基于故障日志的城轨地面信号故障诊断
2020-11-17谢明军何剑峰胡小溪
谢明军,何剑峰 ,胡小溪,曹 源
(1. 通号(西安)轨道交通工业集团有限公司, 西安 710100; 2. 北京交通大学 a.轨道交通控制与安全国家重点实验室, b.轨道交通运行控制系统国家工程研究中心, 北京 100044)
据不完全统计,从2012年初至2017年末,北京市因信号系统故障导致的城市轨道交通列车延误5 min及以上的事故226件,涉及列车3 548列,停运事故1 150件,涉及列车3 263列,造成了旅客出行的不便和经济损失.产生这些事故的原因主要是由于城市轨道交通信号系统结构复杂、耦合紧密、集成度高;信号设备故障类型多、故障影响范围大;信号故障诊断困难、维护抢修耗时较长.目前,城市轨道交通运营现场的故障诊断依旧依赖专家经验,无法满足城市轨道交通对运输的需求.因此,如何有效地进行城市轨道交通信号的故障诊断是解决故障时恢复城市轨道交通运输系统规定运营能力的关键所在.
城市轨道交通信号故障日志是目前现场最常见的故障信息的载体,记录了故障相关的信息.学界上,利用统计机器学习方法可挖掘和学习故障日志的故障相关信息,建立故障现象与致因间的映射关系,从而达到故障诊断的目的[1].
基于故障日志的故障诊断通常包括文本预处理、特征分析与提取、构建分类器、故障诊断4个步骤[2].1)文本预处理通常是数据清洗、文本分词与结构化.数据清洗主要是过滤无效数据和填补缺失值等.分词是将文本字符串切割成词或字单元,以便结构化处理和转换.分词方法主要有基于词库、基于统计和基于理解的分词[3].其中,常用的分词方法是基于词库的分词[4-5],但这种方法对词库的依懒性强,需要处理未登录词(该词不存在于词库中,但存在于故障日志中)的问题,导致人工维护词库的工作量大.结构化是将分词后的文本用向量模型,通常采用基于词袋假设的向量空间模型[6]表示.同时在深度学习领域也提出将文本向量化的方法.2)特征分析与提取是分析数据、提取数据特征与维度缩减,通常有词频TF加权、卡方检验Chi-square、主成分分析、期望交叉熵等方法.文献[7]采取奇异值分解实现了数据去噪并提取特征,但无法完全解决自然语言的语义模糊问题.文献[8]采取基于EM的pLSA进行特征提取,同时解决了语义问题.但pLSA在文档层没有引入先验概率,不是完备的生成模型,导致pLSA无法直接提取未知致因的新样本特征.只能将新样本加入旧样本作为整体文本库重新进行pLSA训练,以此获取新样本的特征信息,且EM-pLSA容易出现过拟合问题,pLSA的参数数目随着语料库中的文档数呈线性增长,当样本量过大时,使其无法快速地对未知致因的新样本进行故障诊断,因此不适用于日益增大的语料库.3)构建分类器通常采用机器学习、深度神经网络等建立故障特征与故障致因间的映射关系,从而得到故障诊断映射.文献[9-10]分别利用人工神经网络和长短时记忆网络学习故障现象与致因的映射,实现了故障诊断,但诊断结果仅给出一种致因.对于轨道交通信号系统的大多数故障而言,宏观上相同的故障现象,在微观上却有可能由不同的致因所导致,因此这种方法不适用于城市轨道交通信号领域的故障诊断.4)故障诊断是用已建立的分类器对新发生故障进行诊断分析,给出可靠的致因.诊断的评价指标多以准确率进行计算.文献[11]以准确率为故障诊断评价指标,使用分数阶小波包能量熵实现列车塞拉门的故障诊断.
