基于HRCA的可重构SM4密码算法研究与实现
2020-10-21张骁周清雷李斌
张骁,周清雷,李斌
(郑州大学信息工程学院,河南 郑州 450001)
1 引言
开放的互联网环境必然带来诸多安全问题,为保证网络中通信与数据交换的安全性,通常将传输的数据进行加密保护。SM4分组密码算法比国外使用的同类算法具有较高的安全性[1-2];同时它作为国家密码管理局发布的密码行业标准,适用于无线局域网和可信计算系统中,主要对具有敏感性的内部信息、行政事务信息、经济信息等进行加密保护。
目前对SM4分组加密算法方面的研究主要有:文献[3]提出了“一次一密”的加密机制,主要解决SM4算法加解密使用相同的密钥并缺乏对密钥保护的问题,从而提高整个算法的安全性;文献[4]基于SM4的通用结构,利用混合线性整数规划设计出一种较优的认证加密算法SAME;文献[5]结合AES-GCM实现了SM4-GCM方案,通过乒乓操作提高数据处理速度,并验证了方案具有更高的吞吐量和较低的资源消耗;文献[6]提出了一种逻辑化简方法,通过减少算法关键路径上时延,设计出多轮合一的组合逻辑电路减少时延,从而提高SM4算法在CBC模式下的吞吐率;文献[7]针对SM4-CTR模式进行了优化,实现了高吞吐率的ASIC设计。
随着处理数据量的增大和多种加解密模式的出现,上述方案无法完全满足大规模文本、物联网、云计算以及视频流媒体等复杂多变的应用场景对多种加密模式的需求。为了满足高速的网络传输环境和密码行业标准的要求,本文基于可重构计算提出了适用于超混合可重构计算阵列(HRCA,hybrid reconfigurable computing array)上映射实现的SM4加密算法方案。首先,基于可重构计算思想对SM4算法计算、存储与通信特征的分析后,实现了粗粒度的可重构计算单元。接着,对SM4进行多种映射展开以适应不同的加密工作模式,并对SM4整体架构进行了优化设计,提高了算法的灵活性与可扩展性,在保证高性能与安全性的前提下满足了不同应用场景的需要。
2 研究背景
2.1 SM4算法原理
SM4迭代分组密码算法采用非平衡Feistel结构,数据分组长度均为128 bit,加解密算法与密钥扩展算法均为32轮非线性迭代结构,加密密钥和解密密钥相同[8]。SM4算法加密结构与轮密钥结构如图1所示。
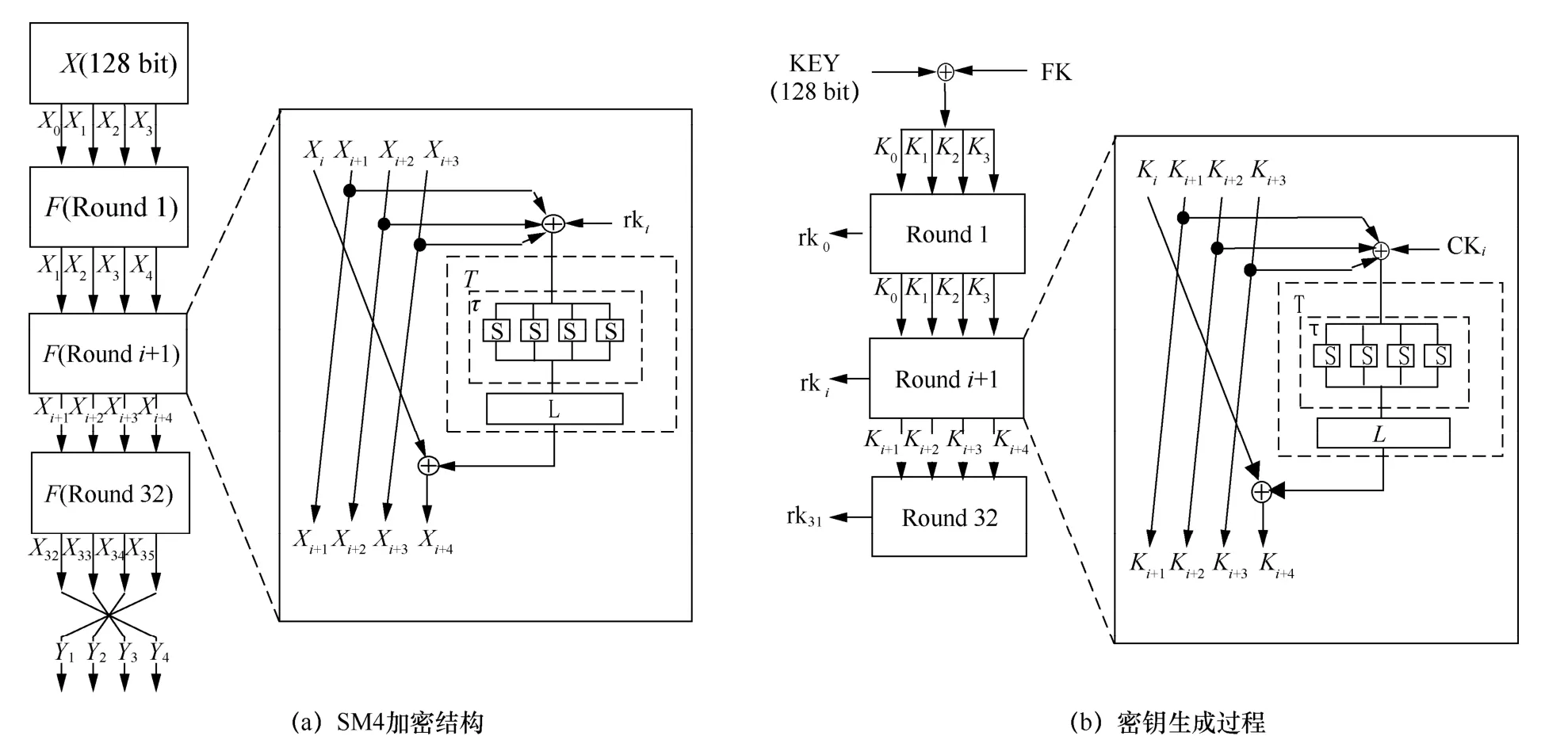
