基于BalanceCascade-GBDT算法的类别不平衡虚假评论识别方法*
2020-11-02陶朝杰
陶朝杰,杨 进
(上海理工大学 理学院, 上海 200093)
1 引 言
近几年,互联网经济不断繁荣,支付手段也在不断优化,越来越多的人选择在网上购物消费.为了寻求性价比更高的商品和服务,或者反馈个人观点以及使用情况,消费者愈加关注线上平台的相关评论.海量的评论逐渐成为能够影响商品销售业绩和用户购买决策的重要因素.正面积极的评论有助于提高商品的声誉,间接提升销售总量;反之,负面消极的评论会降低该商品的竞争力,造成经济损失.因此,有些商家为了追求更高的利润,开始雇佣网络水军发布一些虚假评论来鼓吹自己的产品,或是贬低竞争者的产品.这些虚假评论会误导消费者,造成自由市场的混乱.于是,识别和过滤虚假评论具有重要的现实意义.
根据前人的研究[1],虚假评论通常分成3类:不真实评论,只关注品牌评论和无关评论.其中,不真实评论是指与产品实际情况不相符的评论.只关注品牌评论是只针对品牌、制造商或者销售商而非产品本身的评论.无关评论包括广告和无意义评论(比如问答和随机文本).后两类评论虽然令人厌烦,但普通用户轻易就能识别.第一类评论却因其隐蔽性和多样性等特点难以分辨,因此具有较高的研究价值.
Jindal等人[1]于2008年提出虚假评论识别问题,他们基于评论者信息、评论文本以及商品特征建立模型,用以区分复制观点(虚假评论)和非复制观点(真实评论).Ott等人[2]从心理学和语言学角度出发,提出了一种虚假评论检测方法.宋海霞等人[3]借助评论者的行为特性提出了一种自适应聚类的虚假评论检测方法.Mukherjee等人[4]发现近些年虚假评论发布者们通常以群组的形式出现,于是提出了一种基于群组结构、发布内筒以及行为特征判断虚假评论者的方法.Peng等人[5]在心理学方法的启发下,提出了一种基于情感分析的虚假评论识别方法.
样本类别不平衡不仅严重影响分类器的性能,而且对模型的评价指标也提出了要求.例如,在一个不平衡度为99的问题中,直接将全部样本归为大类.一方面,学习算法在最小化误差训练时可以获得1%的低错误率,这往往导致算法过于重视大类,而忽略了小类.另一方面,虽然分类明显不合理,但其效果可以达到99%的准确率,于是需要选择不受类别影响的评价指标,本文采用AUC值评价模型分类效果.
以往研究中通常采用过采样或欠采样方法解决类别不平衡问题.欠采样方法通常截取部分大类样本进行训练,可能会造成部分信息的丢失.过采样方法则通过重复小类样本或者利用特定算法构造新样本来平衡数据,这会放大噪声,容易造成过拟合.文献[7]提出的BalanceCascade算法是一种欠采样算法,但其利用级联策略不断删减大类样本,最后集成所有基分类器,在整体上利用全部样本数据,弥补了欠采样的固有缺陷.
考虑GBDT模型作为基分类器以满足集成学习中子模型“好而不同”的要求.一方面,GBDT作为一种强化的提升树模型,具有较强的学习能力和泛化能力.另一方面,树模型是样本扰动不稳定模型,能构造多样的基分类器.于是,本文提出了一种基于BalanceCascade-GBDT算法的类别不平衡虚假评论识别方法.在实验中,收集来自拉斯维加斯地区餐饮行业的评论,根据虚假评论的特点构造多维特征,训练BalanceCascade-GBDT模型,然后与逻辑回归、随机森林和神经网络模型得进行对比,实验结果表明,该方法具有更高的AUC值.
2 算法介绍
2.1 GBDT算法
虚假评论识别实质上是一个分类问题,为了得到精度更高的分类结果,需要构造强分类器,而提升树模型在该类问题中效果显著。GBDT[8](Gradient Boosting Decision Tree,梯度提升决策树)由Jerome Friedman于1999年提出.该算法使用了加法模型和前向分步算法,是一种优秀的Boosting算法,多用于预测,适当调整也可用于分类.不同于传统的Adaboost算法利用前一轮迭代中弱学习器的误差率来更新训练样本权重,GBDT的算法思想是在每次迭代中通过拟合残差构建CART回归树模型.Friedman提出使用损失函数的负梯度来代替残差,称为伪残差.GBDT算法是最优秀机器学习算法之一,适用于几乎所有线性或非线性回归问题,广泛应用于各个领域,特别在金融方面已经有许多成功案例.GBDT的具体流程如下.
