基于情境案例推理的播前收视率预测方法
2020-11-07翁康年张倩帆张玥杰
张 涛,翁康年,张倩帆*,张玥杰
基于情境案例推理的播前收视率预测方法
张 涛1,翁康年1,张倩帆1*,张玥杰2
(1.上海财经大学 信息管理与工程学院,上海市金融信息技术研究重点实验室,上海 200433;2.复旦大学 计算机科学技术学院,上海市智能信息处理重点实验室,上海 200433)
本文旨在研究基于情境案例推理的电视节目播前收视率预测方法,充分利用大量积累的历史收视数据,通过历史电视节目案例与新节目案例的匹配与重用对新节目收视率进行播前预测,弥补传统播前预测方法成本高、效率低的缺陷,为电视节目的播前收视率预测提供新思路。该方法在以下三方面显著不同于其他已有相关研究工作:1) 引入心理学和知识领域的情境至基于案例推理的播前收视率预测中,构建一种内外部情境相交融的电视节目案例表达多层次情境结构;2) 基于电视节目案例表达中所存在的多值情境,构建多值符号情境的局部相似度计算模式,即多值匹配策略;3) 针对案例重用中目标案例与相似案例的情境匹配,构建基于差异情境的情境系数调整规则。基于华东地区8个月的收视数据,以电视剧收视率调查作为实验分析的具体案例,实验结果表明,本文提出的播前收视率预测方法具有良好的预测效果,并展示出其有效性与合理性。
播前收视率预测;案例推理;多值情境;案例检索;案例重用
0 引言
20世纪90年代初,我国电视业开始尝试从“制播合一”向“制播分离”转变,在电视产业链中电视台仅负责节目的购买、编排和播放,而制作环节是由社会制片机构完成,电视台需向制片公司购买电视节目的播映权或版权[1]。这种交易发生在电视节目正式播出之前,是在未能完全确定电视节目的真正市场价值之前所产生的投资。若能在购买电视节目之前对电视节目的收视效果进行有效评估和预测,电视台就能准确把握电视节目的潜在市场价值,降低电视节目的经营风险。收视率作为媒介调查的重要数据,是衡量电视节目收视效果的重要指标,电视台通过把握电视节目收视率来提高其传播的针对性与有效性,并以此作为电视广告营销与市场定位的重要依据[2]。电视节目播前收视率的准确预测可帮助电视台进行电视节目的合理购买,降低投资风险和经营风险[3]。同时,电视广告商也需要根据电视节目收视率,进行广告播出时段价值评估和选择性购买,收视率的播前预测可为广告投放策略提供决策依据[4]。因此,如何准确预测电视节目收视率特别是播前收视率,对于电视媒体至关重要同时也是电视媒体领域的研究焦点。
目前,国内外有关收视率预测的研究主要侧重于播后预测,即电视节目播出后,根据影响收视率的相关因素,运用时间序列、线性回归、决策树、贝叶斯及神经网络等方法来预测未来一段时期内该节目的收视率[5][6]。对于播前预测的研究则相对较少,主要通过播前测试与播前评估的方式来预测电视节目收视率或电影票房[7]。针对播前测试,美国电视业普遍使用小安妮(Little Annie)节目分析系统,在播放样片的同时记录观众反应和情绪对节目情节进行深入分析,进而预估电视节目收视率。在此基础上,上海电视台(Shanghai Media Group, SMG)建立受众测试中心,对新节目与改版节目进行播前受众测试,首先通过看片系统实时监测观众在收看节目时的意愿变化,并以曲线形式展现其兴趣点;然后通过填写问卷了解观众对关键要素的评价,最后对收视率进行预测。相关研究者也对播前评估体系与方法进行研究,提出包括品牌和内容质量指标在内的电视节目评价指标体系,将观众进行分类取样,然后进行电视节目试播和观众实时评价记录,根据评价指标的权重以及观众的打分而得到电视节目收视率的预测结果[8]。虽然播前测试/评估方法取得较好的效果,但在构建看片室、组织观众和专家试看节目、及对评价结果进行统计分析上却要耗用大量的人力与物力,测试方式耗时长、流程复杂,对于电视制播机构是一项不小的开支。
电视节目播前收视率的智能预测研究尚处于起步阶段,难以满足电视媒体领域实际需求[9]。考虑到电视节目收视率在短时间内较为平稳,电视节目的受众群体相对稳定且极少受突发事件影响,灰色预测、时间序列分析、线性回归等方法被逐步引入至电视节目播前收视率预测,并获得一定的预测效果[10]。这些方法偏重于对电视节目收视数据的整体倾向性进行统计分析,针对预测模型的变量间呈现显著线性关系、或者经过数据转换可构建变量间线性关系的情形,对电视节目播前收视率预测具有一定的优势。但现实中的电视节目播放通常存在一些干扰因素,使得播前预测问题的变量间呈现非线性关系,这可能增大预测误差甚至会导致预测失败。因此,上述预测方法难以对电视节目播前收视率的线性及非线性规律进行有效分析与归纳,其预测的播前收视率准确性往往也较为有限。针对该问题,电视媒体领域的学者尝试采纳电视节目收视率的各种影响因素作为统计依据,利用数据挖掘与统计学习方法进行电视节目播前收视率预测[11][12]。目前,有关电视节目播前收视率的智能预测方法主要包括决策树算法、贝叶斯算法、以及神经网络算法三类。基于决策树的收视率预测模式充分发挥其能够有效解决高维数据分类且分类效率高、准确性高、生成模式简化等诸多优势,使用决策树中的ID3算法实现电视节目收视率分类预测建模[13]。基于贝叶斯算法的收视率预测模式充分发挥其易于结合先验知识和样本数据、具有因果与概率性清晰语义、有效描述数据间相互关系、以及蕴含所有变量间依赖关系等诸多优势,构建考虑先验知识的电视节目播前收视率预测模型[14][15]。基于神经网络算法的收视率预测模式充分发挥其良好的自学习功能、高速寻优能力等诸多优势,融合电视节目播前收视率指标体系而建立基于BP神经网络的收视率预测模型[16][17]。可以看出,当前已有的电视节目播前收视率预测相关研究工作取得一定效果,但由于主客观因素,目前的主流方法在电视节目播前收视率预测方面仍存在一定的局限性[18][19]。基于决策树的预测模式虽然对电视节目影响因素的分析较为深入,但在具体的播前收视率预测上不能给出确切的预测值,同时随着数据规模变大,决策树也会随之变化。类似地,基于贝叶斯网络的预测模式同样无法对具体的电视节目播前收视率数值进行预测。基于神经网络的预测模式,虽可给出电视节目播前收视率预测值,但网络训练学习在很大程度上取决于电视节目自身的特点,通常采用5分制对影响节目收视的因素进行评分,不同的人对不同因素的评分存在主观性,该预测模式所得到的结果存在较大的主观局限性,在某些情况下所构建的网络学习模型可能精度较低。
