基于支持向量机的沥青路面性能评价
2020-11-03赵静王选仓樊振阳王培丞
赵静 王选仓† 樊振阳 王培丞
(1.长安大学 公路学院,陕西 西安 710064;2.长安大学 信息工程学院,陕西 西安 710064)
截止2018年底,我国高速公路养护里程占总里程的97%[1]。2019年9月,中共中央国务院印发了《交通强国建设纲要》,其中指出应大力发展智慧交通,推动大数据、人工智能等新技术与交通行业的深度融合[2]。因此将人工智能技术运用于道路养护工程中迫在眉睫。其中路面性能评价是路面养护的重要环节,也是养护决策与资金投入的依据,因此使用人工智能技术对路面性能进行评价将是道路养护需要重点解决的问题。
在我国,路面性能综合评价是根据《公路技术状况评定标准》(JTG H20—2018)进行的[3],其方法为依据各单项评价指标(不包括弯沉值)与相应权重的乘积通过计算路面技术状况(PQI)值来判断,各分项指标权重是通过结合专家经验判断各指标重要性并结合实际的数据进行综合确定的,以道路的服务功能为首要考虑因素。所以现在的评价方法无法准确客观地反映出路面的整体水平。
为合理地对路面性能进行评价,Fang[4]为了避免主观与不确定性,提出了一种改进的灰色理论灰色聚类原理。Ling等[5]将可拓理论运用在路面性能评价中。Han等[6]建立了分层贝叶斯估计的马尔可夫混合风险模型,结果表明该模型可以很好地完成短期路面使用性能评价。王静[7]调查了甘肃省实际路面主导损害,建立了灰色逼近理想解排序法(TOPSIS)模型对路面性能进行了评价,评价结果更符合甘肃路面性能实际。张威等[8]选取京哈高速指标建立博弈论的路面性能物元可拓评价模型,该模型将德尔菲法与关联函数法结合起来建立静态博弈。李学峰等[9]采用广义有序逻辑回归法建立了沥青路面使用性能评价模型,该方法可以有效解决逻辑回归模型条件的限制。
这些模型研究也存在着各自的不足,如神经网络比较容易发生过学习情况,层次分析法主要依据专家经验确定相应的重要性,因此客观性不强。这使得评价结果的准确性降低。而随着人工智能的兴起,支持向量机(SVM)被普遍地应用于各个领域中。其在分类评价中效果极佳。同时惩罚参数C和核函数g对模型的精度起着至关重要的作用[10],因此本研究采用3种优化模型对支持向量机参数进行优化,得到最好的优化模型。最后,将此模型运用于广东省某高速公路23个路段路面的性能评价中。
