基于量子遗传算法和模糊C均值聚类的图像分割
2020-12-10游继安
刘 衣,游继安
(湖北工程学院 新技术学院,湖北 孝感 432100)
图像分割在不同的领域有着非常重要的作用,如医学图像分割是在医疗物联网领域中自动或半自动化对2D或3D图像进行边界检测的一个重要过程[1]。模糊C均值(fuzzy C means,FCM)聚类方法已被证明是一个很有效的图像分割的方法[2],但是它的鲁棒性较差,而且对噪声图片的分割会很敏感,准确性降低[3]。量子遗传算法(quantum genetic algorithm,QGA)是韩国人Kuk-Hyun Han最先提出的,它的收敛速度比普通的遗传算法等要快很多,而且由于量子计算的特征,不容易陷入局部最优解的困境[4]。
本文利用量子遗传算法计算模糊C均值聚类中心,然后得到图像每个像素点对应聚类中心的隶属度,达到分割的效果。在计算聚类中心时,首先需要选择随机样本。传统的随机样本选择范围图像中的所有像素点,随机在图像中选择一个像素点,得到其灰度值,将其作为某个聚类中心的样本。但是,不同大小的图片,像素点个数范围变化非常大,对量子遗传算法中需要使用的种群规模(染色体个数)、染色体上每个基因的长度,以及进化的代数,都有着不确定性。如果图像比较小,而种群规模或者基因长度过大,则会造成计算冗余,实际测试过程中,发现长时间都无法得到计算结果;如果图像较大,而种群规模或基因长度相对较小,需要计算的进化代数就必须增加,搜寻的范围大了,就很难快速找到最优值。对于此问题,本文将图像的所有像素点的灰度值变化范围作为寻找聚类中心的样本空间,可以解决图像大小不确定的问题,因为任意像素点灰度值变化的最大范围是0到255,而图像像素点灰度值变化值不超过255,这样,就可以使用固定的种群数量、基因长度和进化代数来计算,使得算法有很好的鲁棒性。
本文利用C++语言和Open CV工具,在Win10系统上使用VS2017进行编程测试,实验结果表明本文方法是有效的。
1 QGA简介
量子叠加态是QGA的基础,一个量子比特的叠加态ψ可以有公式(1)表示:
ψ〉=α0〉+β1〉
(1)
式中:α表示偏向0态的概率,β表示偏向1态的概率,α和β之间有公式(2)的关系:

(2)
QGA的最小单元是一个量子比特,可以用如下向量的形式表示:
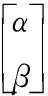
(3)
若一个基因由k个量子比特组成,而一个染色体又由m个基因组成,则一个染色体用矩阵可表示为公式(4)的形式:
(4)
量子的一大特点就是一旦观测后,每个由α和β构成的量子比特叠加态就立刻随机变成0态或者1态。所以一旦观测后,基因就变成了二进制形式,最小单位为1个bit,只能取0或1。那么公式(4)代表的染色体的长度(比特总量)就应该为k*m。
QGA的步骤如下:

Step 2 测量并存储坍塌后的二进制数,将其按照样本范围转换为十进制的值;
Step 3 将得到的样本值带入适应度方程中计算适应度的值;
Step 4 筛选最优个体,并将其数据作为下一代;
while (若当前进化代数t<总进化代数n) do
begin
Step 2~Step 3;
Step 5 所有染色体基因的所有量子比特经过量子旋转门更新α和β;
Step 6 筛选和存储最优个体,满足下一代必须优于或等于上一代;
end
算法运算结束后,最优个体的所有数据便知道了。
其中Step 5中提到的量子旋转门,是一个二维矩阵,如公式(5)所示:
(5)

(6)
进一步化简,可得公式(7):
(7)
旋转门中的旋转角θi是由偏转角度的绝对值和旋转方向共同决定的,具体关系如公式(8)所示,其中s(αi,βi)为旋转方向:
θi=Δθi·s(αi,βi)
(8)
公式(8)中的Δθi和s(αi,βi)可以根据旋转角选择策略确定,如表1所示。根据基因中某个位置xi、对应位置的最优值的bi、该染色体适应度是否优于最佳染色体适应度、αi和βi的值,查询对应的Δθi和s(αi,βi)的值,从而确定θi的值。

