一种差分隐私K-means聚类算法的隐私预算分配方案
2020-12-15黄保华程琪袁鸿黄丕荣
黄保华 程琪 袁鸿 黄丕荣


摘 要:差分隐私K-means聚类算法因其能很好地兼顾数据可用性和数据隐私安全,而得到了广泛地关注和研究。目前,在许多对差分隐私K-means聚类算法的研究中,都从K-means聚类算法的初始中心点的选择上做改进来提高数据的可用性,而很少关注隐私预算的分配问题对聚类结果带来的影响。传统的隐私预算分配方法可能在K-means算法后期的迭代更新质心的过程中引入大量的噪声而造成数据聚类效果差的问题。为了解决这个问题,提出一种结合三分法和等差数列的隐私预算分配方案。该方法在差分隐私K-means聚类算法中,保证每次迭代更新质心的过程中引入的噪声不会引起质心变形,且前期使用三分法分配较大的预算,而在后期使用等差递减的方式,分配隐私预算使隐私预算能在设定的迭代次数中用尽。实验证明,该方法在相同条件下能提高差分隐私K-means聚类算法的可用性。
关键词:差分隐私;K-means聚类;隐私预算;隐私保护;数据挖掘
中图分类号: TP391 文献标识码:A
Abstract: Differential privacy K-means clustering algorithm has received extensive attention and research because it can balance data availability and data privacy security. At present, in many researches on the differential privacy K-means clustering algorithm, the improvement is made from the selection of the initial center point of the K-means clustering algorithm to improve the availability of data, but little attention is paid to the impact of the distribution of privacy budget on the clustering results. The traditional privacy budget allocation method may introduce a lot of noise in the later iteration of K-means algorithm, resulting in poor clustering effect. In order to solve this problem, a privacy budget allocation scheme is proposed, which combines the trisection method and the equal difference sequence. In the K-means clustering algorithm of differential privacy, this method ensures that the noise introduced in the process of updating the centroid of each iteration will not cause the deformation of the centroid. In the early stage, the three-dimensional method is used to allocate a larger budget, while in the later stage, the equal difference decreasing method is used to allocate the privacy budget so that the privacy budget can be exhausted in the set number of iterations. Experiments show that this method can improve the availability of differential privacy K-means clustering algorithm under the same conditions.
Key words: differential privacy; K-means clustering; privacy budget; privacy protection; data mining
1 引言