1 原理及模型的建立
支持向量机是一种应用广泛的机器学习方法,它的精确性取决于惩罚参数C和核函数g。本研究分别使用参数寻优方面的3种常用的方法(交叉验证(CV)、粒子群算法(PSO)、遗传算法(GA))确定最佳参数。
1.1 支持向量机原理
1992年,Vapnik提出了支持向量机(SVM)[11]。SVM是主要解决分类的模型。传统模型是将数据处理为低维度数据,以便模型建立。而SVM方法是将数据点进行“升维”,通过核函数将样本点映射到高维甚至无穷维空间[12],在高维空间中采用处理线性与非线性问题的方法[13]。
原理可以用图1中的二维情况说明。图中的“●”与“▲”分别代表2类不同样本,H是分类超平面[14]。这两个样本类的平面应满足两个条件:①H1和H2同时平行于H。②H1和H2都为各自类距H平面最远。H1和H2的间隔称为分类距离。最优分类超平面就是让分类超平面H使得和距离最大,并且能将2类不同样本正确分开(训练错误为0)。支持向量(SV)是离最佳分类超平面最近的向量[15]。假设每一个路段为一个点,其相应的检测指标为其属性。
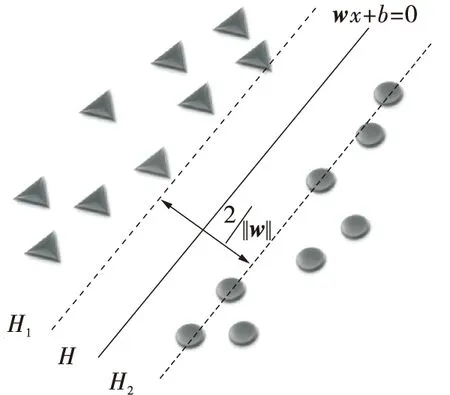
图1 最佳分类超平面图Fig.1 Best classification super plan
1.1.1 线性分类
假如分类数据为n维向量,某区间的l个样本及这个区间可能的类为:(xi,yi),i=1,2,…,l,xi∈Rn,yi∈{1,-1)}l,R为实数集,H表示为
wxi+b=0
(1)
其中:w为超平面法线向量,b为分类直线的偏移量。显然,式(1)中w和b乘以系数后仍满足方程。不失一般性,设对所有样本x满足下列不等式:
(2)
可将上述不平等合并为如下不等式:
yi(wxi+b)≥1,i=1,2,…,l
(3)
