基于残差空洞卷积神经网络的网络安全实体识别方法
2020-10-21谢博申国伟郭春周燕于淼
谢博,申国伟,郭春,周燕,于淼
(1.贵州大学计算机科学与技术学院,贵州 贵阳 550025;2.贵州省公共大数据重点实验室,贵州 贵阳 550025;3.中国科学院信息工程研究所,北京 100093)
1 引言
在网络空间安全态势日趋复杂的形势下,威胁情报驱动的网络安全防御成为业界关注的重点[1]。从海量碎片化的网络数据中挖掘威胁情报,采用知识图谱模型进行组织,支撑攻击路径预测、攻击溯源等,可实现海量数据驱动的威胁情报智能分析。
网络安全实体识别是威胁情报知识图谱构建任务中非常重要的一个基础任务[2],其目标是从网络安全领域的文本数据中提取出安全实体的语义类,如攻击组织、企业、漏洞、软件等。
网络安全实体识别属于一种特定领域的命名实体识别。命名实体识别是自然语言处理中的一项重要研究内容,主要有基于规则的命名实体识别方法、基于机器学习的命名实体识别方法和基于深度学习的命名实体识别方法[3]。由于深度学习方法能够自适应地提取文本的特征信息,不依赖大量的特征工程和额外的语言学知识,因此,深度学习被广泛地应用在命名实体识别任务中[4]。
Georgescu等[5]通过基于命名实体识别的解决方案来增强和检测物联网系统中可能存在的漏洞。王通等[2]使用深度置信网络对威胁情报知识图谱实体识别子任务中的安全实体进行有效识别。2003年,Hammerton[6]利用长短记忆模型(LSTM)抽取句子的序列信息,并通过条件随机场(CRF,conditional random fields)对命名实体的标签进行分类。之后,很多命名实体识别方法是在LSTM-CRF网络架构下融入各种句子隐含的特征信息。Collobert等[7]在2011年使用窗口化方法的神经网络和基于句子的卷积神经网络方法对命名实体识别进行了深入探索,在命名实体识别任务中取得了不错的效果。随后,Santos等[8]使用字符级的特征向量作为卷积神经网络的输入,来增强CNN-CRF模型。Chiu等[9]在Hammerton和Collobert等的工作基础上使用双向LSTM并融合卷积神经网络来获取词的字符特征,与Collobert的模型相比,利用双向LSTM模型打破固定窗口大小的限制。由于传统的卷积神经网络在提取大的上下文特征信息时会丢掉一些信息,2017年,Strubell等[10]提出利用空洞卷积神经网络进行命名实体识别,实验表明该网络能够弥补传统卷积神经网络的不足且进一步提高网络的训练速度。
He[11]、Liu[12]、Li[13]等通过实验表明了基于字符的命名实体识别方法一般比基于词的命名实体识别方法好。因此,秦娅等[14]针对传统的命名实体识别方法难以识别网络安全实体,提出一种基于特征模板的字符级CNN-BiLSTM-CRF网络安全实体识别模型。除了基于字的命名实体识别,还有基于词、融合字和词特征信息的命名实体识别方法。Xu等[15]将字和词的特征信息联合训练进行融合,其中,Zhang等[16]提出的Lattice LSTM中文命名实体识别网络结构取得了较好的实体识别效果,该方法将传统的LSTM单元改为网格LSTM,在字模型的基础之上利用词典,从而得到词与词序的特征信息,降低了分词带来的错误传播问题。
