融合多特征的老挝机构名实体识别方法
2020-10-13晏雷周兰江张建安周枫
晏雷 周兰江 张建安 周枫

摘 要: 为了解决老挝机构名实体构词方法和语法规则复杂的问题,提出融合多特征的CRF与SVM的实体识别框架。面向老挝语机构名构词特点,将老挝机构名称分为前缀词和后缀词,将前缀词提取构造成一个机构名称特征词典,基于词典与SVM模型确定老挝机构名称前界,再使用融合多特征的CRF模型识别机构名称;最后使用SVM确定的前缀词修正CRF的识别结果。实验结果表明,精确率达到83.49%,召回率达到81.99%,证明了该方法的有效性。文中方法结合了SVM模型与CRF模型的优点,并融合了老挝机构名称的相关语言学特征,取得了较好的识别效果。
关键词: 老挝语; 机构名称识别; 多特征融合; 前缀词提取; 识别结果修正; 实验结果分析
中图分类号: TN911.1?34; TP391 文献标识码: A 文章编号: 1004?373X(2020)19?0122?04
Abstract: In order to solve the problem that the word?formation method and grammatical rules of Lao organization name entities are complex, an entity identification framework of CRF (conditional random field) and SVM (support vector machine) fusing multiple features is proposed. According to the word?formation characteristics of institution names in Lao language, the Lao institution names are divided into prefix words and suffix words. The prefix words are extracted to build a dictionary about institutional name features. The prezones of the Lao institution names are determined on the basis of the dictionary and SVM model. The CRF model fusing multiple features is used to identify the institution names. Finally, the prefix words determined by SVM are used to correct the recognition results of CRF. The experimental results show that the accuracy rate of the method reaches 83.49% and its recall rate reaches 81.99%, which prove the effectiveness of the method. In the proposed method, the advantages of the SVM model and CRF model are combined, and the relevant linguistic features of Lao institution names are integrated, which achieve good recognition results.
Keywords: Lao; organization name recognition; multi?feature fusion; prefix word extraction; recognized result correction; experiment result analysis