此时分类间隔为2/‖w‖,要使‖w‖2/2最小并满足yi(wxi+b)≥1,i=1,2,…,l,求解最佳分类平面H便改为求解下面的最优解问题[16]:
(4)
s.t.yi(wxi+b)≥1。
通过Lagrange函数对式(4)进行转化,即
(5)

(6)
1.1.2 非线性分类
实际应用中,会遇到非线性分类超平面情况,此时若依然使用线性划分是不精确的,对于这类问题,超平面已经不能解决这类问题,这时需要求得一个超曲面对数据进行分类[17]。支持向量机通过寻找“最大间隔”来确定最优超平面,但超曲面没有间隔的概念[18]。此时需要通过一个映射,将寻找超曲面的问题转化为寻找超平面的问题,相对图1的线性分类,图2为非线性分类示意图。

图2 非线性分类示意图Fig.2 Schematic diagram of nonlinear classification
由映射函数φ:x→H将样本向量xi映射到高维特征空间H,在空间H中得出最佳超平面。引进核函数K(xi,xj),但函数满足Mercer条件[19],对应变换空间的内积为K(xi,xj)=φ(xi)φ(xj),这可解决“维数灾难”问题。
与第1.1.1节步骤相同,二次规划的目标函数为
L(w,x,b,a,b)=
(7)
其中K(xi,xj)=φ(xi)φ(xj)被称为核函数,则分离超平面表示为
(8)
训练集的最优分类判别函数为
(9)
其中,xi为支持向量,x为未知向量,f(x)为支持向量机。
1.2 最优参数确定
1.2.1 交叉验证
交叉验证是用于验证分类器性能的统计方法,其思想是将训练集进行分组,将一部分作为训练集,一份作为验证集,已得到的分类准确率作为评价分类器性能的指标,最终得到最佳的参数[12]。
1.2.2 粒子群算法
1995年Eberhar与Kennedy提出了一种全局不间断的随机优化技术[20]。粒子群优化算法中,每个粒子都利用其各自的记忆与学习来寻找最优的解[21]。
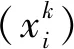
(10)
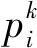
1.2.3 遗传算法
