基于XGBoost的上市企业财务违约预测研究*
2020-11-02李亚琼
王 行,李亚琼
(1.湖南大学 数学学院,湖南 长沙 410082;2.湖南大学 金融与统计学院,湖南 长沙 410006)
1 引 言
近些年A股市场规模发展迅速,已然成为重要的资本市场.A股上市公司作为中国实体经济的典型代表和经济发展的中流砥柱,一旦出现财务违约引发财务危机,不仅公司自身会遭受经济损失和信誉损耗,同时投资者的利益也将蒙受严重损害,甚至可能对金融市场和社会的稳定造成冲击.因此科学合理地建立上市公司财务违约风险预警机制,为风险管理者和投资者提供可靠决策,这对上市公司、投资者以及社会经济的发展都具有重要意义.
上市企业的财务违约风险预测一直是学界和业界关注和研究的热门课题,而过去的研究中采用的模型较为简单,建模时所用数据也以财务指标为主.Beaver[1]采用单一财务指标变量分析的方法测算违约概率.但仅用一个指标是难以对公司的财务状况进行多维度评价,其后有学者提出多元财务变量的预测模型.比如Altman[2]提出基于几个固定的财务比率的Z-score模型,Ohlson[3]基于Logistic模型对反映公司经营盈利能力等多个财务指标数据进行建模分析, 曹勇等[4]则针对国内上市公司采用Logistic进行违约预测.
由于近些年人工智能的蓬勃发展,机器学习领域的支持向量机、随机森林、决策树等经典模型被广泛用于预测研究.Shin等[5]基于支持向量机模型拟合韩国1996-1999年间上市公司破产的数据.Frydman等[6]首先将决策树引入财务预警研究中,鲍新中等[7]选取反映公司成长能力、偿债能力等多维财务指标利用决策树对制造业上市公司财务违约进行预警,但单棵的决策树容易发生过拟合导致在新数据上的泛化能力不强.孟杰[8]则考虑基于集成学习的随机森林算法,学习生成多棵决策树,各个决策树的结果以“投票”的形式选出公司预测的最终结果,虽然预测准确率有所提升但树的独立性对变量的解释性有所减弱.XGBoost(extreme gradient boosting)[9]是目前机器学习领域较新的算法,不同于随机森林Bagging的集成学习思路,XGBoost是基于梯度提升完成集成学习.在违约预测问题上具有以下优势:1)XGBoost模型使用前无需对数据归一化处理,对缺失值能有效处理.2)模型增加了对树结构复杂度的惩罚项,能够有效避免过拟合的问题.3)模型迭代式生成树,并提供增益、覆盖、权重等多个选项和维度描述特征重要性,具有较强变量解释性.
从上市公司信息披露的内容来看,主要包含财务指标数据和文本报告.上述论文在财务违约预测主要使用的财务指标数据,但文本报告也是信息披露中的重要部分.贺建刚等[10]、Muslu等[11]的研究表明年报中管理层讨论与分析可以为外部投资者提供了解企业现状和预测未来的有用信息,在一定程度上可以缓解投资者、分析师等外部信息使用者与上市公司之间的信息不对称.因此本文同时采用定量财务指标数据与定性的管理层讨论与分析文本数据对上市公司进行财务违约预测和分析.
对于管理层讨论与分析文本的研究,有学者以正负面情感来量化年报中的文本语调并实证检验了其存在参考价值.谢德仁等[12]基于英文年报用词构建的词典来分析中文年报中管理层讨论与分析的文本语调.虽然翻译成中文后具有一定参考性,但中文用词和英文用词存在差异.王泽霞等[13]基于专业性、真诚性和前瞻性深度等语言特征测度指标来分析年报中的管理层讨论与分析文本和企业未来业绩表现的关联.由于过多地依赖词汇类别字典和人工判别,造成特征间信息重叠的可能性较大且操作方法不易推广.
为此本文采用Jiang等[14]基于Loughran 和 MacDonald[15]词典,word2vec算法等方法构造的全新的中文金融文本情感词典,依据积极和消极情感词典构建表面语调情感指标.另一方面,为了克服依赖情感词典导致对文本中出现的包括无情感而实际隐含积极和消极意味或行为等特征词的忽视,本文对ST公司和正常公司年报中管理层讨论与分析文本的非情感的特征词进行提取,并构建隐含违约倾向指标.通过表面语调情感指标和隐含违约倾向指标两个指标,将管理层讨论与文本中有助于财务违约预测的增量信息进行充分的提取,并结合定量的公司财务数据组成特征集.最后基于XGBoost模型实现对上市公司的财务违约风险的准确预测.
