基于双层并行架构的高速目标访问计算技术
2020-10-28杨纪伟赵汝哲张学亮彭会湘岳群彬
杨纪伟,赵汝哲,张学亮,彭会湘,白 晶,颜 博,岳群彬
(中国电子科技集团公司第五十四研究所,河北 石家庄 050081)
0 引言
随着遥感技术的发展,卫星成像技术广泛应用于战场观测、国土普查、环境监测和气象预测等领域[1]。采用多星协同观测特定目标或目标群的方法,可以充分利用卫星资源。多星协同规划的前提是预先计算所有卫星对目标或目标群的可见信息[2]。快速实时计算卫星对目标的可见信息,能够为后续任务规划预留更多机动时间[3];如果计算耗时过长,甚至有可能影响到任务的顺利进行。
传统目标访问计算通常采用多星排队计算、单星逐点搜索的方法。多星之间按照时间先后顺序,依次进行访问计算,一颗卫星计算完成后再继续处理下一颗卫星,直至所有卫星处理完成;对于单颗卫星的访问计算,逐时刻点搜索最优访问时刻,直至所有时刻点搜索完成。该算法随着卫星数量和目标数量的增加,访问计算所需的时间将线性增加。
针对多星多任务访问计算时效性差的问题,提出了基于双层并行架构的高速目标访问计算技术,该技术通过多节点并行架构将不同的卫星计算任务分配到不同的访问计算节点,可以解决多星排队计算的问题;通过CPU+GPU异构架构将单星单任务逐点计算问题转化为多线程并行计算问题[4]。最后通过多颗卫星的实测数据验证了算法的时效性。
1 目标访问计算技术概述
对地观测卫星的主要任务是实现对地面目标的准确观测,考虑到多星协同观测以及对卫星反应速度的要求,需要快速、准确地计算观测卫星对地面目标的访问时段及相应时段卫星观测目标的姿态信息[5]。目标访问计算技术的主要功能是根据卫星星历数据(包括卫星空间位置信息、卫星速度信息和星下点地理位置信息等)、目标地理位置信息以及卫星的约束条件(包括卫星侧摆角范围、卫星俯仰角范围、卫星传感器成像太阳高度角等)计算卫星对地面目标的访问时段及对应的姿态信息(侧摆角、俯仰角)。
计算卫星指向地面目标的侧摆角和俯仰角示意如图1所示[6]。
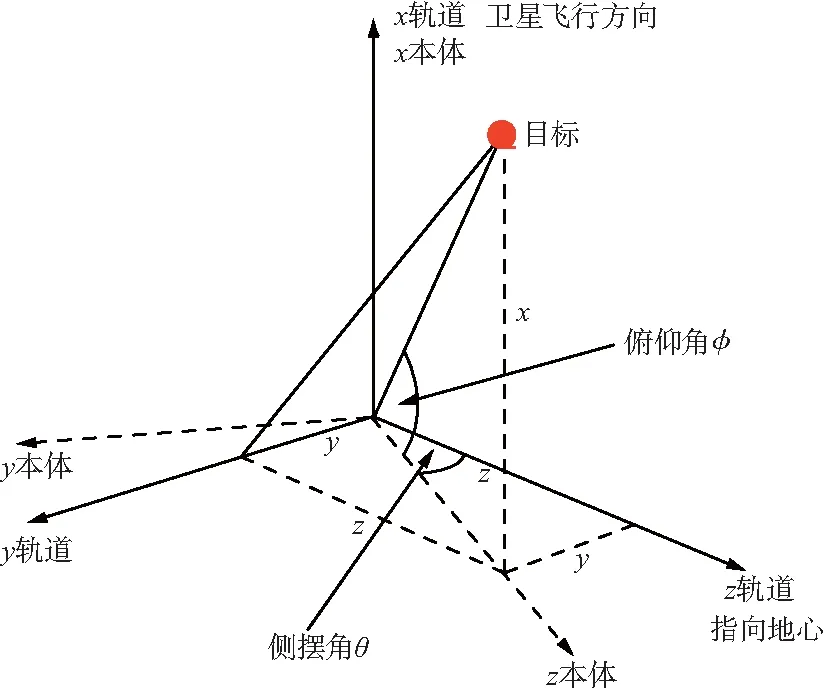
图1 卫星二维指向示意Fig.1 Schematic diagram of satellite two- dimensional pointing
卫星相机光轴在卫星本体坐标中为(0,0,1),即指向卫星本体坐标系z轴;不进行姿态机动时,卫星本体坐标系与卫星轨道坐标系重合;先绕x轴转动侧摆角θ,再绕y轴转动俯仰角φ后,相机光轴矢量(本体坐标系z轴方向)指向目标[7]。
2 传统目标访问计算架构
传统目标访问计算架构为纯串行架构,如图2所示。
收到目标访问计算申请任务后,接收线程将任务加入到任务申请队列中。处理线程监视任务申请队列,如果任务申请队列中有待处理任务,处理线程就从申请队列中取出第一个任务作为当前任务进行处理,当前任务处理完成后,再继续处理下一个申请任务,任务与任务间是串行处理的,遵从“先来先服务”原则。
具体到对某一个任务的处理时,处理线程对所有时刻逐点进行搜索计算,计算对应时刻的卫星姿态信息(侧摆角、俯仰角)以及其他约束信息(太阳高度角)。计算完成后对姿态信息和约束信息进行判定,如果满足约束条件,对结果进行记录,如果不满足约束条件,直接舍弃;处理完当前时刻后,将时间自加1 s。如果自加1 s后的时间已经超过时间范围,直接结束;如果没有超过时间范围,则处理该时刻,直至所有时刻处理完成。

