Shao等[8]的研究是基于工具变量的方法,即假设存在工具变量使得它仅与因变量相关或者仅与缺失数据的倾向相关.Miao等[9]于2016年的研究中指出,在因变量满足正态分布的前提下,当使用logistic模型建立缺失机制时,只要缺失关于因变量参数的符号已知,则可以保证模型是可识别的.2017年Cui等[10]说明了,即使将因变量从正态分布扩展成指数族分布时,Miao的结论依然成型.本文基于 Logistic模型对CACE进行参数建模,在假设不存在协变量的情况下,使用联合似然的方法进行模型估计,得出两点结论:①如果描述缺失机制模型中的参数可识别,则整个模型中的参数可识别;②如果描述缺失机制模型中的参数的可识别性未知,则整个模型中的参数是不可识别的.
1 符号与假设
对于个体i,Zi=1表示个体i被随机分配到实验组,Zi=0表示个体i被随机分配到对照组.Di(z)=1表示个体i实际接受治疗,Di(z)=0表示个体i实际接受对照.Yi(z)=1表示个体i的结果满意,Yi(z)=0表示个体i的结果不满意.Ri(z)=1表示Yi(z)没有缺失,Ri(z)=0表示Yi(z)缺失.这里需要注意的是,Di(z),Yi(z),Ri(z)都是个体i在假设Z=z的潜在结果.本文记Di,Yi,Ri为个体i实际观测的结果.
1.1 不依从下的因果效应与主分层
当Zi≠Di时,就称为“不依从”.本文用Yi表示个体i的因变量.基于这种数据,传统的分析要么直接基于变量Z作为自变量,忽略变量D的存在;要么直接基于变量D作为自变量,忽略变量Z的存在.前一种方法虽然满足随机性,但由于忽略实际处理变量D,因而没有实际意义;而后一种不满足随机性,导致结果没有说服力.
因此,本文采用Frangakis等[1]提出的“主分层”的框架来分析.记Ui为个体的潜在结果,则
(1)Ui=c, 如果Di(1)>Di(0);
(2)Ui=n, 如果Di(0)=0且Di(1)=0;
(3)Ui=a, 如果Di(0)=1且Di(1)=1;
(4)Ui=d, 如果Di(1) 其中,c,n,a,d分别代表个体i是依从者、永远放弃治疗的人、永远接受治疗的人,以及反对者.这里需要注意,Ui是一个无法观测的潜在变量.本文研究的对象是: CACE=E(Y(1)-Y(0)│Ui=c), 其中,Y(1)表示在实验组中的因变量,Y(0)表示在对照组中的因变量. 假设1:在实验组或对照组中的被研究个体相互独立; 假设2:Z是随机的; 假设3:单调性假设P{Di(1)≥Di(0)}=1; 假设4:对于Ui=n和Ui=a的个体采用类似双盲试验的假定 P{Yi(1)|Ui=n}=P{Yi(0)|Ui=n}, P{Yi(1)│Ui=a}=P{Yi(0)│Ui=a}; 假设5:对于Ui=n和Ui=a的个体,采用混合双盲试验的假定 P{Yi(1),Ri(1)|Ui=n}=P{Yi(0),Ri(0)|Ui=n}, P{Yi(1),Ri(1)|Ui=a}=P{Yi(0),Ri(0)|Ui=a}; 假设6:对于z=0或z=1满足 P{Ri(z)│Yi(z),Di(z),U=u}= P{Ri(z)│Yi(z),Di(z)}, 且在实验组与对照组的缺失机制相同,即 P{Ri(1)│Yi(1)=y,Di(1)=d}= P{Ri(0)│Yi(0)=y,Di(0)=d}. 假设1说明本文研究的样本是随机的,Angrist等[11]的研究以及Imbens等[12]的研究均采用了该假设.假设2说明分组Z与个体的潜在结果无关.假设3说明反对者(Ui=d)不存在.假设4是对Ui=n和Ui=a的个体进行了额外的限制,即Ui=n和Ui=a的个体中,分组Z对因变量Y没有产生影响.Angrist等[11]于1996年的研究中采用了假设4.假设5比假设4的条件更严谨,除了具有与假设4相同的含义外,假设5还意味着P{Ri(1)|Zi=1,Ui=n}=P{Ri(0)|Zi=0,Ui=n},P{Ri(1)|Zi=1,Ui=a}=P{Ri(0)|Zi=0,Ui=a},Chen等[4]于2009年的研究中也采用了该假设.假设6因变量Y的缺失不仅可以与Y自身相关,也可以与D相关,且实验组与对照组中的缺失机制相同. 