本文应用定性文本数据参与违约预测。基于全新的中文情感词典构建表面情感语调指标以量化文本字面的积极或消极的情感倾向,进一步利用扩展的TF-IDF方法构建隐含违约倾向指标量化文本隐含的违约倾向。两种指标特征间信息重叠较小,并对定性文本数据有效地降维;利用XGBoost模型对特征进行重要性排序,并结合敏感性分析对本文构建的文本特征的有效性进行了有力验证。
2 实证研究设计
2.1 样本和数据
学术界普遍将风险警示ST视为上市公司陷入财务危机的标志.本文选取2017-2019年期间A股制造业上市中被ST的78家公司和日期对应并规模相似的78家正常的公司,样本配对比例为1∶1.由于上市公司发布t-1年报与其在t年是否被特别处理这两个时间点相近,为此本文采用了t-2年的财务数据和年报文本数据进行分析并建立模型预测公司是否会在t年出现财务违约.因此对应数据的时间区间为2015-2017年.
本文样本公司的财务数据来源于国泰安数据库,考虑相关财务违约预测研究的指标选取经验,并兼顾数据的可获取性.从反映上市公司偿债能力、经营能力、盈利能力和发展能力的四个方面初选取26个财务指标.公司的年报文本是从新浪财经网下载,并截取管理层讨论与分析的文本内容.获取共156家的公司的管理层讨论与分析文本,在去除停用词后共有55.285万字数.
2.2 数据预处理
获取财务数据和文本数据后,对数据进行预处理,主要包括对财务数据的缺失值填充和文本数据的分词.在财务数据预处理中,对选取的26个财务指标中的缺失值采用均值填充方法.
在文本数据预处理中,首先基于Python的中文分词工具库Jieba对管理层讨论与分析文本分词,再基于中文停词表对中出现频率较高的符号、虚词、介词等无实际含义的符号和词汇删除.
2.3 管理层讨论与分析的文本量化方法
上市公司在年度报告中会对公司经营和财务情况进行披露,在管理层讨论与分析中对当期财务做进一步解释,并从公司管理层的角度对未来一年的经营和发展中可能遇到的风险和挑战进行说明.该部分的措辞会受到上市公司经营状况的影响,量化具有差异性的措辞信息并纳入财务风险预警的考量因素中,或许对投资者和市场管理者规避风险有所帮助.
本文基于“词袋”假设,其假定文档是词的集合且词的出现是相互独立的.采用两种方法对管理层讨论与分析文本进行违约倾向的量化.一种方法是从语调情感出发,对文本中积极和消极情感进行量化,并构建表面语调情感指标STONE.另一种方法是从特征词的角度量化文本,借鉴Cecchini[16]的TF-IDF扩展方法,对不同类别文本的特征词汇进行提取计算ts得分作为权重,进一步构建隐含违约倾向指标IPD.
2.3.1 基于情感词典的表面语调情感指标构建
基于Jiang等[14]构建的中文金融文本情感词典,将分词后的文本对应情感词典进行积极词汇和消极词汇的匹配,计算出管理层讨论与分析的积极倾向值POSTONE和消极倾向值NEGTONE,其表达式分别:

(1)
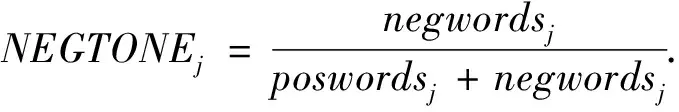
(2)
其中postwordsj和negwordsj分别表示t年财务正常或出现财务违约的上市公司j在t-2年年报中管理层讨论与分析文本积极词和消极词的频数.进一步构建文本的表面语调情感倾向指标STONE(Superficial Tone)的表达式:
(3)
最终计算的STONEj表示公司j的t-2年年报中管理层讨论与分析文本的表面情感倾向值,STONEj的值越大,则表明语调情感越倾向于乐观积极.相反,STONEj的值越小则表示越倾向于悲观消极.
2.3.2 基于扩展的TF-IDF方法的特征词提取
基于特征词在不同文档间重要程度差异和在不同类别间重要程度差异的思想,通过扩展的TF-IDF方法,计算各个类别中特征词的得分,特征词的得分高低体现重要程度.不同于经典的TF-IDF方法仅考虑特征词汇所在文档词频和出现在其他文档频率,扩展的TF-IDF方法考虑了特征词汇所在文档词频、同类文档词频和出现在异类文档频率.