输入:训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},损失函数为L(y,f(x))=(y-f(x))2
输出:回归树F(x)
1)初始化弱学习器,由于损失函数为平方损失,因此该节点的平均值为最小化损失函数的常数值.
(1)
2)对m=1,2,…,M,有
对i=1,2,…,N,计算伪残差,即负梯度
(2)
将所得的伪残差作为样本值,生成新的训练数据{(x1,rm1),(x2,rm2),…,(xN,rmN)},而后构建新回归树fm(x),其对应的叶子节点区域为Rjm,j=1,2,…,J,其中J为回归树的叶子节点个数.
对j=1,2,…,J,通过线性搜索,计算最佳拟合值
(3)
其中,K表示第m棵树第j个节点的样本数量.
3)得到最终学习器
(4)
2.2 BalanceCascade算法
虚假评论识别过程中真实评论和虚假评论的样本数量不平衡会在一定程度上影响模型的分类效果。BalanceCascade算法受到级联结构启发,可用于解决上述问题.该算法是一种欠采样算法,从大类中随机采样与小类数量相等的样本集,与全部小类组合成训练样本子集.此外,通过在每次迭代中删除部分被正确分类的大类样本使数据趋于平衡.于是,随着越来越多易分类的大类数据被剔除,剩下的多是与小类样本特征相近的.这样一方面能够解决欠采样带来的信息缺失问题,另一方面也可以更加关注难分的样本,挖掘其中的内在规律.算法流程如下.
输入:小类样本集P,大类样本集N,其中|P|<|N|;从N中采样的子集个数T,迭代次数si;训练AdaBoost集成学习器Hi.

步骤2Repeat
步骤3i⟸i+1
步骤4对N随机采样得到子集Ni,其中|Ni|=|P|.
步骤5由P和Ni训练AdaBoost集成学习器Hi,其中弱学习器hi,j的个数为si,相应权重为αi,j.该集成学习器的阈值为θi.公式如下
(5)
步骤6调节阈值θi使得Hi的假正率为f.
步骤7去除N中被Hi正确分类的全部样本.
步骤8Untili=T
步骤9输出:集成学习器
(6)
3 BalanceCascade-GBDT模型
BalanceCascade-GBDT模型主要分成4个步骤:a)产生样本训练集;b)训练基分类器;c)更新大类样本;d)基分类器集成.模型的整体结构如图1所示.

图1 基于BalanceCascade-GBDT算法的类别不平衡虚假评论识别模型整体结构
3.1 产生样本训练集
给定一个小类样本集P和大类样本集N,利用欠采样方法从N中随机不放回地采样子集Ni,其中|Ni|=|P|.该样本集与全部小类样本组合成类别平衡的训练样本子集Ti.
3.2 训练基分类器
集成学习的核心是训练“好而不同”的基学习器,即准确率高且多样化的基学习器.考虑到GBDT是基于提升树模型设计的,而提升树被认为是性能最好的机器学习算法之一,在许多应用场景中都取得了显著的分类效果[9].此外,GBDT作为一种树模型,相较于朴素贝叶斯和支持向量机等样本扰动稳定模型,是一种样本扰动不稳定模型,即不同的训练样本集可以得到明显不同的基分类器,满足多样性要求.
基于训练样本集Ti,通过贝叶斯参数寻优方法设置算法学习率、最大迭代次数、特征采样比等超参数,训练得到性能优异的GBDT基分类器Hi.
3.3 更新大类样本
Hi被训练后,如果样本x∈Ni被Hi正确地归为大类,那么可以合理推测x在Ni中有一定的冗余[7].因此,可以从Ni中删除一些被正确分类的样本.
算法通过设置误报率f在一定程度上控制所删除样本的比例,并调节阈值θi使得f在Hi中得到反映,然后将调整后的GBDT模型对大类样本进行预测,删除其中被正确分类的,最后得到新的大类样本集Ni+1.
3.4 基分类器集成
重复以上3个步骤,可以得到一组相异的GBDT基分类器,使用合适的集成方法将它们进行组合.本文通过对全部基分类器的预测概率采用简单平均法,并设置阈值进行分类.
给定样本x=(x1,x2,…,xn),xi∈Rm,集成模型有m个基分类器H1(x),H2(x),…,Hm(x),则对于样本x,其集成输出的结果为
(7)
4 实证分析
4.1 实验数据集
虚假评论研究的一个重要难题是无法获得标准的标注数据集.而进行人工标注具有主观性,或多或少会存在误差.本文利用爬虫技术从美国版大众点评网站Yelp上抓取拉斯维加斯地区餐饮行业的评论信息.该网站会利用自身的检测系统过滤虚假评论,其中真实评论会显示在主界面上,而虚假评论则隐藏在底部的折叠页面中.通过上述方式,利用Yelp网站上的过滤系统对所有评论进行标注.