案例推理(Case-Based Reasoning, CBR)是人工智能领域一种基于经验的问题求解方法,其模拟人类求解问题的思路,通过修改已有解决方案来满足求解新问题的需要[20][21]。随着数字电视与机顶盒技术的成熟,收视数据的采集越来越方便,电视媒体机构积累的收视数据也不断增长,这些激增的收视数据背后蕴藏着大量具有决策价值的信息均为问题求解的经验。案例推理主要基于两个假设:(1)相同或相似问题有相同或相似的解决方案;(2)相同或相似的问题会重复出现[22] [23]。它可被认为是基于类比的推理,采用目标案例和源案例的相似性匹配进行问题求解,当遇到一个新问题时,会在存储以往解决问题经验的案例库中查找与新问题相似的案例,并将相似案例的解决方法进行一定的调整作为新问题的解决方案,同时新问题也作为一个新的案例加入至案例库中[24]。本文拟利用从某公司获取的大量历史收视数据,研究基于情境案例推理的电视节目播前收视率预测方法。考虑到电视剧是电视台播出量最大、观众收视时间最长的节目类型,是大部分电视台及新媒体播出机构投入量最大、产出最多、覆盖效果最好的产品,结合电视剧的特点,将案例推理机制应用于电视节目播前收视率预测,同时引入心理学和知识研究领域中的情境概念至案例知识表达,构建局部相似度计算的改进策略与案例重用的调整规则[25]。由此,针对电视节目播前收视率预测而提出有别于传统播前预测方式的新思路,有效降低播前评估成本且提高预测效率,支持电视媒体与广告商在节目的交易、编排、及广告投放中进行合理决策。
1 融合多层次情境的案例框架表示
案例表示是案例推理的基础,准确的案例表示是保证案例推理高效求解问题的前提。在案例表示方法中,框架法能够表达结构性知识,既可减少知识冗余,又可保证知识一致性。鉴于本文所研究的电视节目案例具有结构性强的特点,利用框架法对其进行案例表示有利于案例知识的进一步扩充,因此采用框架法来对电视节目构建有效合理的案例表示。同时,在案例表示中引入情境的概念作为案例的一种具体表达形式,建立电视节目案例表示的多层次情境结构[26]。其中,将演员、类型、题材、年代等电视节目本身的要素定义为内部情境,将电视节目播出的频道、时段、档期等环境因素定义为外部情境。内外部情境两者相结合共同组成电视节目案例表示中的问题描述,解描述即为播前收视率。
1.1 情境案例框架表示
一般案例中的情境按取值可分为两类,即确定数情境与确定符号情境。确定数情境是指情境值是确定数字的案例情境,这些情境值可连续也可为离散;确定符号情境是指情境值为确定字符串的案例情境,这些情境值通常用明确的术语表示。根据内外部情境的定义,本文将内外部情境的取值均定义为确定符号型,事先将各情境的可能取值一一列出,情境值仅限于所列举的取值范围内。
本文将案例表示成框架、槽和侧面的形式。在电视剧案例中,设电视剧是一个框架,其演员类型、演员知名度等问题描述以及解描述都是电视剧这个框架下的槽/情境,每个情境的取值即为槽值。本文采用归纳法总结出电视剧案例的内、外部情境及其取值,用框架法对电视剧案例进行表示的形式如下:
<电视剧>
<案例编号> (1, 2, …)
<电视剧名> (琅琊榜,伪装者,欢乐颂,…)
<演员类型> (偶像派,实力派)
<演员知名度> (一线,二线,三线)
<地区> (大陆,港台,日韩)
<年代> (当代,现代,近代,古代)
<类型> (爱情,搞笑,悬疑,犯罪,动作,恐怖,科幻,偶像,…)
<题材> (军旅,都市,农村,青少,涉案,传纪,革命,神话,…)
<编剧知名度> (一般编剧,知名编剧)
<导演知名度> (一般导演,知名导演)
<剧本来源> (小说改编,原创,电影改编,游戏改编,真实案例)
<制片人等级> (甲证,乙证)
<频道影响力> (一线,二线,三线)
<播出时段> (黄金时段,次黄金时段,非黄金时段,深夜时段)
<播出档期> (暑期档,贺岁档,公休日,工作日)
<播出方式> (首播,重播,非首播1,非首播2,非首播3)
<收视率>
1.2 情境权重计算
案例情境的权重决定着案例间相似度的大小,影响着案例推理的质量[27]。常用的客观赋权法包括主成分分析法、熵权法、信息增益法等。主成分分析法进行特征权重的计算是一个变量降维的过程,即所提取的主成分个数小于原始数据变量的个数,且对主成分含义的解释一般带有模糊性。在针对案例推理的研究中,若用主成分分析法对情境进行降维,则案例表示中的内外部情境将减少,案例库中案例间的区分度也将降低,影响案例检索的结果,同时对所提取的主成分含义的解释也具有一定的模糊性,不利于后续的预测。熵权法是根据信息的离散程度对各指标赋熵权,能充分利用原始数据所提供的信息来得到客观指标权重。然而,熵权法仅考察各指标内部信息的离散程度,缺乏指标间的横向对比。若采用熵权法来计算各案例情境的权重,则仅能根据各情境的离散程度来衡量每一情境的重要性,缺乏各情境对收视率影响程度的对比。信息增益法被广泛应用在机器学习领域,用来处理文本分类中的特征选择问题,是最有效的特征选择算法之一[28]。信息增益法通过特征为系统带来的信息量来衡量特征的重要度,充分考虑了特征对文本类别的信息表示量,根据信息量的多少来确定特征的权值,并进行特征的选取。因此,信息增益能够将特征与系统分类目标联系起来,客观地衡量特征对系统分类的影响,不仅有利于后续的预测,而且还利于实现各情境对收视率影响程度的对比。因此,本文采用信息增益法来计算各案例情境的权重,过程如下:

2 基于情境案例推理的播前收视率预测
案例推理过程包括案例表示、案例库构建、案例检索与匹配、案例重用、案例修改、及案例存储等诸多环节。由于电视节目案例表达中存在多值情境,因此在案例检索阶段对最近邻(K-Nearest Neighbor, KNN)算法中局部相似度的计算进行补充与改进,建立多值符号情境的局部相似度计算方法,即多值匹配策略。在案例重用阶段,构建基于差异情境的情境系数调整规则,对最相似案例的解进行调整,得到目标案例的建议解。
2.1 案例推理
案例推理是基于知识的问题求解和学习方法,相关学者已构建一些将案例推理思想有效应用的模型框架,其中R4模型被大部分学者接受与认可,并在实际中被广泛应用[29]。R4模型将案例推理的过程分为四个阶段,包括检索(Retrieve)、重用(Reuse)、修正(Revise)和存储(Retain)。案例库的构建是案例推理的基础,有学者在R4模型的基础上,又将案例推理的模型扩展为R5模型[30],即增加了重分配(Repartition),在R4模型中的案例检索阶段考虑了案例表示的重要性,强调案例表示是案例推理过程中的重要组成部分。本文采用R5模型,以融合多层次情境的案例框架表示为基础,构建基于情境案例推理的播前收视率预测模型,如图1所示。