本文采用联合似然函数的方法,并基于logistic模型进行建模,得到的联合似然函数如下: Di(0)}]Zi Ri(1)[P{(1-Zi)Ri(0)=1,Yi(1), 1,y(1),Di(1)>Di(0)}dy(1)]Zi(1-Ri(1)) Di(0)}dy(0)](1-Zi)(1-Ri(1)) (1) 在不可忽略缺失机制下,似然函数(1)的可识别性问题引起了广泛的关注.等式(1)的可识别性转化为[P{ZR(1)=1,Yi(1),D(1)>D(0)}]Z与[P{(1-Z)R(0)=1,Y(0),D(1)>D(0)}]1-Z两者的乘积可识别即可[10].本文将它们的乘积记为Q,并对其进行整理可得: Q=[P{R(1)=1,Y(1),D(1)>D(0)}]Z× [P{R(0)=1,Y(1),D(1)>D(0)}]1-Z= [P{R(1)=1,Y(1),D(1)=1,Z=1}- P{R(0)=1,Y(0),D(0)=1,Z=0}]Z [P{R(0)=1,Y(0),D(0)=0,Z=0}- P{R(1)=1,Y(1),D(1)=0,Z=1}]1-Z (2) 等式(2)的成立依赖于先前的5个基本假设条件,它的存在使得CACE可以依据观测的数据进行计算,该等式的具体证明参见附录一. 对等式(2)进行参数化建模,记 P(Z=1)=π,P(D=1│Z=1)=ν, P(D=1│Z=0)=η. 这里假定上述的三个概率已知,并记 P(R(z)=1│Y(z)=y(z),D(z)=d,Z=z)= F(αy(z)+θ0+θ1d), P(Y(1)│D(1)=d,Z=1)={F(β0+ β1d)}Y(1){1-F(β0+β1d)}1-Y(1), P(Y(0)│D(0)=d,Z=0)={F(γ0+ γ1d)}Y(0){1-F(γ0+γ1d)}1-Y(0). 其中,F(x)=expit(x)=exp(x)/exp(1+x).这里假定β1,γ1>0, 这是由于本文假定分组Z与治疗D对因变量都有正效应.通过以上记号,等式(2)可以转化为 Q(α,β,γ,θ,π,ν,η)={F(αy(1)+θ0+θ1)· {F(β0+β1)}Y(1){1-F(β0+β1)}1-Y(1)·ν· π-F(αy(0)+θ0+θ1)·{F(γ0+γ1)}Y(0) {1-F(γ0+γ1)}1-Y(0)·η·(1-π}Z· {F(αy(0)+θ0)·{F(γ0)}Y(0)· {1-F(γ0)}1-Y(0)·(1-η)·(1-π)- F(αy(1)+θ0)·{F(β0)}Y(1)· {1-F(β0)}1-Y(1)·(1-ν)·π}1-Z (3) 此时,等式(1)中的参数可识别可以转化为Q(α,β,γ,θ,π,ν,η)中的参数可识别.因此,证明等式(1)中的参数可识别,则只需证明:若Q(α,β,γ,θ,π,ν,η)=Q(α*,β*,γ*,θ*,π,ν,η),则α=α*,β=β*,γ=γ*,θ=θ*即可. 定理1假设因变量是二分类的,且不存在协变量的情况下,基于logistic模型,使用联合似然的方法,可以证明得到的结论是:模型中的参数是不可识别的. 定理1的详细证明参见附录二. 基于似然函数的方法在没有个体其他信息(协变量),如身高、血压等协变量的前提下,模型是不可识别的.因此,本文采用文献[4]中的估计方法进行模拟,具体计算方法可参见附录三.参考文献[4]中的符号设计,令θyzu=P(Y=y|Z=z,U=u),ρy=P(R=1|Y=y),则CACE=θ11c-θ10c.在本次模拟中,采用的样本量为500,重复1 000次.其中,个体随机分配到实验组的概率为0.5,且个体永远放弃治疗的概率是0.3,永远接受治疗的概率是0.2,依从者的概率是0.5.当Y=0时,其缺失的概率设定为0.7;当Y=1时,其缺失的概率设定为0.8.由于假设4的存在,有θ10a=θ11a,θ11n=θ10n.通过矩的估计方法,计算了感兴趣参数的偏差、标准差、置信区间,以及覆盖率,详细结果见表1. 表1 CACE值模拟表 本文首先介绍了基于 Frangakis等[1]提出的“主分层”框架得到的CACE,并通过提出的6个基本假设条件,使得CACE可以依据观测的数据进行估计.