建立ST公司文本语料库和正常公司文本语料库,两个语料库中各自包含ST公司和正常公司t-2年年报中管理层讨论与分析的文本文档.所有文档经过文本预处理.首先计算一篇文档中某个词在本篇文档中的出现频率和在另一个语料库的文档数次数,通过式(4)计算每篇文档中每个词的词汇文档得分tds.再利用式(5)对一个语料库中每个词在每篇文档中的得分进行求和,得到词得分ts.计算词汇得分ts之后,经过排序之后根据需要选取前n个词作为文本的特征词汇.
(4)
tsik=∑jtdsijk·log(nk),k∈{0,1}.
(5)
2.3.3 基于特征词的隐含违约倾向指标构建
通过选取特征词并利用式(5)计算其权重ts,以及利用式(4)中已经计算的特征词频率tf.由此构建基于文本分析的公司隐含违约倾向指标 IPD(Implicit Propensity for Default):
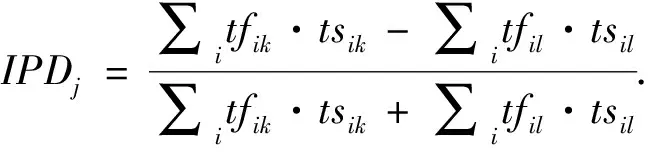
(6)
其中k=1,表示第一类t年出现财务违约的公司,l=0,表示第二类t年财务正常公司.IPDj表示上市公司j的违约倾向值,tfik表示财务违约公司的文本特征词汇ti在t-2年年报管理层讨论与分析中出现的频率,tsik表示财务违约公司的文本特征词汇ti的权重.相应的,tfil和tsil分别表示正常公司的特征词汇ti的词频和权重.
2.4 实证模型
上市公司财务违约预测是二分类预测的问题,一类状态是财务正常,另一类状态是财务违约被ST特殊处理.目前在财务违约预测的研究中被广泛使用的基本模型和方法集中在传统统计模型和机器学习方法.机器学习方法中的XGBoost算法具备预测分类的能力,其在预测分类问题中表现较强的优越性、稳健性以及泛化能力,因此本文选择XGBoost作为实证模型.
XGBoost是目前机器学习领域中较新的一种集成学习算法,其迭代地生成学习器,前后的学习器间存在强依赖性.提取财务数据和文本数据的特征后,得到数据集
D={(xi,yi)},i=1…n,xi∈Rm,yi∈{0,1}.
其中n表示样本量,每个样本具有m个特征并且对于标签值yi,其中yi=0表示上市公司i在t年财务正常,yi=1表示上市公司i在t年被ST处理,xi表示上市公司在t-2年时的财务指标和年报中管理层讨论与分析部分的文本特征.假设有K棵回归树,则模型表示为:
(7)
其中,fk表示第k棵回归树,fk(xi)表示第k棵对第i个样本的计算值,F表示回归树的集合.下面是模型求解过程中经过一系列推导得到的目标函数:
(8)
目标函数Obj又被称为结构分数,分数越小表示树整体的结构越好,其建立了树的结构与模型效果的直接联系.采用贪心算法对树进行分枝,即每进行一次分枝需要选择结构分数增益高的特征.当整体结构分数低于先前设定的阈值时,树停止生长.分枝前后结构分数的增益可表示为

(9)
其中
GL=∑i∈ILgi,GR=∑i∈IRgi,HL=∑i∈ILhi,HR=∑i∈IRhi.
(10)
IL和LR分别表示树分类后左右子树和右子树的样本组.分枝特征的平均结构分数增益可以体现出特征的重要性程度,即对于上市公司的财务违约预测的重要性,由此可得出所有特征的重要性排序.
3 实证分析与结果
3.1 财务和文本数据的处理
对财务定量数据和文本定性数据分别处理和分析,并对抽取后得到的特征进行建模.通过相关性分析和独立样本t检验对财务定量数据选择出11个财务指标.这11个财务指标是流动比率(x1)、现金比率(x2)、资产负债率(x3)、权益对负债比率(x4)、资产报酬率(x5)、净资产收益率(x6)、营业净利率(x7)、应收账款周转率(x8)、现金及现金等价物周转率(x9)、流动资产周转率(x10)、资本保值增值率(x11).
