基于梯度提升决策树的气体传感器阵列识别模型研究
2020-10-14董晓睿
董晓睿
(中国石油大学胜利学院 基础科学学院,山东 东营 257000)
电子鼻系统是近年来工程领域的研究热点之一,涉及化学、材料、传感器、模式识别、电子技术、计算机和应用数学等多个学科,它包括一组化学传感器、一个信号处理系统和一个模式识别系统,可以对混合气体中的各种气体成分进行定性或定量分析。电子鼻系统克服传统单气体传感器在检测交叉灵敏度等方面的缺点,被广泛应用于化工、环保、能源、食品、医疗、交通运输等诸多应用工程领域[1]。传感器阵列是电子鼻系统的关键,它用于采集气体类型和浓度的信息,其参数选择主要选择有:传感器类型、阵列大小和选择性、稳定性、噪声水平等。传感器阵列通常由若干离散元件组成,能够对至少一种待测气体的作出反应,响应范围广,但对不同种类气体的响应程度有所不同。传感器阵列对气体的检测过程是可逆的,响应时间和恢复时间要保证尽可能的短,性能要保持稳定可靠。如何提高气体传感器阵列的稳定性、灵敏度和选择性是重要的研究方向之一。
1 相关理论技术
气体传感器阵列的性能直接决定电子鼻系统的识别能力、识别距离和使用寿命。Prajapati[2]提出了用于监测空气污染物CO、CO2、NO2和SO2的四元气体传感器阵列的设计方法。Akamatsu[3]提出了一种利用主成分分析(Principal Component Analysis,PCA)对传感器信号进行分析,增加两个批量响应传感器来提高识别能力的方法。Ziyatdinov[4]提出了一种新的基于公共主成分分析的漂移补偿方法,该方法在最佳拟合参考气体的情况下与传统方法具有相同的性能。Padilla[5]提出了一种正交信号校正(Orthogonal Signal Correction,OSC)算法用于漂移补偿,以对抗传感器老化、记忆效应和环境干扰。Zhen[6]尝试使用带有两层隐层和决策树学习的反向传播神经网络(Back-Propagation Neural Network,BPNN)来估计挥发性有机物(VOCs)的浓度。可见,传感器阵列性能的提升主要从两个方面进行:一是提高传感器本身的性能;二是优化模式识别算法。然而这两种方法都以强规则的形式对传感器数据进行补偿或分析,过分依赖于历史数据和经验,存在较大程度的主观性。针对这一问题,本次研究提出了一种基于梯度提升树和信息熵权特征法的气体传感器阵列识别模型,决策旨在自适应补偿时间漂移和剔除识别异常信息,同时采用集成学习方法整合多个基分类器以提高气体传感器识别精度,该模型在UCI气体传感器阵列漂移数据集(Gas Sensor Array Drift Dataset,GSAD)上进行了试验,取得了良好的试验结果。
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[7]是一种迭代的决策树算法,可被用来处理分类或回归任务。GBDT由若干决策树组成,运用加法模型和前向分布算法,对模型拟合残差进行修复而逐步趋近最优模型。GBDT方法可以减少多种因素之间的冗余程度,对异常值拥有较强的鲁棒性。本研究充分利用GBDT鲁棒性强、去除异常值和精度高等优势,弥补传感器的脆弱性引发的异常信号和时间漂移问题,以提高最终的气体识别准确度。
