基于迁移的联合矩阵分解的协同过滤算法
2020-12-04陈珏伊朱颖琪崔兰兰伍少梅
陈珏伊, 朱颖琪, 周 刚, 崔兰兰, 伍少梅
(1.贵州电网有限责任公司贵阳供电局物流服务中心, 贵阳 550001; 2.贵州电网有限责任公司信息中心, 贵阳 550000;3.四川大学计算机学院, 成都 610065; 4.78123部队,成都 610017)
1 引 言
随着电子商务平台的不断发展,越来越多的电商平台(如淘宝、京东等)高度依赖在线的推荐系统,以增强用户的服务体验.协同过滤CF(Collaborative Filtering)是近年来最流行的推荐方法之一.它的基本思想是首先利用用户对商品的历史评分信息来度量用户之间的相似度,再通过搜索最相似用户的喜好来预测某个用户对商品感兴趣的程度,最后根据兴趣程度将商品进行排序后推荐给用户[1].但是随着电子商务系统的发展,用户和商品数目的急剧增加,整个商品项目空间上用户评分数据非常稀疏,即使活跃的用户,他们购买或评价的商品往往还不到整个项目集的1%.如果用户对商品项目的评价很少,那么用户之间选择商品的差异就很大,不同用户购买相同产品的情况就很少,那么用户之间由于商品选择的差异性会导致最近邻居的搜索不可靠,也就无法产生准确的推荐,这就是协同过滤推荐系统所遇到的数据稀疏性问题[2]. 为此,研究者们针对协同过滤算法提出了很多的改进工作,如文献[3]提出了基于粗糙集规则的方法提高性能;文献[4]利用LDA模型提升稀疏评分矩阵下的推荐性能;文献[5]提出使用矩阵分解解决稀疏问题;文献[6-7]将迁移学习的方法引入到协同过滤以此提高推荐性能.
将迁移学习引入到协同过滤研究的主要思想是通过目标领域和辅助领域的公共用户的信息来促进目标领域的学习.但是迁移学习的效果依赖于目标领域和辅助领域的共同用户,虽然两个领域的共同用户的商品数量很多,但是由于每个用户可能只在少部分商品上有历史行为,公共用户所购买的公共商品依然是稀疏的,通过用户的表面特征来度量用户相似性的性能也不好.同时,降维的方法,如矩阵分解,虽然也能在一定程度上缓解稀疏问题,但是过于稀疏的数据,实际应用中矩阵分解的效果不能满足要求.为了解决公共用户中商品数量多,相似度评估性能不好的问题,本文利用迁移学习思想,引入辅助领域的用户评分信息,提出对两个领域的用户评分矩阵进行联合矩阵分解,并将公共用户信息作为两个矩阵分解的约束项,通过联合分解来进一步提高协同过滤的性能,缓解数据稀疏问题.
2 相关工作
推荐系统中主要包括三类方法[8]:基于内容的推荐、协同过滤的推荐以及混合推荐[9-10].其中,协同过滤推荐算法是推荐系统中应用最广泛、最成功的个性化推荐技术之一.协同过滤的算法近年来引起了国内外的研究者广泛的关注[11-13].在推荐系统中,由于每个用户评分的商品项目数目有限,而随着电子商务的快速发展,商品项目的集合在不断增加,因而导致了用户-商品评分矩阵变得很大也很稀疏.协同过滤算法主要是依靠用户的历史评分信息,数据稀疏导致了搜索最近邻用户时相似度计算的误差很大,而过少的评分会导致覆盖率降低,从而导致推荐的精度严重降低[14].
为了解决推荐系统中数据稀疏问题,研究者们开展了很多的研究工作,其中主要包括三个方面的研究工作:填值方法[15-16]、降维方法[5,17-19]以及迁移学习方法[4,7,20-22].降维的方法主要是围绕对用户-项目评分矩阵进行降维处理,如基于规则的简单降维、主成分分析等技术来实现.矩阵分解是目前使用最为广泛的方法[17-18].矩阵分解主要利用了奇异值分解SVD(Singular Value Decomposition),但是SVD只能对稠密数据进行处理,因此在分解之前需要补全缺失值,太多的缺失值,导致在实际应用中的效果很差,同时矩阵分解的时间复杂度高,这些缺点制约了SVD 在协同过滤领域的发展.2006年,SimonFunk在Netflix 大赛上改进了SVD,并提出Funk-SVD,并在Netflix 上取得了优异的成绩.Funk-SVD是将评分矩阵分解成两个近似的低维矩阵相乘,Simon Funk的思想很简单:可以直接通过训练集中的观察值利用最小化均方根学习用户和商品的特征矩阵,这个模型也被称作 LFM (隐语义模型).这使得Funk-SVD和它的变体在协同过滤领域中得到了广泛的应用.文献[17]为了解决冷启动问题,针对现有研究中忽略项目之间关联关系的问题,提出将商品度量的关联和社会关系相结合的基于联合正则化矩阵分解的推荐模型.文献[18]为了解决稀疏问题,将用户之间的信任程度考虑到协同过滤中,提出了基于信任机制的概率矩阵分解的系统过滤算法.现有的基于矩阵分解的各种变体协同过滤算法虽然一定程度上缓解稀疏带来的问题,但是单一源领域严重的数据稀疏仍然制约矩阵分解方法的性能.
近年来,迁移学习逐渐被引入到推荐系统中,它主要是利用目标领域与辅助领域之间隐藏的潜在关系,将辅助领域的知识迁移到目标领域,以此来提高目标领域的推荐质量.文献[23]提出了基于用户相似度迁移以及用户特征迁移的协同过滤算法.文献[7]提出了一种综合相似度迁移模型,在度量目标域和辅助域用户的相似性时,通过使用用户评分信息和用户属性信息来提高目标领域的推荐性能.这些研究主要利用的是两个领域的共同覆盖的公共用户信息,而公共用户成为影响基于相似迁移的研究发展的关键.虽然引入辅助领域以后能够增加公共用户的数量,但是公共用户中共同评分的商品数目仍然面临稀疏问题,这导致这些基于相似度迁移的协同推荐算法性能不好.
综上所述,现有基于相似度量的迁移协同过滤研究忽略了辅助领域和目标领域中公共用户中包含公共商品数量少时,使用表面特征不能很好地捕捉用户的潜在特征以及相似性度量性能差的情况,本文提出了一种基于迁移的联合矩阵分解协同过滤模型,以公共用户为锚,将两个领域的用户和商品映射到一个潜在的语义空间,来解决用户相似度量不准确的问题,从而提高推荐的准确性.
3 基于迁移的联合矩阵分解协同过滤模型
现有的基于相似度的迁移学习协同推荐算法都是基于用户商品的浅层特征来计算相似性,而公共用户所包含的商品打分稀疏时,相似性度量的性能很差.因此,本文提出了在两个领域公共用户信息作为约束的情况下,两个领域的用户-商品评分矩阵进行联合分解的模型,如图1所示.
由图1可知,联合矩阵分解的过程是通过输入的两个领域的评分矩阵,将两个领域的公共用户信息作为约束项,对两个评分矩阵进行联合分解,最后分解得到目标领域的用户和商品潜在特征矩阵,并得到近似得分矩阵.
3.1 基于单领域的矩阵分解协同过滤模型
对于M个用户和N个商品,用户-商品的评分矩阵R∈RM×N,其中,Ri,j∈{1,2,3,4,5},表示第i个用户在第j个商品上评分.由于用户和商品数目巨大,R中很多值为空,因此R是一个稀疏矩阵.

