基于支持向量机模型的价值投资策略分析
2020-10-21赵子铭


摘要:传统机器学习算法在量化投资上的应用大多是数据挖掘式的全盘决策,但较少被用于优化现有金融学定价模型。因此,本文提出一种基于支持向量机的优化多因子价值投资模型,该模型首先以估值、质量类因子作为评分指标构建多因子价值投资模型,再将基于价值因子的多维指标作为输入变量,训练并建立多截面期支持向量机模型。通过对各期候选股进行0-1预测分类,选取“未来20日夏普率高居前30%”的1类股票构建优化投资组合;最后依据技术指标构建动态仓位调整法则,以达到控制风险及回撤的目的。实证结果表明:在70%的调整仓位下,策略最终年化收益为25.08%,夏普率为1.24,远超同期沪深300指数。
关键词:价值投资 多因子模型 支持向量機 技术指标
一、 引言
量化投资是依据技术指标、基本面及宏观经济指标数据,通过建立某种数学模型或算法预测资产价格的趋势变化并从中获利的投资方式,其盈利能力的逻辑支撑来自于Sharpe(1964)[1]提出的资本资产定价模型(CAPM)。在M-V准则基础上,该模型将证券的期望收益分解为无风险收益与证券特有风险的溢价;作为多因子模型的最简单形式,CAPM改变了投资者看待证券收益组成的方式,“Seeking Alpha”的策略成为量化投资的最初尝试;Ross(1976)[2]提出套利定价理论(APT),并在非均衡条件下推导出多因子模型,而CAPM模型自然成为其一个特例。自此,寻找恰当数量的有效因子并通过定价模型进行证券估值的量化投资策略主导了学界及商界的市场实践,如:Fama、French(1993)[3]通过研究发现:SML、HML因子及Beta系数能够显著地解释证券的超额收益。量化投资的发展离不开其核心假设,即历史数据与证券价格的未来走势存在某种关联关系,然而越来越多的研究与实践证明,依赖线性关系的传统定价模型在逐渐有效的市场中出现了“失灵”的现象。
机器学习算法依据严谨的数据输入、模型训练及预测方法,恰能通过高维数据指标描述证券截面特征,并寻找各维度间隐含的非线性关系。由于其优秀的分类预测能力,机器学习算法被广泛地运用于量化选股与择时之上。
作为“预测统计学”体系的发展成果之一,支持向量机强调结构风险最小化,因此解决了神经网络等算法中存在的“过学习”理论缺陷,具有非常优秀的泛化能力。因其在二分类上的优秀能力,支持向量机经常被用于预测股市涨跌情况。王彦峰等(2006)利用滚动窗口方法构建支持向量机预测模型,准确预测了个股日均价;张玉川等(2007)将技术指标作为输入变量对个股股价进行涨跌预测,其预测准确率大于60%;徐国祥等(2011)在传统SVM基础上引入主成分分析及遗传算法,经优化后模型对我国股指的预测准确率较高;赛英等(2013)使用遗传算法和粒子群算法优化支持向量机模型,并构建了股指期货回归预测模型;李斌等(2017)使用技术指标作为输入变量,比较了不同算法模型的收益预测情况,其中SVM模型策略的夏普率超过1.38,收益能力最高;吕凯晨等(2019)利用SVM优化多因子模型,其策略年化收益大于20%,远超同期大盘指数表现[4-9]。
总结以上文献,可以发现以下值得改进之处:
第一,利用支持向量机模型进行全权投资决策的方法在一定程度上忽略了传统金融学理论对投资决策的指导作用,因此模型的高预测准确度或许仅是数据挖掘的产物;
第二,在弱有效市场假说成立时,使用技术指标作为训练样本维度所构建的模型将只能获得市场平均收益;
第三,证券实际价格分布的峰度与偏度具有显著的时变性,因此在预测多截面期股价涨跌时,依据固定样本建立的支持向量机模型预测能力有限。
鉴于上述文献中存在的缺陷,本文提出以下改进措施:
第一,构建多因子-支持向量机联合优化模型,将机器学习算法与传统金融学理论模型进行对等融合;
第二,尝试摒弃技术指标,引入“安全边际”“内在价值”等价值投资理念因子作为模型训练数据的维度指标,使模型预测准确率具有更显著的经济学解释意义及理论支撑;
第三,使用滑动窗口的训练样本更新方法建立各截面期支持向量机模型,解决单一样本训练模型在进行长期预测时准确度低的问题;使用网格搜索方法更新最优参数,提高模型预测准确度。
二、 多因子价值投资模型
(一)价值投资因子
构建多因子模型的两大核心在于:第一,多因子模型中各因子的解释意义是否具有理论支撑;第二,所挑选的因子是否具备超额收益预测能力。据此,本文以因子评分法构建多因子价值投资模型,模型建立方法如下:
第一步,以价值投资理念为基础,围绕估值与质量维度筛选因子。由于以相对价格、盈利能力、利润增长率为基础的三要素定价法是证券数量化分析的关键,因此分析维度如下:
1.内在价值,企业价值体现在:企业具有长期可持续竞争的行业优势,且盈利状况稳定;
2.安全边际,即相对于其内在价值,证券价格相对合理。具有较高安全边际的证券能够为投资者提供良好的价格下跌缓冲[10]。
本文基于价值因子、估值因子两大维度对证券的内在价值及安全边际进行筛选[2],并以此构建多因子模型。将多因子模型的候选因子定为如下3大类共9个因子,它们综合考虑了企业的估值、成长、质量三个维度。
第二步,测试因子有效性。对所选因子进行有效性检验,以保证各因子具有显著的超额收益解释能力。本文利用IC、IR值检验因子有效性。因子IC值指因子t期暴露与证券t+1期证券收益率的相关系数,其绝对值越高,则意味着该因子具有较强的收益预测能力;IR值则由下式给出:
其中表示投资组合的夏普率平方和,表示消极投资组合的夏普率平方和,最后项为IR值(Information Ratio),是积极投资组合的alpha收益除以其标准差。IR值衡量主动证券分析带来的额外回报,是验证因子有效性的另一维度[11]。
利用沪深300指数成分股计算候选因子IC均值、IR值,结果如下。
除净现金流量增长率外,其余因子的12周期IC均值绝对值均超过0.015,表明因子暴露与股价未来收益具有显著相关性。
第三步,剔除冗余因子。估值与质量因子之间经常存在高相关性,为了防止因子相关造成的选股同质性问题,对上述9个候选因子进行相关系数分析。因子相关系数矩阵如下:
市净率与市现率、5年净资产收益率与资产回报率、每股收益、每股股息的相关系数均大于0.85。在对比因子IC均值、IR值后,舍弃IC均值较低的市现率和5年净资产收益率。
(二)多因子价值投资模型
依据上节筛选出的候选因子建立多因子模型,步骤如下:
1.区分候选因子的方向性,将资产回报率、每股收益等效益型指标划分为正向因子;将市盈率、市净率等成本型指标划分为负向因子。区分方向性对多因子评分的准确性具有重大意义;
2.在各截面期,依据沪深300指数成分股的各因子值排名进行评分[12]。以正向因子为例,在t截面期,i股票的第j个因子的评分为:
其中表示i股票在t截面期j因子的因子值排名;
3.对股票各因子得分进行基于该期因子IC值的权重求和,获得综合得分;选取得分最高的50只股票作为该截面期的候选股票,等权重分配资金形成投资组合;在每个截面期重复上述操作。
多因子价值投资模型的收益结果如下。(相关回测数据由Auto-Trader提供)模型在2017年1月1日——2019年4月1日获得超过35.9%的累计收益,年化收益为15.21%,夏普率达0.75。
三、基于支持向量机的多因子优化模型
支持向量机(Support Vector Machine)是由基于结构风险最小化原理的机器学习算法,从原理上克服了传统机器学习算法存在的维数灾难与“过学习”等问题。支持向量机的思路即在特征空间中寻找使样本点间距最大化的超平面;在非线性可分情况下,可以使用核函数映射方法,将原始特征空间映射至高维空间以寻找最优超平面(高维问题即可被归结为求解凸规划问题)。
因其在非线性、高维问题中具有较强的延拓能力,本文引入支持向量机对证券收益特征进行预测及分类。下文先简述支持向量机的原理,再将其应用于优化多因子模型的选股步骤。
(一)线性支持向量机
在线性可分情况下,考虑给定共有m个样本的训练样本集:
;
每个样本位d维向量,有d个观测值,即。分类超平面可以通过以下现象方程来描述:
其凸二次型规划问题的方程组如下:
利用拉格朗日乘子法,即得到其对偶问题;通过拉格朗日乘子()变换,该问题化简为如下函数:
其中。令对和的偏导数为零,最终联立两式、解出、求出和,即得到预测模型:
下图是简单线性支持向量机分类器示例。
图2 线性可分情况下的SVM
(二)非线性支持向量机
在非线性情况下,通过核函数变换将原始特征空间映射至高维空间,即可将非线性可分问题转换为高维空间中的线性可分问题。同上理,其预测模型如下:
其中核函数。由于实际计算并不需要在高维空间进行,因此其复杂度并未提高。常见核函数有线性核函数、Sigmoid核函数、高斯核函数等。经验表明,高斯核函数通常具有较高准确度,本文将其作为构建支持向量机的核函数[13-15]。