图1 面向案例推理的R5模型
Figure 1 An illustration of the R5 model for case-based reasoning
2.2 案例检索与匹配
案例检索是案例推理中的重要环节,通过目标案例与源案例的检索与匹配来找到目标案例的相似案例。KNN算法结合领域知识,解释能力强,在很多案例推理系统的研究中都取得较好效果,因此采用KNN算法来实现案例检索,通过计算目标案例与源案例在特征空间中的距离来得到两个案例间的相似度。首先计算目标案例与源案例各情境间的距离,然后根据各情境的权值计算出两个案例间的距离,从而得到两者之间的相似度,这里采用欧式距离计算相似度。
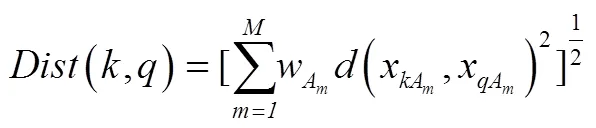

使用KNN算法进行案例检索时涉及局部相似度与全局相似度的计算,局部相似度是目标案例与源案例各个情境之间的相似度,全局相似度则是目标案例与源案例之间整体的相似度。局部相似度计算根据情境值类型的不同而不同,本文电视节目案例的情境均为符号型,其中类型和题材两个情境是复杂的多值符号型,其余情境为简单符号型。所谓复杂多值符号型是指情境取值为多值且各取值之间存在层次结构,而简单符号型是指情境各取值之间相对独立且不存在层次结构。各类型情境的局部相似度计算方法如下:
(1)简单符号型局部相似度计算
若目标案例与源案例的某情境取值完全一致,则该情境的局部相似度为1,否则为0。即:

(2)复杂符号型局部相似度计算
这里,利用分类体系表示情境取值之间的关系,例如,有关“题材”情境的分类体系示意图如图2所示。

图2 题材情境的分类体系表示
Figure 2 The classification system representation of subject context
1)检索值和案例值均为叶节点,其局部相似度为:
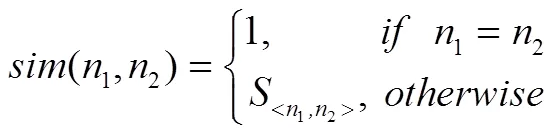
2)检索值为叶节点,案例值为内部节点,其局部相似度为:

3)检索值为内部节点,案例值为叶节点,其局部相似度为:
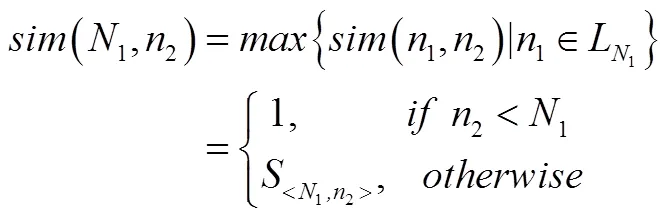
4)检索值和案例值均为内部节点,其局部相似度为:
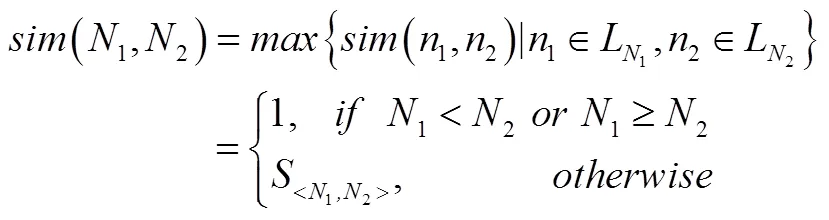
(3)改进的多值符号型局部相似度计算方法
对于多值符号型情境,以往对其局部相似度计算的方法大都较为简略。例如,“类型”和“题材”两种都是复杂多值符号型情境,即一个电视节目可以有多个类型和题材,且不同类型和题材有不同的收视群体,题材和类型的差别可能导致较大收视率差异。因此,对于多值情境的相似度计算,本文提出一种多值匹配策略,将目标案例的类型或题材逐一与源案例的类型或题材相匹配,只有类型或题材的所有取值都完全匹配时,两者间局部相似度为1;否则,局部相似度需要按公式(8)计算。