为了得到全局的最优解,遗传算法可通过模仿生物进化过程产生繁殖、变异及选择得到最优解[22]。其具体的寻优支持向量机最佳参数过程大致如下:
(1)首先对训练集训练得到的惩罚参数C与核函数g编码,每一串代码代表一个可行解,用qij表示(生物术语称为基因)。同时产生一个初始种群Q,Q中包含所有的可行解。
(2)计算初始种群的误差函数,确定种群的适应度。
(3)第k个染色体和第l个染色体在第j位进行交叉操作,即式(11)-(12):
qkj=qkj(1-d)+qljd
(11)
qlj=qlj(1-d)+qkjd
(12)
式中:d是区间[0,1]的一个随机常数。
(4)第i个个体的第j个基因qij变异,即
(13)
其中,qmax与qmin分别为qij最大值及最小值,r为[0,1]区间的一个随机常数。
适应度函数为
f(s)=r2(1-s/Gmax)2
(14)
其中,r2为一个随机数,s为迭代次数,Gmax为最大进化次数。
1.3 建模过程
高速公路沥青路面使用性能的合理评价是便于公路管理部门进行养护决策的重要前提,通常路面使用性能所处状态用“优、良、中、次、差”表述,这是一个多分类问题,模型建立步骤如下:
(1)确定训练集、训练集标签和测试集、测试集标签。
训练集:采用评价标准等级,具体方法为:将优、良、中、次、差5个等级中的路面抗滑性能指数(SRI)、路面车辙深度指数(RDI)、路面行驶质量指数(RQI)、路面损坏状况指数(PCI)、路面结构强度指数(PSSI)5项指标,运用Matlab中rand()函数在其对应的区间中产生10个随机数。
训练集标签:评价为优的标签为1,良的标签为2,中的标签为3,次的标签为4,差的标签为5。
测试集:测试集为所要评价路段的SRI、RDI、RQI、PCI等5项指标数据。
测试集标签:按照评价标准计算各个路段的PQI,得到相应的评价等级,为优的标签为1,良的标签为2,中的标签为3,次的标签为4,差的标签为5,用来对比两种评价方法的不同。
(2)选择核函数。本研究的核函数均选择K(x,xi)=exp(-g‖x-xi‖2),g>0。
(3)通过粒子群算法、遗传算法、交叉验证3种方法分别求出最佳参数C和g。

