结合YOLOv3模型的轨旁公里标识别方法
2020-11-30邱新华王文昆季育文
邱新华,王文昆,季育文,李 佳
(株洲时代电子技术有限公司,湖南 株洲 412007)
0 引言
里程编码器计数是目前常用的列车定位方式,利用里程编码器脉冲技术能获取精确到微米级的列车位置信息,但其存在里程累积误差。部分线路利用位置精确的轨道电路分界点或应答器进行位置校正来消除累积误差,但对于一些没有铺设应答器或者无法获取轨道电路分界点信息的线路,该方法则无法生效。目前国铁钢轨探伤车采用人工目视方法识别公里标,将公里标作为位置基准手动输入到系统进行里程累积误差校正,智能化程度低,且人工劳动强度大。文献[1]采用基于虚拟轨迹在单幅图像中识别公里标、百米标等轨旁标志进行定位校正,其主要利用灰度方差的水平和垂直投影波形来分割公里标,但易与其他轨旁标志混淆,且算法鲁棒性不高。文献[2]提出基于虚拟轨迹和支持向量机(support vector machine, SVM)的方法进行轨旁标志定位与识别,在利用灰度值方差定位的基础上引入矩形区域宽高比进行筛选,再用SVM分类器提取公里标,效果有一定的改善。但以上方法因过度依赖虚拟轨迹进行公里标定位、灰度阈值无法确定而导致算法鲁棒性差和识别率不高,无法适应公里标在虚拟轨迹范围外、背景复杂等情况。
近年来,多种基于深度学习的目标检测框架被提出,其中采用Two-stage模型的R-CNN(region CNN)系列算法先采用selective search算法从图像上提取2 000个候选框(region proposal),再归一化尺度,分别进行特征提取与分类回归,该方法占用空间且推理速度慢;Fast R-CNN算法[3]在整张图像上提取卷积神经网络(convolutional neural network, CNN)特征,把建议窗口映射到最后一层特征图上共享CNN运算结果,改善了检测效率;Faster R-CNN算法[4]先通过区域生成网络(region proposal network,RPN)产生候选框并将其缩小为原来的15%,再进行分类和边界回归,引入锚定(Anchors)机制能获取较高的检测精度和效率,但其检测速度无法满足公里标实时性较高的应用场合。文献[5]提出一种基于YOLOv2模型的交通标志检测算法,其识别率达到80.1%,比Fast R-CNN的高出5%;由于采用了One-stage模型,检测帧率达到40帧/s,但其检测精度无法满足系统应用要求。文献[6]提出的YOLOv3模型在YOLOv2模型的基础上进行了改进,其采用Darknet53为基础网络及类特征金字塔网络(feature pyramid networks, FPN)方式进行特征融合和多尺度预测,平均精确度(mean average precision,mAP)显著提高,但对一些大尺寸的物体,检测效果不理想。本文提出一种结合YOLOv3模型的公里标图像识别算法,其首先进行图像预处理,对经过卷积神经网络各层输出得到的图像特征进行特征融合,之后送入YOLO层进行回归分析,将置信度最大且大于预设阈值的区域视为公里标;在保证系统实时性的前提下,降低了背景误检率,能精确地分割出图像中公里标并准确识别数字信息,充分满足了系统对检测精度和速度的要求。
1 基于YOLOv3轨道公里标检测
列车高速运行中,摄像机相对公里标的距离和角度时刻在变化,因此公里标在图像中的位置波动很大。为准确识别出公里标的数字信息作为里程校正参考值,须先从原始图像中定位公里标区域,在此基础上再进行公里标字符提取和分割识别。由于列车运行速度快,相邻两帧图像之间的距离须尽可能短,经计算,相机采集帧率只有达到15帧/s以上才能防止公里标被漏拍情况的发生,因此需要保证公里标检测算法的实时性。
1.1 定位算法模型
公里标识别过程中,可能存在公里标在虚拟轨迹范围外、公里标部分被道砟覆盖、变旧变暗、背景复杂等情况。表1示出典型轨旁标识图像。
YOLOv3是目前检测速度与精度最均衡的目标检测网络模型之一,其应用多种先进技术补齐了YOLO和YOLOv2的全部短板,核心思想是将目标检测作为回归问题来解决,以真正实现端到端的目标检测,而采用多标签分类和跨尺度预测,则能更好地模拟数据。