(三)模型构建
基于上述原理,支持向量机模型构建流程如下:
1.数据获取。①股票池:沪深300指数成份股及其相关因子数据,每只股票在某截面期的价格及相关因子数据为一个样本;②初始训练样本区间:2016年1月1日至 2016年11月30日共 11个月作为训练样本,并对接下来2个月内候选股票未来20日夏普率进行分类预测。在完成一次训练-预测后,固定训练集长度为11个月,进行步长为2个月的滑动窗口训练集更新;③回测时间:2017年1月1日至2019年4月1日,共28个截面期。
2.特征和标签提取。每个自然月第一个交易日股票各大类因子数据作为训练样本的特征集,股票未来20日夏普率作为训练样本标签:未来20日夏普率排名前30%的股票标记为1类,排名后30%的股票标记为0类。
3.特征标准化。对各类因子数据进行Z-Score标准化,消除量纲影响。
4.训练。在各截面期(每月第一个交易日)选取未来20日夏普率排名前、后30%的股票分别作为正例与负例、使用网格搜索、交叉验证方法,在每截面期更新最優参数,以保证各截面期模型对于其所训练样本具有最高预测准确率。
5.构建投资组合。若多因子价值投资模型的50只候选股票中存在“未来20日夏普率”预测为1类的股票,则等资金权重买入所有1类股票,构建优化投资组合;对已有持仓股票中预测为0类的股票进行清仓操作。
(四)策略结果
经支持向量机分类优化后,模型回测结果如下。
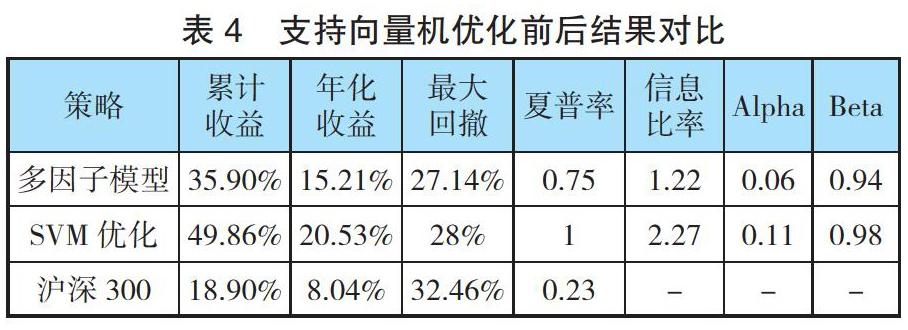
模型回测期内累计收益近50%,年化收益为20.51%,信息比率为2.27。滑动周期、网格寻参下的支持向量机选股模型的平均预测准确率达70%,模型的收益效果显著提高。
(五)基于移动均线的动态仓位调整方法
技术分析指标泛指以证券价格为基础、通过某种数学公式衍生得出的价格指标。虽然有效市场假说的最简单形式足已否决技术分析获取超额收益的能力(Fama,1965)[16-17],但大量文献及市场实践证明:第一,我国证券市场远不及弱有效(赵子铭,2019)[18];第二,投资者仍能通过移动平均线(MA)、异同移动平均线(MACD)在内的技术指标进行趋势获利 [19]。支持向量机优化后的选股模型具有较高预测准确度和远超大盘的盈利能力,但其回撤、波动率较大,在实际投资中会对投资者带来巨大心理压力,从而导致非理性投资行为。因此本文尝试利用技术指标信号对投资组合的仓位进行动态调整,以控制策略的风险敞口。
本文使用沪深300指数MA5、MA60移动平均线判断股市涨跌趋势。移动均线间的相对走势能够提供客观的择时信号,因此可以通过其趋势预测资产价格的变化拐点:以移动平均线的金叉、死叉作为牛市和熊市的转换条件进行必要的择时操作[20]。具体操作为:
在每一调仓截面期判断沪深300指数MA5与MA60的相对走势;若形成金叉,则使用全仓策略构建投资组合;若形成死叉,则将仓位动态调整为某一固定比例(分别使用70%、50%、30%,空仓作为调整比例实现策略)。策略结果如下表所示。
投资实践常用70%仓位作为动态调整比例。在此方法下,模型在原SVM优化模型基础上累计收益为65.07%、年化收益为25.08%、夏普率为1.24,且最大回撤下降至24.21%。
经优化后的多因子—支持向量机模型具有良好的分类预测能力,且其回撤风险被有效控制,为投资者提供了良好的市场实践参考价值。同时,将支持向量机作为防范与监控我国证券市场系统性风险的预测手段,或能丰富与完善决策者现有的风险调控机制,为我国资本市场的健康发展提供重要参考。
四、结论
本文以沪深300指数成分股及相关数据为研究对象,使用支持向量机对传统多因子模型的选股步骤进行分类-预测优化,提高了策略收益能力;提出基于移动均线的动态仓位调整方法并有效控制了投资策略的风险敞口。对应于引言中提出的前人文献不足之处,本文通过实践得出以下结论:
第一,通过滑动窗口、网格寻参方法建立的多截面期支持向量机优化模型在量化选股中具有优秀的分类预测能力;策略最终年化收益为25.08%、夏普率为1.24,预测准确度较高;多因子-支持向量机联合优化模型的理论逻辑与预测可信度都优于将算法、数据与金融学理论剥离的传统“数据挖掘式”方法;
第二,与使用技术指标的文献相异,本文使用价值投资因子作为输入数据的维度指标,所建立的支持向量机模型具有优秀的分类预测能力,表明模型能够发掘传统价值投资及因子估值模型中未能被描述的隐性关系。
