基于网络爬虫的电商评价数据可视化
2020-11-06孙媛张俊芳
孙媛 张俊芳


摘 要:文章通过网络爬虫数据采集方式获取电商平台《弟子规》书籍的评价数据,利用Python的jieba中文分词组件对电商评价文本数据进行分词、去除停用词、词频统计等数据处理,采用词云图的形式将用户评价信息进行数据可视化展现,试图帮助人们了解数据背后的价值。从大量网络评论中提取反映评论褒贬极性的特质词语,避免消费者所需信息被大量的评论噪音掩盖,从而为消费者的购买决策和企业的营销策略提供支持。
关键词:网络爬虫;弟子规;数据可视化
中图分类号:TP391.1;TP277 文献标识码:A 文章编号:2096-4706(2020)12-0095-03
Abstract:This paper obtains the evaluation data of the e-commerce platform “Di Zi Gui” through the data collection of web crawler,uses Python jieba Chinese word segmentation component to process the e-commerce evaluation text data,such as word segmentation,removal of stop words,word frequency statistics,etc.,and uses the word cloud chart to visualize the user evaluation information,trying to help people understand the price behind the data. From a large number of online reviews,the characteristic words reflecting the polarity of reviews are extracted. In order to avoid the information that consumers need to be covered by a large number of comments noise,it can provide support for consumerspurchase decisions and enterprisesmarketing strategies.
Keywords:web crawler;Di Zi Gui;data visualization
0 引 言
如今,網上购物已成为大众生活中的重要消费途径之一。人们在电商平台浏览、购买商品,随之产生的是海量用户行为数据,如对产品的评价数据。这些线上评论数据的根据是消费者购买并使用产品后的自身感受,数据间接地反映了所购买的商品或服务的实用性、质量、性价比、适用群体等内容。面对这些碎片化、非结构化、信息量密集的数据,可利用网络爬虫这种互联网数据收集方式,爬取电商平台的用户评价数据,为电商商品的评价情感分析提供数据支撑。
根据西安交通工程学院“思想品德优、专业基础实、实践能力强、综合素质高、具有创新精神和社会责任感”的人才培养目标定位,及中兴通信学院大数据管理与应用专业的建设需求,结合作者在数据可视化领域的发展方向,本文将以京东平台《弟子规》书籍评价为例,阐述数据采集、预处理和可视化过程。希望通过本项目的研究,使作者掌握扎实的专业知识,为更好地进行教育教学做铺垫。
1 背景与目标