图1 SM4分组密码算法与密钥扩展算法Figure 1 SM4 block cipher algorithm and key expansion algorithm
SM4算法包含轮函数F、合成置换T、非线性变换τ、线性变换L以及逆序转换R等函数过程。设明文输入为,密文输出为,加密密钥为,轮密钥为。SM4算法的解密结构与加密结构相似,但两者轮密钥的使用次序不同,加密时轮密钥使用次序为(rk0,rk1,rk2,…,rk31);解密时逆序使用轮密钥。SM4的加密原理描述如下。
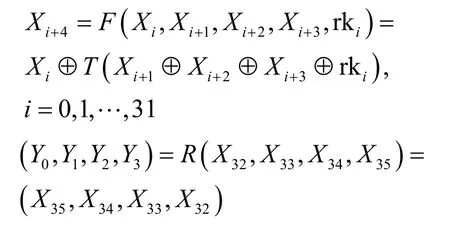
其中,T为合成置换,由非线性变换τ和线性变换L复合而成,即T(·)=L(τ(·))。线性变换L由移位操作完成,即;非线性变化τ由S盒扰乱构成,输入,非线性变换可以描述为
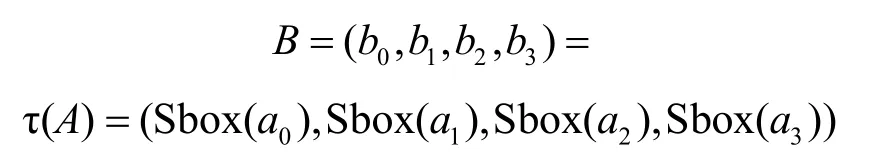
轮密钥由加密密钥通过密钥扩展算法得到,FK与CK均为固定参数组,用于密钥扩展算法。SM4密钥扩展算法公式如下。

T′与加密算法轮函数T基本相同,只是线性变换移位长度不同,为
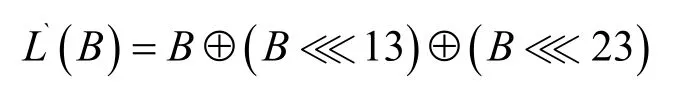
2.2 超混合可重构计算阵列原理
由于研究角度不同,人们对于可重构计算(RC,reconfigurable computing)的定义不尽相同。在1999年ACM国际会议上,由美国加州大学伯克利分校可重构技术研究中心的Dehon等[9]提出的定义是目前比较公认的。可重构计算结构综合软件的灵活性和硬件的高效性,利用生产加工后结构上的空间特性优化算法,通过对可重构处理单元硬件资源进行编程配置可以实现算法到计算引擎的空间映射,进而可以从时间和空间多维度上对计算任务进行展开。重构粒度是指可重构系统中映射工具所能寻址最小的处理单元数据通路的位宽[9]。依据可重构单元的不同粒度,可重构计算系统可依次分为细粒度、粗粒度和混合粒度可重构计算系统。