注意力机制(attention mechanism)[17]被广泛应用于自然语言处理任务。Bahdanau等[18]将注意力机制和循环神经网络(RNN,recurrent neural network)结合起来解决机器翻译任务,使注意力机制成功融入自然语言处理领域。Yin等[19]提出一种基于注意力机制的卷积神经网络,并成功地应用于句子对建模任务。Wang等[20]在关系抽取任务中证明了注意力机制和卷积神经网络结合的有效性。
与传统领域的实体识别相比,网络安全领域的实体识别发展比较缓慢,且仍存在以下几方面的挑战。
1)深度学习依赖大规模的标签数据,然而网络安全领域中缺乏大规模高质量的网络安全实体标注数据。
2)网络安全实体识别比较复杂,包含大量的多种混合安全实体,如“SQL注入”“80端口”。
3)全文非一致问题。即在一篇文章、段落或者长句子中相同的实体被赋予不同的类别标签。此外,存在实体缩写情况,即第一次提到实体时给出全称,在其后提到该实体时,仅仅给出该实体的缩写。
针对上述挑战,本文提出一种残差空洞卷积神经网络的安全实体识别方法。本文的主要贡献如下。
1)构建并开放了一个网络安全实体识别语料库,标注了6类典型的网络安全实体。
2)提出一种基于BERT[21]语言模型的残差空洞卷积神经网络命名实体识别方法,与基于注意力机制的BiLSTM-CRF网络结构相比,本文的模型可以接收句子的平行化输入,降低了模型的训练时间。
3)将残差连接与空洞卷积神经网络模型相结合,构建网络安全实体识别模型,无须使用诸如词性、依存句法等额外的特征信息。此外,以字符级特征向量作为模型的输入,降低了分词错误导致的误识别率。实验表明,本文提出的模型取得了比BiLSTM-CRF等模型好的安全实体识别效果。
2 任务定义
网络安全实体识别任务可以看作特定领域中的命名实体识别,其相当于自然语言处理中的序列标注问题。由于网络安全文本数据中的词条存在歧义和安全实体构成比较复杂,为了防止分词带来的错误传播问题,在字符层面进行序列标注是解决网络安全实体识别的关键问题。
本文以网络安全文本中的句子为基本单元,针对其中的任意一个句子,xN],xi是句子s中的第i个字符。在BIO标注方法[14]的指导下,识别句子s中的安全实体相当于给出标注序列。例如,句子s为“腾讯安全防御威胁情报中心检测到一款通过驱动人生系列软件升级通道传播的木马突然爆发”,其对应的序列标注sL是“B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O B-SW I-SW I-SW I-SW O O O O O O O O O O O B-RT I-RT O O O O”。
3 基于残差空洞卷积神经网络的网络安全实体识别模型
针对网络安全实体识别任务,本文在BERT预训练模型的基础上,提出基于残差空洞卷积神经网络和CRF相结合的网络安全实体识别模型BERT-RDCNN-CRF,如图1所示。
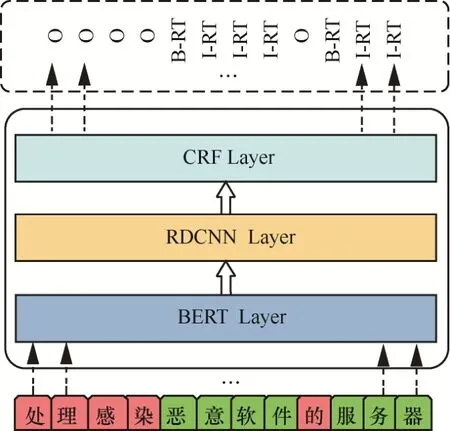
图1 基于BERT-RDCNN-CRF的网络安全实体识别模型Figure 1 Network security entity recognition model based on BERT-RDCNN-CRF
该模型在BERT预训练模型的基础上,采用RDCNN提取文本中的特征,为实体识别奠定基础,最后通过CRF层处理给出标注序列。