在大數据时代,数据挖掘成为备受人们关注的热点,K-means聚类算法作为一种简便易用的数据挖掘[1]技术,受到了广泛地关注。然而,K-means聚类算法需要不断更新质心,使用K-means聚类算法可能会泄露数据拥有者的隐私。因此,很多学者将信息保护技术引入到K-means聚类算法中来。由于差分隐私具备一些传统信息保护技术(k-匿名[2]、干扰[3])没有的特质,如能抵御背景知识[4]攻击和一致性[5]攻击等,差分隐私结合K-means聚类算法成为研究的热门。
众多学者对差分隐私K-means(DPK-means)聚类算法进行了研究。Blum等人[6]在2005年首次提出了差分隐私K-means算法,并部署在SuLQ平台将其实现。但是,该方法存在查询函数敏感、聚类效果不佳等问题。Nissim等人[7]从DPK-means算法的初始中心点选择上进行优化,在一定程度上提升了聚类效果。李杨等人[8]将原始数据集分成k个子集,再从子集中选择中心点进行聚类,增强了数据的可用性。Yu等人[9]考虑了数据集中异常值的影响,采用计算数据点密度的方法剔除异常值再进行DPK-means聚类。Ren等人[10]通过重复执行DPK-means算法得到优质的初始中心点来提升聚类效果。许多研究都从DPK-means算法的初始中心点选取上改进来提升聚类效果,但是隐私预算是否合理分配也对聚类结果有着重要的影响。Dwork[11]在文献[6]的基础上,对DPK-means算法进行了详尽地分析,并提出了两种差分隐私预算因子的分配方式。Su等人[12]在对差分隐私聚类算法的研究中,使用均方差的方法,得到了聚类算法每次迭代需要分配隐私预算的最小值,保证质心不会因为加入噪声而变形。Fan等人[13]利用DPK-means算法中隐私预算分配的最小值,提出了一个等差递减序列作为隐私预算分配序列,保证质心不会因为噪声加入而变形。但通过观察,在DPK-means算法的前期迭代中,分配到的隐私预算并不太大,会一定程度影响算法前期迭代的效果。
为了解决DPK-means聚类算法中隐私预算的分配方法不好而导致聚类效果不佳的问题,提出一种新的DPK-means隐私预算分配方案。该方案在DPK-means聚类算法中,先给每一次迭代分配需要的最小隐私预算值,保证每次迭代质心不变形;在剩余的预算中,前期迭代使用三分法分配隐私预算,使得前期的迭代更新能更快地收敛;在后期使用等差数列方法分配,使隐私预算能在设定的迭代次数中用尽。实验证明,该方案能在一定程度上提高聚类效果。
2 相关定义与理论基础
2.1 差分隐私
差分隐私[14~17]是针对统计数据库中可能造成隐私信息泄露[18]而提出一种隐私模型。差分隐私模型并不会使数据完全加密,而是通过在敏感数据加入符合某种特定分布的噪声,使数据在一定程度上失真但却不丢失数据的某些统计特性。在差分隐私模型的模型中,对统计数据集的查询结果不会因为其中一条数据的增加或删除发生明显的变化,因此即使在最大化攻击者背景知识的情况下,攻击者也无法根据已知信息推断出数据集中的敏感信息。
定义1[14] 假设有随机算法M,Pm是算法M所有的可能输出的值的集合。对于任意的数据集D和D'(D和D'之间最多只相差一条信息),Sm为Pm的任意子集,如果算法M满足:
其中,Lap(△f/ε)为服从参数为△f/ε的拉普拉斯分布的噪声,ε的值越小,其概率密度越平均,数据所添加的噪声量就越大,对数据的隐私保护更强。
2.2 DPK-means聚类算法
在K-means聚类算法中,更新质心的过程有可能会造成隐私泄露。在更新一个簇的质心时,需要用簇中点的坐标和除以数据的个数,这等效于在数据集中查询计数,如果直接发布更新的质心,攻击者则可以通过背景知识来获取数据集中的信息。
DPK-means聚类算法通过引入噪声的方法解决K-means算法中存在的隐私安全问题。通过在更新簇质点时,向簇中的数据点的坐标和和数据点个数加入一定量的噪声达到隐私保护目的。差分隐私DPK-means聚类算法步骤分为四步。
(1)从待聚类的数据集中随机选取k个点作为初始中心点。
(2)计算数据集中的点与k个中心点的欧氏距离,并将数据点归类到距离最近的初始中心点的簇中。
(3)计算每一个簇中数据点到中心点的距离之和sum,并计算簇中的数据点个数num,分别向sum和num添加满足Lap(△f/ε)分布的拉普拉斯噪声得到sum和num,然后更新簇的中心点sum/num。
(4)重复步骤(2)和(3)直到误差平方和不再发生变化或者迭代次数达到上限。
3 差分隐私预算分配方案
在差分隐私K-means算法中,寻找k个中心点相当于在空间[0,1]d上进行直方图查询[19],删除或增加一个空间中的点最多影响一个簇中的坐标和,这个坐标最多只能在d维空间中的每一维改变1,总的灵敏度改变d,对于计算数据点的个数,灵敏度的改变为1,因此总的灵敏度为d+1。在基于拉普拉斯机制的DPK-means算法中,加入的噪声为Lap(d+1/ε)。如何避免ε过早用尽以及如何控制引入噪声量的大小也是影响算法聚类效果的重要因素。
Dwork[11]针对DPK-means的隐私预算问题提出了两种方法:(1)当迭代的次数N确定时,每次迭代加入的噪声为Lap((d+1)N/ε);(2)当迭代的次数不确定时,采用二分法,即每次迭代时使用当前剩余预算的一半,如第一次为Lap(2(d+1)N/ε),第二次为Lap(4(d+1)N/ε)。文献[12]通过计算原始K-means算法中质心与DPK-means算法中质心的均方差,得到了一个数据集在差分隐私聚类算法中每一次迭代需要的隐私预算的最小值:
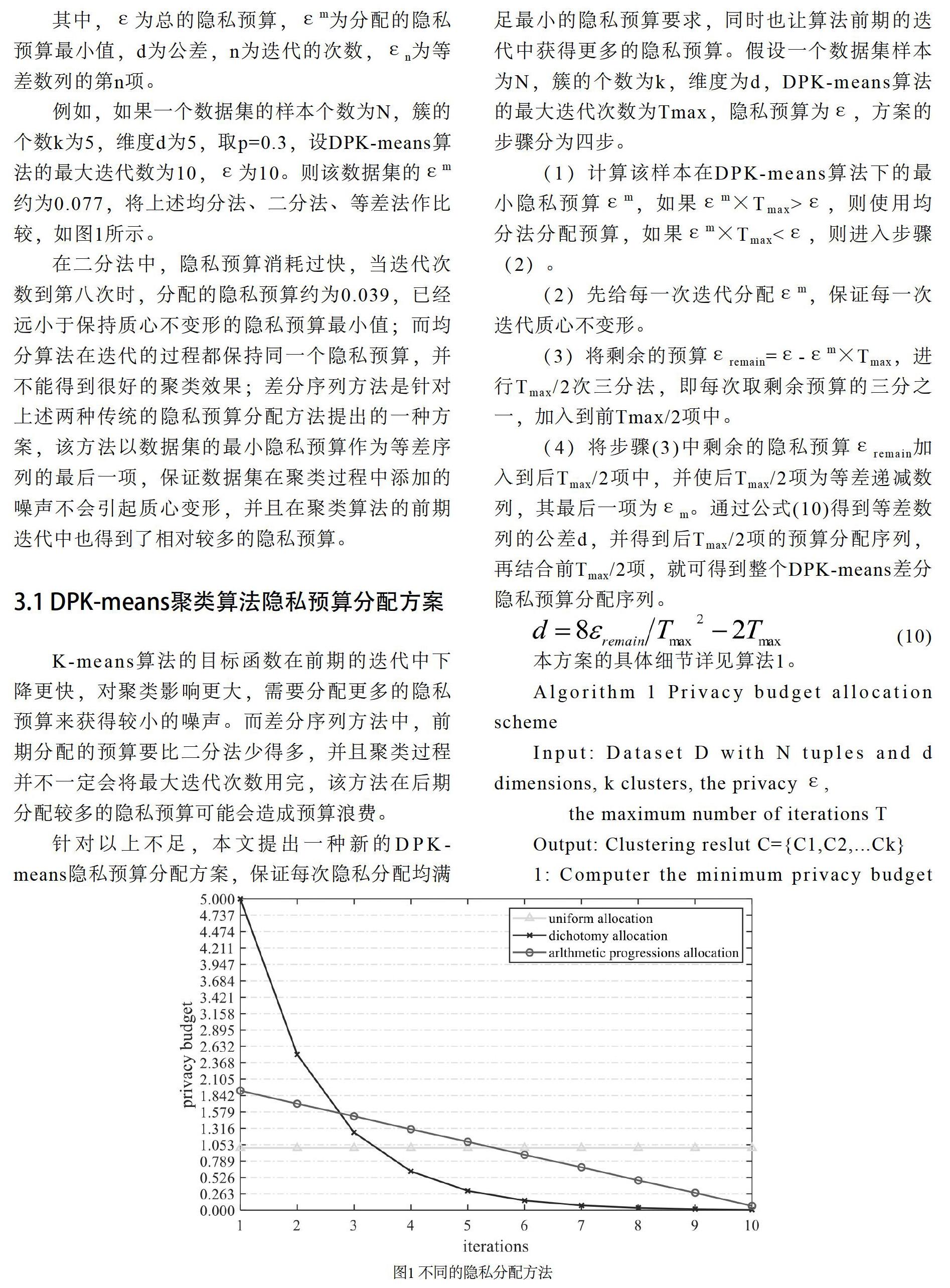
例如,如果一个数据集的样本个数为N,簇的个数k为5,维度d为5,取p=0.3,设DPK-means算法的最大迭代数为10,ε为10。则该数据集的εm约为0.077,将上述均分法、二分法、等差法作比较,如图1所示。
在二分法中,隐私预算消耗过快,当迭代次数到第八次时,分配的隐私预算约为0.039,已经远小于保持质心不变形的隐私预算最小值;而均分算法在迭代的过程都保持同一个隐私预算,并不能得到很好的聚类效果;差分序列方法是针对上述两种传统的隐私预算分配方法提出的一种方案,该方法以數据集的最小隐私预算作为等差序列的最后一项,保证数据集在聚类过程中添加的噪声不会引起质心变形,并且在聚类算法的前期迭代中也得到了相对较多的隐私预算。
3.1 DPK-means聚类算法隐私预算分配方案
K-means算法的目标函数在前期的迭代中下降更快,对聚类影响更大,需要分配更多的隐私预算来获得较小的噪声。而差分序列方法中,前期分配的预算要比二分法少得多,并且聚类过程并不一定会将最大迭代次数用完,该方法在后期分配较多的隐私预算可能会造成预算浪费。
针对以上不足,本文提出一种新的DPK-means隐私预算分配方案,保证每次隐私分配均满足最小的隐私预算要求,同时也让算法前期的迭代中获得更多的隐私预算。假设一个数据集样本为N,簇的个数为k,维度为d,DPK-means算法的最大迭代次数为Tmax,隐私预算为ε,方案的步骤分为四步。
(1)计算该样本在DPK-means算法下的最小隐私预算εm,如果εm×Tmax>ε,则使用均分法分配预算,如果εm×Tmax<ε,则进入步骤(2)。
(2)先给每一次迭代分配εm,保证每一次迭代质心不变形。
(3)将剩余的预算εremain=ε-εm×Tmax,进行Tmax/2次三分法,即每次取剩余预算的三分之一,加入到前Tmax/2项中。
(4)将步骤(3)中剩余的隐私预算εremain加入到后Tmax/2项中,并使后Tmax/2项为等差递减数列,其最后一项为εm。通过公式(10)得到等差数列的公差d,并得到后Tmax/2项的预算分配序列,再结合前Tmax/2项,就可得到整个DPK-means差分隐私预算分配序列。
本方案的具体细节详见算法1。
Algorithm 1 Privacy budget allocation scheme
Input: Dataset D with N tuples and d dimensions, k clusters, the privacy ε,
the maximum number of iterations T
Output: Clustering reslut C={C1,C2,...Ck}
1: Computer the minimum privacy budget εm with(6);
2: if ε≤T×εm then
3: privacy budget of each iteration ← ε/T;
4: else
5: εrem=ε-T×εm ;
6: for i=1 to T/2 do
7: εi=1/3×εrem+εm;
8: εrem= εrem-1/3×εrem;
9: end for
10: Computer d with (10);
11: for j =1 to T/2 do
12: εT+1-j=εm+(j-1)×d;
13: end for
14: sequence ε ={ε1,ε2,...εT}
15: end if
16: Ramdomly select k points from D;
17: t=0;
18: while The SSE not converges and t 19: t=t+1; 20: for i=1 to N do 21: Computer distance dij between xi and uj(1≤j≤k); 22: Put xi to the nearest cluster Cj(1≤j≤k); 23: end for 24: for j=1 to k do 25: sum=∑x∈Cjx; 26: num=|Cj|; 27: sum'=sum+Lap((d+1)/ε); 28: num'=num+lap((d+1)/ε); 29: uj'=sum'/num'; 30: if uj'≠uj then 31: uj=uj'; 32: else 33: keep uj unchange; 34: end if 35: end for 36: end while 本文再使用上述的例子來观察本方案和等差序列方法,如图2所示。Jain等人[20]对大数据进行K-means聚类指出,K-means算法中给定的迭代次数的设置要随着数据的增大,数据维度的增加而增加。