2.3 案例重用
案例重用是案例推理的关键步骤,也是案例推理中的难点,主要归因于其具有领域依赖性。一个新问题通常不可能和先前已解决的问题完全一致,即在案例检索阶段得到的最相似案例解通常不能完全适用于目标案例的解决方案[31]。因此,当检索出最相似案例之后,还需重用检索出的相似案例的解,对解进行一定的调整,以得到更好的解决方案。案例调整通常采用完善规则与调整规则。完善规则是对目标案例的问题描述进行修改,调整规则是对相似案例的解进行修改。本文采用调整规则来对相似案例进行重用,提出一种基于差异情境的情境系数调整规则,根据目标案例与相似案例中存在的差异情境,采用事先定义的情境系数对相似案例的解进行调整,从而得到目标案例的建议解。
所提出的调整规则其思想源于构建电视节目评估体系时所关注的收视指标标准化,即将频道、时段等外部因素对电视节目收视指标的影响降至最低,从而形成客观的评价指标。标准收视指标的表示形式为:标准收视指标=基础指标*时段系数*频道系数*节目类型系数,其中时段系数是指某时段与全天其他时段相比的收视贡献程度;频道系数是指某频道与市场竞争频道相比的收视贡献程度;节目类型系数是指某节目类型与其他节目类型相比的收视贡献程度。
(1)情境系数定义
以标准收视指标以及时段、频道和节目类型系数的定义为基础,提出电视节目案例情境系数的概念。情境系数即为某情境取值与其他情境取值相比的收视贡献程度,如下所示:
(2)基于差异情境的情境系数调整规则
3)根据差异情境各取值的调整系数,将相似案例的收视率调整至一个标准值,即:

4)根据目标案例中对应差异情境的取值,利用这些情境取值的系数对标准值进行调整,使其与目标案例相匹配,得到目标案例的建议解,即目标案例收视率的预测值为:

3 实验分析
本文实验数据来源于华东地区8个月的十多万条收视数据,包含每天各个时段各个频道播放的不同电视剧。按照案例情境表示的方法,将收视数据以电视剧案例的形式表示,形成包含2,000条电视剧案例的案例库。
3.1 情境权重设置
-Means算法属于一种成熟的聚类方法[32],以数据的均值作为对象集的聚类中心,均值体现了数据集的整体特征,从而可以达到掩盖数据本身特性的目的。-Means算法的基本思想是选取个数据对象作为初始聚类中心,通过迭代将数据对象划分到不同的簇中,使簇内部对象之间的相似度很大,而簇之间对象的相似度很小,-Means算法是理论上可靠、应用上高效的聚类方法[33]。应用-Means算法需要首先确定分类数,的确定直接影响最终的聚类结果。通常可以采用聚类优度的方法来选择出最优类别数。本文选取2000个案例样本,分别选取类别数1到20进行测试,并比较各类别下的聚类优度。结果显示,在类别数小于等于3时候,随着类别数的更加,聚类效果越来越好(类别为3时聚类优度为96.0%);但是当类别数大于3时,聚类效果基本不再提高。因此,本文选择类别数3,即将案例库中的案例分为三类。
根据信息增益法某一次计算出的情境权重值如表1所示。因利用信息增益确定情境权重随案例库变化而变化,在后续实验中每次选取不同的训练集来训练出各情境的权重,每一次实验中权重取值不同。

表1 情境权重计算结果
以案例库作为原始数据计算出各情境不同取值的情境系数。以外部情境为例,其情境系数某一次计算结果如表2所示。由于情境系数的取值随案例库的变化而变化,因此在后续实验中,每次实验将训练出不同的情境系数。

表2 外部情境调整系数表
3.2 检索阈值设置
在案例检索阶段,需设定检索阈值,即只有当案例库中源案例与目标案例的相似度大于该阈值时,源案例才会被检索出来。对于案例推理求解过程,检索阈值的设定尤为重要,其决定着目标案例的求解结果。若针对目标案例的各情境取值,能在案例库中检索出相似度大于检索阈值的案例,则该目标案例求解成功,否则目标案例求解失败。因此,本文对检索阈值的设定进行对比实验,以期找到使案例检索效果最佳的检索阈值。这里,以查全率(Recall)和查准率(Precision)来衡量案例检索的效果。
设为案例库中与目标案例真实相似的案例集合,是检索出的与目标案例相似的案例集合,则:

首先将目标案例的问题情境(演员、类型、题材等)和解情境(收视率)同时作为检索条件在案例库中进行检索,找出案例库T中与目标案例真实相似的案例集合。真实相似是指除案例的各内外部情境相似之外,其实际收视率也相似。在案例检索中,检索阈值的确定不仅影响到案例检索的结果,对查全率和查准率也产生直接影响,选择合适的检索阈值非常重要。本文在原始案例库中选择5%的案例进行测试,计算其在不同检索阈值下的平均查全率与平均查准率,相关实验结果如图3所示。
Figure 3 The recall and precision rates under different retrieval thresholds
从图3可看出,当相似度阈值设置在0.87附近时,查全率与查准率达到一个基本平衡的点,在该点上案例检索的查全率与查准率均接近0.50。由于案例检索阶段的目标是得到高查准率的检索效果,要获得较高查准率就要提高检索阈值,而检索阈值的提高又会导致案例推理求解失败率的上升。为得到较好的求解和预测效果,特别针对大于平衡点相似度阈值下的推理失败率进行对比,如图4所示。

图4 针对不同检索阈值设置的推理失败率
Figure 4 The reasoning failure rates under different retrieval threshold settings
从图4可看出,当检索阈值小于0.91时,推理失败率为10%;而当检索阈值设置为0.93时,推理失败率上升为40%,进而影响案例推理的求解效果。因此,在保证案例推理求解效果的情况下,为获得较高查准率而设置检索阈值为0.91,此时案例检索的查准率在0.70左右。
3.3 多值情境相似度计算
为验证所提出的多值符号情境相似度计算模式有效性,以查全率与查准率作为评价指标,分别比较使用多值匹配策略与不使用多值匹配策略所获得的查全率与查准率。在原始案例库中选择5%的案例进行测试,得到实验结果如表3所示。

