改进的多目标回归学生课堂行为检测方法
2020-09-29刘新运叶时平张登辉
刘新运,叶时平,张登辉
(1.常州大学 信息科学与工程学院,江苏 常州 213164;2.浙江树人大学 信息科技学院,浙江 杭州310015)
0 引 言
行为识别应用于课堂场景,能够帮助教师掌握学生上课状态、调整教学方式,并可作为教学评价的重要依据。目前主流的视频行为识别方法多基于深度学习技术。其中Karpathy等基于CNN设计了4种不同的神经网络模型用于行为识别[1]。Simmoyan等使用图像空间特征和时序特征的双流网络方法,改善了运动特征提取不足问题[2]。Limin Wang等提出TSN方法将视频分为K个部分,稀疏采样后使用双流网络提取特征,再融合各部分特征进行行为识别,提高了长时间视频的行为识别能力[3]。Tran等提出的C3D方法使用三维卷积核提取视频特征,简化了网络结构、提高了检测速度[4]。Wenbin Du等提出的RPAN方法[5]和Donahue等提出的LRCN方法[6],采用RNN和LSTM网络,提升了时间维度的理解能力。
应用中,沈铮等使用改进的CNN模型对经预处理后的连续帧图像进行识别,实现了公交车中异常行为的检测[7]。孔言等将注意力机制融入双流网络中,实现了油田现场人员的行为识别[8]。李辰政等使用迁移学习训练的C3D网络实现了公共场合下危险行为识别[9]。
上述方法计算成本较高、模型训练时间较长、实时性不足;此外,所用数据集包含的场景有限、目标单一且小目标少,训练所得模型难以在课堂场景中推广。针对课堂场景中学生活动空间有限、行为受时间影响小的特点,可使用多目标回归的目标检测方法对学生课堂行为进行检测。本文主要工作有:
(1)针对检测任务,通过课堂视频均匀采样,建立了学生行为检测数据集;
(2)通过设计多尺寸输出的网络结构、聚类生成的预选框,适应了学生目标尺寸的变化;
(3)采用了两段式训练策略,优化了训练参数,提高了模型训练速度和模型性能。
1 相关算法
YOLO(you only look once)目标检测算法由Rodmon等提出[10],其原理是通过神经网络提取图像特征,将图像划分成S×S个网格,每个网格针对中心落在网格内的目标预测B个边界框(bounding box)和置信度(confidence scores),以及C个类别(class)。
该算法采用基于残差结构[11]与全卷积网络[12](fully conventional networks,FCN)的Darknet-53[13],包含53个卷积层,能够提取图像更底层的特征。算法采用Anchors boxes机制[14],使用多个预选框对目标进行预测。其工作原理为:采用大小与比例不同的几个预选框采集同一网格特征,并根据预测边框与真实边框交并比(intersection over union,IOU)与置信度的阈值选择最适合的预选框采集图像特征[15]。