大数据技术是信息技术几十年发展和积累催生的产物。目前,网络购物盛行、产品竞争激烈、用户体验度要求高、产品评论信息价值高,这是大数据时代对电商领域发起的挑战,也是电商领域发展的动力和前进的方向。《弟子规》作为热门国学经典,讲述了丰富深刻的人生哲理,可以潜移默化地培养孩子的文化修养。该书籍深受家长和孩子们的喜爱,因而在京东平台的销量高。作为销售商,需要根据消费者海量的评论文本数据更好地了解用户的个人喜好,从而提高书籍质量、改善服务,获取市场上的竞争优势。而作为消费者,需要在没有看到书籍实体、做出购买决策之前,根据其他购买者的评论了解书籍的质量、性价比等信息,为购物抉择提供参考依据。
本文对《弟子规》书籍评价数据的分析流程如图1所示。
因此,本文研究的目标是获得产品评价数据、进行数据处理并将结果直观地展示出来,为销售商和消费者们提供依据。通过网络爬虫采集数据,采集到的数据为文本形式的非结构化数据,数据预处理包含中文分词、去除停用词和词频统计,数据可视化利用词云图将用户评论的文本数据中出现频率较高的词提取出来,将用户评价数据通过丰富的图形或图像进行内容展示。
2 数据分析实战
2.1 数据爬取
《弟子规》书籍下的评价数据为网络文本数据,通过网络爬虫采集数据,过程即像蜘蛛一样在互联网上“爬行”,先“爬”至评价网页上,然后把需要的评价数据“铲”下来,将数据存储到本地。
在对网络文本数据爬取的过程中,首先需要了解数据获取方法,然后利用PyCharm编辑器编写代码,通过网络爬虫的方法模拟浏览器发送请求、提取有用信息、将提取到的数据存储在本地,其数据获取的具体过程如下。
2.1.1 了解数据获取方法
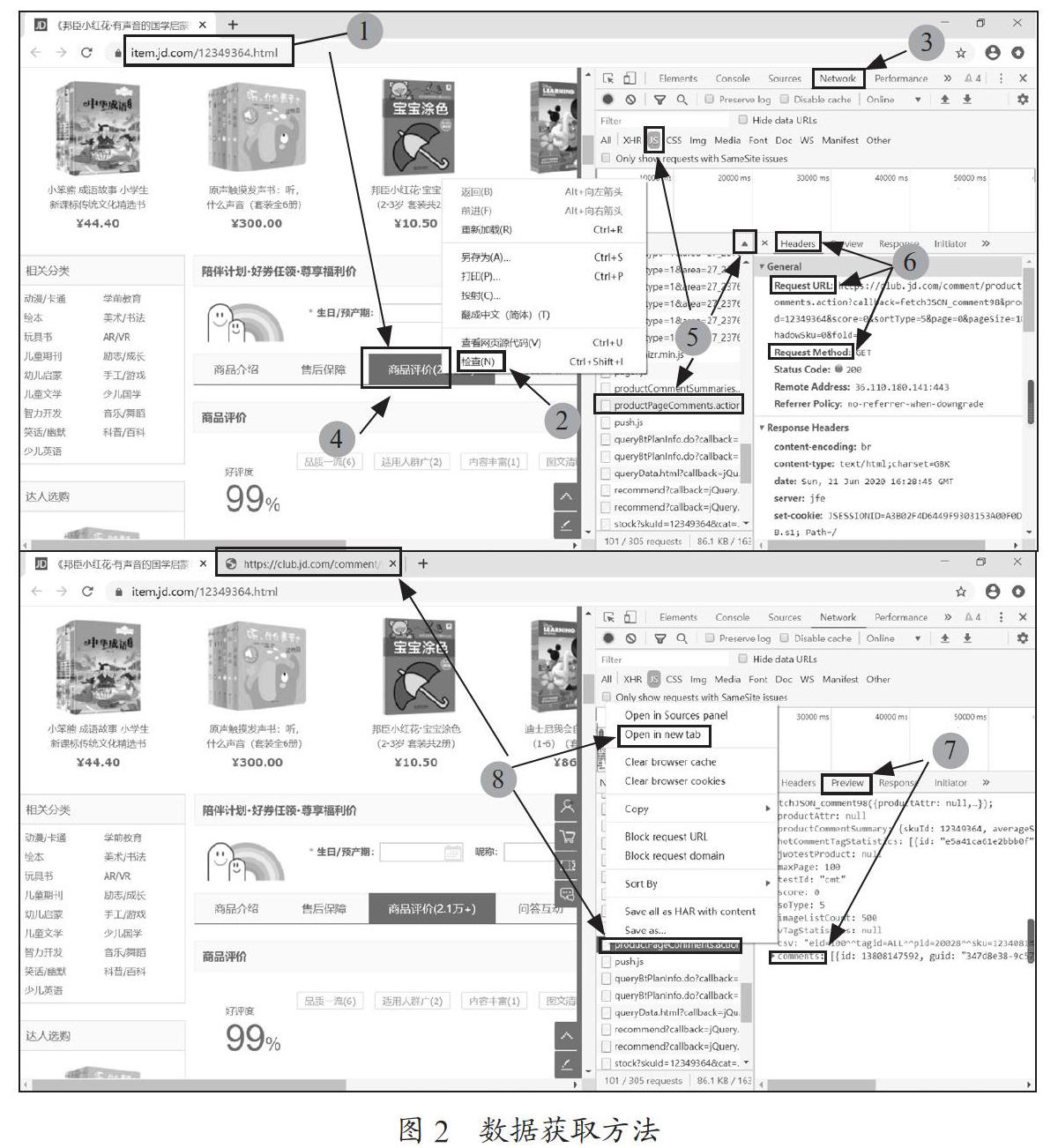
(1)打开京东商城,搜索《弟子规》,以销量排名靠前的书籍为例,点击商品评价。
(2)单击右键,点击检查,借助谷歌浏览器的Web开发者工具找到评论数据存放的位置。
(3)打开网络(Network)面板,可以看到从网络上下载资源的实时信息。
(4)单击商品评价信息并刷新,可看到网络(Network)面板显示加载出来的资源。
(5)单击JS,通过name排序或size排序找到product-PageComments.action。
(6)在右侧显示Headers标签下的Request URL和Request Method。
(7)在右侧显示Preview标签下的comments资源具体内容。
(8)右键点击productPageComments.action,选择Open in new tab,可在新标签页更仔细地查看该资源。
上述数据获取方法的具体操作过程,如图2所示。
2.1.2 采集评论数据
(1)模拟浏览器发送请求。首先使用GET方法向url= f'https://club.jd.com/comment/productPageComments.action? callback=fetchJSON_comment98&productId=12349364&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1发送请求并添加表头;然后将编码方式修改为'gbk';再利用JSON将字符串转换为键值对形式的字典。
(2)提取有用信息。获得服务器响应后,提取网站有用信息(用户昵称、产品名、用户评价和发布时间)并组成数据框。其代码为:data_jd = pd.DataFrame ({'nickname': nickname, 'productColor': productColor,'content': content, 'referenceTime': referenceTime})。
(3)数据存儲到本地。采用逆向分析法,利用循环的方式爬取100页(共1 000条)评价数据,将数据保存到本地命名为“弟子规用户评价数据”的Excel表格中,其代码为:all_data.to_excel ('./弟子规用户评价数据.xlsx', index=None)。
2.2 数据预处理
需要对通过爬虫采集到的文本数据进行预处理,具体流程如下。