表3 不同多值情境相似度计算模式下的查全率与查准率
从表3可看出,在案例检索阶段进行多值符号情境相似度计算时,使用多值匹配策略时的查全率与查准率均比未使用该策略的查全率与查准率高。这是由于未使用多值匹配策略时,目标案例与源案例的多值情境只要有一个情境值相匹配,该情境的相似度即为1。而针对电视节目案例,类型与题材细微的差别就可能导致收视率的不同。在案例检索时,只有类型与题材的每一个情境取值都匹配时,其局部相似度才为1,否则为一个小于1的数。因此,使用多值匹配策略能更加准确地检索到与目标案例相似的案例。
3.4 重用案例方案选择
案例重用阶段需要对检索出的相似案例进行调整,以得到目标案例的建议解。本文针对重用案例的方案选择,对比分别使用检索出的最相似案例(方案1)与使用相似度最高的前三个案例(方案2)进行重用的播前预测效果。以预测准确率以及准确预测和偏离预测的案例所占比例来衡量预测效果,其中预测准确率=1-|预测收视率-实际收视率|/实际收视率,准确预测表示预测准确率大于或等于60%,偏离预测表示预测收视率和实际收视率相差较大。基于案例库进行十次交叉验证,将2000条案例集合随机分为10份,每次随机选择其中的一份即200条案例作为测试集,其余案例作为训练集用于训练情境权重与调整系数,相关实验结果如图5和表4所示。

图5 选择不同重用案例方案的预测准确率
Figure 5 The prediction accuracy rates under different case reuse schemes

表4 不同重用案例方案下准确预测和偏离预测案例的平均占比
由图5和表4可见,方案1的准确预测案例占比要高于方案2,且预测结果偏离的案例占比要低于方案2,说明方案1优于方案2,因此本文在案例重用阶段选择对检索到的最相似案例进行调整。
3.5 调整规则有效性
为验证所构建调整规则的有效性,特别针对案例重用阶段使用调整规则与未使用调整规则所得到的预测结果进行对比实验。以预测准确率以及准确预测和偏离预测案例的占比为评价指标,十次交叉验证的实验结果如图6和表5所示。
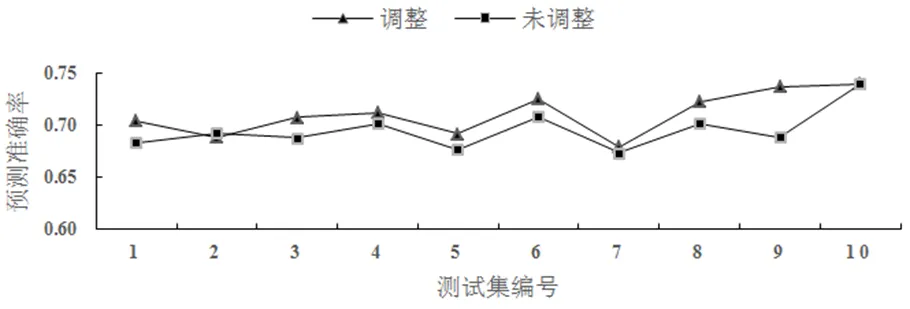
图6 使用调整规则与未使用调整规则的预测准确率
Figure 6 The prediction accuracy rates with and without adjustment rules
从图6和表5可见,当采用调整规则时,收视率预测准确率要高于未使用调整规则的预测准确率,且预测结果中准确案例占比较高,而偏离案例占比略高。因此,案例重用阶段使用调整规则得到的预测结果更佳。

表5 使用调整规则与未使用调整规则的平均预测结果
3.6 整体性能评估
为验证基于案例推理的电视节目播前收视率预测方法的有效性,本文针对整体性能进行十次交叉验证,交叉验证可以在一定程度上避免过拟合问题[34][35],随着交叉验证重数的增加,误差总量度的均值与误差减小,验证样本的正确率增加。因此,交叉验证可以有效避免陷入局部最小与过拟合。实验结果如表6所示。
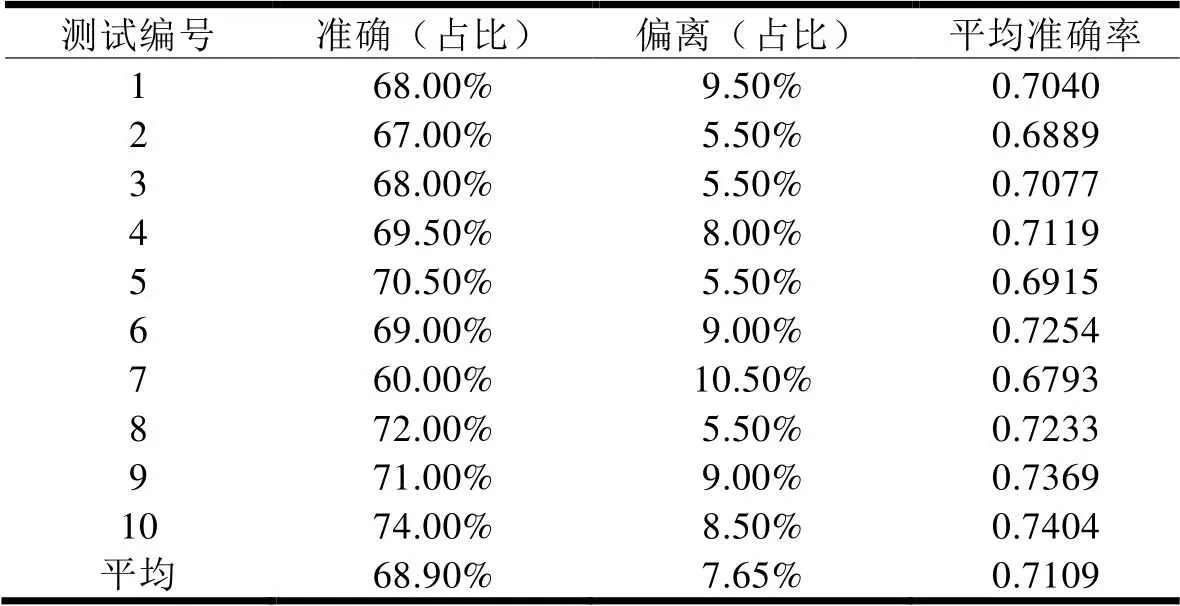
表6 针对整体性能的十次交叉验证实验结果
以一次测试中200条案例为例,实际收视率和预测收视率的对比曲线如图7所示。