YOLO算法在实际应用中应考虑以下几点:①根据实际场景中数据特点和目标检测要求,合理设计与制作数据集;②针对实际场景中目标大小及特征深度提取的需求,设计结构合理的网络;③选择适应数据特点的模型训练策略与参数。
2 学生课堂行为检测方法设计
2.1 实验数据集
实验数据来源于17个不同课堂,经采集、筛选和处理、行为统计、标注4个步骤完成数据集制作,具体过程如下:①数据采集。每课堂采集40-50分钟的视频数据,总时长680分钟;②数据筛选与处理。去除视频中非课堂场景部分,并对课堂部分视频做均匀采样,生成jpg格式图片数据集;③行为统计。经统计各课堂场景中学生行为类别总数为15个,其中7个出现频率低,单个课堂场景中出现类别最多为7个;④数据标注。以统计结果为依据,选取出现频率较高的8个类别为标签对所有图像文件进行标注,标签说明见表1,数据按照PASCAL VOC数据集格式进行保存。数据集由图像文件及包含有标注对象分类信息、边框位置信息的XML文件组成。

表1 学生课堂行为检测数据标签
学生课堂行为检测数据集共包含1300幅图像、46 800多个目标,表2表明该数据集具有目标数量大、目标密集、分类和尺寸多变、遮挡率高等特征。
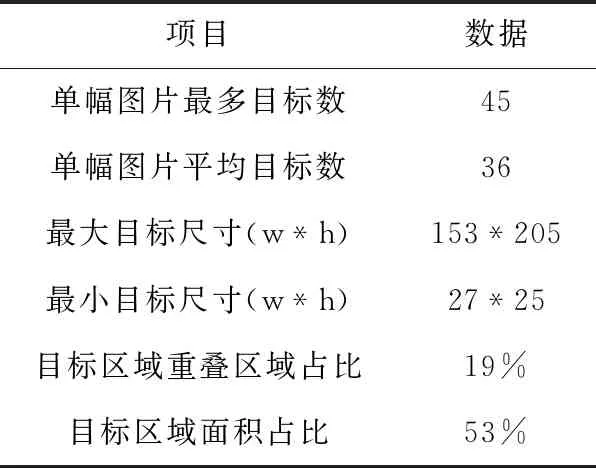
表2 学生课堂行为数据集特征
2.2 模型设计与训练
如图1所示,学生行为检测网络模型包含DBA结构(Darknetconv2D_BN_Activation)和ResN结构(Resblock_body)。每个DBA结构依次包含一个Conv2D层、一个BN(batch normalization)层和一个激活函数层。每个ResN结构依次由一个Zero padding层、一个DBA结构和N个Res_unit 组成(Res_unit为残差网络基本单元),且同一个ResN结构中特征尺寸不变。该网络为全卷积网络,包含75个卷积层,通过改变卷积步长(stride)实现网络特征尺寸变化。图1中实线框为网络模型特征提取的主体部分,由一个DBA结构和5个ResN结构组成。
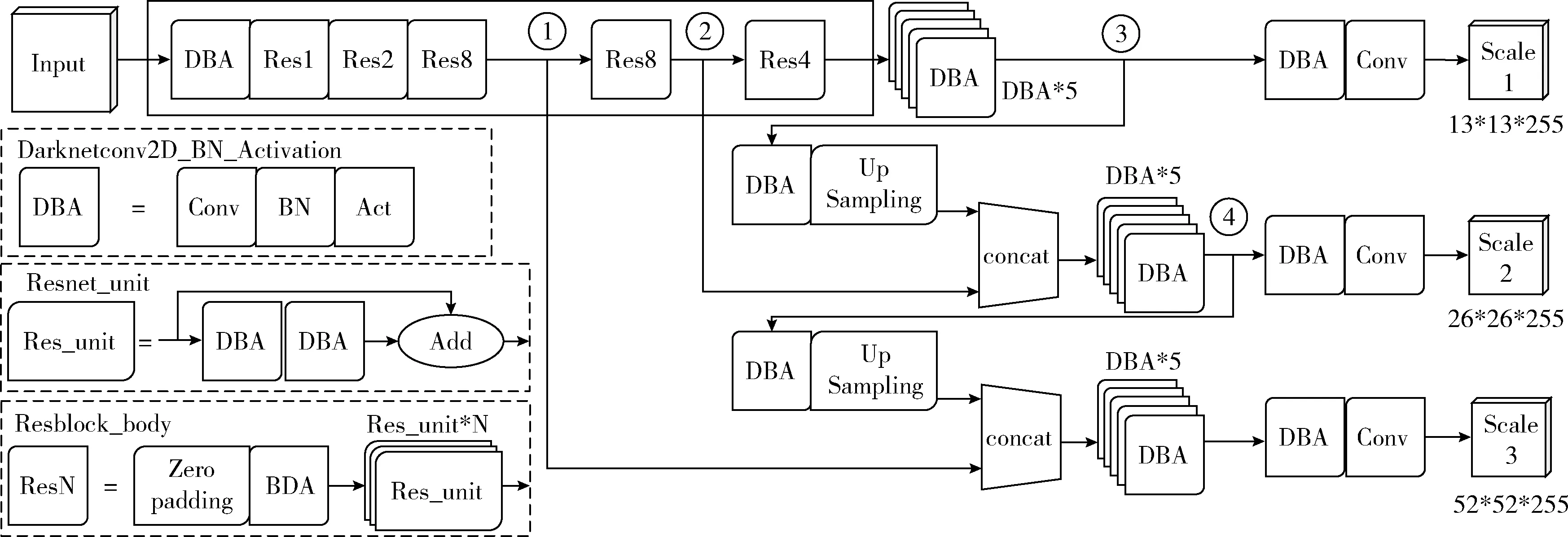
图1 网络模型结构