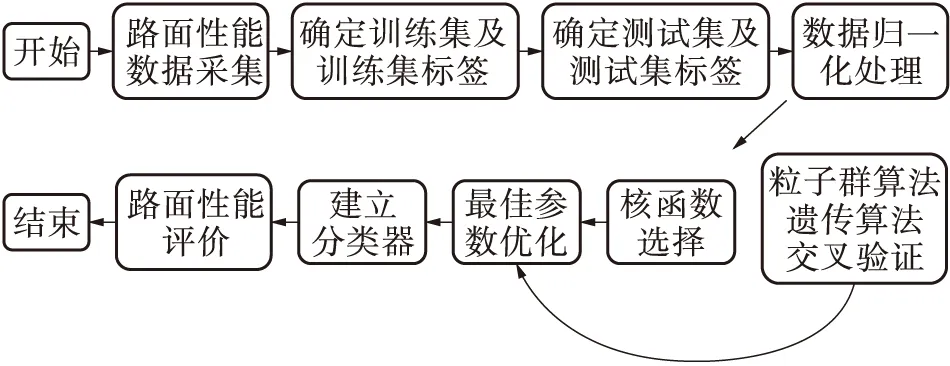
图3 路面性能评价流程图Fig.3 Flow chart of pavement performance evaluation
2 实例分析
2.1 数据采集
本研究以2017年广东省某路段AK53+840—AK87+682的检测数据为例,首先进行聚类分析,将最终的23个养护路段均值按照《公路技术状况评定标准》(JTG H20—2018)计算,并对该段的路面性能进行综合评价。具体数据见表1。
为便于对数据进行分析,本研究对表1对数据可视化处理,见图4。
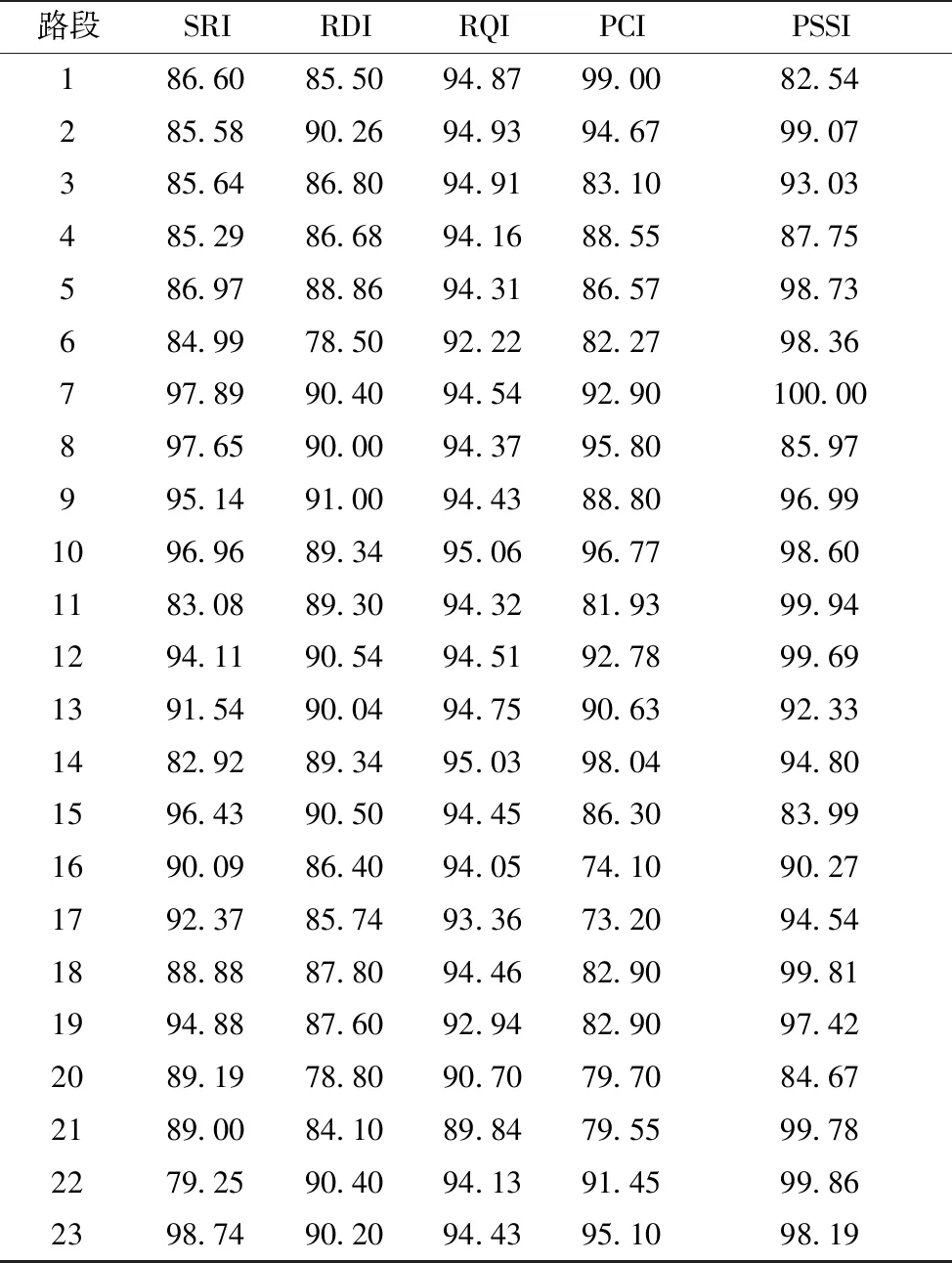
表1 各指标值Table 1 Value of each indicator
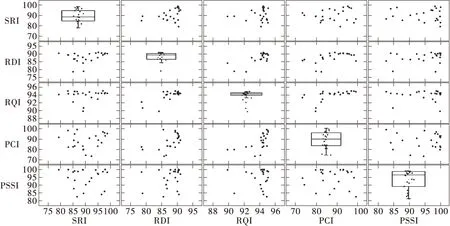
图4 散点图矩阵Fig.4 Scatterplot matrix
在图4中,对角线中的箱线图表示相应指标的分布情况,非对角线的散点图可以看出5指标两两之间的关系。通过SRI、RDI、RQI、PCI、PSSI的23组数据得到的箱式图,笔者很清晰地了解到各指标的最小值、最大值,上、下四分位数以及中位数和异常数据。同时,大部分指标之间都是非线性关系,因此,在分类模型中应选择非线性分类器。
2.2 训练集的确定
以上述的23个养护路段作为测试集,规范评价方法得到的结果为测试集标签。由于表1中各单项指标都大于80,因此,在模型建立时,只选择为优、良、中3个等级。其中,优等的标签为1,良等的标签为2,中等的标签为3。以优等为例,生成的训练集见表2。
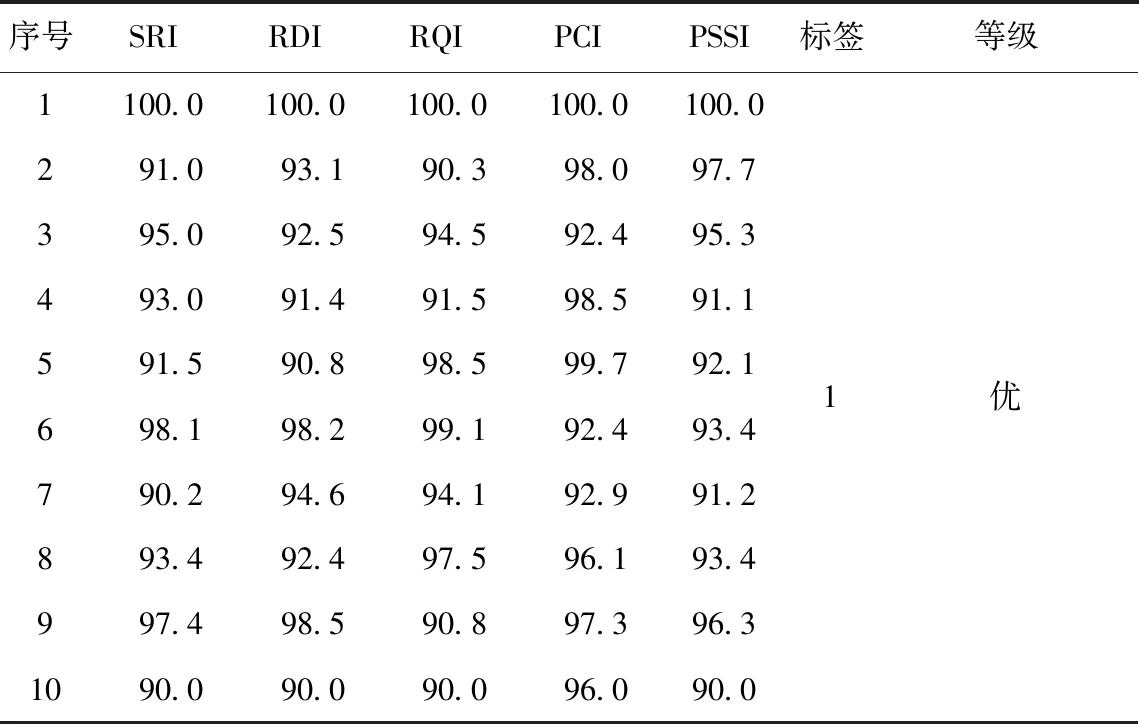
表2 优等训练集及标签Table 2 Excellent training set and label
2.3 最佳参数的优选
对训练集与测试集进行归一化处理,分别采用交叉验证、粒子群算法、遗传算法3种参数优化方法,对第2.2节所确定的训练集进行训练,3种方法分别得到C1与g1,C2与g2,C3与g3。最终得到准确率最大的惩罚参数C与核函数参数g。