表1 典型轨旁标识图像Tab. 1 Images of typical trackside identification
YOLO层检测流程如图1所示。

图1 YOLO层检测流程Fig.1 Flow chart of the YOLO layer detecttion
(1)将待检测图像划分S×S个网格(grid cell),每个网格一次性预测出B个中心落在该网格中的预测边界框bbox、类别以及定位置信度。边界框预测使用维度聚类(dimension clusters)作为anchors来预测[7]。网络为每个bbox预测 4个坐标(tx,ty,tw,th),如图2所示。
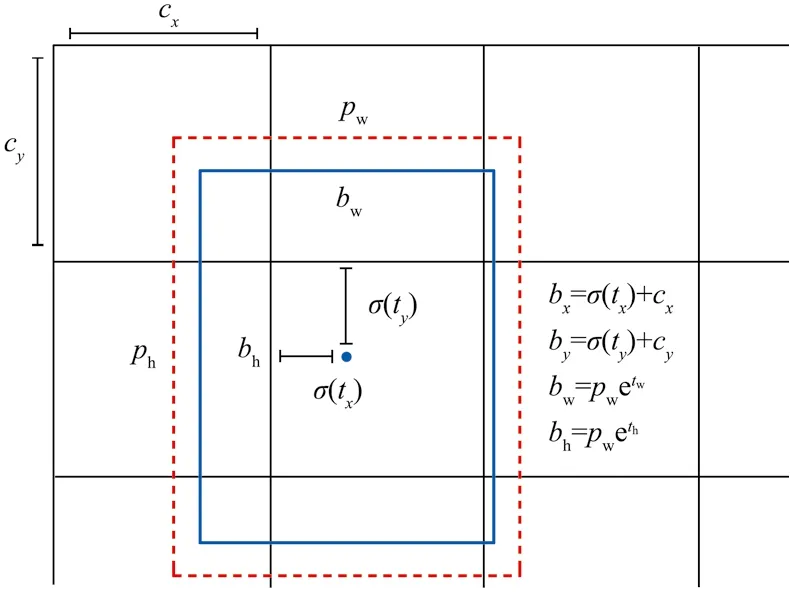
图2 带有尺寸先验和位置预测的边界框Fig. 2 Boundary box with dimensional priori and position prediction
若网格从图2中图像的左上角平移(cx,cy),之前bbox的宽度和高度分别为pw和ph,则对应预测框为

系统采用平方误差损失和进行训练,应用逻辑回归预测所有边界框的对象分数。如果之前的一个边界框比其他边界框与标记区域(ground truth)重叠得更多,则对应的类别被置为1。若之前的边界框不是最优的,但是与标记区域对象重叠超过给定阈值,则忽略这个预测,每个标记区域对象只分配一个bbox。如果之前的边界框没有分配给标记区域对象,则不影响坐标或者类别预测。
(2)采用多标签分类法为每个边界框预测可能包含的类别,应用独立的逻辑分类器,在训练时使用二元交叉熵损失函数进行类别预测,处理一个边界框包含多个类别的情况。
(3)预测3种不同尺度的边界框,使用与FPN相似的概念从这些尺度中提取特征。首先,从基础特征提取器中加入几个卷积层(convolutional),预测3维张量编码边界框、对象和类别。张量尺寸为N×N×[3×(4+1+nc)],其中,N为最终特征维度,被默认为1;nc为类别个数。接着,从前两层中获取特征图(feature map)并将其进行2倍上采样,从早期的网络中获取特征图并与上采样的特征进行合并,从而在早期特征映射中的上采样特征和更细纹理信息中获得更有意义的语义信息。最后,再加入几个卷积层处理组合的特征图,预测一个2倍大小的相似张量,并采用k-means聚类确定边界框的先验。具体的网络结构如图3所示。