因此,通过对图2示例的数据维度增加1倍,迭代次数也相应增加1倍,再计算隐私预算分配序列,如图3所示。 对比图2和图3的隐私分配曲线,可以看出,随着迭代次数的增加,等差序列方法的曲线会逐渐趋于平缓,而本文的方法在多维度大数据中,前期依然能提高较大的隐私预算而后期保证满足数据隐私预算的最小值。 3.2 安全性分析 假设有数据集D1和D2,它们最多只相差一条数据,M(D1)和M(D2)表示使用本文算法的两个输出结果,S表示任意一种划分聚类。假设算法满足ε-差分隐私,则: 4 实验及分析 本文实验中,使用Python来做本文算法与二分法的DPK-means和等差数列法的DPK-means做比较。实验环境CPU:Intel(R) Core(TM) i5-4200U 1.60GHz;RAM:10.0GB;操作系统:Windows 10。实验的数据样本来UCI Machine Learning Repository(http://archive.ics.uci.edu/ml/index.php),数据集信息如表1所示。 4.1实验评价标准 4.2 实验结果与分析 本文对三个已有分类标签的数据集分别运行二分法、等差法以及本文方案的DPK-means算法。首先对数据集D1-D3作数据预处理,使数据集每一维的值标准化为[0,1],并且算出每一个数据集的最小隐私预算值,然后选择合适的ε值,并逐步调高ε,进行三组算法的实验对比,观察不同算法的F-measure值,结果如图4~6所示。 通過实验发现,随着隐私预算ε的提高,F-measure值逐渐增大。通过分析发现:(1)随着数据集的样本数和属性数的增大,二分法的聚类效果与另外两种方法的差距越来越大,本文方法也在一定程度上优于差分法;(2)在数据集样本数和属性数越来越多的情况下,本文方法聚类效果均比差分法聚类效果好,主要的原因是在数据样本和维数增加的情况下,最大的迭代次数也要相应的增大,差分法分配的预算曲线会趋于平缓,导致DPK-means算法前期得到的隐私预算不多,而后期可能造成隐私预算浪费。 因此,本文的方法与其他两种方法相比具有更好的可用性和聚类效果。 5 结束语 为解决DPK-means聚类算法中隐私预算的分配方法不好而导致聚类效果不佳的问题,提出一种新的DPK-means隐私预算分配方案。该方案在DPK-means聚类算法中,先给每一次迭代分配不会引起质心变形的最小隐私预算值;在剩余的预算中,前期迭代使用三分法分配隐私预算,使得前期的迭代更新能更快地收敛;在后期使用等差数列方法分配,使隐私预算能在设定的迭代次数中用尽。实验证明,该方案能在一定程度上提高聚类效果。在未来的工作中,希望从DPK-means聚类算法的初始中心点选择上进行研究,进一步提高本方案的聚类效果。 基金项目: 国家自然科学基金项目(项目编号:61962005)。 参考文献 [1] Hand D J, Adams N M. Data Mining[J]. Wiley StatsRef: Statistics Reference Online, 2014: 1-7. [2] Sweeney. k-anonymity: a model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(05):557-570. [3] Lindell Y, Pinkas B. Privacy Preserving Data Mining[C]// Proceedings of the 20th Annual International Cryptology Conference on Advances in Cryptology. Springer, Berlin, Heidelberg, 2000. [4] Machanavajjhala A, Kifer D, Gehrke J, et al. L-diversity: Privacy beyond kanonymity[J].ACM Transactions on Knowledge Discovery from Data, 2006, 1(1):3. [5] Ganta S R, Kasiviswanathan S P, Smith A. Composition attacks and auxiliary information in data privacy[C]//Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 2008: 265-273. [6] Blum A, Dwork C, McSherry F, et al. Practical privacy: the SuLQ framework[C]//Proceedings of the twenty-fourth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. 