3.1 BERT预训练语言模型
BERT模型能从大量的无标签数据中学习词条或者字的前向和后向这种双向表示,并且在学习词条或者字的上下文表示过程中通过微调来解决词或字的歧义问题。BERT模型的框架如图2所示,其主要由输入层、双向的Transformer编码层和输出层组成。输入层接收输入句子的字嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)拼接而成的一个特征矩阵。Transformer编码层主要提取输入层特征矩阵中重要的特征信息。输出层通过一个前馈神经网络输出每一个字的嵌入表示。

图2 微调BERT模型在单句标注任务图示Figure 2 Illustrations of fine-tuning BERT on single sentence tagging tasks
本文以字为单位并将其作为BERT模型的输入,对于长度为n的句子s,其字嵌入表示为

其中,⊕为拼接操作符。
由于本文的输入为文本句子,所以对于长度为n的句子s,引入段嵌入作为句子对的区分界限。段嵌入全部初始化为0,如式(2)所示。

在网络安全实体识别任务中,字的位置特征是识别的关键特征。因此,BERT模型加入了位置嵌入,如式(3)~式(5)所示。


其中,pos为位置,i为维度,dmodel为模型的输出维度,为拼接操作符。
最后,将字嵌入、段嵌入和位置嵌入拼接起来作为BERT模型的输入,如式(6)所示。
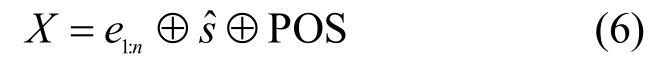
双向Transformer编码层通过“多头”注意力机制(multi-head attention mechanism)扩展了模型专注于不同位置的能力,增大注意力单元的“表示子空间”。“多头”注意力机制的基础是自注意力机制,自注意力机制主要计算句子中的每个字对于这个句子中所有字的相互关系,即将与该字相关联的其他字的特征信息编码进该字的嵌入表示中。自注意力机制的计算如式(7)所示。
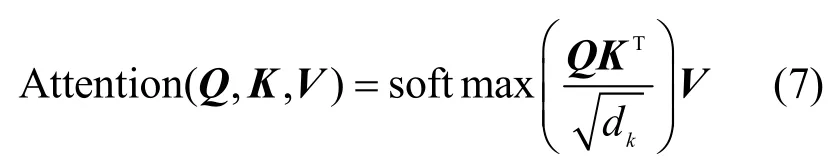
其中,Q、K、V分别是自注意力机制中的查询向量(query vector)、键向量(key vector)和值向量(value vector),计算方法如下。
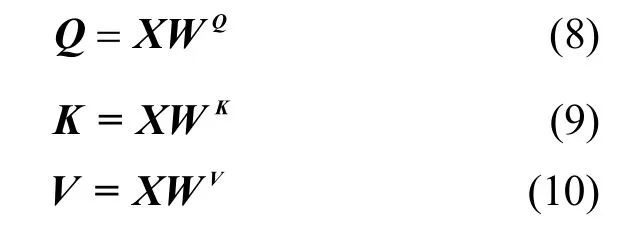
其中,WQ、WK、WV为权重矩阵,在模型开始训练时随机初始化。
由此,实现“多头”注意力机制的计算如式(11)所示。
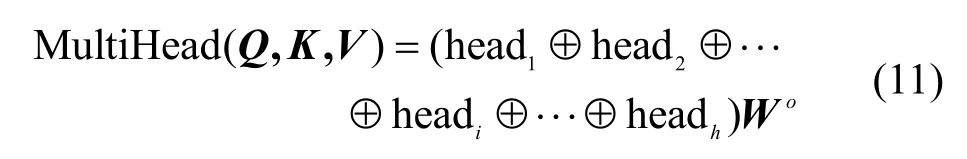
其中,⊕为拼接操作符,Wo为形状变换矩阵,是一个需要学习的参数,headi=Attention,。
最后,通过一个全连接层,输出每个字的嵌入表示,其计算如式(12)所示。
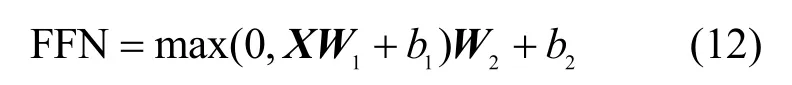
其中,W1、W2为权重矩阵,b1、b2为偏置,FFN为BERT模型的输出结果。
3.2 RDCNN -CRF命名实体识别模型
本节在BERT模型的基础上,提出网络安全实体识别模型RDCNN-CRF,如图3所示。RDCNN-CRF主要由输入层、空洞卷积层和CRF层组成。输入层接收输入句子的特征矩阵;空洞卷积层利用卷积核对输入的基本单位进行卷积操作提取特征。RDCNN的输入层将BERT模型的输出构建为一个特征矩阵传入模型中;CRF层通过提取到的特征信息输出字的命名实体标签分类结果。