图2 传统目标访问计算架构Fig.2 Traditional target access computing architecture
对于上述目标访问计算架构,任务与任务之间是串行处理的,每次只能处理一个任务;任务内部所有时刻的搜索是串行处理的,每次只能处理一个时刻。
3 双层并行目标访问计算架构
3.1 任务级并行架构
双层并行高速目标访问计算架构采用任务级并行和任务内部线程级并行的双层并行策略[8],任务级并行架构如图3所示。

图3 任务级并行架构Fig.3 Diagram of task level parallel architecture
并行调度软件与访问计算节点通信的消息有2种:握手消息和计算任务消息。并行调度软件通过握手消息判断访问计算节点是否正常。对于正常节点,当有任务申请时,并行调度软件会将任务发送到空闲的访问计算节点,如果空闲的访问计算节点数量少于任务总数量,按照“先来先服务”原则,多出的申请任务继续排队,任意一个节点返回计算结果后,并行调度软件会将排队的任务继续分发,直到所有的任务都计算完成[9]。
对于任务级并行,当任务量增加时,可以通过扩充访问计算节点的方式保证访问计算的反应时间,从而减少因为任务之间进行排队而造成的访问计算反应时间不可控的情况发生。
3.2 线程级并行架构
线程级并行架构采用CPU+GPU异构架构,CPU负责进行逻辑处理,GPU负责大数据量的计算,CPU+GPU的异构架构之所以能够实现多线程并行,是由GPU本身架构决定的。CPU与GPU的对比如图4所示[10]。

图4 CPU与GPU架构对比Fig.4 Comparison between CPU and GPU architecture
ALU为计算单元,相比于CPU,GPU的控制单元较少,即GPU的逻辑控制能力相对较弱,但GPU将更多的单元用于执行数字计算。所以相比于CPU,GPU更适合大量的数字计算,却不适合于逻辑处理[11]。
基于以上原因,采用CPU进行逻辑处理、读写操作;采用GPU进行数字计算。线程级并行流程如图5所示。