对定性文本数据,首先基于积极和消极情感词典对所有公司t-2年年报中的管理层讨论与分析的文本逐一进行积极词和消极词的匹配和词频计算得到poswords和negwords,再通过式(3)计算表面语调情感指标得分.通过扩展的TF-IDF计算词汇得分,本文分别选取tsi0和tsi1得分前300个特征词,并从中选取卡方检验显著的特征词,此外为防止与STONE指标产生信息重叠,剔除出现在情感词典中的词汇,如“增长”“提高”“诉讼”“亏损”等具有表面积极、消极情感的词汇.最终得到90个ST公司特征词和90个正常公司特征词,利用式(6)计算公司的隐含违约倾向指标IPD.
3.2 财务违约风险预测模型评价
3.2.1 交叉验证
对数据进行训练集和测试集分割,70%样本作为训练集,30%样本作为测试集.通过K折交叉验证来确定模型的最佳参数,即将训练集分为K份,轮流择其1份作为验证集,剩余K-1份作为训练数据,依次进行训练和验证,计算相应的评价指标,最后将K次试验的评价指标值的均值作为模型预测精度的估计.本文采用常规的十折交叉验证进行试验.
3.2.2 财务违约预测评价指标的构建
考虑到ST公司而被预测为正常公司的代价不同于正常公司而被预测为ST公司的代价,代价的差异取决于风险管理者和投资者所关注的决策效益,因此构建不同评估指标,包括漏警率(Missing Alarm Rate, MAR)、假警率(False Alarm Rate, FAR)、总体准确率(Accuracy, ACC)和受试者工作特征曲线下的面积(Area Under Curve,AUC).
MAR是指实际为ST公司被预测为正常公司的比例,FAR是实际为正常公司而被预测为ST公司的比例,MAR和FAR的值越小表示模型误判比例小.ACC表示公司状态预测准确的总体比例,AUC表示模型受试者工作特征曲线下的面积,是衡量模型优劣的性能指标.ACC和AUC值越大表示模型具有越好的预测分类和拟合效果.
3.3 财务违约预测和分析
采用XGBoost对公司的财务数据和管理层讨论与分析文本量化STONE和IPD特征建立上市公司财务违约预测模型,并且和基于其他分类器的预测模型比较分析.进一步地,为了判断情感语调和隐含违约倾向对定量财务违约模型的增强效果和验证指标的有效性,并且考虑在财务特征集的基础上不加STONE和IPD特征、仅增加STONE特征、仅增加IPD特征、增加STONE和IPD特征四种情况,来对STONE和IPD特征进行敏感性分析.
3.3.1 模型预测效果比较
针对目前在财务违约预测中常用算法,采用XGBoost、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree, DT)、随机森林(RandomForest, RF)以及逻辑回归(Logistic Regession, LR)建模.从表1可以看出,XGBoost财务风险预测模型在假警率和总体准确率方面优于其他模型,预测的假警率低至8.69%,同时总体准确率高达91.48%.
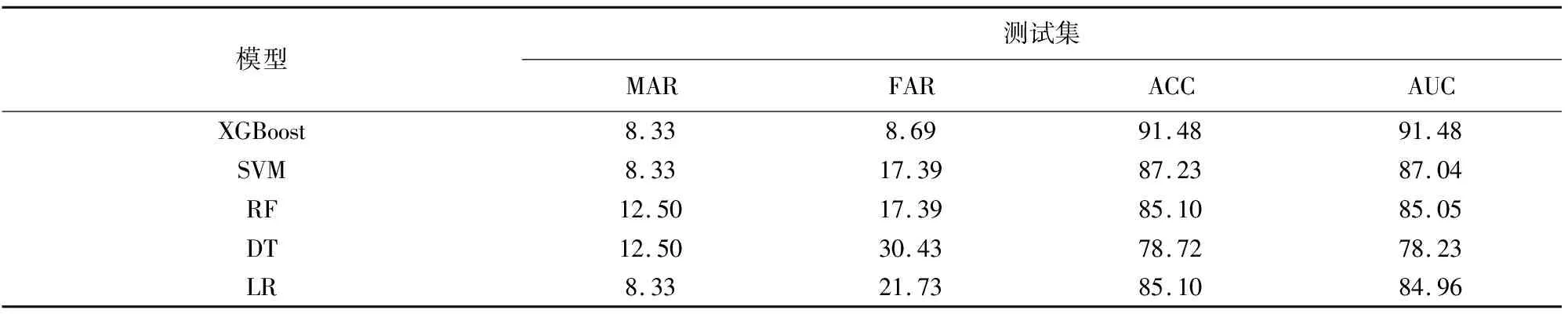
表1 预测分类结果对比 %
3.2 财务违约预测模型解释性验证
XGBoost除了在预测精度上具有优势外,同时还具有良好的可解释性.基于XGBoost集成了50棵回归树对财务违约预测模型进行解释性验证.如图1所示,此处只展示第1棵树和第50棵树.