2.2.1 中文分词
在对数据进行分析之前,需要对采集到的文本数据进行分词处理。所谓的分词其实是将连续的词句按照一定的规范重新排列组合并分割成单个词序列的过程。本文采用基于词典的分词方法,即从左向右取待切分汉语句子的字符并查找词典与之进行匹配,若匹配成功,则将这个匹配字段作为一个词切分出来;若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段再次进行匹配,重复匹配直到切分出所有词为止。
(1)安装Python第三方库——jieba库,在https://github.com/fxsjy/jieba网站中下载jieba并安装,jieba是目前常用的Python中文分词组件。对于一长段文字,首先要用正则表达式将中文段落粗略分成句子,然后寻求最佳切分方案将句子划分为词组。
(2)使用jieba.cut方法进行分词:data_cut = all_data ['content'].apply (jieba.lcut)。
2.2.2 去除停用词
停用词是指文本数据中使用频率不高或对本文特征的表示没有价值的词,如空格、回车、标点符号等。本文首先下载停用词表stoplist.txt,然后在已下载好的停用词表中根据需要手动建立新停用词(空格和换行符号):stop = [' ', '\n'] + stop,进行分词后通过比较停用词将价值不高的词删除。
2.2.3 词频统计
词频统计是对去除停用词之后的每个词组的频率进行统计,为后续数据可视化做铺垫。本文导入Tkinter自带函数_flatten,对去除停用词后的中文词组进行频率统计,其代码为:num = pd.Series (_flatten (list (data_after))).value_counts ()。
2.3 数据可视化
数据可视化可让京东《弟子规》评价信息中挖掘到的价值清晰呈现。本文利用词云图将预处理后的数据根据词组的出现频率直观地展示出来,生成的词云图中词组字体的大小与词组出现的频率成正比。词云图生成过程如下。
(1)下载并安装第三方库——wordcloud库。
(2)设置词云,包括背景颜色、字体路径及背景形状等。
(3)根据词频统计结果,调用Matplotlib.pyplot绘制词云图,其中Matplotlib.pyplot是Python的绘图库,包含了一系列类似MATLAB中绘图函数的相关函数。
词云图生成结果如图3所示。
3 结 论
本文以京东平台《弟子规》书籍评价数据可视化为例,研究网络爬虫的数据采集方式,安装jieba和wordcloud库,实现文本数据的分词、去停用词、词频统计,根据词频统计结果、绘制词云图,完成用户评价文本数据的可视化分析、采用词云图展示用户对该产品的评价。从词云图中可以直观、清晰地看到用户对该产品的评价的高频词语,并能获取以下有用信息。
(1)该产品为书。
(2)多数用户评价为喜欢、质量、不错。
(3)适用对象为宝宝、小朋友、孩子。
(4)多数用户对京东平台价格或物流表示满意等。
总之,对《弟子规》评价数据进行可视化展现,可为消费者提供购买决策,协助商家指导客户购买产品,让商家更好地发现用户的需求,进而改进产品、提升用户体验。
参考文献:
[1] 宋永生,黄蓉美,王军.基于Python的数据分析与可视化平台研究 [J].现代信息科技,2019,3(21):7-9.
[2] 韩宝国,张良均.R语言商务数据分析实战 [M].北京:人民邮电出版社,2018:145-168.
[3] 冯与诘.词云生成系统的构建 [J].通讯世界,2019,26(3):190-192.
[4] 高宇,杨小兵.基于聚焦型网络爬虫的影评获取技术 [J].中国计量大学学报,2018,29(3):299-303.
作者简介:孙媛(1992—),女,汉族,陕西西安人,专职教师,助教,硕士,研究方向:计算机通信。