HRCA是一种新提出的可重构阵列,能够以可重构方式支持不同精度和多种聚合单位的变化[10]。HRCA具有应用驱动、非指令执行和高度可扩展等特点。其中,应用驱动是指通过对具体应用的分析从算法中提取可共用的基本操作,并形成在硬件上易于实现的基础算核集,在此基础上构建各种粒度的可重构单核;非指令执行与通用处理器结构对算法的执行过程有所区别,将算法直接映射到硬件结构中实现,即粗细粒度单元在单核内以硬件可重构方式实现算法中的基础算核集,减少了通用处理器取指译指的开销,进而大幅提高执行效率;高度可扩展是指核间采用全局异步、核内采用局部同步的互联通信方式,可实现以单核为基础的高度可扩展。HRCA结构如图2所示,HRCA中可重构单元构成的更大规模硬件结构Re_Eng形成了可以支持应用算法各子模块的高阶运算栈。对比通用处理器结构,在HRCA中具有一定相似度的基本操作由不同粗粒度的高效可重构计算单元完成,各计算单元间的互联结构支持具有并行特点的数据流,使高阶运算栈在计算过程执行上效率更高,因此通过这些结构可以支持各种应用的核心算法在计算过程中高效实现。
3 基于HRCA的可重构SM4实现
3.1 基础算核的提取
为满足高性能可重构计算阵列设计需求,需要对复杂的算法和计算部件进行分析,在一定条件下将复杂计算问题分解成若干简单的计算,并刻画出适合的粗粒度计算可复用算核,减少冗余的资源开销,提高算法的映射效率。统计目前公开文献中分组密码算法的基本操作,可以发现分组算法仅由有限的几种操作构成[11]。这给算核提取与可重构计算单元的构建提供了便利。
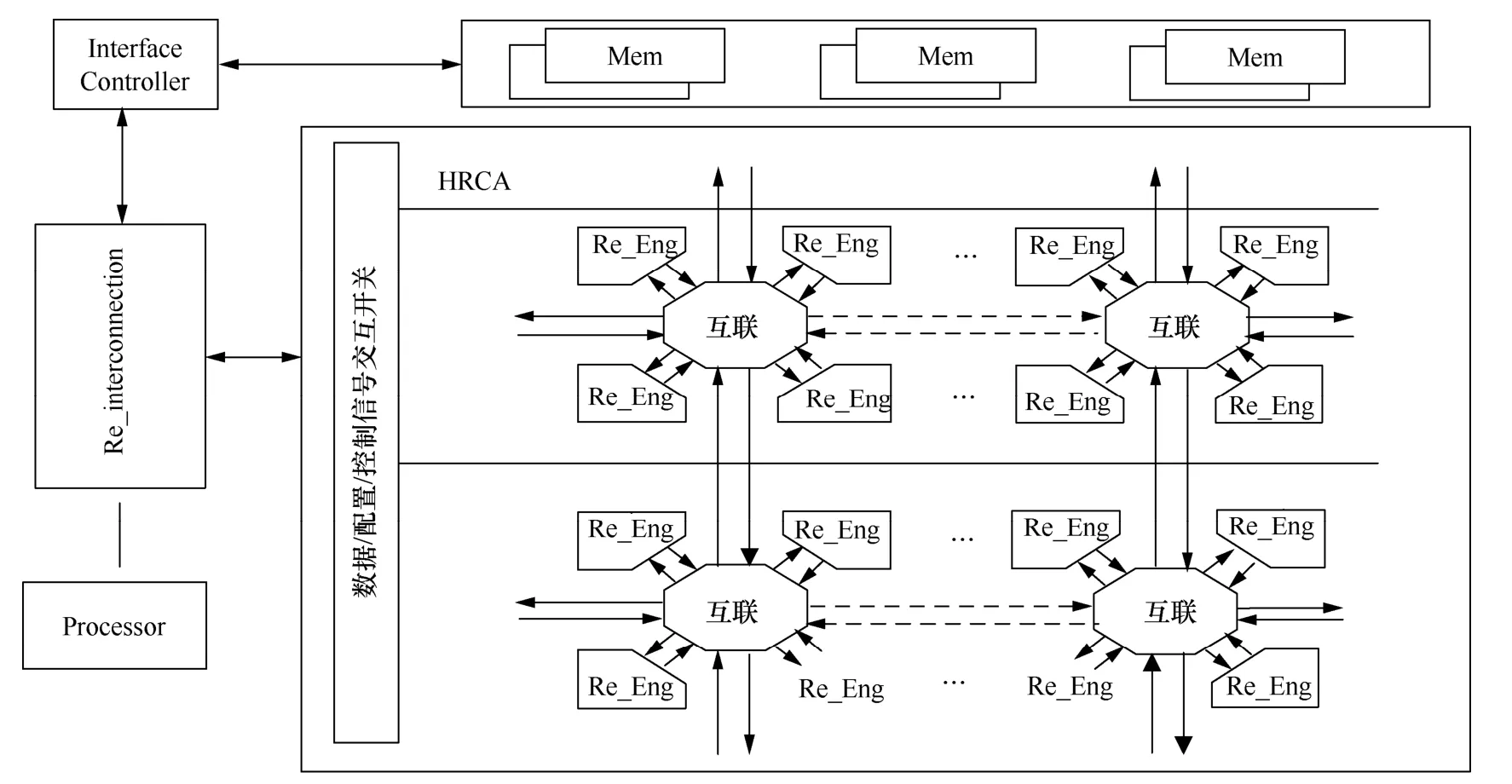
图2 HRCA结构Figure 2 HRCA structure
作为构建HRCA中关键的算核提取过程,在所选算法满足可重构的前提下,保证提取出的算核在重构过程中被使用概率基本一致,基础算核集提取过程如下。
令HRCA芯片上总资源为R,基础算核集表示,其中,bn为算核个数。CKi所需要资源为ri,则重构算核所需要资源即为。算法重构时所需要连接资源记为ra。算核CKi被算法调用时表示为

则算核CKi的利用率为
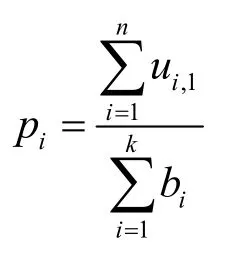
求解基础算核集的算法是一个迭代过程,从算法各步骤所需算核集的简单并集出发,调整使用算核集合,使算核利用率的方差最小。
根据基础算核提取过程,在SM4算法中提取出以下基础算核:S盒的查找表(LUT),以S盒内存放的数值替换相对应的输入,查找表通过互联方式使其他运算单元共享使用;移位操作包含对多种移位位数的处理;逻辑计算主要用于完成对多组相同位宽的输入数据进行异或运算;比特位操作用于对数据进行拼接和拆分,使数据分组的位宽符合算法要求。SM4算法主要基础算核如表1所示。