图1 基于迁移的联合矩阵分解协同过滤算法Fig.1 The collaborative filtering algorithm based on transfer learning and joint matrix decomposition
由于传统的SVD需要对稠密矩阵进行分解,而用户-商品的评分矩阵往往是一个稀疏矩阵.为了解决传统SVD存在的问题,现有的协同过滤矩阵分解算法中使用的主要是LFM、bias SVD以及SVD++.本文选择bias SVD算法进行矩阵分解.通过bias SVD只需要分解两个矩阵:U∈Rf×M和V∈Rf×N,分别表示为分解得到的用户和项目的潜在特征矩阵.用户商品得分矩阵公式如式(1)所示.
(1)
其中,f表示隐特征维度,用户i对商品j的预测评分为
(2)
由于用户对物品的评价有些因素与用户的喜好无关,而只取决于用户或物品本身特性.因此,Bias SVD把这些独立于用户或独立于物品的因素称为偏置(Bias)部分.Bias SVD在用户的预测评分公式中加入了基准预测评分,如式(3)所示[24].
bij=μ+bi+bj
(3)
其中,μ表示全局评分的平均值;bi表示用户i的偏置向量,表示用户的属性因子;bj表示商品j的偏置向量,代表商品的属性因子.
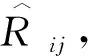
(4)
加入基准预测评分后的优化目标函数如式(5)所示.
(5)
其中,λ为正则化因子.最小化的过程即采用梯度下降法分别对Ui、Vj、bi和bj求偏导的过程.
3.2 基于联合矩阵分解模型