通过整理,从Yelp网站上共爬取12402条评论,以及508071条相关评论(包括255530条店铺历史评论和252541条用户历史评论).具体实验数据如表1所示.

表1 实验数据集
4.2 特征工程
根据文献[10]中整理的虚假评论特征,基于所爬取的数据建立多维特征模型,并将其分成评论文本特征和用户行为特征.前者从评论文本的内容,包括词性,词义以及语法角度对评论进行挖掘.后者通过用户行为特征确定虚假评论用户,间接判断该评论的真实性.具体特征如表2所示.
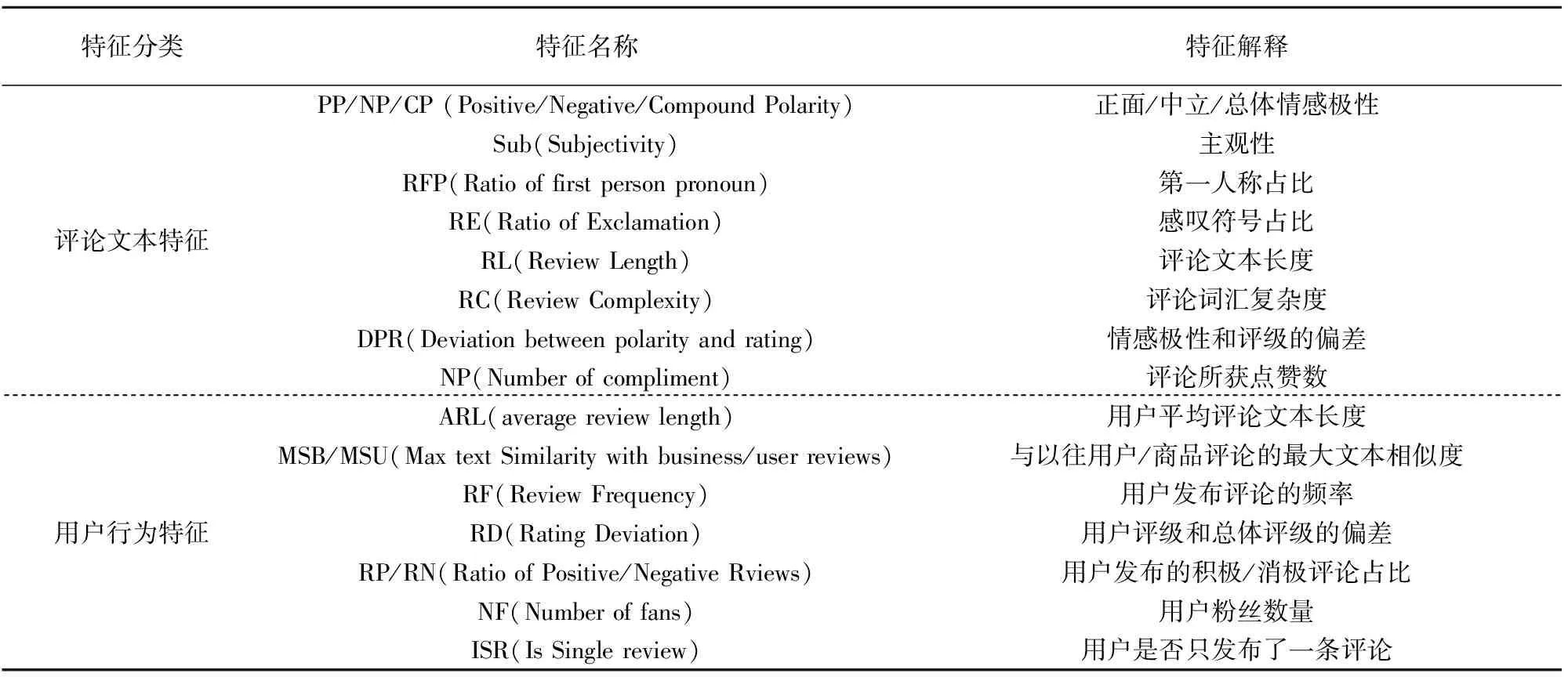
表2 评论文本特征和用户行为特征
4.3 数据预处理
由于支持向量机等分类模型是基于距离度量的,具有大变化范围的特征可能会影响模型对小变化范围特征的关注度,需要进行数据标准化处理.此外,标准化还能够使最优解的寻优过程变得平缓,提高模型的收敛速度.本文使用两种标准化方法对数据进行处理,其中神经网络模型使用Z-Score标准化,其他模型使用Min-Max标准化.它们的处理方法如下.