图1 基于XGBoost的财务违约预测模型的决策图
树的每个节点在做分枝决策时都在选取特征集中结构分数增益大的特征,由于XGBoost模型生成多棵树,所以一个特征会在多棵树上出现.因此可以将每个分枝特征的平均结构分数增益Gain作为度量特征重要性的标准.Gain越高意味着相应的特征对于预测财务违约越重要.对于重要性程度高的特征,在收集数据阶段应该加以重视,保证预测精度.
隐含违约倾向指标IPD和表面语调情感指标STONE位于特征重要性排序的前两位,如图2所示,这表明管理层讨论与分析的文本特征能够反映上市公司财务健康状况,其重要性不亚于财务指标.净资产收益率x6的重要性仅次于文本特征,说明具有财务违约风险的公司与正常公司在自有资本获得净收益的能力上是具备较高差异的.相比之下,流动比率x1处于特征重要性排序最后一位,相对于其他参与排序的特征重要性不足,除此之外,由于在所有树的分枝中流动资产周转率x10都没有发挥作用,所以没有Gain值且未参与重要性排序,可以考虑舍弃以加速模型训练.

特征
3.3.3 文本特征的敏感性分析
为了进一步验证构建的表面语调情感指标和隐含违约倾向指标对于财务违约预测的重要性和增强效力,利用敏感性分析,考虑在财务指标特征集的基础上的4种特征组合,XGBoost财务违约模型的预测结果见表2.

表2 不同特征组合下XGBoost预测结果比较 %
当财务指标特征集结合表面语调情感特征STONE时,模型预测的假警率FAR指标有较大幅度降低,总体准确率ACC略有提高.当财务指标特征集结合隐含违约倾向IPD特征时,模型预测的漏警率MAR指标有较大幅度降低同时总体准确率有所提高.当STONE和IPD同时加入特征集,结合STONE和IPD特征两种预测优势,模型预测的MAR和FAR同时降低,总体准确率ACC达到91.48%.当模型的应用场景中更关注漏警率时,可考虑使用财务指标特征集结合IPD特征组合三,这时模型的漏警率MAR最低仅有4.16%.当应用场景中更重视总体准确率时,可考虑使用财务指标特征集结合STONE和IPD的特征组合四.因此,管理层讨论与分析的文本特征对于财务违约预测具有较高的增强效力,在数据收集和特征提取时应以重视.
应用XGBoost方法对上市公司财务违约进行预测,不仅能够实现较高的准确率,并且有利于风险管理者和专业量化投资者判别该模型的可靠性,进一步可结合特征重要性对预测模型作出改进.
4 结 论
本文选取A股制造业2017-2019年间78家ST公司与78家正常公司为研究对象,结合定量财务数据与年报中管理层讨论与分析的文本数据建立上市公司财务违约预测模型.针对定性文本数据,本文分别基于情感词典和扩展的TF-IDF方法抽取特征词汇,构建表面语调情感指标(STONE)和隐含违约倾向指标(IPD),并将两种量化文本的指标与财务指标数据结合,基于XGBoost模型对上市公司财务违约风险预测.实证表明构建的XGBoost财务违约模型相比支持向量机、随机森林、决策树和逻辑回归在预测精度上具有明显优势.最后通过特征重要性排序和敏感性分析验证了所构建的表面语调情感指标和隐含违约倾向指标的有效性.
本文的研究局限于A股制造业上市公司,虽未对其他行业的公司进行研究,但本文的研究思路和操作可供推广和借鉴.此外在本文财务指标数据和管理层讨论与分析文本数据的基础上,进一步地,还可以增加内部控制、股权结构和宏观经济方面的定量数据,以及其他渠道如新闻报道和社交媒体上的定性文本数据.当然这些数据能否在本文的指标基础上额外提供有助于预测的增强效力,还需要进一步的研究.