2.3.1 交叉验证
采用K-CV模型交叉验证选择最佳的惩罚参数C和函数参数g,如图5所示。首先C1的范围为2-10~210,g1取值范围为2-10~210,最佳惩罚参数C1=0.001,g1=0.001时,准确率为97.00%。
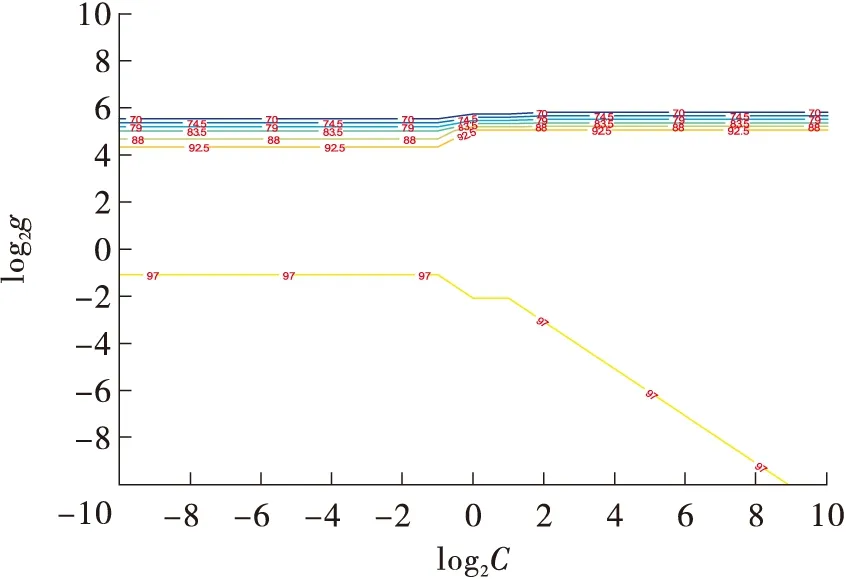
图5 最佳参数初选等高线图Fig.5 Primary selection of optimal parameters contour map
通过初选,如图6所示,将C1取值范围缩小在2-2~22间,g1的取值范围缩小在2-4~20之间,同时降低等高线中变化间隔。最终得出最佳参数C1为0.25,g1为0.062 5,此时准确率最大为99.60%。
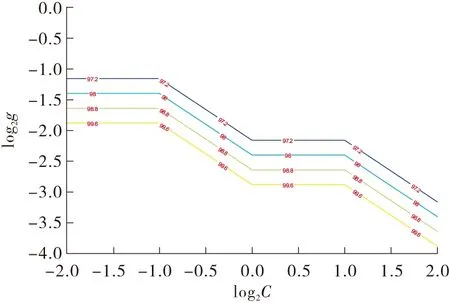
图6 最佳参数的终选等高线图Fig.6 Final selection of optimal parameters contour map
2.3.2 粒子群算法
当迭代次数为200,种群数量20时,粒子群算法的适应度曲线如图7所示,最终得出最佳参数C2为4.858,g2为0.503时,准确率最大为96.67%。
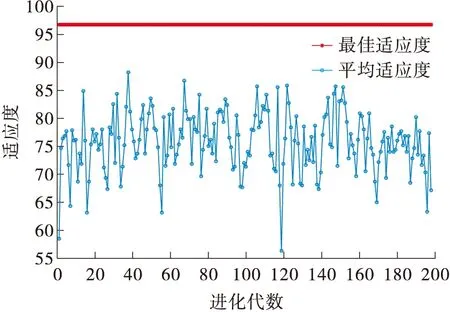
图7 粒子群算法适应度曲线Fig.7 Particle swarm algorithm fitness curve
2.3.3 遗传算法
同样当迭代次数为200,种群数量20时,遗传算法的适应度曲线如图8所示,最终得出最佳参数C3为0.964,g3为0.407,此时准确率为94.77%。

图8 遗传算法适应度曲线Fig.8 Genetic algorithm fitness curve
使用3种模型对训练集进行参数优化,各模型准确率及得到的参数见表3。

表3 3种模型参数优化结果Table 3 Optimization results of three models’ parameters
由表3可知,交叉验证模型得到的准确率最高,粒子群算法次之,遗传算法最差。因此笔者选用交叉验证所得到的最佳参数对路面性能进行评价。