熵权特征法[8]是一种基于信息熵理论的可用于多对象、多指标的综合评价方法。熵作为度量不确定性信息的一个准则,采用离散的概率分布进行表示,分布越广表示系统越不稳定,越集中表示系统越稳定。采用熵权特征法动态调整各传感器权值,克服在常规均权评价过程中不稳定传感器和异常信号对最终评估结果的影响。
集成学习[9]是通过构建并结合多个学习器来完成学习任务,可获得比单一学习器更加显著的泛化性能,对弱学习器尤为明显。结合策略主要有平均法、投票法和学习法等。本研究对不同批次的数据训练得到若干基分类器,在预测环节对不同基分类器采用Bagging法[10]进行集成,以增强整体分类器的泛化能力。
2 算法设计
假设传感器阵列S有I个传感器,每个传感器有J个检测项(即特征属性),si,{j=1,2,…,J}为第i个传感器检测项,X为随机森林模型的输入向量,Y为模型的理想输出向量,则
X={x1,x2,…,xj,…,xJ},
(1)
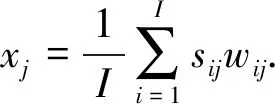
(2)
式中,wij为第i个传感器第j个检测项的权重,其计算公式为:
(3)
式中,ej为第j个检测项根据信息论的输出熵,其计算公式为:
(4)
传感器数据采用Z-score规范化,如下式所示:
(5)
式中,μ是区间数据均值,σ是区间数据标准差。
采用梯度提升决策树方法,融合多个CART决策树模型,通过比较每次迭代的损失函数梯度,逐步建立高精度模型。选择交叉熵作为损失函数,可表示为:
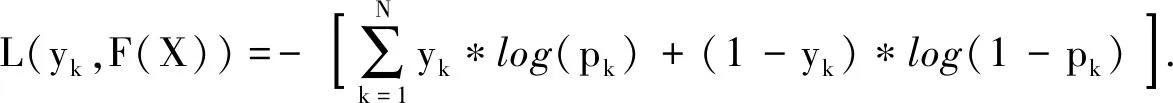
(6)
式中,pk是第k类的预测概率。将损失函数转换到odds,可表示为:
L(yk,F(X))=-yk*log(odds)+log(1+elog(odds)).
(7)
第t轮的第i个样本对应类别l的负梯度误差可由下式计算得出:
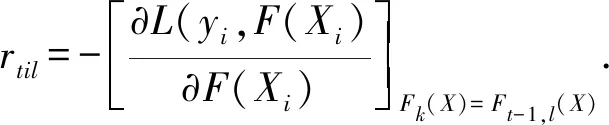
(8)
进而对树进行累加,随着对模型拟合残差进行修复而逐步趋近最优。
最后通过准确率Accuracy、精确度Precision、召回率Recall和F1得分来评价模型的性能,定义为:
Accuracy=(TP+TN)/(TP+FP+FN+TN),
(9)
Precision=TP/(TP+FP),
(10)
Recall=TP/(TP+FN),
(11)
(12)
式中,TP为被判定为正样本的正样本数,TN为被判定为负样本的负样本数,FP为被判定为正样本的负样本数,FN为被判定为负样本的正样本数。
3 试验与分析