图3 RDCNN-CRF模型框架Figure 3 Illustrations of RDCNN-CRF model framework
在空洞卷积神经网络的卷积层中,给定长度为h的卷积核,可以把句子分为,然后对每一个分量进行卷积操作,通过式(13)得到卷积特征图。
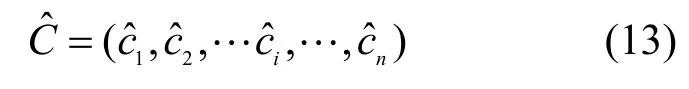
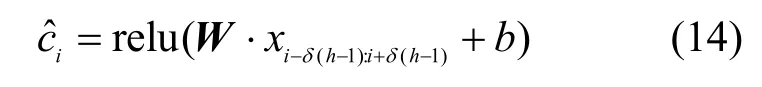
其中,W为卷积核权重,b为偏置,δ>1为空洞卷积神经网络的膨胀系数。若δ=1,此时的空洞卷积神经网络和传统的卷积神经网络等价。
由于对空洞卷积神经网络的卷积层进行简单的线性堆叠会使网络在训练过程中产生过拟合和退化问题,本文引用文献[22]提出的残差连接来防止退化问题,使用批正则化(BN,batch normalization)防止过拟合问题。残差连接的残差块计算如式(15)所示。

其中,x为输入,F()表示残差函数。
最后,通过CRF层得到字的实体标签分类结果。CRF能够考虑相邻字的实体标签之间的关系,这符合字的实体标签关系之间并不独立的特点,且充分利用了字实体标签的上下文信息。而通过直接对残差空洞卷积神经网络的输出获取其对应字的实体标签的结果取决于数据的性质和质量。CRF层的具体算法如下。
首先,定义一个状态转移矩阵A,这里的Ai,j表示标签i转移到标签j的得分,该得分会随着模型的训练而更新。另外,定义分值矩阵为空洞卷积层的输出分值,其中,[fθ]i,t是第t个字、第i个标签的RDCNN的输出分值,θ是RDCNN的参数。针对句子,N为句子的长度。定义为整个RDCNN-CRF模型需要学习的参数。这样,一个句子在给定标签序列的总得分计算为
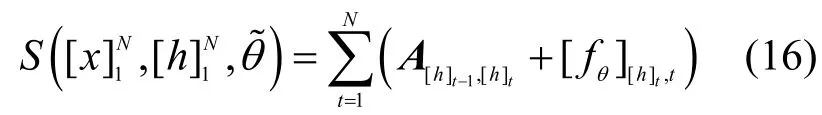

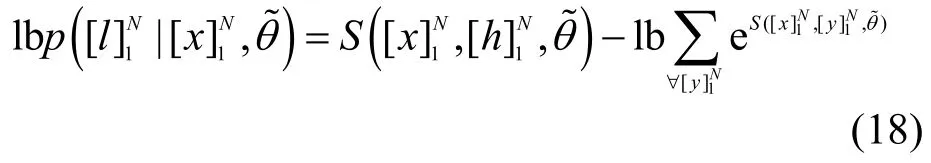
模型训练结束后,本文采用维特比算法来找到最佳标签序列。
3.3 模型训练过程
本文基于Tensorflow深度学习框架实现所提出的网络安全实体识别方法,具体训练过程如下。
本文提出的安全实体模型在训练的过程中先对BERT、RDCNN和CRF模型进行初始化,然后BERT对字进行编码,随后RDCNN进行解码提取出句子局部特征信息,接着CRF模型计算出字的安全实体标签;最后将错误向前传播更新各个模型的参数。
算法1BERT-RDCNN-CRF
输入
训练数据集T=(X,Y),其中,X,Y∈ℝV×n,|V|是数据集的大小,n是句子最大长度;
输出
实体标签序列;
1)初始化BERT,RDCNN和CRF;
2)fori=0,1,2,do
3)for batch do
4)BERT和RDCNN模型前向传播;
5)CRF前向传播和后向传播,计算出序列的全局似然概率;
6)对RDCNN和BERT模型进行后向传播;
7)更新BERT,RDCNN,CRF模型的参数;
8)end for
9)end for
4 实验与结果分析
本节将所提出的方法在构建的数据集上进行实验。在本文的实验中,字向量均采用Google预训练好的BERT中文字向量。BERT模型采用Fine-tuning策略,即模型参数采用Google预训练好的参数进行初始化,并可以在网络训练过程中自适应地调整BERT模型的参数。