本文作者为了弥补基于词库分词的缺陷,获取更全面的特征,采用不依赖词库的机器学习方法学习故障日志的词语分词规律,以完成对未知文本的切分,识别出未登陆词,将该词汇入用户词库,形成最终使用的专门面向线路的词库.为了提高特征提取的精度,采用监督型隐狄利克雷分布(supervised Latent Dirichlet Allocation, sLDA)对故障日志进行特征降维,同时解决了故障日志的描述不规范、多词同义,且适应于记录简短、语义单一的文本.由于故障现象语义的独立性,采用朴素贝叶斯模型(Naïve Bayesian Model, NBM)学习故障现象与故障致因间的关系,进行统计推理,得到各种致因的概率分布,从而实现实时故障诊断.在实验阶段,选取某城市轨道交通线路2010、2012—2017年地面信号设备故障日志进行实验,以验证该方法的有效性.
1 城轨地面信号系统与故障日志
1.1 城轨地面信号系统
城市轨道交通信号系统是保障列车安全运行、提升运输效率的核心控制设备.本文以城市轨道交通地面信号系统为对象展开研究,其主要分为中心层设备、车站层设备和轨旁层设备,系统组成见图1.中心层设备的主要作用是集中调度和监控现场运营状态.中心调度员通过中心调度大屏和调度员工作站对现场设备进行监督和控制.车站层的主要作用是控制现场设备,保证列车在本区域的安全运行,由联锁系统完成逻辑运算并控制室外转辙机的动作、信号机的点灯;区域控制器计算列车的移动授权.轨旁层的设备复杂繁多.转辙机控制道岔的位置从而改变或保持列车的行驶轨道,轨道电路主要由发送器、接收器和钢轨导体组成,用于完成列车的定位和信息传递,信号机在后备模式下点灯指示列车的最高允许行驶速度,应答器用于信息传输和列车位置校核、TDT告知司机剩余发车倒计时.各种设备正常协同工作,以完成轨道交通的高效与安全运行.
1.2 故障日志数据特点
以某城市轨道交通地面信号设备为例,相关设备的故障日志部分字段如表1所示,数据来源于该线路现场信号维修工人的记录,故障现象通常是运输调度人员通过ATS分机或者中心调度大屏上观察得到的高层级别的故障表现.其中未列出的字段对本文研究没有意义.

表1 某城市轨道交通地面信号设备故障日志(部分)
观察故障日志,发现了一些现象和问题.语义含义相同的故障现象的描述记录措辞不规范、不统一,存在多词同义的现象,并且描述简短,语义单一、均为高层的系统级故障表现、没有细节化的故障表象.例如,故障记录1~3对于轨道电路红光带的描述不统一,有记载为“红光带”、“红色光带”、“轨道电路闪红”等,其实质均为轨道电路红光带故障,即为多词同义现象、描述不规范、不统一;类似情况如故障记录4~6对于列车未收到前方区段的目标速度码的描述不规范,措辞存在:“无列车速度码”、“收不到速度码”、“未收到目标速度码”、“未收到列车目标速度码”等;同样地,故障记录7~8对TDT黑屏故障的描述方式多样,有中文全称和英文缩写.对于这些描述不统一的故障现象,计算机无法直接将其识别为同类故障.此外,大多数相同的故障现象对应多种不同的故障致因,如故障记录1~3,4~6和7~8,这是由于故障日志的记载仅描述了系统级层面的故障,无法进行细节化填充.
部分故障记录中未记载明确的故障致因,经事后调查发现是间歇性故障[12]和NFF(No-Fault-Found)失效[13].这些故障的故障致因暂未查明,且是目前占据比例较大的故障.如故障记录8,但此类故障对运营也造成了一定干扰,需将此类情况考虑在内,给予保留.
部分故障现象记录了对运营的影响,如故障记录2、3、7.但运营延误信息是在故障发生后对运输的影响,在实时故障诊断中无法立即获取延误信息,因此延误信息对实时故障诊断没有意义,需要过滤掉各条记录中延误相关信息.