随着我国资本市场的日益发展与成熟,市场有效性将侵蚀以技术指标、基本面分析等方法获取超额收益的机会,而支持向量机在内的机器学习算法或许能为投资者带来超越市场平均收益的新机遇。
未来,本文作者拟在如下几个方向进行深入研究:第一,尝试使用更高维度的基本面信息作为输入变量,以期能更全面描述证券的价格动量、盈利指标、流动性等特征,提升模型的预测效果;第二,尝试使用其他机器学习算法寻找传统因子模型中未能被线性解释的证券超额收益。
参考文献:
[1]Sharpe,W.F.Capital Asset Prices:A Theory of Market Equilibrium under Conditions of Risk[J].Journal of Finance,1964,19:425-442.
[2]Ross,Stephen(1976).The arbitrage theory of capital asset pricing[J].Journal of Economic Theory 13 (3); 341-360.
[3]Fama E F,French K R.Common risk factors in the returns on stocks and bonds[J].Journal of Financial Economics,1993,33 (1):3-56.
[4]王彥峰,高风.基于支持向量机的股市预测[J].计算机仿真,2006(11):256-258+321.
[5]张玉川,张作泉.支持向量机在股票价格预测中的应用[J].北京交通大学学报,2007(06):73-76.
[6]徐国祥,杨振建.PCA-GA-SVM模型的构建及应用研究——沪深300指数预测精度实证分析[J].数量经济技术经济研究,2011,28(02):135-147.
[7]赛英,张凤廷,张涛.基于支持向量机的中国股指期货回归预测研究[J].中国管理科学,2013,21(03):35-39.
[8]李斌,林彦,唐闻轩.ML-TEA:一套基于机器学习和技术分析的量化投资算法[J].系统工程理论与实践,2017,37(05):1089-1100.
[9]吕凯晨,闫宏飞,陈翀.基于沪深300成分股的量化投资策略研究[J].广西师范大学学报(自然科学版),2019,37(01):1-12.
[10]本杰明.格雷厄姆,聪明的投资者[M].北京:人民邮电出版社,2010:1-289.
[11]Bodie,Z.,Kane,A.and Marcus,A.(2014).Investments-Global Edition.London:McGraw Hill Higher Education.
[12]Piotroski J D.Value investing:The use of historical financial statement information to separate winners from losers[J].Journal of Accounting Research,2000 :1-41.
[13]汪梦竹.基于支持向量机的股票量化交易策略研究[D].重庆大学,2018.
[14]Vapnik V.N,1995,The Nature of Statistical Learning Theory [M].New York :Springer.
[15]宋文达.基于支持向量机的量化择时策略及实证研究[D].西安工业大学,2017.
[16]Fama,E F.The Behavior of Stock Market Prices [J].Journal of Business,1965,38:34-105
[17]Fama E F.Efficient Capital Markets:A Review of Theory and Empirical Work [J].Journal of Finance,1970,25:383-417
[18]赵子铭.上海证券市场有效性的复合分析[J].大众投资指南,2019(07):217-220+222.
[19]梁淇俊.基于生存分析的量化投资模型及其策略实现[D].暨南大学,2015.
[20]约翰.莫非.期货市场技术分析[M].北京:地震出版社,2017:1-530.
作者单位:华南师范大学数学科学学院