2.4 模型训练
用最佳参数C与g在Matlab的libsvm3.20工具包中对测试集进行测试,结果见图9。
对图9进行分析如下:
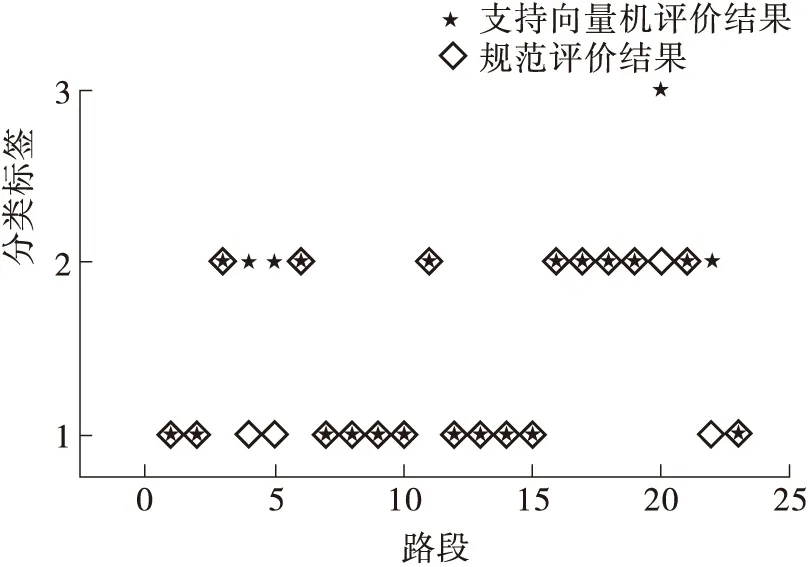
图9 评价结果对比Fig.9 Comparison of evaluation results
(1)在23个养护路段中,有11个养护路段为优等,总长度为16 624 m,优等率为47.06%;有11个养护路段被评为良,总长度为17 704 m,良等率为50.11%;只有养护路段20为中等,总长度为1 000 m,中等率为2.83%。说明这23个养护路段整体性能良好。
(2)通过标准与支持向量机评价模型对比可得,在23个养护路段中,有4个养护路段评价不一致,分别为养护路段4、5、20、22。以养护路段4为例,该养护路段SRI、RDI、PCI、PSSI为85.29、86.77、88.55、87.75,均小于90,但RQI值为94.16,按照标准评价,该养护路段评价为优,而使用支持向量机对该段的评价为良,更符合实际路况。整条高速公路RQI值都落在了94至96这个区间,如若整条高速公路按照这种标准评定,只要其他指标值都大于80,评价结果都可能为优,这显然不合理。因此,使用支持向量机建立的沥青路面综合评价更为合理。
3 结论
针对我国传统《公路技术状况评定标准》(JTG H20—2018)中PQI沥青路面性能综合评价模型的不足,本研究提出了支持向量机沥青路面性能综合评价模型。具体结论如下:
(1)支持向量机分类可应用于沥青路面的综合性能评价,其通过建立最优超平面,寻找最优解,可以很好地反映沥青路面状况。
(2)本研究提出了支持向量机路面性能评价模型训练集的确定方法,即利用等级评价标准进行训练。同时采用交叉验证、粒子群算法、遗传算法3种优化模型对最佳参数进行寻优。其中,交叉验证方法所得到的最佳参数准确率最高为99.96%。
(3)以广东省一条高速公路的23个养护路段为实例,通过与《标准》PQI评价结果进行对比分析可知,支持向量机建立的评价模型更符合实际。