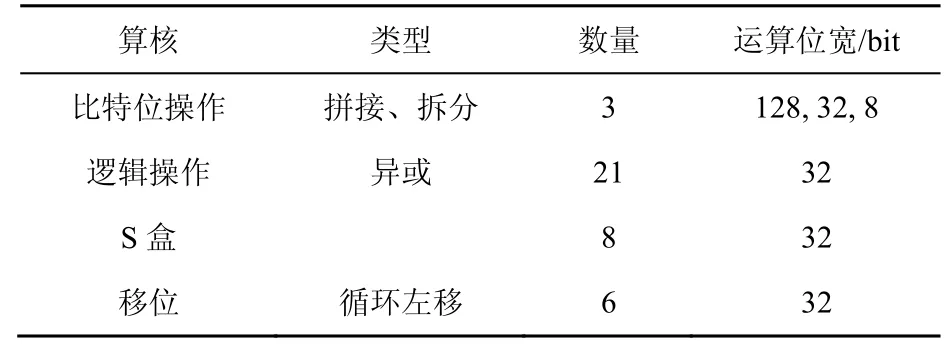
表1 SM4主要基础算核Table 1 Basis computing kernel of SM4
3.2 粗粒度可重构单元
粗粒度的可重构体系结构主要针对计算密集型应用,一般要求配置的最小数据位宽大于4 bit,可以并行处理大量算数运算。同时,SM4作为分组加密算法具有如下特性:运算类型集中,加解密过程主要通过轮函数运算完成;循环迭代为主,需要经过32轮完全相同的轮函数运算;密钥扩展过程与加解密过程结构基本相同且形式固定。因此,在提取相关算核的基础上,除部分移位操作外,可以对算法中关键操作进行重构,使用相似的结构与运算单元来实现算法。本文将SM4算法中每一次轮函数单元计算构建为粗粒度重构运算单元[12]。
粗粒度可重构运算单元作为可重构的适用于HRCA的高阶运算栈,包含逻辑功能单元、选择器、寄存器组、算术逻辑单元和移位异或选择单元,其基本结构如图3所示,主要功能如下。
(1)逻辑功能单元:作为控制配置中心负责接收阵列中的配置信息,主要执行以下几个任务。一是控制粗粒度可重构单元待执行的运算功能;二是确定片上存储器和主存储器之间的运算类型以及数据的流向,通过不同的配置条件确定任务特征及部件状态,将任务分配到匹配的部件或子结构上计算;三是允许配置IV寄存器使算法工作在不同的加密模式下。
(2)选择器:用来处理输入数据的拆分与拼接,拆分成32位数据字长并输入算术逻辑单元进行计算。
(3)寄存器组:作为片上阵列中的存储单元为运算部件提供加密算法所需的系统参量和固定参量,同时存储一些必要的中间结果。
(4)重构的算术逻辑单元RE_ALU与异或移位单元RE_L:作为依据算法处理流程中提取出的基础算核所重构而成的逻辑部件,是完成SM4算法运算的主要功能模块。RE_ALU主要完成32位加减法、逻辑异或运算等基本算术和逻辑操作,并通过查找表的方式对S盒访问,将计算数据作为SBOX存储器的地址,并将相应地址中的内容作为输出,从而在算法中实现数据的替换功能。移位异或选择单元RE_L和RE_L`在完成基本的逻辑异或操作基础上分别完成不同位长的移位操作。