4.1 实验数据
实验数据主要来自乌云漏洞数据库、Freebuf网站、国家漏洞库等主流网络安全平台的公开数据。网络安全实体主要有6种类型,分别是人名(PER,person)、地名(LOC,location)、组织名(ORG,organization)、软件名(SW,software)、网络安全相关术语(RT,relevant term)和漏洞编号(VUL_ID,vulnerability ID)。网络安全实体数据均采用BIO命名实体标注策略。数据集的具体统计信息如表1所示。实验中将标注好的数据集划分为训练集、验证集和测试集,分别占总数据集规模的70%、10%和20%。详见Github官网。

表1 数据集的统计信息Table 1 Statistic of datasets
本文采用精确率(P,Precision)、召回率(R,Recall)、F1值(F1-measure)和准确率(Accuracy)作为评价标准。
4.2 对比实验
为了验证本文提出的网络安全实体识别方法BERT-RDCNN-CRF的有效性,对12种模型进行对比实验。其中,前6组实验的词向量和字符向量是基于word2vec语言模型训练的,后 6组基于BERT预训练语言模型。实验代码可到Github官网下载。
1)CRF:文献[23]提出使用CRF对序列数据进行标注。
2)LSTM:文献[24]提出使用LSTM进行命名实体识别的模型。
3)LSTM-CRF:文献[25]提出结合CRF的LSTM命名实体识别模型。
4)BiLSTM-CRF:文献[26]提出考虑词上下文的双向LSTM结合CRF进行命名实体识别模型。
5)CNN-BiLSTM-CRF:文献[27]提出使用CNN学习词条的字符级特征信息,并将其和词拼接在一起作为BiLSTM的输入进行命名实体识别的模型。
6)FT-CNN-BiLSTM-CRF:文献[14]提出结合特征模板的网络安全实体识别模型。
7)BERT-CRF:在文献[21]中模型的基础上结合CRF进行命名实体识别的模型。
8)BERT-LSTM-CRF:在文献[25]的基础上将语言模型使用BERT代替。
9)BERT-BiLSTM-CRF:在文献[26]的基础上将语言模型使用BERT代替。
10)BERT-GRU-CRF:在BERT的基础上,使用普通GRU与CRF结合的命名实体识别模型。
11)BERT-BiGRU-CRF:在BERT的基础上,使用普通双向GRU与CRF结合的命名实体识别模型。
12)BERT-RDCNN-CRF:本文提出的识别方法弥补了CNN提取特征信息有限,并使用残差连接防止模型在训练的过程中出现过拟合的情况。
4.3 实验模型参数
在实验中,使用多种窗口卷积核对BERT的输出矩阵进行卷积操作。卷积核函数为rectified linear units,激活函数为Leaky ReLU。模型训练过程中采用Zeiler[28]提出的Adadelta更新规则,其他参数见表2。

表2 实验参数设置Table 2 Hyper parameters of experiment
4.4 整体对比实验及分析
本文将12组实验在网络安全实体识别数据集上进行实验,分析网络安全实体识别。表3给出了12组实验在网络安全实体识别数据集上总体的实体识别准确率、精确率、召回率和F1值。