1)Z-Score标准化:
(8)
2)Min-Max标准化:
(9)
4.4 评价指标
在类别不平衡问题中,准确率、精确率和召回率并不合适作为评价指标.本文使用AUC(Area Under Curve)作为评价指标.AUC是ROC曲线下与坐标轴围成的面积,能有效评估模型性能,非常适用于该类问题.
4.5 实验设计
为了验证本文所提出的虚假评论识别模型的有效性,实验使用上述的数据集和评价指标,与逻辑回归模型(LR)、随机森林模型(RF)、神经网络(ANN)模型进行比较.
上述所有的模型都需要设置超参数.在机器学习算法中常用的搜索策略一般有4种:随机搜索、贝叶斯搜索、网络搜索和梯度搜索.本文选用贝叶斯搜索[11],该方法相较于其他方法更加稳定高效.LR、RF、ANN和GBDT模型的参数寻优范围如表3所示,参数优化过程如图2所示.

迭代次数

表3 不同虚假评论识别模型的参数寻优范围
4.6 实验结果
以AUC为评价指标,在Yelp评论数据上训练模型,实验结果如表4所示.

表4 不同模型的AUC对比
从表2中可以看出:1)本文所提出BalanceCascade-GBDT模型在对比实验中AUC值最高,预测效果最好;2)两种欠采样方法的分类效果相较于单模型有很大的提升,表明在虚假评论模型训练之前对样本数据进行平衡很有必要;3)利用BalanceCascade算法处理类别不平衡问题,其模型的分类效果比简单欠采样好,这是因为该算法更充分地利用了全部样本数据.
关于多维特征在虚假评论识别中的作用,可以通过模型的特征权重进行观察.其中特征重要性排序的前十位如图3所示.
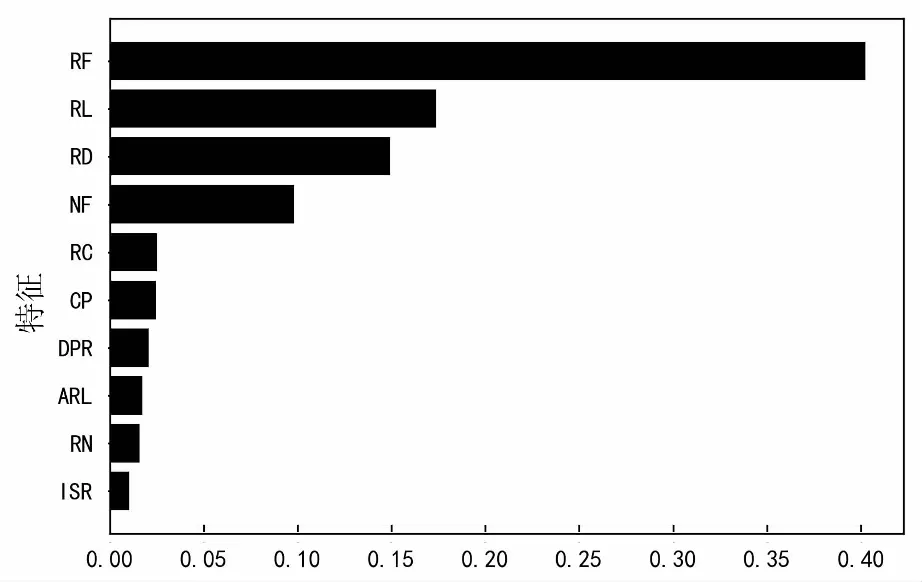
特征重要性
从图中可以看出用户评论频率、评论长度、评级偏差和用户粉丝数在识别虚假评论的过程中具有突出效果.
5 结 论
本文利用BalanceCascade-GBDT算法解决类别不平衡的虚假评论识别问题.该算法通过控制误报率不断删减大类样本,并在每层中利用欠采样方法产生类别平衡的训练样本子集训练基分类器,最后对这些基分类器进行集成.由于全部训练样本子集所包含的信息要比单个的多,因此该算法能在整体上利用全部数据.至于GBDT则保证了基分类器的分类效果,特别在后期迭代中,当易分类的大类被剔除后,需要性能优异的模型进行学习.实验结果表明,本文提出的方法可获得更高的AUC值.