图7 实际收视率与预测收视率对比图
Figure 7 The comparison results between actual and predicted audience ratings
由上述实验结果,在进行电视节目的播前收视率预测时,基于情境案例推理的播前收视率预测机制的平均准确率可达71.09%,其中准确预测案例平均占比为68.9%,预测偏离案例平均占比为7.65%,基于案例推理技术的电视节目播前收视率预测模型具有良好的泛化能力。通过对产生预测偏离的情况进行分析,发现其主要归因于案例情境的选择与情境权重的确定还需进一步优化。在播前预测准确率方面,虽然所提出方法的预测准确率未如小安妮节目分析系统的预测准确率(85%)高,但小安妮系统需要构建看片室,组织受试的观众观看样片,同时需要仪器记录观众的情绪反应,这样的播前测试方式和预测过程比较复杂而且预测成本也相对较高[36]。基于情境案例推理的播前收视率预测方法,利用历史收视数据构建电视节目播前收视率预测模型,可以直接根据目标电视节目各情境的取值在案例库中进行检索与匹配,通过对最相似案例收视率的调整得到目标电视节目收视率的预测值,相对于小安妮系统来说,能够在很大程度上节约预测成本并显著提高预测效率。另外,从理论上讲,本文预测方法也可以用于节目未制作完成之时,即可为制片机构提供借鉴。
4 结论
本文采用基于情境案例推理方法进行电视节目播前收视率预测的研究,将心理学和知识管理领域的情境概念引入至案例表达中,建立电视节目案例表达的多层次情境结构,面向案例检索而提出多值符号情境的局部相似度计算策略,以媒体公司的标准收视指标为参考而构造基于差异情境的情境系数调整规则。该方法不仅能够有效解决传统的播前收视率预测方法成本偏高、预测效率偏低的问题,而且能够得到较为理想的预测效果。本文的研究成果不仅能够帮助电视台在电视节目交易之前把握其潜在市场价值,进行合理购买而降低投资风险和电视节目经营风险,还可以根据预测结果搭建一套合理、有效的节目编排体系,从而提高电视台的经济效益;同时也能帮助广告商进行时段价值评估,预判电视节目的广告传播价值,为广告商的广告投放计划提供有益的决策依据;另外能够为节目制作及定位提供参考,帮助制片机构预测节目的市场前景,在一定程度上降低投资风险;最后,还可以为运营商实施电视节目智能推送提供参考。
在当今的大数据时代,本文基于情境案例推理进行电视节目播前收视率预测的方法,采用数据驱动策略进行播前预测,不仅为有效预测电视节目收视率提供了一条新的途径,而且对网络视频、电影等数字节目的预测也具有一定的借鉴意义。后续研究工作包括:首先,针对案例库构建的特征选择以及案例检索策略优化还可以做进一步的深入研究,以期获得更好的播前预测性能;其次,本文仅分析了华东地区的收视数据源,未来可以进一步增大样本量,延长时间跨度,丰富数据特征,进行更大规模的收视率趋势研究。
[1] 邢亚彬, 史兹国. 大数据背景下江苏有线电视收视率预测[J]. 江苏社会科学, 2015, (3): 257-265.
Xing Y B, Shi Z G. A cable television (CATV) audience rating forecast in Jiangsu province in the context of big data [J]. Jiangsu Social Sciences, 2015, (3): 257-265.
[2] 陈青, 薛惠锋, 闫莉. 基于半模糊核聚类算法的收视率预测研究[J]. 计算机工程与应用, 2012, 48(6): 151-154.
Chen Q, Xue H F, Yan L. Study on audio rating prediction based on semi-fuzzy kernel clustering algorithm. Computer Engineering and Applications, 2012, 48(6): 151-154.
[3] 张茜, 吴超, 乔晗, 等. 基于TEL@I方法论的中国季播电视综艺节目收视率预测[J]. 系统工程理论与实践, 2016, 36(11): 2905-2914.
Zhang Q, Wu C, Qiao H, et al. Forecasting audience ratings of China’s seasonal entertainment TV shows based on TEI@I methodology [J]. Systems Engineering -Theory & Practice, 2016, 36(11): 2905-2914.
[4] Cheng Y H, Wu C M, Ku T, et al. A predicting model of TV audience rating based on the facebook [A]. in: International Conference on Social Computing [C], USA: IEEE, 2014. 1034- 1037.
[5] 姚芳, 李越, 肖春来. 基于时间序列模型的全国30家电台收视率分析[J]. 数学的实践与认识, 2011, 41(13): 34-39.
Yao F, Li Y, Xiao C L. Based on time series the analysis of TV ratings of 30 TV channels [J]. Mathematics in Practice and Theory, 2011, 41(13): 34-39.
[6] Danaher P J, Dagger T S, Smith M S. Forecasting television ratings [J]. International Journal of Forecasting, 2011, 27(4): 1215-1240.
[7] 王炼, 贾建民. 基于网络搜索的票房预测模型-来自中国电影市场的证据[J]. 系统工程理论与实践, 2014, 34(12): 3079-3090.
Wang L, Jia J M. Forecasting box office performance based on online search: evidence from Chinese movie industry [J]. Systems Engineering — Theory & Practice, 2014, 34(12): 3079-3090.
[8] Fukushima Y, Yamasaki T, Aizawa K. Audience ratings prediction of TV dramas based on the cast and their popularity [A]. In: IEEE Second International Conference on Multimedia Big Data [C]. USA: IEEE Computer Society, 2016. 279-286.
[9] Hunter S D, Breen Y P. W(h)ither the full season: An empirical model for predicting the duration of new television series’ first season [J]. Advances in Journalism & Communication, 2017, 05(2): 83-97.
[10] 张方红, 李浩, 张明辉. 基于时间序列模型的收视率研究[J]. 中国传媒大学学报(自然科学版), 2015, 22(3): 35-39.
Zhang F H, Li H, Zhang M H. Study on the ratings based on time sequence model [J]. Journal of Communication University of China (Science and Technology), 2015, 22(3): 35-39.
[11] 陈青, 薛惠锋. 改进P-SVM收视率预测方法及其应用研究[J]. 西安工业大学学报, 2011, 31(6): 535-542.
Chen Q, Xue H F. Modified potential support vector machine and its application in predicting audience rating [J]. Journal of Xi’an Technological University, 2011, 31(6): 535-542.
[12] Navarathna R, Carr P, Lucey P, et al. Estimating audience engagement to predict movie ratings [J]. IEEE Transactions on Affective Computing, 2017, PP(99): 1-11.
[13] Quellec G, Lamard M, Bekri L, et al. Medical case retrieval from a committee of decision trees.[J]. IEEE Transactions on Information Technology in Biomedicine, 2010, 14(5):1227-1235.
[14] Prakash S, Darbari M. ‘Quality & Popularity’ prediction modeling of TV programme through fuzzy QFD approach [J]. Journal of Advances in Information Technology, 2012, 3(2): 77-90.
[15] Danaher P, Dagger T. Using a nested logit model to forecast television ratings [J]. International Journal of Forecasting, 2012, 28(3):607-622.
[16] 邬丽云, 曲洲青. 基于BP神经网络的收视率预测[J]. 中国传媒大学学报(自然科学版), 2011, 18(3): 59-62.
Wu L Y, Qu Z Q. The prediction of audience rating research based on BP networks [J]. Journal of Communication University of China (Science and Technology), 2011, 18(3): 59-62.
[17] 李思屈, 诸葛达维. 认知神经科学方法在媒体效果测评中的应用研究——以电视剧收视率预测为例[J]. 现代传播(中国传媒大学学报), 2016, 9: 37-43.
Li S Q, Zhuge D W. The application of cognitive neuroscience in media effectiveness evaluation: a case study of TV audience rating prediction [J]. Modern Communication (Journal of Communication University of China), 2016, 9: 37-43.
[18] Iii SDH, Chinta R, Smith S, et al. Moneyball for TV: a model for forecasting the audience of new dramatic television series [J]. Studies in Media & Communication, 2016, 4(2): 13-22.
[19] Ferro R, Hernández C, Puerta G. Rating prediction in a platform IPTV through an ARIMA model [J]. International Journal of Engineering and Technology, 2016, 7(6): 2018-2029.
[20] Richter M M, Weber R O. Case-based reasoning: A text book [M]. Germany: Springer, 2013.
[21] 赵辉, 严爱军, 王普. 提高案例推理分类器的可靠性研究[J]. 自动化学报, 2014, 40(9): 2029-2036.
Zhao H, Yan A J, Wang P. On improving reliability of case-based reasoning classifier [J]. Acta Automatica Sinica, 2014, 40(9): 2029-2036.
[22] 赵卫东, 盛昭瀚. 基于快速模拟退火的案例检索模型研究[J]. 管理工程学报, 2001, 15(1): 77-79.
Zhao W D, Shang Z H. Research on case retrieval model based on fast simulated annealing [J]. Journal of Industrial Engineering and Engineering Management, 2001, 15(1): 77-79.
[23] Fan Z P, Li Y H, Wang X,et al. Hybrid similarity measure for case retrieval in CBR and its application to emergency response towards gas explosion [J]. Expert Systems with Applications, 2014, 41(5):2526-2534.
[24] 严爱军, 赵辉, 王普. 基于可信度阈值优化的案例推理评价分类方法[J]. 控制与决策, 2016, 31(6): 1253-1257.
Yan A J, Zhao H, Wang P. Trustworthiness evaluation method with threshold optimization for case-based reasoning classification [J]. Control and Decision, 2016, 31(6): 1253-1257.
[25] 路云, 吴应宇, 达庆利. 基于案例推理技术的企业可持续竞争能力的模型建立与应用[J]. 管理工程学报, 2005, 19(3): 1-5.
Lu Y, Wu Y Y, Da Q L. A sustainable competitive power model of enterprise based on case-based reasoning [J]. Journal of Industrial Engineering and Engineering Management, 2005, 19(3): 1-5.
[26] 钱静, 刘奕, 刘呈, 等. 案例分析的多维情景空间方法及其在情景推演中的应用[J]. 系统工程理论与实践, 2015, 35(10): 2588-2595.
Qian J, Liu Y, Liu C,et al. Study on case analysis and scenario deduction based on multi-dimensional scenario space method [J]. Systems Engineering - Theory & Practice, 2015, 35(10): 2588-2595.
[27] 吴登生, 李建平, 孙晓蕾. 基于加权案例推理模型族的软件成本SVR组合估算[J]. 管理工程学报, 2015, 29(2): 210-216.
Wu D S, Li J P, Sun X L. Combination estimation of software effort by support vector regression based on multiple case-based reasoning with optimized weight [J]. Journal of Industrial Engineering and Engineering Management, 2015, 29(2): 210-216.
[28] 徐燕, 李锦涛, 王斌, 等.文本分类中特征选择的约束研究[J]. 计算机研究与发展, 2008, 45(4): 596-602.