粗粒度可重构运算单元的运算周期为一个时钟,运算单元按照运算步骤划分算法,确保了多个重构单元可以串行或并行地映射到流水线上,达到提高计算性能和效率的目的。可重构单元作为HRCA中的高阶运算栈Re_Eng采用交叉的可重构互联结构,充分利用单元件的程序执行局部性,提高系统的灵活性与可扩展性。
3.3 SM4算法结构的映射策略
SM4作为分组密码算法拥有多种工作模式,其中,CBC模式和CTR模式具有较高的安全性[13]。CBC模式中存在数据依赖性,不适于使用流水线并行结构,而CTR模式适合数据分组,不存在依赖性,可并行实现[14-15]。为了同时满足CBC和CTR等加密模式的SM4分组算法的运行,本文按照不同策略对算法分别进行循环串行展开映射以及流水线并行展开映射以提高算法在不同工作模式下的处理性能,同时降低对硬件资源的占用。构建的粗粒度可重构计算单元作为算法中的关键循环块,将运算分配到这些可重构计算单元上进行执行。
3.3.1 循环迭代映射
这种结构下完成一组数据的加解密只需要进行原来轮计算次数的一半,即32次轮计算,则总耗时为32TF+32Treg。这种映射方式中,轮函数在资源和时间上的开销是整个算法的主要部分,算法运算时间缩短了一半。该映射方案可以应用于实现CBC模式下的SM4加解密运算。
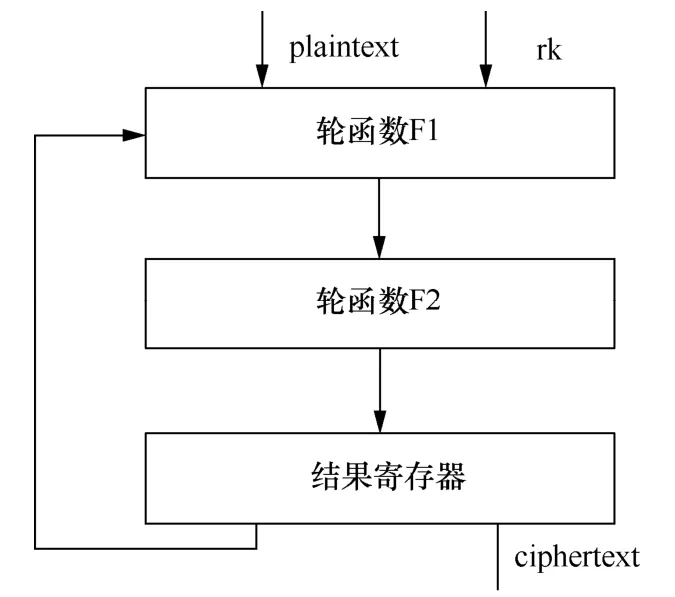
图4 2合1逻辑结构Figure 4 2 in 1 logical structure
3.3.2 流水线映射
由于HRCA中单元的粗粒度可重构计算单元的独立性,算法可以映射到多个计算单元进行流水线运算。流水线映射策略主要有两种:一种是循环展开的全流水线映射,即将循环迭代过程分配到不同的计算单元;另一种是基于数据分配的方式,由不同单元独立承担完成数据全部的运算任务。全流水展开方案中,将密钥扩展运算和加解密运算中的轮运算作为主体进行映射,不同的可重构计算单元承担不同迭代次序的轮运算,同一组数据的处理由多个计算单元共同完成。流水线映射方案主要可以实现CTR模式下的SM4加解密运算。
在循环展开的全流水映射中,加密过程的流水线分为两级,分别是密钥扩展运算流水线和轮函数运算流水线,全流水线映射时空图如图5所示。密钥和明文数据被分配进入不同的流水线进行处理,加解密流水线需要在密钥扩展流水线完成第一轮计算得到轮密钥后才可以启动。流水线从接收到第一组明文和密钥直至填满整个流水线需要经过33FT,因此该流水线映射方案时延仅需33个时钟周期。