2005: 128-138. [7] Nissim K, Raskhodnikova S, Smith A. Smooth sensitivity and sampling in private data analysis[C]//Proceedings of the thirty-ninth annual ACM symposium on Theory of computing. 2007: 75-84. [8] 李杨,郝志峰,温雯,等.差分隐私保护K-means聚类方法研究[J].计算机科学, 2013(03):293-296. [9] Yu Q, Luo Y, Chen C, et al. Outlier-eliminated k-means clustering algorithm based on differential privacy preservation[J]. Applied Intelligence, 2016, 45(4): 1179-1191. [10] Ren J, Xiong J, Yao Z, et al. DPLK-means: A novel Differential Privacy K-means Mechanism[C]//2017 IEEE Second International Conference on Data Science in Cyberspace (DSC). IEEE, 2017: 133-139. [11] Dwork C. A firm foundation for private data analysis[J]. Communications of the ACM, 2011, 54(1): 86-95. [12] Su D, Cao J, Li N, et al. Differentially private k-means clustering[C]//Proceedings of the sixth ACM conference on data and application security and privacy. 2016: 26-37. [13] Fan Z, Xu X. Apdpk-means: A new differential privacy clustering algorithm based on arithmetic progression privacy budget allocation[C]//2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). IEEE, 2019: 1737-1742. [14] DWORK C. Differential privacy[C]//Proceedings of the 33rd International Conference on Automata,Languages and Programming-Volume Part II.Springer,Berlin,Heidelberg,2006:1-19. [15] Dwork C. Differential privacy: A survey of results[C]//International conference on theory and applications of models of computation. Springer, Berlin, Heidelberg, 2008: 1-19. [16] Dwork C. The differential privacy frontier[C]//Theory of Cryptography Conference. Springer, Berlin, Heidelberg, 2009: 496-502. [17] Dwork C. Differential privacy in new settings[C]//Proceedings of the twenty-first annual ACM-SIAM symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, 2010: 174-183. [18] DALENIUS T. Towards a methodology for statistical disclosure control[J].Statistik Tidskrift,1977,15(2):429-444. [19] VISWANATH P. Histogranm-based Estimation Techniques in Databases[D].Madison: University of Wisconsirr-Madison, 1997. [20] Jain, Mugdha, Verma, Chakradhar. Adapting k-means for Clustering in Big Data[J].International Journal of Computer Applications, 2014, 101(1):19-24.