图3 网络结构Fig.3 Network structure
1.2 模型训练
模型训练时,建立20 000幅图像作为训练数据集,其中10 000幅包含公里标,10 000幅包含坡度标;建立10 000幅图像作为测试集,其中1 000幅包含公里标,1 000幅包含坡度标,8 000幅不含公里标也不含坡度标。所有图像的分辨率像素均为416×416(宽×高)。该数据集有以下特点:
(1)背景复杂多变。图像中包含花草树木、桥墩、道砟、围墙、房屋等场景,增加了检测难度,对模型泛化能力、实用性提出了很高的要求。
(2)局部标注。标注目标位置时,常规情况下会使矩形框完全包括整个目标;但实际线路中存在公里标一部分被覆盖的情况,为更好地适应实际情况、提高检测精度,部分图像只标注公里标上半部分。
为使YOLOv3模型能更好地应用于公里标检测,通过多次试验对比,得出以下参数修改策略:
(1)网络修改。本文应用预训练的darknet53作为基准网络,针对网络结构修改了3个不同尺度边界框的filters,将其均设置为21;每个检测器只检测公里标和坡度标,故将类别数(classes)设置为2。
(2)一般超参数设置。采用批归一化(batch normalization, BN)简化网络,将最大迭代次数设置为10 000次,动量因子设置为0.9,学习率采用step递减策略,初始值为0.000 5,decay为0.000 5。
(3)优化训练误差统计。采用Focal_loss函数结合泛化交并比(generalized intersection over union,GIOU)计算损失,以提升对识别困难公里标的检测效果。
1.3 公里标字符识别
完成公里标矩形区域定位后,还需要对其中的数字信息进行解析。主要分为2个部分,即字符区域定位、单个字符切分和识别。
(1)字符区域定位。检测到的公里标矩形区域如图4所示,处理流程如箭头指示,应用otsu自适应阈值分割滤除公里碑背景,经形态学处理后精确定位碑面(红色矩形框),再通过水平和垂直梯度探测器搜到文字区域(绿色矩形框)。

图4 字符区域定位Fig. 4 Character region location
(2)字符切分与识别。公里标上的各个字符高度近似,且相邻字符中心水平距离相等。如图5所示,按箭头方向指示顺序进行,首先对字符区域进行阈值分割,前景灰度值为0,背景灰度值为1;接着沿垂直方向进行灰度投影,统计每列灰度值为0的像素点个数,再结合字符高度信息切分出单个字符所在的矩形区域,按从左到右的顺序进行排序。训练一个输入为32×32、输出为10的LeNet[8]卷积神经网络分类器,将每个字符所在的矩形区域缩放至32×32大小,输入到已训练好的LeNet,输出单个字符所属类别。

图5 字符切分与识别Fig. 5 Character segmentation and recognition
2 试验结果与分析
本文应用NVIDIA QUADRO P5000型专业图形显卡进行加速计算,从实际线路上采集的图像中挑选出10 000幅具有代表性的图像作为测试样本进行算法性能验证。应用同样的数据集,本文还采用了Faster R-CNN深度学习框架进行公里标检测对比试验。
2.1 公里标检测实验
应用本文算法训练损失函数变化曲线(图6),算法能够很好地收敛,用训练好的模型参数在测试集上测试的结果如表2所示,主要从mAP、召回率及检测速度方面进行评估。两种算法对公里标检测的mAP和召回率接近,均能很好地区分公里标和坡度标,消除了坡度标带来的位置信息解析错误风险,但YOLOv3检测速度比Faster R-CNN的快3倍。

图6 训练误差曲线Fig. 6 Training error curve

表2 公里标定位测试结果对比Tab. 2 Comparison of kilometer post position test results
对于表1所列的各种复杂场景,采用本文算法均能准确地获取公里标矩形区域(图7),从而保障后续数字信息识别的准确性。

图7 复杂场景检出效果Fig. 7 Detection results in complex scenes
2.2 公里标数字信息识别试验
采用1.3节阐述的数字信息解析流程,在检出的公里标矩形区域进行位置信息解析,其字符区域定位准确率、切分准确率、单字符识别准确率均高于99.8%,存在错误的原因主要是部分图像因相机抖动导致存在残影,即便如此,整体公里标识别准确率也达到99.87%,完全满足实际应用需求。
3 结语
本文提出一种结合YOLOv3模型的公里标识别方法,以实现对公里标位置信息的精确解析。在面对复杂场景的公里标检测识别上,本文算法具有检测精度高、鲁棒性强和检测效率高的优势,解决了现有公里标图像识别方法在复杂背景下无法正常工作的问题,从而满足钢轨探伤车位置校正的需求。虽然采用本文方法能取得很好的识别效果,但图像质量若太差,依旧会存在无法识别的情况,因此后续将研究如何进一步提高系统的整体性能。