Xu Y, Li J T, Wang B,et al. A study on constraints for feature selection in text categorization [J]. Journal of Compution Research and Development, 2008, 45(4): 596-602.
[29] Qi J, Hu J, Peng Y H, et al. A case retrieval method combined with similarity measurement and multi-criteria decision making for concurrent design [J]. Expert Systems with Applications, 2009, 36(7): 10357-10366.
[30] Finnie G, Sun Z. R5 model for case-based reasoning [J]. Knowledge -Based Systems, 2003, 16(1):59-65.
[31] Tsymbal A, Huber M, Zhou S K. Learning discriminative distance functions for case retrieval and decision support [J]. Transactions on Case-Based Reasoning, 2010, 3(1): 1-16.
[32] Kumar K M, Reddy ARM. An efficient-means clustering filtering algorithm using density based initial cluster centers [J]. Information Sciences, 2017, 418–419, 286-301.
[33] 邵必林, 边根庆, 张维琪, 等.采用-均值聚类算法的资源搜索模型研究[J].西安交通大学学报,2012, 46(10): 55-59.
Shao B L, Bian G Q, Zhang W Q, et al. A resource search model using-means clustering analysis [J]. Journal of Xi’an Jiaotong University, 2012, 46(10): 55-59.
[34] Faber N M, Rajkó R. How to avoid over-fitting in multivariate calibration-The conventional validation approach and an alternative [J]. Analytica Chimica Acta , 2007, 595 (1): 98-106.
[35] Kokkinos Y, Margaritis K G. Managing the computational cost of model selection and cross-validation in extreme learning machines via Cholesky, SVD, QR and eigen decompositions [J]. Neurocomputing, 2018, 295: 29-45.
[36] 洪皓轶. 电视剧收视率预估的市场化操作模式构建探析[J]. 电视研究, 2013, (2): 71-73.
Hong H Y. Analysis on the construction of market - oriented operation mode of TV series audience rating prediction [J]. TV Research, 2013, (2): 71-73.
Audience rating predication before broadcasting based on context case-based reasoning
ZHANG Tao1, WENG Kangnian1, ZHANG Qianfan1*, ZHANG Yuejie2
(1. School of Information Management and Engineering, Shanghai Key Laboratory of Financial Information Technology, Shanghai University of Finance and Economics, Shanghai 200433, China;2. School of Computer Science, Shanghai Key Laboratory of Intelligent Information Processing, Fudan University, Shanghai 200433, China)
In the early 1990s, China's television industry began to change from "integration of production and broadcasting" to "separation of production and broadcasting". As broadcast institutions, Television stations need to buy the right or copyright of television programs from production companies. The accurate audience rating prediction of the pre-broadcast ratings of TV programs can help TV stations to make reasonable purchases of TV programs, reducing investment risks and operating risks of TV programs. At the same time, the audience rating prediction of pre-broadcast ratings can also provide a basis for advertisers to formulate advertising strategies. Therefore, it is of great significance to study the audience rating prediction of TV ratings before broadcasting.
This paper studies the pre-broadcast audience ratings prediction method based on situational case reasoning, makes full use of the accumulated historical ratings data, and uses the matching and reuse of historical TV program cases and new program cases to predict the pre-broadcast audience ratings of new programs to make up the shortcomings of high cost and low efficiency for the traditional rating prediction method, and provide new ideas for the prediction of pre-broadcast ratings of TV programs. The main research work of this paper includes the following three aspects: 1) In view of the strong structural characteristics of TV programs, the framework method is used to construct an effective and reasonable case representation for TV programs, which is conducive to the further expansion of case knowledge. At the same time, introducing psychology and the context of knowledge managements a specific form of expression of the case, we build a multi-level context structure of TV drama case expression that blends internal and external context; 2) In the case retrieval, firstly the distance between the target case and the source case is calculated, the distance between the two cases according to the weight of each situation is then calculated, so as to obtain the similarity between the two cases. For the multi-valued context that exists in the TV program case expression, we construct a local similarity measurement method for the multi-value symbolic context, that is, multi-value matching strategy; 3) Case reuse is the difficult part in case-based reasoning, which is mainly attributed to its domain dependence. For the case matching of the target case and similar cases in case reuse, we construct a context coefficient adjustment rule based on the difference context, that is, according to the context matching of the target case and the most similar case retrieved, the solution of the difference context is used to adjust the solution of the most similar case to obtain the proposed solution of the target case.
Finally, based on the 8-month audience rating data of East China region, this paper uses TV drama ratings as a specific case for experimental analysis. The results show that when calculating the similarity between the target case and the source case in the case retrieval phase, for the calculation of similarity degree of the multi-valued symbolic situation, the recall rate and the precision rate with using the multi-value matching strategy are higher than those without using the strategy; when the adjustment rules are adopted, the prediction accuracy rate of the ratings is higher than that without such rules, and the proportion of accurate cases and deviation cases in the prediction results is higher; from the overall performance test, it can be seen that the pre-broadcast audience ratings prediction model proposed in this paper has achieved good prediction results and demonstrated its effectiveness and rationality.
Predicting the ratings of TV programs based on case-base reasoning and adopting a data-driven strategy to predict the broadcasts not only provides a new way to effectively predict the ratings of TV programs, but also it has certain reference significance for predicting digital programs such as online videos and movies.
Subsequent work will further study the feature selection of case-base construction and case retrieval strategy optimization to obtain better pre-broadcast prediction performance; in the future, we can further increase the sample size, extend the time span, enrich data features, and conduct larger scale of ratings trend research.
Audience rating prediction before broadcasting; Case-based reasoning; Multi-value context; Case retrieval; Case reuse
TP39
A
1004-6062(2020)06-0156-009
10.13587/j.cnki.jieem.2020.06.016
2018-06-07
2019-05-27
This work is supported by the National Natural Science Fund of China under Grant (61572140), the Humanities and Social Sciences Planning Fund of Ministry of education of China under Grant ( 19YJA630116), the Natural Science Fund of Shanghai under Grant (19ZR1417200) and the Shanghai Municipal R&D Foundation under Grant ( 17DZ1100504)
2018-06-07
2019-05-27
国家自然科学基金资助项目(61572140);教育部人文社会科学研究规划基金资助项目(19YJA630116);上海市自然科学基金资助项目(19ZR1417200);上海市“科技创新行动计划”资助项目(17DZ1100504)
张倩帆(1992—),女,云南临沧人;硕士生;研究方向:数据挖掘、智能优化算法。
中文编辑:杜 健;英文编辑:Boping Yan