0 引 言
命名实体识别一直是自然语言处理领域的基础任务,如信息抽取、文本摘要、机器翻译等[1]。命名实体一般分为七大类,分别为人名、地名、机构名、时间、日期、货币和百分比[2]。时间、日期、货币和百分比由于形式比较固定,识别比较简单;相较于人名、地名而言,机构名结构复杂、长短不一、组成多样,不同机构名差异较大,这些都加大了机构名识别的难度。本文的研究内容主要是面向老挝语中机构名称的识别。
近年来,在命名实体识别领域主要使用的是基于统计的方法与基于神经网络的方法。文献[3]采用SVM与HMM叠加的方法对实体词进行识别,但是由于HMM模型需要严格的独立性假设,使其不能学习长远的上下文特征。文献[4]提出一种基于角色集的方法识别实体名并取得了较好结果,但该方法对于不同语种移植性较差,同时角色集的设计对实验结果影响较大,需要多次实验才能确定最优角色集。文献[5]中使用的基于神经网络的深度学习方法具有泛化性强、更少依赖人工特征的优点,但是目前老挝语命名实体识别语料稀少,并不能为神经网络提供大量的标注数据,所以该方法移植到老挝语上效果一般。
针对老挝机构名实体构词方法和语法规则复杂的问题,本文提出融合多特征的CRF模型与SVM相结合的方法。首先,利用SVM模型结合特征词典对老挝机构名前缀词进行识别;再利用融合词的上下文信息、词性、特征词典、左右指界词特征的CRF模型对机构名实体进行识别;最后,使用SVM的前缀词的识别结果对CRF的识别结果进行修正。实验表明,本文方法能够明显提高识别结果的准确率。
1 系统框架
本文进行的老挝语机构名实体识别的研究以词汇为最小判别单元,使用的标注集合为[{B,I,O}],其中,命名实体首字符标为[B]、命名实体其他字符标为[I]、非实体字符标为[O]。系统的框架结构如图1所示,共分为三层。第一层为输入层,首先将句子做分词处理,再将句子处理为模型所需的格式输入到模型中进行训练。第二层为模型层,将句子输入到训练好的两个模型中,得到标记结果,当SVM模型标记该词为老挝机构名称前缀词[B]并且CRF模型也标记该词为[B]时,方可确定该词为老挝机构名前缀词,并取CRF中[I]的标记结果确定一个完整的实体名;当只有一个模型认为该词为前缀词,另一个模型没有进行该标记则跳过该词。第三层为输出层,综合两个模型的输出得到最终的标注结果。
2 SVM模型
2.1 SVM原理
根据老挝语机构名称的特点构建特征向量,使用SVM模型对特征向量进行分类,可以抽象成一个非线性分类问题。解决非线性分类问题的办法是将原来低维空间的训练数据映射到一个使训练数据线性可分的更高维的空间中,通过SVM模型找到最优分类超平面[6],对数据进行分类,训练模型。
定义训练集如下:
SVM模型通过找到最优分类超平面对数据进行划分[7],该超平面可通过凸二次规划方程求解得到:
对句子中存在于特征词典中的词,使用SVM模型进行判断,若得到标签为+1,则确定其为老挝机构名称的前界;若得到标签为-1,则确定其不是老挝机构名称中的词。
2.2 特征词典的构造
老挝机构名称形式相对固定。在老挝语中一般实体都会以特征词作为一个机构实体词的开头,形式为前缀词+后缀词,如老挝国立大学(???????????????????)分为前缀词(????????????)与后缀词(???????)。将形如大学(????????????)这种机构名称前缀词加入特征词词典。为了更加符合实际应用情况,只将训练集中的机构名称特征词提出来并去重后加入特征词词典,测试集中的词不加入特征词词典。表1中是部分特征词。
2.3 SVM识别老挝机构名称前缀词
前缀词的识别可以看作是一个二分类问题。SVM模型是一个使用监督学习的方式对数据进行二值分类的分类器。使用SVM对老挝语机构名称前缀词进行识别,当句子中存在特征词典的词出现时,将其加入前缀词候选词,使用SVM模型进行识别,确认其是否为老挝语机构名称前缀词。根据语料特性,结合识别效果和效率,定义11维向量,格式如下:
其中:[L]表示标签类型,[L∈-1, 1],[L= 1]表示该特征向量为正类,该词是机构名称前缀词,[L=-1]表示该特征向量为负类,该词不是机构名称前缀词;[W]表示老挝语单词的词形;[P]表示其词性;-2,-1,0,1,2表示单词的位置信息,0代表当前词,1代表当前词后面的第一个词,-1代表当前词前面的第一个词,以此类推。根据定义的向量格式构建相应向量如下所示:
1???ADJ?????????? N????? N??????? N?????N
将标注语料输入SVM模型进行训练与测试,得到老挝机构名称前缀词识别结果。
3 条件随机场模型
3.1 条件随机场原理
自Laggerty等在2001年提出条件随机场以来,在自然语言处理领域得到了广泛的应用[8]。对比HMM与MEMM模型,其打破了条件独立性假设,在给定观察序列[X]和输出的标注序列[Y]时,使用条件概率[PYX]描述概率模型,并以序列化进行全局参数优化,解决了labelbias问题,使其在序列标注问题上获得了更好的表现。
条件随机场是一种无向图模型[9],其中最简单的链式结构图如图2所示,此处只将观察序列[Y]作为条件,不对其做任何独立性假设。
在给定观察序列[X={x1,x2,…,xn}]的情况下,计算并输出对应的状态序列[Y={y1,y2,…,yn}],其条件概率为:
式中:[ZX]为归一化因子,使得所有状态序列的概率和为1;[tjyi-1,yi,xi]是关于观测序列和位置[i]及[i-1]标记的转移概率的函数,称为转移函数;[t′jyi,xi]是关于观测序列和位置[i]标记的状态特征的函数,称为状态函数;[λj]和[λ′j]分别为[tj]和[t′j]的权重,需要通过训练得到。
最大可能的标注序列可通过维特比算法解码得出:
3.2 特征选择
在使用CRF进行机构名称识别时,除了语料大小会对结果产生重要的影响,特征模版也会对结果产生直接影响。本文针对老挝组织机构名实体识别的任务结合老挝语句子的词汇特征、句法特征提取如下特征模板。
1) 词汇上下文特征
根据老挝机构名的语言特性,本文将词汇上下文特征的窗口设置为5。此时输入句子序列的具体形式为[i=2NWi],其中,[N]为句子长度,[Wi]为一个大小为5的窗口,具体如下所示:
式中:[wi]为当前观察的词汇;[ti]为当前词汇的标签。具体的特征模板如表2所示。
2) 词性特征
当前的观察词与该词所对应的词性[pi]。此时输入的句子序列如下所示:
对应的词性特征[wipi]也加入特征模板中。
3) 特征词表
特征词是表示该组织机构名实体类别属性的构件[10],如“?????????????????(坦克?装甲局)”中的“???(局)”即为一个特征词。此处特征词表与上一节中特征词典内容一致。在输入的句子序列中,加上一列特征词标记[ci],如果当前观察词汇出现在特征词表中,令[ci=Y],否则,令[ci=N]。
4) 左右指界词表
指界词即出现在机构名前或后的第一个词,例如左指界词????(通过)后面会伴随出现机构名;右指界词?????(主席)一般出现在机构名后。出现次数不同的指界词对机构名边界的指示作用不同,受语料大小所限,本文实验中只取出现频率最高的20个指界词。同样,在句子输入序列中,加上一列左右指界词标记[mi],如果当前观察词汇出现在特征词表中,令[mi=Y],否则,令[mi=N]。
根据以上4个特征,构造4组不同的训练语料:第一组为词+[BIO]标签;第二组为词+词性+[BIO]标签;第三组为词+词性+特征词表+[BIO]标签;第四组为词+词性+特征词表+左右指界词表+[BIO]标签。第四组语料标注示例如表3所示。
4 实 验
4.1 数据集
本文的实验语料主要通过对老挝新闻网站的爬取,然后再通过老挝语专家和老挝留学生进行标注,并对语料进行分词、词性标注等预处理,并设计程序对左右指界詞进行统计。语料库约18.9 MB,其中,70%的语料用来训练,30%的语料用来测试。
4.2 结果分析
本文使用3个指标对实验结果进行评价,分别是准确率[P]、召回率[R]和[F]值。准确率指的是一个算法的查准率,召回率指的是一个算法的查全率,[F]值是综合考虑准确率和召回率的指标[11]。计算公式如下:
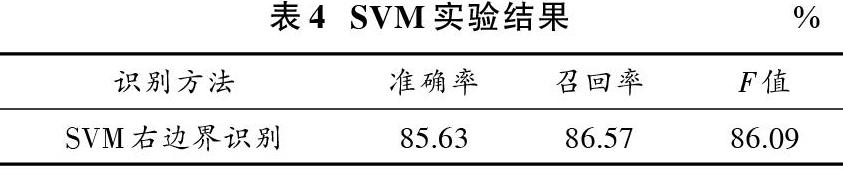
使用SVM模型对上述老挝机构名称前缀词的识别实验结果如表4所示。
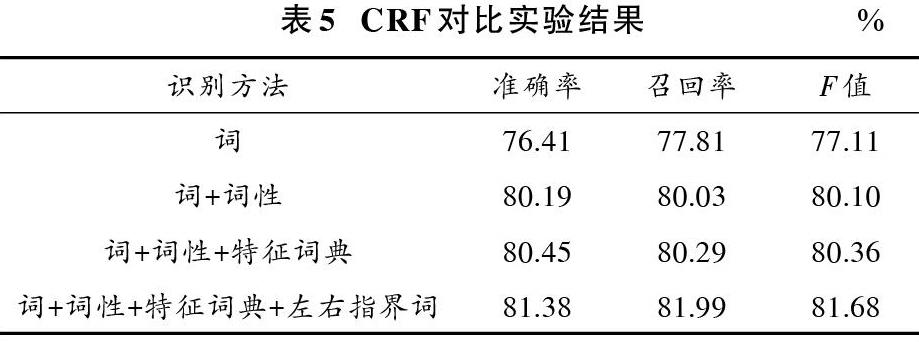
使用4组不同的模板训练CRF模型,得到的对比实验结果如表5所示。
使用SVM与融合多特征的CRF方法进行实验,对比CRF模型中取得的最好实验结果,对比结果如表6所示。
从实验结果可以看出:由于标注语料有限,可以看出在词与词性的基础上融合特征词典的特征对识别准确率提升不大;CRF模型中融合了词、词性、特征词典、左右指界词的模型效果,在CRF的4组实验中效果最好,说明融合的特征都是有效的。单纯使用特征词典+SVM模型,对老挝机构名左边界的识别效果较好。基于SVM与融合多特征的CRF的模型在CRF的基础上有效地提高了准确率,召回率没有改变,说明SVM对左边界的识别结果能够有效剔除CRF中的错误实体结果,减小FP的数量,从而提高识别机构名实体的准确率。但是由于本文的实验结果是基于正确分词和词性标注的基础上,实际上分词与词性标注上的错误都会降低识别的精确度。
5 结 语
本文针对老挝语机构名称构词的语法特点,建立一种基于SVM和CRF的双层模型,对老挝机构名称进行识别。在特征词词典的基础上,使用SVM模型对老挝语机构名称特征词进行识别,并通过CRF模型融合老挝机构名称特征对机构名称进行标注,结合SVM的前缀词识别结果,有效降低了CRF模型预测错误实体的个数,从而达到了提高准确率的目的。
实验表明,本文方法能够获得较好的老挝机构实体的识别准确率,但是不足之处也较为明显,特征词典为人工收集,对于未录入特征词词典的机构名称则无法进行识别,这还有待于后续进一步深入的研究;语料的不足也对实验结果有一定的影响,后续工作还要继续扩充标注好的语料库。
参考文献
[1] 武惠,吕立,于碧辉.基于迁移学习和BiLSTM?CRF的中文命名实体识别[J].小型微型计算机系统,2019,40(6):1142?1147.
[2] 段韶鹏.老挝语命名实体识别研究[D].昆明:昆明理工大学,2017.
[3] 祝继锋.基于SVM和HMM算法的中文机构名称识别[D].吉林:吉林大学,2017.
[4] 李丽双,郭元凯.基于CNN?BLSTM?CRF模型的生物医学命名实体识别[J].中文信息学报,2018,32(1):116?122.
[5] 潘璀然,王青华,汤步洲,等.基于句子级Lattice?长短记忆神经网络的中文电子病历命名实体识别[J].第二军医大学学报,2019,40(5):497?506.
[6] 许华.基于有监督学习的医疗实体抽取方法研究[D].武汉:武汉科技大学,2016.
[7] 周晓磊,赵薛蛟,刘堂亮,等.基于SVM?BiLSTM?CRF模型的财产纠纷命名实体识别方法[J].计算机系统应用,2019,28(1):245?250.
[8] LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings the Eighteenth International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 2001: 282?289.
[9] SARAWAGI S. Sequence segmentation using semi?Markov conditional random fields [J]. Journal of the Indian Institute of Science, 2019, 99(2): 215?224.
[10] 李明鑫.基于信息抽取的实体知识库系统研究[D].北京:北京交通大学,2017.
[11] 罗钰敏,刘丹,尹凯,等.加权平均Word2Vec实体对齐方法[J].计算机工程与设计,2019,40(7):1927?1933.
[12] 杨梦杰.老挝语命名实体识别方法的研究[D].昆明:昆明理工大学,2016.