图5 线程级并行流程Fig.5 Diagram of thread level parallel process
CPU端负责读取目标信息及卫星约束条件,获取星历数据,GPU端负责进行对应时刻的姿态信息及其他约束信息的计算[12]。
具体流程为:
① CPU端读取卫星数据、约束条件、设定时间段内的星历文件和目标文件,传递到GPU,并为GPU分配多个线程。所述的约束条件包括卫星的最小太阳高度角、最小侧摆角、最大侧摆角、最小俯仰角、最大俯仰角、卫星轨道倾角和轨道高度[13]。
② GPU端根据星历文件、卫星数据以及目标文件同时计算每个线程对应的星历时刻下的星下点到目标点的球面距离以及星下点的太阳高度角。
③ GPU端根据卫星数据计算星下点到目标点的球面最大距离,将步骤②中所得的所有星历时刻下的星下点到目标点的球面距离分别与星下点到目标点的球面最大距离进行对比,将步骤②中所得的所有星历时刻下的星下点的太阳高度角分别与卫星的最小太阳高度角进行对比,若该星历时刻下星下点到目标点球面距离小于星下点到目标点的球面最大距离,且星下点的太阳高度角大于卫星的最小太阳高度角,则执行步骤④;否则结束该线程。
④ GPU端计算每个星历时刻下卫星访问目标的滚动角和俯仰角,将滚动角与最小侧摆角和最大侧摆角进行对比,将俯仰角与最小俯仰角和最大俯仰角进行对比,若滚动角在最小侧摆角和最大侧摆角范围内且俯仰角在最小俯仰角和最大俯仰角范围内,则记录该星历时刻及该星历时刻下计算所得的星下点到目标点的球面距离、星下点的太阳高度角以及卫星访问目标的滚动角和俯仰角;否则结束本线程[14]。
具体到GPU进行数据处理,逻辑示意如图6所示。

图6 GPU执行目标访问计算示意Fig.6 The schematic diagram of GPU executing target access computing
根据GPU的核心数量和时间跨度,对GPU核心进行编号,对不同编号的核心分配不同的待执行线程,不同的执行线程根据编号取不同的待处理数据进行处理。
在某个线程具体进行姿态信息计算时,考虑到卫星星下点与目标点球面距离的计算比卫星姿态信息计算的计算量小、耗时少,首先计算卫星星下点与目标点的球面距离,如果球面距离不满足约束条件,该线程直接结束,相应的GPU核心可以继续处理其他待处理任务[15]。
经实验,对于卫星高度500~800 km,侧摆角范围45°以内的卫星,星历预筛选可以筛选掉不低于85%的星历数据,搜索速度得到了一定的提升。
4 实验分析与评价
从单星多目标单节点计算能力、多任务反应能力2个维度对双层并行目标访问计算架构与传统目标访问计算架构进行对比。
单/多计算节点、外推星历24 h情况下,针对单/多星多目标情况进行了试验,具体耗时和加速比如表1所示。表1中,加速比1代表单节点CPU版访问计算耗时与单节点CPU+GPU版访问计算耗时之比;加速比2代表单节点CPU+GPU版访问计算耗时与10个节点CPU+GPU版访问计算之比。

表1 单/多星目标访问计算耗时对比Tab.1 Comparison of calculation time of single-satellite and multi-satellite target access
单节点情况下,卫星数量、目标数量与不同计算架构下的耗时之间的关系如图7所示。

图7 2种计算架构下的目标访问计算耗时Fig.7 Target access calculation time of two computing architectures
CPU,CPU+GPU两种计算架构下的加速比曲线如图8所示。