使用UCI气体传感器阵列漂移(GSAD)数据集[11]作为试验研究对象。GSAD数据集由亚历山大·维加拉(Alexander Vergara)在2012年创建并捐赠,共包含10批次13910条传感器化学气体数据,数据来自于16个化学气体传感器,用于识别6种不同浓度的气体。GSAD数据集无缺失值,除batch10数据外,batch1到batch9均存在一定程度的数据集偏斜,其中batch3、batch4、batch5甚至不包括甲苯数据。GSAD数据集各批次数据的数据分布如图1所示。
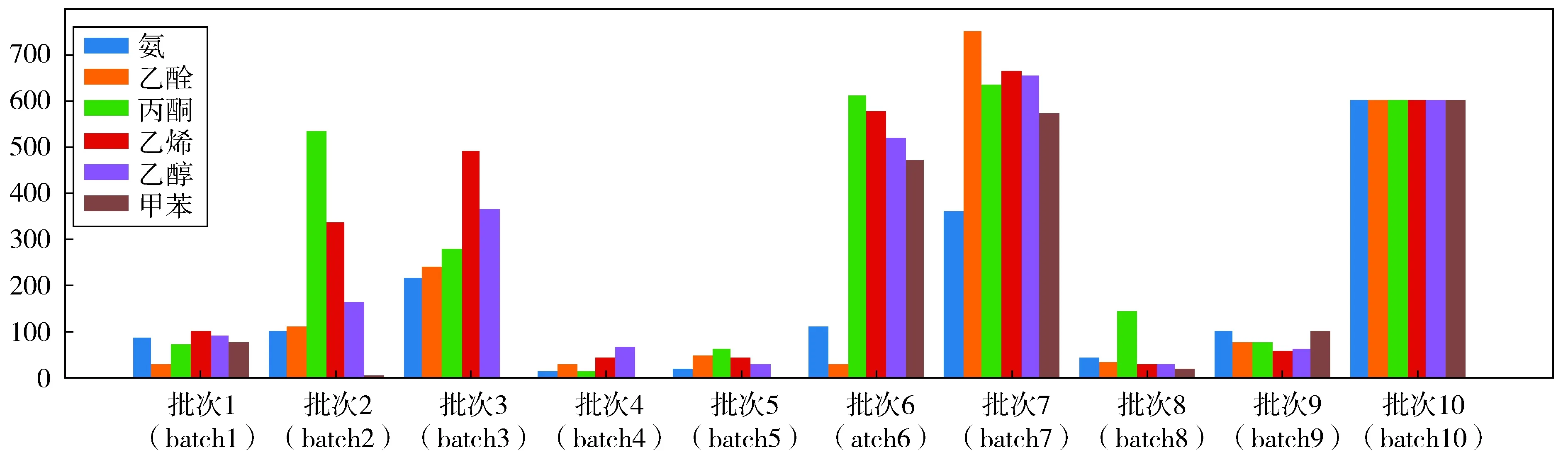
图1 GSAD数据集数据分布
采用Anaconda(Python 3.7)为开发环境,试验环境CPU为Intel Xeon W-2145 3.70GHz、内存为32GB RAM。试验首先根据公式(1)~(4)完成数据集的预处理,适当缩减数据集的规模;其次,采用公式(5)完成数据标准化,使得处理后数据符合均值为0和标准差为1的标准正态分布;然后,如公式(6)~(8)所示,建立基于梯度提升树的识别模型,学习率设为0.01,梯度提升迭代次数为100,个体回归估计器最大深度为3;最后,根据公式(9)~(12)完成模型评价与结果分析。该模型对GSAD数据集的10批次数据进行识别分类,试验结果如图2所示。
由图2可见,该模型对10批数据的识别分类任务取得了良好的效果。在处理batch4时,模型的准确率和召回率达到1.0,在处理batch2、batch3、batch6和batch9时,准确率和召回率接近1.0。由图1可知,batch7和batch10是10个批次数据中最具代表性和最大的两个数据集,区别在于batch10数据分布均匀,而batch7数据分布不均匀。模型在处理这两个数据集时性能表现也较为稳定,几乎所有指标都在0.9以上。同时,发现存在某些批次试验效果不佳,例如在对batch2的识别中,由于数据集存在严重的偏斜情形,导致模型未能成功识别出甲苯类型的数据;由于batch1和batch8的数据集规模较小,同时存在一定程度的数据集偏斜,导致batch1中的氨和甲苯的识别准确度较低,而对乙烯的识别召回率较低,batch8中的丙酮的识别准确度较低,而对甲苯的识别召回率较低。整体上看本次研究提出的气体传感器阵列模型对复杂气体的识别精度取得较好效果,尤其是在提高气体数据充足的情况下,模型的各指标均较为优秀。
4 结束语
气体传感器的使用易受到设备老化、记忆效应和环境干扰等因素影响。传统的传感器阵列优化方法,通常是以强规则的形式对传感器数据进行补偿或分析,过分依赖于历史数据和经验,存在较大程度的主观性。针对这一问题,本次研究提出一种基于梯度提升树分类器和信息熵权的气体传感器阵列识别模型,采用熵权来降低异常信号对最终结果的影响,以梯度提升决策树作为主体算法,挖掘数据间的潜在规则,同时辅以集成学习思想来整合多批次传感器数据,旨在自适应补偿时间漂移和剔除识别异常信息,提高气体传感器识别精度,该模型在UCI气体传感器阵列漂移数据集(Gas Sensor Array Drift Dataset,GSAD)上进行了试验,取得良好试验结果。本次研究所提出的识别模型的设计与实现方法对相关领域的研究具有一定的参考价值。