从表3结果可以看出,整体上本文提出的方法在网络安全实体数据集上取得了不错的实体标签分类效果。其中,BERT-CRF、BERT-LSTMCRF、BERT-BiLSTM-CRF、BERT-GRU和BERTBiGRU-CRF模型在网络安全实体数据集中的命名实体识别准确率比传统基于特征的CRF命名实体识别模型、LSTM模型、BiLSTM模型、CNN-BiLSTM模型和基于特征模板的FT-CNNBiLSTM模型好。
对比文献[26]提出的CNN-BiLSTM-CRF模型和文献[13]提出的FT-CNN-BiLSTM-CRF模型可以看出,考虑了字特征信息的BERT-RDCNNCRF模型在网络安全实体数据集上的实体识别准确率相比考虑了词特征信息和字特征信息的模型的准确率高。这是因为网络安全的实体是由字母、数字和中文构成的,在分词的过程中会产生大量的分词错误,这种错误会随着模型的训练往后传播,影响模型最后对实体标签的分类效果。
从表3的结果还可以看出,模型BERTCRF的F1值相比不使用BERT模型的实体识别模型没有提高,但是加了能够提取文本的句法和表层特征的序列模型后,其F1值有较大的提高。说明安全实体识别模型在含有丰富的语义特征基础上利用文本的句法和表层特征能提高实体识别性能。
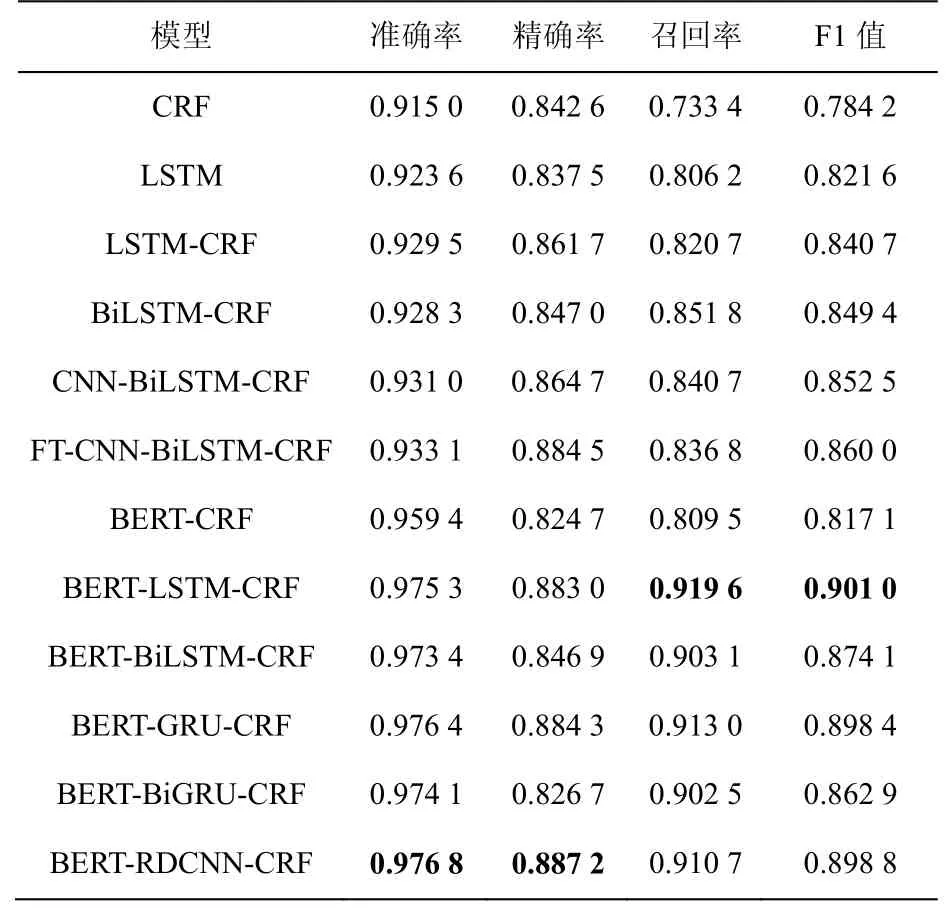
表3 不同模型的网络安全实体识别对比结果Table 3 Comparison of cyber security entity recognition results of different models
为了进一步说明基于BERT预训练模型的LSTM、BiLSTM、GRU和BiGRU模型与本文提出的方法在网络安全实体识别任务中的实体识别效果,本文进一步做了对比实验。从表3的结果可以看出,在准确率和精确率方面,本文提出的方法比其他基于BERT模型的网络安全实体识别模型好,说明本文提出的方法在网络安全实体识别任务中的有效性,并且在使用BERT模型的前提下,单向的LSTM模型和GRU模型比双向的LSTM模型和GRU模型在网络安全实体识别任务中效果更好。然而,从召回率和F1值的结果来看,BERT- LSTM-CRF均取得了最好的结果,分别是91.96%和90.10%。与本文提出的方法在召回率(91.07%)和F1值(89.88%)上相比,分别提升了0.89%和0.22%,说明本文提出的方法在这两个评价指标上与能够提取字的序列特征的模型相比差距不大。
4.5 6类安全实体识别对比实验及分析
为了进一步比较基于BERT模型的安全实体识别模型在不同安全实体上的识别效果,本文计算出这6种安全实体的精确率、召回率和F1值,其中精确率如图4所示。
从图4可以看出,BERT-CRF模型在SW和VUL_ID两类安全实体上的实体识别效果非常差。所有实体识别模型在安全实体SW上的精确度比较低,最高的精确率才50.26%,其中BERT-LSTM-CRF模型、BERT-GRU-CRF模型和BERT-RDCNN-CRF模型的精确度相近,说明这些模型不擅长识别安全实体SW,这是因为一方面该实体在安全实体数据集中的数量较少,另一方面这类实体通常由数字、字母和汉字组成,构成非常复杂,特征不好提取。
