一种基于AI的全媒体灾情受理系统设计方案
2020-10-20于春强

摘要:灾情受理是消防救援队伍灭火救援行动的首要步环节,关系着救援行动的成败和群众生命的安危。然而,在实际接警中,由于单纯语音沟通的局限性和表达描述的口头性,灾情定位和事故类型等关键要素需要反复确认任然极易出现偏差,导致调派效率低下,装备力量不准,甚至贻误战机,严重威胁到国家与人民群众的生命财产安全。本文基于AI语音语义识别、AI文本转换优化的关键信息智能提取等多种技术,提出一种新型智能化灾情受理系统的设计方案。
关键词:AI;全媒体;灾情受理系统
中图分类号:X915文献标识码:A文章编号:1672-9129(2020)07-0064-03
Abstract:The acceptance of the disaster is the first step of the fire rescue team fire rescue operation, related to the success of the rescue operation and the safety of people's lives. In actual receiving alarm, however, due to the limitation of the simple voice communication and expression to describe oral sex, disaster and accident types such as key element requires repeated confirmation still deviation, appear easily lead to inefficient transfer, power equipment, and even delay, serious threat to the country and the people's life and property safety. Based on AI speech semantic recognition, AI text conversion optimization of key information intelligent extraction and other technologies, this paper proposes a new intelligent disaster acceptance system design scheme.
Key words:AI;All the media;Disaster acceptance system
1前言
目前各级消防救援队伍的灾情受理方式还主要是程控电话传统方式。“电话报警”“短信报警”“网上报警”3种方式进行报警。而提取灾情的关键信息则依靠人工,从其效率和准备性上有待提高。市场上的报警方法或产品主要问题:报警方式不够自动化。报警人在事发过程中往往不及反映,或没有精力来完成报警动作;报警后处置系统需要完全由人工甄别灾情,在处置资源不足时往往造成灾情处置延误,谎报、误报的灾情往往也造成无效接警。
现如今,人工智能技术的飞速发展,在各种行业都有应用,基于AI语音语义识别,文本转换等技术有效的提取信息,能减少或避免传统的灾情受理靠成延误或无效接警。
2总体目标
研究基于语音语义识别、文本转换优化的关键信息智能提取技术,提供灾情定位等有效信息,通过移动应用(android/ios)、微信小程序等多种互联网报警方式的融合接入技术,基于实时全媒体灾情信息和历史接处警信息智能化动态生成人、车、装备辅助调派方案。
3研究内容
3.1 AI语音语义识别:包括以语言学、计算机语言等学科为背景的,对自然语言进行词语解析、信息抽取、时间因果、情绪判断等等技术处理,最终达到让计算机“懂”人类的语言的自然语言认知,以及把计算机数据转化为自然语言的自然语言生成。
词语解析与信息抽取:包括分词、词性标注、命名实体识别和词义消歧,从给定文本中抽取重要的信息。
句法解析与语篇理解:对篇章结构的一系列连续的子句、句子和语段间一定层次结构和语义关系的分析,包括时间、事件、因果关系等,甚至于文本所携带的情绪识别。
自然语言生成:从结构化数据中以可读地方式自动生成文本的过程。包括三个阶段:文本规划(完成结构化数据中基础内容的规划)、语句规划(从结构化数据中组合语句,来表达信息流)、实现(产生语法通顺的语句来表达文)。
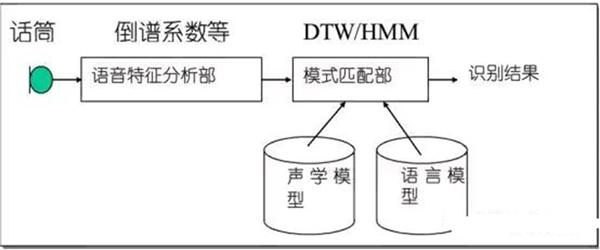
词典、数据集、语料库、知识图谱,以及外部世界常识性知识等都是语义识别算法模型的基础。模式匹配部是语音识别系统的关键组成部分,它一般采用“基于模式匹配方式的语音识别技术”或者采用“基于统计模型方式的语音识别技术”。前者主要是指“动态时间规整(DTW法”,后者主要是指“隐马尔可夫(HMM)法”。
隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov鏈演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。