在同一条流水线中,由不同的运算单元承担不同迭代次序的运算,中间结果直接由下一级运算单元接力处理,因此不需要寄存器存储中间结果。这种映射策略在加密过程中具有较好的表现,既减少了存储中间结果资源消耗也减少了通信消耗。但是,该映射方案在解密过程因为轮密钥逆序使用需要增加一组寄存器进行存储,并且需要等待全部轮密钥计算完成。因此,仅在密钥更新周期长的情况下具有良好的性能,在密钥频繁更换的情况下解密速度和循环迭代的串行速度一致。
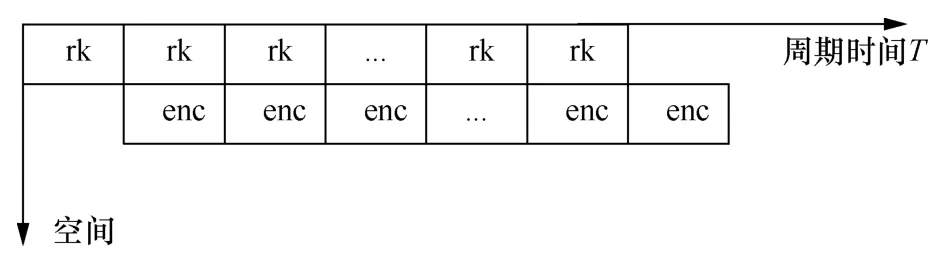
图5 全流水线映射时空图Figure 5 Full-pipeline space-time mapping graph
基于数据分配的流水线映射方式,将分组数据直接分配给可重构处理单元,密钥扩展和加解密在同一条流水线中。加解密运算需在完成所有密钥扩展运算后才可以开始,因此每条流水线的中间轮密钥结果都需要使用寄存器进行存储。流水线从被分配到数据直至整个流水线被填满需要经过64TF,因此该流水线映射方案的时延为64个时钟周期。该映射方式的流水线时空图如图6所示。相较于全流水线映射策略,基于数据分配的映射策略可以将加解密过程统一在一个策略下,但中间结果需要大量FIFO进行存储。
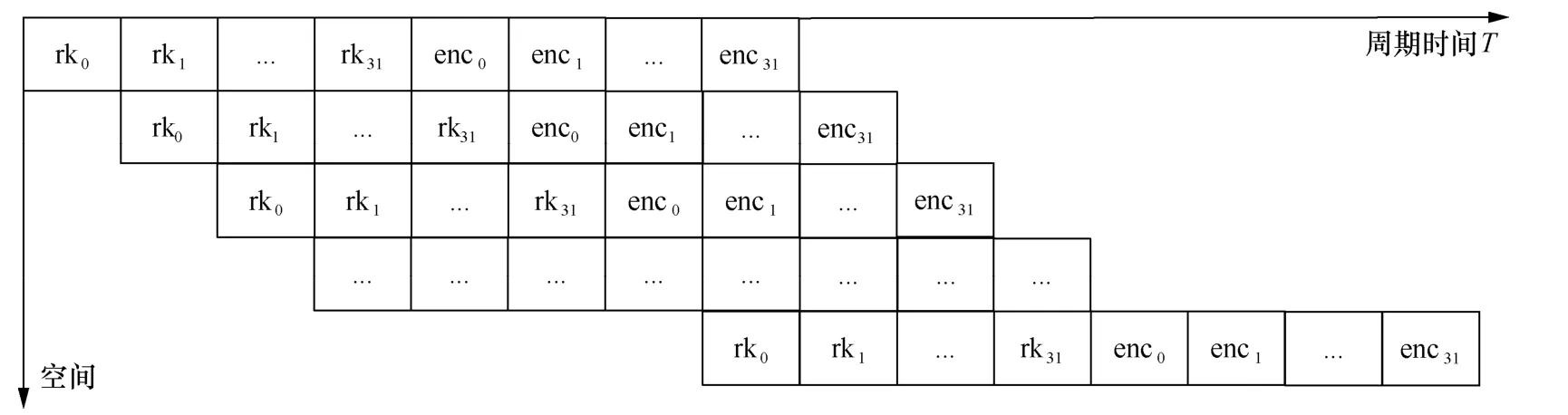
图6 基于数据分配的流水线映射时空图Figure 6 Data distribution based pipeline mapping space-time graph
具体分析两种流水线映射方式带来的性能提高,主要包括以下两个方面。
基于国家职业教育资源库的建设成果,我们将混合式教学方式应用于2017年春季,面向乌鲁木齐职业大学信息管理、计算机网络及物联网应用技术三个专业学生开授的“Java语言程序设计”课程中,修课学生为118人。课程结合笔者主持的“混合式教学方法在程序设计教学中的实证研究”课题,采用“智慧职教云”平台辅助教学并进行教学改革尝试。课程设计将课堂教学与云平台学习同步。学生自我学习和教师讲解异步教学有机结合,为学生提供一个持续学习的环境,主要包含建构基于国家职业教育资源库的云平台学习环境设计、线上线下的课程内容设计、多元互动的学习活动设计以及多维度的学习评价方式等。