1.3 故障诊断流程
本文提出的基于故障日志的故障诊断方法流程如图2所示.
2 文本预处理
清洗故障日志,剔除该故障日志中的无效记录和字段缺失的记录.同时为了更全面地提取特征,需识别既有的通用信号词库中的未登录词,文本选用条件随机场(Conditional Random Field, CRF)进行分词,从而对既有词库的未登录词进行识别.
2.1 CRF
CRF是一种用来标记和切分序列化数据的统计模型和监督式学习方法,具有最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)的所有优点,同时解决MEMM的标记偏置问题[14].在给定的观测序列下,线性CRF计算整个标记序列的联合概率,CRF的图结构如图3所示.在线性CRF分词中,Y是输出变量,表示标记序列,Y可能的取值为{B, M, E, S},代表字的词位信息,分别是首字、中字、尾字、单字成词.X是输入变量,表示需要标注的观测序列,即故障日志文本记录.
利用CRF学习已标记的训练样本数据,即人工切词表明一段文本中各个字的断句关系,再统计全部训练样本库中的前一个字与后一个字之间的聚合情况,即分析BMES关系,通过MLE得到条件概率模型如下
(1)
2.2 CRF分词与文本结构化
故障日志经分词后过滤重复和无意义词项,保留既有的城轨信号词库中未出现的词项,作为未登录词.将未登录词和既有词库融合,形成新的面向该线路的词库,以词库中的词项为特征,采取向量空间模型将故障记录结构化,形成词项-文档矩阵,流程如图4所示.其中,无关词项可不加入词项矩阵的列或数据降维,以过滤故障现象列中的运营延误影响.文档-词项矩阵为
其中:第1行为Doc1,第2行为Doc2,第3行为Doc3,…;第1列为红光带,第2列为红色,第3列为光带,最后则为Label.
3 特征分析与提取
3.1 sLDA方法
sLDA是在LDA模型中引入标签变量形成的监督型LDA,是由LDA结合GLM构造而成的,精度通常比非监督式LDA高.sLDA图模型表示如图5所示,用来描述文本的生成过程.其中:α为狄利克雷分布的超参数;βk为第k个主题的词项分布(共K个主题);θm为第m个文档的主题分布;zm,n为第m个文档中第n个词项的主题;wm,n为第m个文档中第n词项;η和δ为GLM参数.
sLDA生成M篇文档(每个文档含Nm个词)和文档标签lm流程的伪代码如下
算法 1: sLDA的生成模型
1输入:参数α,βk,主题个数K,泊松分布期望ζ,词库,GLM参数η和δ
2输出:M篇文档(每篇文档Nm个词),文档标签lm
3 //文档层
4 form=1:Mdo
5 抽样第m个文档-主题分布θm~Dir(α)
6 抽样第m个文档的文档长度Nm~Poiss(ζ)
7 //词项层
8 forn=1:Nmdo
9 抽样第m个文档中第n个词项的主题zm,n~Mult(θm)
10 抽样第m个文档中第n个词项wm,n~Mult(βzm,n)
11 end
12 抽样第m个文档的标签lm~GLM(zm,η,δ)
13 end
其展示了文本数据集的生成过程,生成过程的逆过程即为通过文本数据集学习sLDA的各个参数的过程,可理解成为数据集的sLDA参数拟合.通过数理统计分析,在sLDA中,文档标签lm的条件概率如下
p(lm|zm,1:Nm,η,δ)=
(2)
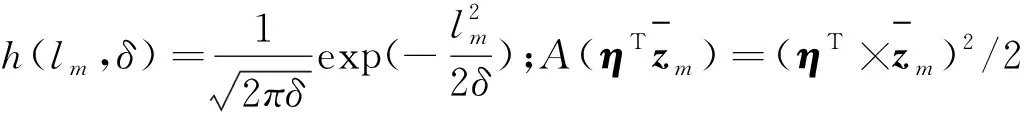
sLDA不仅可处理回归问题,也可处理分类问题.当标签为离散变量即处理分类问题时,sLDA利用变分期望最大化算法观测数据进行模型参数优化求解,得到α,βk,η,δ的最优解,并推断新样本的标签,推导过程见参考文献[16].