图2 算法描述Fig.2 Algorithm description
为了学习模型中的各个参数,可以最小化损失函数J(θ)实现这个目标.令J(θ1)是根据式(5)得到的辅助领域的损失函数,J(θ2)通过式(5)得到的目标域的损失函数,本文矩阵联合分解模型的损失函数如式(6)所示.
J(θ)=ω1J(θ1)+ω2J(θ2)+
(6)
其中,θ表示所有待优化的参数;θ1和θ2为辅助域和目标域损失函数中待优化的参数;ω1,ω2和ω3为超参数,模型的性能和这三个超参数是密切相关,而手工调优它们是非常困难且耗时耗力的事情.为此,借鉴文献[25]提出的思想,将两个单域的损失和约束项看成是三个回归任务的学习问题,考虑每个任务的同方差不确定性(homoscedastic uncertainty)来权衡各个任务的权重.ω1,ω2和ω3为各个任务中训练集的噪声水平.因此,联合分解过程中ω1,ω2和ω3参与优化.
综述所述,本文提出的方法如算法1所示.
算法1基于迁移的协同矩阵分解模型
输入:目标领域评分矩阵Rt,辅助领域评分矩阵Ra,模型参数epoch,λ,学习率,K

1) 通过Rt和Ra,计算两个领域的交叉用户信息,得到指示矩阵Ya和Yt;
2)ω1,ω2和ω3的优化过程及联合矩阵分解过程;
2-1) 初始化:ω1,ω2,ω3,Ut,Vt,Ua,Va输入为J(θ),
2-2) 随机梯度下降,优化函数梯度.
Repeat{
计算▽J(θ);
更新迭代公式:
}直到收敛,算法停止.
3) 计算目标领域的Rt的逼近评分矩阵
4 实验与结果
4.1 数据集
实验数据集采用GroupLens小组提供的被广泛应用在推荐系统的测评数据集MovieLens.该数据集包含了 943 位用户对 1 682 部电影的评分,总的评分条目超过 1×105条,用户评分包含 5 个等级(1~5),其中,1 为不喜欢,5 为非常喜欢,数值越高代表喜欢程度越高.
我们按照文献[7]的数据分组方法对数据集进行了划分,不同的数据组公共用户的数量不相同,包含的公共商品也不相同,数据分布如表1所示.

表1 五个数据集的分布
每个数据集将目标域的样例按照8∶2的比例划分为训练集和测试集.
4.2 评估指标
本文实验采用均方根误差(Root Mean Squared Error,RMSE)以及平均绝对误差(Mean Absolute Error,MAE)来评估模型的性能,如下式所示.
(7)
(8)
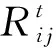
4.3 模型参数
我们的模型使用Xavier进行参数的初始化,Adam作为优化器,其它超参数如表2所示.在五组不同的数据组中,ω1,ω2和ω3的值,如表3所示.