其次,在不存在协变量的前提下,基于Logistic模型,使用联合似然的方法对CACE进行参数建模,得到的结论是:模型中的参数是不可识别的.最后,采用Chen等[4]文章中的估计方法对CACE 涉及到的感兴趣的参数进行了模拟,计算了它们的偏差、标准差、置信区间,以及覆盖率. 附录一 等式(2)的证明与 Chen等[4]附录中的证明类似,主要为了说明5个基本假设条件在CACE的可识别问题上分别起到的具体作用.已知 Q=[P{Ri(1)=1,Yi(1),Di(1)>Di(0)}]Zi[P{Ri(0)=1,Yi(0),Di(1)>Di(0)}]1-Zi= [P{Ri(1)=1,Yi(1),Di(1)=1,Zi=1}-P{Ri(1)=1,Yi(1),Di(0)=1,Zi=1}]Zi· [P{Ri(0)=1,Yi(0),Di(0)=0,Zi=0}-P{Ri(0)=1,Yi(0),Di(1)=0,Zi=0}]1-Zi. 这一步利用假设3,即P{Di(1)≥Di(0)}=1,有Di(0)=1等价于Di(0)=Di(1)=1,以及有Di(1)=0等价于Di(1)=Di(0)=0.接下来证明P{Ri(1)=1,Yi(1),Di(0)=1,Zi=1}=P{Ri(0)=1,Yi(0),Di(0)=1|Z=0}·P(Z=1).容易得到 P{Ri(1)=1,Yi(1)=y,Di(0)=1,Zi=1}= P{Yi(1)=y,Di(0)=1,Zi=1}·P{Ri(1)=1|Yi(1)=y,Di(0)=1,Zi=1}= P{Yi(1)=y,Di(0)=1,Zi=1}·P{Ri(0)=1|Yi(0)=y,Di(0)=1,Z=0}, 其中,上式中的第二个等号成立依赖于假设5.而 P{Yi(1)=y,Di(0)=1,Zi=1}=P{Yi(1)=y,U=a,Zi=1}= P{Yi(1)=y|U=a,Zi=1}·P{U=a|Zi=1}·P{Zi=1}= P{Yi(1)=y|U=a,Zi=1}·P{U=a|Zi=0}·P{Zi=1}= P{Yi(0)=y|U=a,Zi=0}·P{U=a|Zi=0}·P{Zi=1}= P{Yi(0)=y,U=a|Zi=0}·P{Zi=1}, 其中,上式中的第一个等号成立依赖于假设3,第三个等号成立依赖于假设2,第四个等号成立依赖于假设4.所以,P{Ri(1)=1,Yi(1)=y,Di(0)=1,Zi=1}=P{Ri(0)=1,Yi(0)=y,Di(0)=1|Z=0}·P(Z=1)成立,同理可得,P{Ri(0)=1,Yi(0)=y,Di(1)=0,Zi=0}=P{Ri(1)=1,Yi(1)=y,Di(1)=0|Z=1}·P(Z=0).等式(2)成立. 附录二 基于等式(3),令Q(α,β,γ,θ,π,ν,η)=Q(α*,β*,γ*,θ*,π,ν,η).当Z=0时,通过整理可以得到如下两个等式: (1-π)·(1-η)·F(θ0)·{1-F(γ0)}-(1-π)·(1-ν)·F(θ0)·{1-F(β0)}= (4) (1-π)·(1-η)·F(α+θ0)·F(γ0)-(1-π)·(1-ν)·F(α+θ0)·F(β0)= (5) 当Z=1时,通过整理亦可以得到如下两个等式: π·ν·F(θ0+θ1)·{1-F(β0+β1)}-π·η·F(θ0+θ1)·{1-F(γ0+γ1)}= (6) π·ν·F(α+θ0+θ1)·F(β0+β1)-π·η·F(α+θ0+θ1)·F(γ0+γ1)= (7) (8) (9) 附录三 (1)如果P(Y=1|Z=1,U=n)≠P(Y=1|Z=1,U=a)(i.e.,11n≠10a),那么 (2)如果P(Y=1|Z=1,U=n)=P(Y=1|Z=1,U=a)(i.e.,11n=10a),且P(Y=1|Z=1,U=c)≠P(Y=1|Z=0,U=c)(i.e.,11c≠10c),那么 (3)如果P(Y=1|Z=1,U=n)=P(Y=1|Z=1,U=a)(i.e.,11n=10a),且P(Y=1|Z=1,U=c)=P(Y=1|Z=0,U=c)(i.e.,11c=10c),那么1.2 基本假设条件
2 联合似然函数及模型的可识别性
3 估计与模拟

4 结 论