表1 旋转角选择策略
2 FCM算法简介
模糊C均值的聚类算法,其主要思路是先任意查找聚类中心,然后计算每个样本对所有聚类中心的隶属度值,再根据这个值来更新聚类中心,直到由聚类中心、隶属度和所有样本构成的目标函数与上一代相比,相差的绝对值小于某个值,就停止更新,得到最终的聚类中心和所有样本相对所有聚类中心的隶属度。
上述算法中提到的目标函数如公式(9)所示:
(9)
聚类中心Pj和样本隶属度uij之间的关系为公式(10)和公式(11)所示:
(10)
(11)
3 QGA和FCM聚类结合
3.1 算法结合意义
结合两个算法的目的是为了得到更好的聚类效果,将FCM聚类用于图像分割上,能较好地辨别聚类效果。所以,主要算法还是FCM聚类,QGA是用来优化聚类算法的。
3.2 算法结合原理
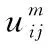
3.3 样本选取
传统的FCM图像分割算法通常将图像所有像素点的信息当作聚类中心的筛选范围,然后在这里面找聚类中心,单个像素点的信息包括x和y坐标值以及灰度值。对于以公式(9)为适应度函数的QGA,聚类中心筛选范围的选取也可以用这种方法。这种方式的优点是直观,容易理解,聚类中心就是某个像素点的信息。缺点是不同的图片大小不一,进而导致样本量不稳定,容易过大或过小,导致对于QGA算法,种群规模(染色体数)、基因长度和进化代数都不能设定为一个常量,算法的鲁棒性大大降低。对于大图片,在寻找聚类中心的过程中,样本量过大,计算量也过大。
本文提出将图像所有像素点的灰度值取值范围作为QGA求聚类中心的样本范围,样本则是范围里的所有灰度值。这样,对于任何图片,最大的样本范围也就是0到255,对于不同的图片,灰度值变化范围也接近与0到255。这种方法的缺点是样本点比较抽象,并不是某个具体像素点的信息,而是灰度范围内的任意灰度值,这种方法的优点特别突出,因为样本范围不会超过0到255的整数范围,所有样本个数最大也就是256,故采用QGA算法时,种群规模(染色体数)、基因长度和进化代数,可以设为比较小的固定值,计算量明显减小,经过测试,种群规模可设为9,每个基因的长度(二进制编码位数)可设为6,由于QGA算法的收敛速度非常快,所以最大进化代数设为9即可。
3.4 QGA-FCM图像分割

Step 2 计算图像所有像素点的灰度值变化范围[a,b],作为聚类中心筛选范围。
Step 3 测量并存储坍塌后的二进制数,将其按照[a,b]范围转换为十进制的值;

Step 5 更新每个像素点对所有聚类中心的隶属度uij(公式(10));
Step 6 利用公式(11)更新聚类中心Pj;
Step 7 根据Step 5和Step 6更新后的uij、Pj,和每个像素点灰度值xi灰度值,利用公式(9)计算适应度函数J。
Step 8 存储最小适应度对应的uij、Pj,以及Pj更新前的十进制和二进制的值;
Step 9 筛选最优个体,并将其数据作为下一代;
while (若当前进化代数t < 总进化代数n) do
begin
Step 3~Step 8;
Step 10 所有染色体基因的所有量子比特经过量子旋转门更新α和β;
Step 11 筛选和存储最优个体,满足下一代必须优于或等于上一代;
end
Step 12 将每个样本(像素点)的灰度值设为对最大聚类中心的隶属度。
经过上述步骤,图像就被分割了。
4 实验结果
将图像的聚类数目设为2,即将图像分割成2个部分,分割情况如图1所示。

图1 聚类数为2的对比图
若在算法中,不是以聚类中心的灰度值去设置像素点灰度值,而是对于隶属于不同聚类中心的像素点灰度值用0或255进行区别,那么,结果就如图2所示。

图2 二值化的两种算法对比图