动态时间归整算法:在孤立词语音识别中,最为简单有效的方法是采用DTW(Dynamic Time Warping,动态时间归整)算法,该算法基于动态规划(DP)的思想,解决了发音长短不一的模板匹配问题,是语音识别中出现较早、较为经典的一种算法,用于孤立词识别。HMM算法在训练阶段需要提供大量的语音数据,通过反复计算才能得到模型参数,而DTW算法的训练中几乎不需要额外的计算。所以在孤立词语音识别中,DTW算法仍然得到广泛的应用。
3.2 AI文字文本转换:
Ocr:光学字符识别(英语:Optical Character Recognition)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
将彩色图像中的三分量的亮度作为三个灰度图像的灰度值,可根据应用需要选取一种灰度图像。
根据重要性及其它指标,将三个分量以不同的权值进行加权平均。由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。F(i,j) = 0.30R(i,j) + 0.59G(i,j) + 0.11B(i,j))
(1)对图像进行二值化处理。图像的二值化处理就是将图像上的点的灰度置为0或255,也就是将整个图像呈现出明显的黑白效果。即将256个亮度等级的灰度图像通过适当的阈值选取而获得仍然可以反映图像整体和局部特征的二值化图像。在数字图像处理中,二值图像占有非常重要的地位,特别是在实用的图像处理中,以二值图像处理实现而构成的系统是很多的,要进行二值图像的处理与分析,首先要把灰度图像二值化,得到二值化圖像,这样子有利于在对图像做进一步处理时,图像的集合性质只与像素值为0或255的点的位置有关,不再涉及像素的多级值,使处理变得简单,而且数据的处理和压缩量小。为了得到理想的二值图像,一般采用封闭、连通的边界定义不交叠的区域。所有灰度大于或等于阈值的像素被判定为属于特定物体,其灰度值为255表示,否则这些像素点被排除在物体区域以外,灰度值为0,表示背景或者例外的物体区域。如果某特定物体在内部有均匀一致的灰度值,并且其处在一个具有其他等级灰度值的均匀背景下,使用阈值法就可以得到比较的分割效果。如果物体同背景的差别表现不在灰度值上(比如纹理不同),可以将这个差别特征转换为灰度的差别,然后利用阈值选取技术来分割该图像。
(2)对图像进行腐蚀处理原理。特征提取和降维:特征是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。对于数字和英文字母来说,这个特征提取是比较容易的,因为数字只有10个,英文字母只有52个,都是小字符集。对于汉字来说,特征提取比较困难,因为首先汉字是大字符集,国标中光是最常用的第一级汉字就有3755个;第二个汉字结构复杂,形近字多。在确定了使用何种特征后,视情况而定,还有可能要进行特征降维,这种情况就是如果特征的维数太高(特征一般用一个向量表示,维数即该向量的分量数),分类器的效率会受到很大的影响,为了提高识别速率,往往就要进行降维,这个过程也很重要,既要降低维数吧,又得使得减少维数后的特征向量还保留了足够的信息量(以区分不同的文字)。
分类器设计、训练和实际识别:分类器是用来进行识别的,就是对于第二步,对一个文字图像,提取出特征给,丢给分类器,分类器就对其进行分类,告诉你这个特征该识别成哪个文字。
3.3智能灾情分析和出警信息调度。终端 设备采集数据信息,对历史 出警数据快速分析,以找到最有效的出警调度信息。
3.4精确定位。GPS+北斗+基站定位+WiFi的混合定位模式进行定位,以达到更准确的定位。
4技术路线
4.1 MFCC提取一般流程。
预滤波:CODEC前端带宽为300-3400Hz的抗混叠滤波器。
A/D变换:8kHz的采样频率,12bit的线性量化精度。
预加重:通过一个一阶有限激励响应高通滤波器,使信号的频谱变得平坦,不易受到有限字长效应的影响。
分帧:根据语音的短时平稳特性,语音可以以帧为单位进行处理,实验中选取的语音帧长为32ms,帧叠为16ms。
加窗:采用哈明窗对一帧语音加窗,以减小吉布斯效应的影响。
快速傅立叶变换(Fast Fourier Transformation, FFT):将时域信号变换成为信号的功率谱。
三角窗滤波:用一组Mel频标上线性分布的三角窗滤波器(共24个三角窗滤波器),对信号的功率谱滤波,每一个三角窗滤波器覆盖的范围都近似于人耳的一个临界带宽,以此来模拟人耳的掩蔽效应。
求对数:三角窗滤波器组的输出求取对数,可以得到近似于同态变换的结果。
离散余弦变换(Discrete Cosine Transformation, DCT):去除各维信号之间的相关性,将信号映射到低维空间。
谱加权:由于倒谱的低阶参数易受说话人特性、信道特性等的影响,而高阶参数的分辨能力比较低,所以需要进行谱加权,抑制其低阶和高阶参数。
倒谱均值减(Cepstrum Mean Subtraction, CMS):CMS可以有效地减小语音输入信道对特征参数的影响。