6种安全实体识别模型在安全实体LOC、ORG和PER上的实体识别效果相差无几且精确率较高,说明6种模型能够对LOC、ORG和PER这种简单的实体特征信息进行充分提取。对于安全实体RT,BERT-CRF模型的精确率最低,本文提出的方法比BERT-LSTM模型的精确率高0.52%,说明无论是使用改进的卷积网络还是使用能够存储句子序列信息的LSTM,在安全实体RT上都能取得较好的精确率。在安全实体VUL_ID的结果中,BERT-GRU-CRF模型取得了最高的精确率,比BERT-LSTM-CRF模型提升了0.28%,比本文提出的方法提升了4.13%,说明能够存储句子序列信息的LSTM模型和GRU模型在安全实体VUL_ID的精确率上更有优势。
从图4中还可以看出,使用双向BiLSTM模型和双向BiGRU模型的精确率比使用单向的LSTM模型和GRU模型的精确率低,这是因为模型的复杂度增加会产生过拟合问题,损失函数的损失值在模型训练过程中很难下降。为了更进一步比较6种模型的安全实体识别性能,对不同模型在不同安全实体上的召回率进行对比,如图5所示。
从图5的结果可以看出,6种模型在6类安全实体上的召回率和图4的结果差不多。值得注意的是,BERT-LSTM-CRF模型和BERT-GRUCRF模型比其他模型取得了更好的召回率,这说明在召回率这一评价指标上,这两种模型能够召回更多的安全实体。

图4 不同模型在不同安全实体上的精确率对比Figure 4 Comparison of accuracy of different models on different security entities

图5 不同模型在不同安全实体上的召回率对比Figure 5 Comparison of recall of different models on different security entities
为了平衡精确率和召回率,不同模型的F1值如图6所示。从图6中可以看出,BERT-CRF模型、BERT-BiLSTM-CRF模型和BERT-BiGRUCRF模型对于复杂的安全实体RT、SW和VUL_ID的识别效果不是很好。对于安全实体PER的识别效果这6种模型相差无几,说明这6种模型都适合用来识别PER这样的安全实体。对于安全实体LOC的识别效果,BERT-RDCNN- CRF模型、BERT-LSTM-CRF模型、BERT-GRU- CRF模型和BERT-BiGRU-CRF模型的F1值比BERT-CRF模型和BERT- BiLSTM-CRF的F1值有不同程度的提升。对于安全实体ORG,BERT-RDCNN-CRF模型和BERT-LSTM-CRF模型的F1值比其他模型的F1值有不同程度的提升。以上结果表明,本文提出的方法在各种安全实体识别任务中的鲁棒性和有效性。
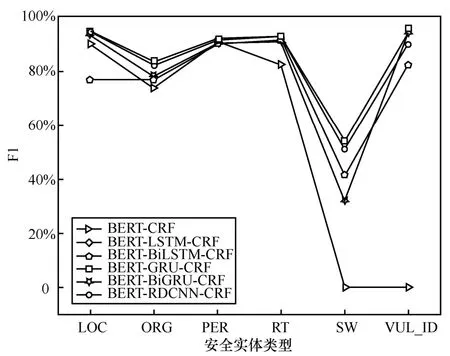
图6 不同模型在不同安全实体上的F1值对比Figure 6 Comparison of F1-measure of different models on different security entities
4.6 参数调整分析
本文提出的安全实体识别方法和其他传统的神经网络方法一样,通过最小化损失函数来进一步更新模型的参数。而损失值在模型训练过程中的变化情况表示该模型在训练过程中是否学习和是否稳定等。进一步分析模型在训练过程中损失值的变化情况如图7所示。