(1)流水线的使用可以减少系统运算部件的空闲时间。由于SM4需要经过密钥扩展流程得到轮密钥才能进行加密过程,得到一组完整的加解密数据的时延至少是64个周期,其中32个周期用来进行轮密钥计算,另外32个周期进行加解密过程。这就造成一半的时间主要运算模块处于等待状态。用流水线方法映射SM4算法,可减少运算单元的等待时间,大幅度提高资源利用效率。
(2)减少通信量。如果运算单元按照顺序执行时,系统需要为这些模块的数据预留很多空间来存储中间运算结果,同时在时序上增加了中间数据的存储与读取。采用流水线的方式并行处理各个运算单元可以减少中间数据存储和通信的开销。
3.4 整体算法优化
为了使FPGA芯片满负荷工作,基于控制算法细化、模块化和最佳适用性原则,本文按照所选择硬件架构对整体算法进行设计,主要划分为控制平面的上层控制和数据平面的核心算子两部分完成。
SM4整体结构如图7所示,主要包括控制平面的轮密钥扩展控制与加解密控制以及数据平面的密钥扩展模块与加解密模块。加解密模块仅用控制命令确定算法进行加密操作还是解密操作。控制平面通过实例化多个核心算子以及放置多条流水线以增加芯片的利用率,并对各算子进行资源的分配回收与任务的分发调度,同时可以控制加解密模式,选择算法运行在串行或流水行结构中。数据平面的核心算子分为密钥扩展模块和加解密模块,这些模块主要由粗粒度可重构计算单元组成,模块间可以进行数据传输。SM4算法作为计算密集型任务在数据平面通过可重构计算单元高速实现,使管理控制与数据间存在不同的吞吐量和复杂度。因此,通过控制平面与数据平面的分割避免速度差异导致算法整体性能降低。
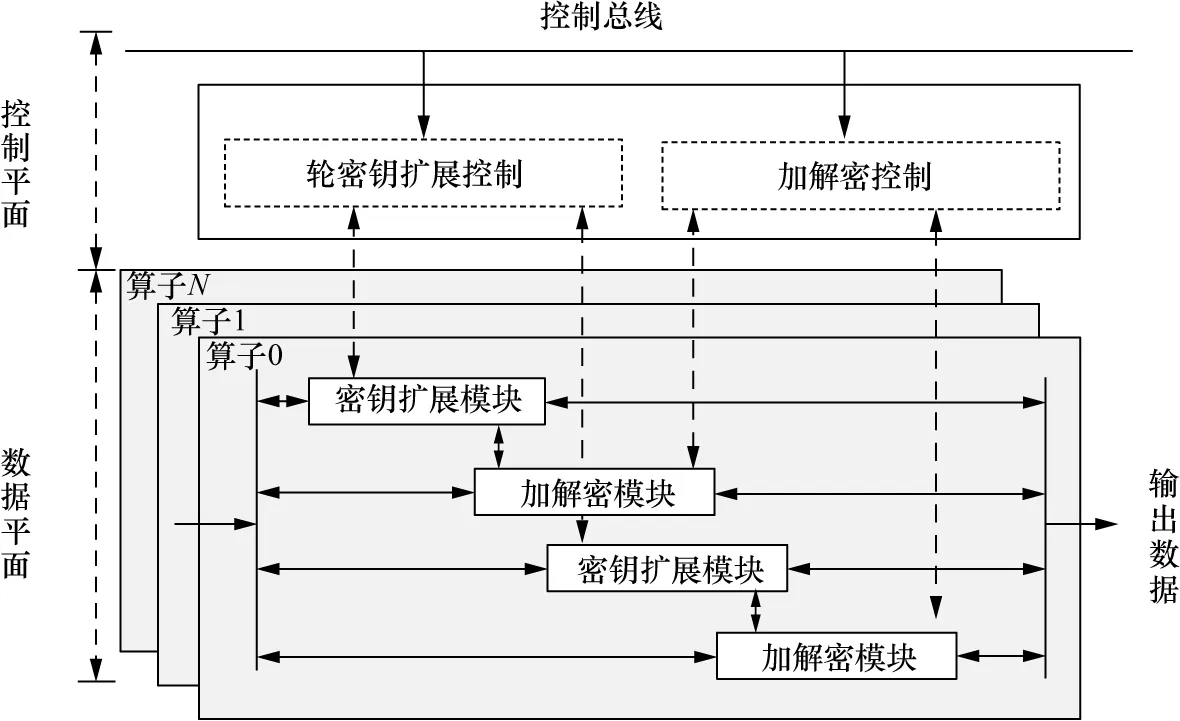
图7 SM4整体结构Figure 7 Overall structure of SM4
4 实验与性能对比
为评估本文提出的粗粒度重构计算单元与多种展开方案并验证性能与资源开销,本文使用Verilog HDL硬件描述语言对以上方案进行描述,然后使用XILINX公司的Vivado2018.2进行功能和时序仿真验证算法功能的正确性,并在FPGA集成加速卡进行实现,芯片型号为XILINX公司的XCKU060。
4.1 资源占用
表2给出了本文各种映射方案的资源开销情况。从表中可以看出,循环迭代映射与流水线映射中,流水线并行策略消耗资源多,因为后者为达到可用的流水线级数需要的可重构计算单元较多。在全流水线并行和数据分配并行中,后者每一级流水线都需要寄存器存放中间结果,因此所需资源明显增多。