差分参数:大量实验表明,在语音特征中加入表征语音动态特性的差分参数,能够提高系统的识别性能。在本系统中,我们也用到了MFCC参数的一阶差分参数和二阶差分参数。
短时能量:语音的短时能量也是重要的特征参数,本系统中我们采用了语音的短时归一化对数能量及其一阶差分、二阶差分参数。
4.2模式匹配和语言处理。
通过语音特征分析以后接下来就是模式匹配和语言处理。
声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型的目的是提供一种有效的方法计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大的影响。必须根据不同语言的特点、识别系统词汇量的大小决定识别单元的大小。
语言模型对中、大词汇量的语音识别系统特别重要。当分类发生错误时可以根据语言学模型、语法结构、语义学进行判断纠正,特别是一些同音字则必须通过上下文结构才能确定词义。语言学理论包括语义结构、语法规则、语言的数学描述模型等有关方面。目前比较成功的语言模型通常是采用统计语法的语言模型与基于规则语法结构命令语言模型。语法结构可以限定不同词之间的相互连接关系,减少了识别系统的搜索空间,这有利于提高系统的识别。语音识别过程实际上是一种认识过程。就像人们听语音时,并不把语音和语言的语法结构、语义结构分开来,因为当语音发音模糊时人们可以用这些知识来指导对语言的理解过程,但是对机器来说,识别系统也要利用这些方面的知识,只是如何有效地描述这些语法和语义还有困难:
小词汇量语音识别系统。通常包括几十个词的语音识别系统。
中等词汇量的语音识别系统。通常包括几百个词至上千个词的识别系统。
大词汇量语音识别系统。通常包括几千至几万个词的语音识别系统。这些不同的限制也确定了语音识别系统的困难度。
模式匹配部是语音识别系统的关键组成部分,它一般采用“基于模式匹配方式的语音识别技术”或者采用“基于统计模型方式的语音识别技术”。
5实施方案
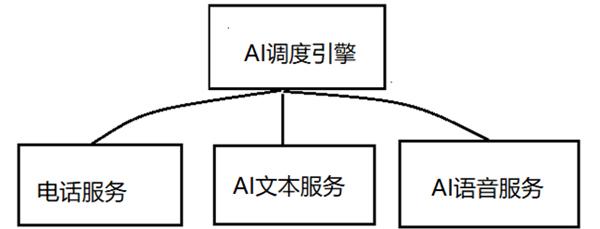
以下所述包括前端AI云端引擎服务、地图定位服务、AI前端信息采集系统,三个主要部分组成;所述前端AI信息采集系统通过restful 接口与AI研判引擎系统相连接,将自动化采集到的信息发送引擎进行处理;所述AI研判引擎系统通过restful 接口与后台AI云端引擎服务相连接,将灾情处理的研判结果发送调度系统,辅助调度人员的灾情研判。本发明结合AI技术,利用计算机视觉处理、声音识别对报警信息自动化采集、处理,实现信关键信息,报警信息传送后计算机系统自动化辅助分析判断,极大地提高灾情受理的及时性、便捷性与处置效率。
5.1 AI云端引擎服务开发
开发Ai调试引擎服务,监控文本和语音服务,将音频或文字交附给对对应的AI语音服务和AI文本服务。对应的服务快速提取关键信息并迅速反馈。
目前市场语音语义解析产品解决方案AIUI,AIUI是科大讯飞推出的一套以语音为核心的人机交互解决方案,意在使应用和设备能够快速具备能听会说,能理解会思考的能力。
支持语音唤醒,高唤醒率,低配置需求,低功耗。支持语音识别:识别结果响应时间低于200ms,支持中文、英文、粤语、四川话等,依托机器学习和积累的海量数据,识别复杂主义,作出精准响应。
构建文字检测和识别服务
可以考虑OpenCV。OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列C函数和少量C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
文字检测:OpenCV的文字检测模块textDetectorCNN中使用了TextBoxes:具有单个深度神经网络的快速文本检测器 链接地址为:
文字识别:OCRHolisticWordRecognizer类提供了分段词语的功能。给定预定义的词汇表,使用DictNet来选择给定输入图像的最可能的词。
5.2 地图定位服务。
定位SDK通过GPS+基站定位+WiFi的混合定位模式进行定位,不论在室外、室内还是在高楼林立的城市峽谷,都可以实现精准的定位。
地图开放平台应提供2D、3D、卫星多种地图形式供开发者选择,无论基于哪种平台,都可以提供API和SDK
5.3 AI前端信息采集系统。
开发android/ios app 开发,用于收集报警信息,语音信息,文字信息,当前海量信息加入深度学习计划,为后续的ai服务提供支撑,为数据服务提供数据支撑。
同时要开发web管理后端,对于一些用户权限,信息汇总统计,基本设置,服务治理等公共服务进行管理操作。完成人、车、装备等信息的管理功能 ,可以有效的汇总此类信息。
参考文献:
[1]安全,城市面对的严峻课题[J]. 王利公. 中国城市经济. 2004(08)
[2]重大突发事件及其应急决策研究[J]. 袁辉. 安全. 1996(02)
作者简介:于春强(1970、8一),男,汉族,黑龙江密山市人,大学本科,工科学士,工程师,黑龙江省消防救援总队,研究方向:信息通信、消防安全。