3.2 sLDA特征降维
通过sLDA参数拟合带有标记的故障日志文档-词项矩阵,获得模型sLDA{α,β1:K,η,δ}.现可视化各故障现象的词项分布及其释义,如表2所示,聚类得到故障现象|L|=33个.

表2 标签的词项分布及释义

续表2
观察表2可发现,sLDA使计算机自动识别出相同语义的故障现象,将其合并为同一类故障,以便后续处理.例如,标签为1的词项分布的故障释义对应表1中编号为1~3的故障记录;标签为2对应编号为4~6的故障记录.可以分析出,sLDA将故障日志从词项空间转换至故障语义空间,使故障日志的数量规模降低到有限的故障现象的数量规模,可简化诊断映射关系中的节点数目,降低诊断网络的复杂性,并在一定程度上使故障现象对应的致因概率分布更加贴近真实值.
4 故障分类器构建
4.1 朴素贝叶斯模型
NBM是贝叶斯网络的简化形式,其朴素表现在该模型假设特征属性是互相独立的,且特征属性对被解释变量的影响相同,通用 NBM 如图6所示.
城市轨道交通信号故障日志的特征恰好符合朴素贝叶斯模型的假设,其表现在每条故障记录仅存有一个故障语义标签.因此本文采取朴素贝叶斯模型学习城市轨道交通故障日志的特征节点与故障致因间映射关系,用于故障诊断.
在城市轨道交通信号故障诊断中,NBM的属性节点Lh(1≤h≤H)为故障现象,F为故障致因节点,F={fj|1≤j≤J},fj为第j种故障致因,共J种故障致因.对于给定的故障现象的sLDA输出L={L1,L2,…,LH-1,LH},再通过训练好的NBM,输出故障致因的后验概率,计算公式如下
P(F=fj|L)=
j=1,2,…,J
(3)
同时,为了避免特征属性的条件概率为0导致故障致因的后验概率为0,因此采取Laplace Smoothing处理条件概率.
4.2 故障诊断网络的建立
城市轨道交通地面信号设备故障诊断网络如图7所示.其中:Di表示第i条故障日志的自然语言描述;Li表示故障语义空间的故障分布的标签;H为标签个数;Q为故障日志的总条数;DQ+1表示发生的一条新故障;J为故障致因的总个数.
由于本方法从实质上是属于数据驱动的诊断诊断方法,因此可适用于各个城市轨道交通线路.
5 故障诊断实验与分析
以某城市轨道交通线路2010、2012—2017年的地面信号设备故障日志数据(共892条有效记录)进行实验分析,采取Holdout验证,抽取75%的样本用于诊断网络的学习,剩余样本作为新故障进行致因概率统计推断,以验证算法的准确性.以表3样本为例进行诊断结果的展示(致因仅作为诊断网络的准确度判断),诊断结果的致因分布按概率降序排列如表4所示.