表2 不同方案资源开销情况Table 2 Resources utilization of different schemes
4.2 性能对比
本文在对SM4进行重构的基础上,通过多种映射策略对算法进行实现。表 3给出了本文所有映射策略的性能。从表中看出,在流水线展开策略有较高的吞吐率,可达到25.6 Gbit/s。
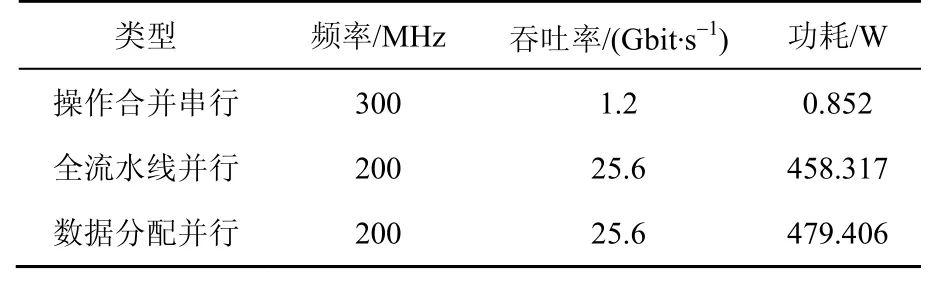
表3 不同方案性能分析Table 3 Performance analysis of different schemes
为了尽可能利用芯片资源,在200 MHz频率下对循环迭代映射和流水线映射方案分别实例化了41个SM4算子和20个SM4算子,占用资源分别为82%和80%。为了说明本文基于可重构计算单元进行映射在性能方面的提高,给出了与其他文献提出的方法的对比情况,如表4所示。
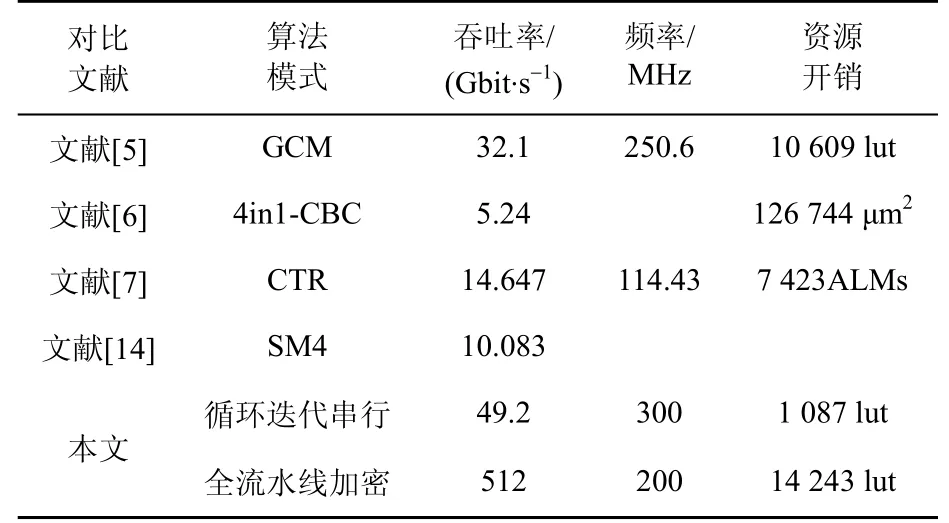
表4 不同文献性能与资源对比Table 4 Comparison of performance and resources with other references
5 结束语
当前SM4算法的应用主要集中在专用ASIC和CPU这两种平台上实现,然而,随着应用需求的不断发展与极速变化,应用使用SM4算法进行身份认证、系统自检以及数据加密等不同的场景阶段所需加密的数据量与工作模式有所不同,上述两种平台不能平衡性能与灵活性的需求。针对这些问题,本文基于超混合可重构计算阵列对SM4算法进行了算粒集提取和粗粒度可重构单元的设计,同时对算法按照不同的策略进行了展开,结合FPGA并行性和灵活可编程的特性,通过状态机实现减少访存时间,使算法处理速度进一步提高,兼顾了高性能与灵活性。通过实验分析了不同映射方案对性能和资源的影响,结果表明,对于CBC模式使用的串行运算和CTR模式使用的流水线运算,本文通过采用重构设计和映射方案,在单算子和多算子情况下对算法的运行效率有不同程度的提高。本文方案可以加快数据的加解密速度,并通过配置可在硬件平台下实现多模式转换,在要求算法具备多种加密工作模式的复杂应用场景中具有重要的意义。