表2 超参数设置
4.4 对比模型
为了验证基于迁移的联合矩阵分解协同过滤模型的有效性,本文选择了下面三个模型作为基线模型进行对比实验.(1) UCF 算法[26]:只能利用公共用户进行推荐;(2) TSUCF 算法[23]:基于传递相似性的交叉推荐算法,利用多个网站平台中用户的相似度来解决数据稀疏问题;(3) Jin2018[7]: 基于综合相似度迁移模型,在相似度计算上,利用公共用户评分信息同时也利用了用户属性信息,并且考虑了用户间对满意度的打分标准的差异性,采用了用户评分分布一致性来衡量用户评分相似度的方法.

表3 公式(6)的超参数
4.5 实验结果分析
首先我们分别验证了学习率和隐变量维数对模型性能的影响,如图3~图6所示.
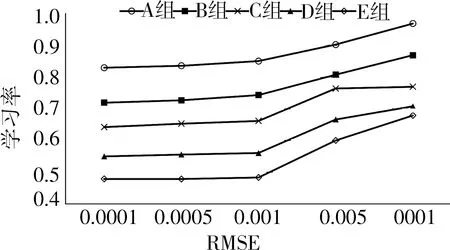
图3 不同学习率下RMSE的结果
从图3和图4可以看出,随着学习率的增加,RMSE和MAE的性能都在下降,特别是在学习率为0.01时,由于学习率过高,导致无法收敛.从两个图的性能比较中可以看出,学习率为0.000 5的模型性能相对较好.

图4 不同学习率下MAE的结果

图5 不同维数隐变量下的RMSE结果

图6 不同维数的隐变量下MAE的结果
从图5和图6中可以看出,随着隐变量K维数的增加,RMSE和MAE的性能都在提高.在维数为150时,MAE的性能有了降低.
我们使用表2和表3给出的模型超参数,训练模型,图7给出了在A组、B组、C组、D组以及E组五个数据集在训练过程中各个epoch下的RMSE和MAE的结果.





图7 不同Epoch下的RMSE和MAE的结果
从图7中可以看出,5个数据组的RMSE和MAE最开始处于欠拟合状态,随着迭代次数的增加,进入拟合状态.我们和基线模型进行了对比实验,结果如图8所示.

图8 和基线模型的对比结果
从图8可以看出,UCF模型的性能是最差的,因为只利用公共用户的信息进行推荐,没有考虑其他的信息.当公共用户数目增加时,UCF的性能才能有轻微的提高.而Jin2018和TSUCF都是利用浅层的表面特征来计算用户的相似性的,虽然比UCF性能更好,随着公共用户的增加,它们有一定的提升,但是提升的幅度不大,说明这种表层的特征不能很好地刻画用户的潜在特征.而我们的模型在A组数据集中,公共用户非常少的情况下,公共用户的公共商品也非常稀疏,我们的模型RMSE能够高于Jin2018模型4%,随着公共用户的增加,这些公共用户包含的公共商品数目也相应在增加,所以在B、C、D以及E组数据集中都获得了很好的结果,特别是在E组数据集上,我们模型的RMSE达到了0.48.结果说明捕捉了用户的潜在特征能够显著提高协同过滤的性能,也验证了模型的有效性.同时,随着公共用户数目的增加,商品稀疏性在减少,我们的模型能够从辅助领域学到更多的隐藏知识,因此,在E组的数据集下性能显著提高,并远远高于基线模型.
5 结 论
针对现有的基于迁移学习中利用辅助领域和目标领域之间公共用户的相似性度量进行协同过滤的研究,本文发现随着数据的增加,公共用户虽然多,但是包含的公共商品依然存在数据稀疏的问题,利用表层特征计算相似度的性能差.为此,本文提出利用公共用户信息作为矩阵分解的约束项,将辅助领域和目标领域的用户评分矩阵进行联合矩阵分解的协同过滤算法.和现有的研究进行了实验对比,本文提出的算法高于基线模型,随着公共用户中包含的公共商品数量的增加,我们模型的性能显著提高.实验结果也证明捕捉用户之间的潜在特征能更好地提高协同过滤的性能.