表3 新样本案例
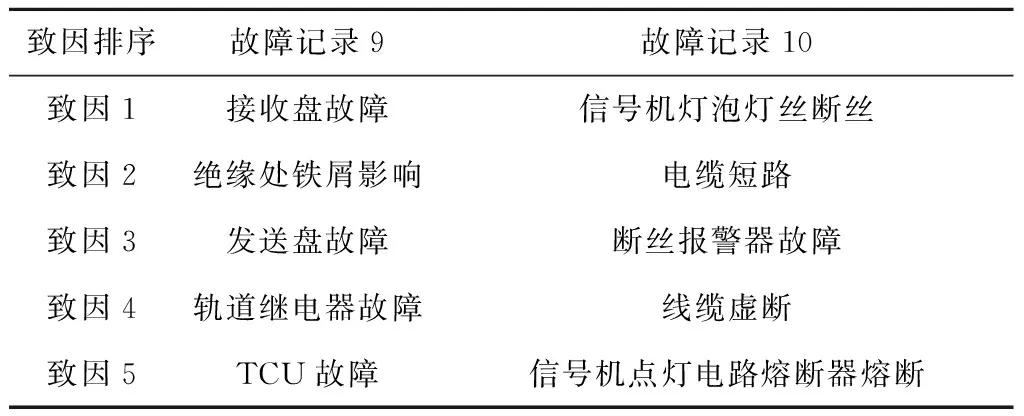
表4 新样本案例的诊断情况
为了避免遗漏重要故障致因,同时给故障处置提供足够支撑,且目前现场的故障日志为高层级别的故障现象,无法映射到准备的故障致因,本实验以P@N(N取5)为验证指标[17],即概率排序前五的致因作为输出结果,具体计算公式如下
(4)
式中:i指第i类故障;Ci是第i类故障的个数;I(j)是指将第Ci类故障的第j个故障输入故障诊断模型后输出的故障现象对应的前五个致因是否包括故障现象的真实致因.若包括,则I(j)取值为1;反之,取值为0.
同时选择TF、IG、Chi-square、PLSA、VEM-LDA[18]、Gibbs-LDA[19]6种方法进行比较,表5给出了按照式(4)分别计算不同故障Ci的诊断效果.

表5 各类故障的P@5
表5展示的故障诊断结果中,sLDA算法的整体P@5值高于其他对比算法.经过分析,其他几种特征提取方法精确率较低的原因是:TF方法仅考虑了词项的出现频数,未考虑其语义之间的关系,IG和Chi-square方法同样未考虑语言信息,且采用的统计学方法无法较好地提取本问题中的特征.PLSA、VEM-LDA、Gibbs-LDA和sLDA方法均考虑了自然语言信息,但是PLSA容易出现过拟合问题,聚类得到的故障类别数偏低.VEM-LDA、Gibbs-LDA方法通过词项的共现获取词项间的语义信息,但均属于非监督学习方法,其效果没有监督式学习精确,因此sLDA方法整体上较优,且会更加精确于实际故障致因的概率分布情况.
此外,进路相关故障、信号机相关故障和中心监控相关故障的P@5较低,其他类型的较高.观察故障日志发现,进路相关故障主要涉及车站本地控制台和联锁设备及两者间的通信;信号机相关故障主要涉及联锁系统和点灯控制电路的各个元器件;中心监控相关故障涉及中心层的全部设备.这三类故障的致因均包括系统软件缺陷、倒机影响、设备死机、通信异常、线路异物、人误等.然而,由于故障现象的表征信息不足、语义单一,相同的故障现象记录对应不同致因,故障致因分布相对均匀,致使故障诊断网络无法从繁多的故障致因中精确定位至实际的故障致因,因此这三类故障的诊断率较低.
综上所述,在系统级别层面上,可通过本文方法获得的高层级故障现象的致因概率分布,以辅助现场的维修人员进行快速的故障定位及处理,同时加速系统故障后的运营恢复.
6 结论
1)以某城市轨道交通线故障日志为文本数据,提出了基于故障日志文本信息挖掘的城市轨道交通信号设备的故障诊断.使用CRF完善既有城市轨道交通信号词库,形成面向线路的信号设备专有词库.
2)采用sLDA对故障日志进行语义识别,解决了故障日志的不规范性、多词同义现象且提高了故障分类精度.采用了朴素贝叶斯搭建故障现象节点与致因节点间的关系.
3)通过该城市轨道交通线路2010、2012—2017年的地面信号设备故障日志为数据进行实验,分析了该方法的有效性和局限性.
在后续的研究中,将研究制定信号设备状态特征信息的结构与框架,旨在全面地描述和表征设备系统的状态信息,使得故障诊断的准确率和精度有所提升.