图8 2种计算架构下的加速比曲线Fig.8 Acceleration ratio curve of two computing architectures
CPU+GPU异构计算架构下,单节点与任务级多节点并行时,不同的卫星数量、目标数量对应的耗时曲线如图9和图10所示。
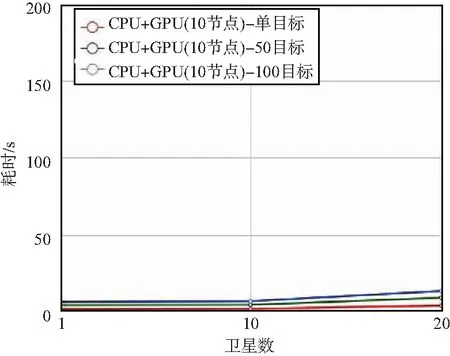
图9 单GPU节点目标访问计算耗时Fig.9 Target access calculation time of 1 GPU node
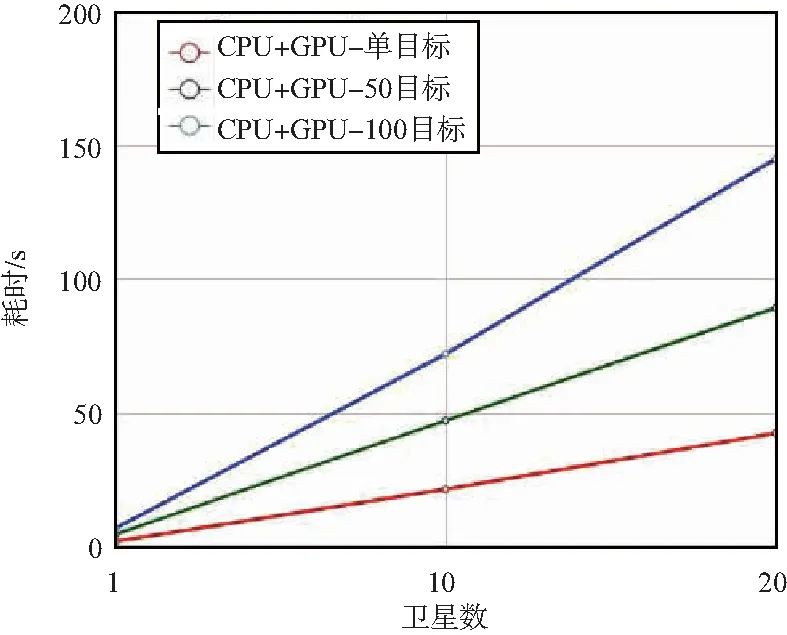
图10 10 GPU节点目标访问计算耗时Fig.10 Target access calculation time of 10 GPU node
单节点与任务级多节点并行时的加速比曲线如图11所示。
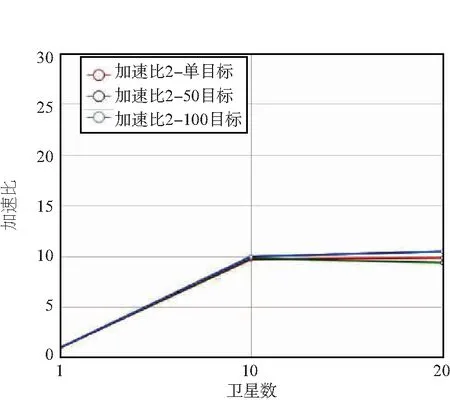
图11 不同并行节点数时的加速比曲线Fig.11 Acceleration ratio curve of different parallel nodes
由表1、图7和图8可知,对于单节点,当目标数较少时,加速比较低,随着目标数的增加,加速比逐渐提高,但是当目标数达到一定数量后,加速比趋近于一个定值,不再提升。
由表1、图9、图10和图11可知,双层并行计算架构的加速比受并行节点数量、单次任务目标数量两方面因素影响。当所有节点满负荷运行时,加速比与节点数量大致成正比例关系。
5 结束语
本文提出了一种基于双层并行架构的高速目标访问计算技术,用于解决卫星管控中多星多目标筹划实时性差的问题。通过多节点的任务级并行,将多星任务分解为单星任务进行处理。同时,通过CPU+GPU异构架构,提高了单点目标最优访问时刻的搜索效率。在本文给出的数据集上的实验,表明了该技术的有效性。