从图7可以看出,模型在整个训练过程中损失值是下降的,说明模型能够学习网络安全实体的相关特征信息。此外,由于本文提出的方法参数太多并且损失值整体上下降,进一步表明本文模型在训练过程中具有鲁棒性。从图7中还可以看出,损失值的下降曲线并不是平滑的,这主要与最小化损失函数的优化算法和学习率的设置有关,从整体上看依然能够说明本文所提方法的鲁棒性。
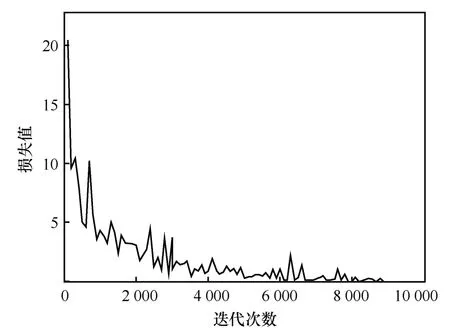
图7 损失值曲线Figure 7 Loss value curves during training on network security entity datasets
4.7 实例分析
为了进一步分析本文提出方法的实用性,从网络安全实体识别数据集中抽取一些典型句子的实体标签分类结果进行分析。经典句型分析如表4所示。
从表4中可以看出,对于句子1这种结构简单的实体识别,本文提出的方法能正确识别出实体的标签。在句子2中,本文提出的方法除了准确识别出安全实体PER和RT,还识别出了安全数据测试集中没有标注的ORG实体类型。另外,在句子3和句子7中,本文提出的方法均能准确识别出安全数据测试集中没有标注的ORG和SW实体类型,说明本文提出的方法具有识别与训练集中相似实体的新实体的能力。对于句子8和句子9这种VUL_ID类型的英文字母和数字构成的实体,不管该实体是单独出现在句子中还是成对出现在句子中,本文提出的方法均能准确识别出该类型的实体。此外,诸如“暗云Ⅲ”这种汉字加罗马字符的安全实体,本文提出的方法均能准确将其识别出来。“IP地址”这类英文字母加汉字构成的实体也能被准确识别出来,如句子5所示。
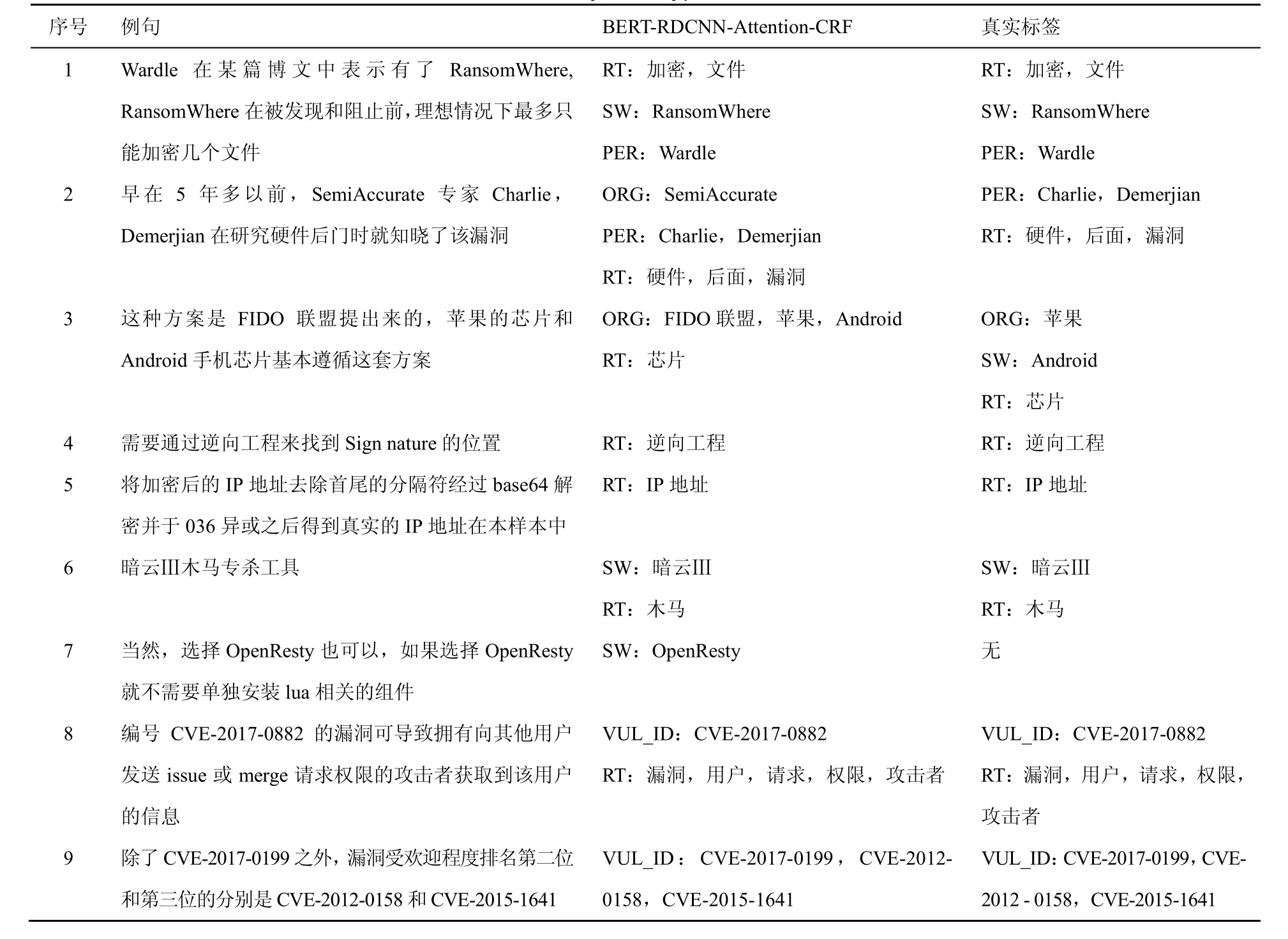
表4 经典句型例子分析Table 4 Analysis of typical sentences
然而,在句子3中,前一个实体“芯片”被准确识别出,而后一个实体“芯片”却没有被准确识别出来,Android却被误识别为ORG实体类型,这可能是因为Android前面有两个ORG实体类型,算法在提取上下文信息的时候误认为android也是ORG类型的实体。
除了表4展示的这些典型例子,在实验过程中,对于较长的ORG这种实体类型算法,往往不能准确将其识别。换句话说,对于名称较长的实体,不管是构成简单的还是构成复杂的模型往往不能将其准确识别出来。所以,本文提出的方法更加适用于安全实体中名称不是很长和实体构成相对规律的安全实体。
5 结束语
针对开放网络文本数据中的安全实体构成非常复杂的问题,本文提出了一种基于残差空洞卷积神经网络的网络安全实体识别方法。使用BERT模型对字进行向量化表示,进一步结合空洞卷积神经网络和CRF准确地识别网络安全实体。在网络安全实体识别数据集上的实验结果表明,本文提出的基于残差空洞卷积神经网络的方法在准确率和精确率方面优于许多已有的实体识别方法。
通过分析经典句型可以看出,本文提出的方法在某些安全实体类型的识别上是存在不足的,仍然不能准确识别出一些安全实体。在下一步的工作中,考虑从网上爬取大量的网络安全数据,使用表示能力较强的语言模型训练出网络安全领域的字嵌入。并且,针对网络安全数据集中安全实体的数量不平衡问题,对相应的安全实体数量进行补充或者在模型训练的过程中采用解决数据不平衡的训练技巧。此外,进一步提高较长的安全实体的识别准确率。