为提高课堂场景中小目标检测能力,并兼顾模型检测速度与准确率,网络采用图像32、16、8倍下采样后的3种尺寸进行输出。第一种尺寸由特征提取主体后接6个DBA结构和1个Conv2D 层输出,其维度为13*13*255。第二种尺寸由节点3输出经1个DBA结构和一个上采样层与节点2连接,再经过6个DBA结构和1个Conv2D层输出,其维度为26*26*255。第3种尺寸由节点4输出经1个DBA结构和一个上采样层与节点1连接,再经过6个DBA结构和1个Conv2D层输出,其维度为52*52*255。回归器接收3种尺寸输出的特征,并计算目标分类值、置信度和位置值,最后计算loss值。
该模型利用特征图中网格坐标的相对位置来预测目标边框,使目标位置参数易于收敛。具体计算如式(1)所示,其中xp、yp为预测边框的中心坐标,wp、hp为预测边框的宽和高,xg、yg为特征图中当前预测网格左上角坐标,ε(ox)、ε(oy) 为预测边框中心坐标相对于xg、yg的偏移量,其中ε为sigmoid函数,用于将ox、oy约束在(0,1)之间,保证预测中心落在当前网格内,wa、ha为预选框的宽和高,wu、hu为预测边框相对于预选框宽、高的偏移量,e为自然常数
xp=ε(ox)+xg
yp=ε(oy)+yg
wp=wa*ewu
hp=ha*ehu
(1)
loss函数计算如式(2)所示,包含4个损失项,边框中心坐标损失、宽高损失、置信度损失和分类损失。当预测网格中包含目标物体时θobj=1、θnoobj=0, 否则θobj=0、θnoobj=1。 式中wt、ht、xt、yt为真实边框宽高和中心坐标值,wp、hp、xp、yp为预测值,ct、cp为置信度真实值与预测值,clt、clp为分类真实值与预测值。其中Η为交叉熵函数,计算括号中参数的交叉熵。此外S为当前特征图大小,A为预选框的个数,K为分类的种类数

(2)
本文设计了两段式训练策略,以提高模型训练速度。第一阶段为适应性阶段,加载由COCO数据集[16]训练所得权重,训练过程中只对网络最后三层的权重做更新,使得loss值下降到较为稳定的区间;第二阶段为优化阶段,加载第一阶段训练所得权重,在数据集上迭代训练,更新网络各层权重参数,使网络模型趋于最优化、loss值下降到最优区间。
模型训练时的超参数是影响其训练速度和性能的另一重要因素,下文将通过实验对影响模型训练较大的学习率(learning rate)、批尺寸(batch size)、预选框尺寸、激活函数(activation function)、优化器(optimizer)5项参数进行筛选,并确定优化的模型训练方案。
2.3 学生课堂行为检测
学生课堂行为检测流程如图2所示。首先,将课堂监控视频切分成图像逐帧输入到训练好的网络模型中,由网络给出预选目标集;其次,通过设定阈值排除得分小的目标的选项,剩余预选目标做降序排列;而后使用非极大值抑制(NMS)排除冗余选项;最后,由回归器计算出目标位置和分类结果,并在图像中标示。
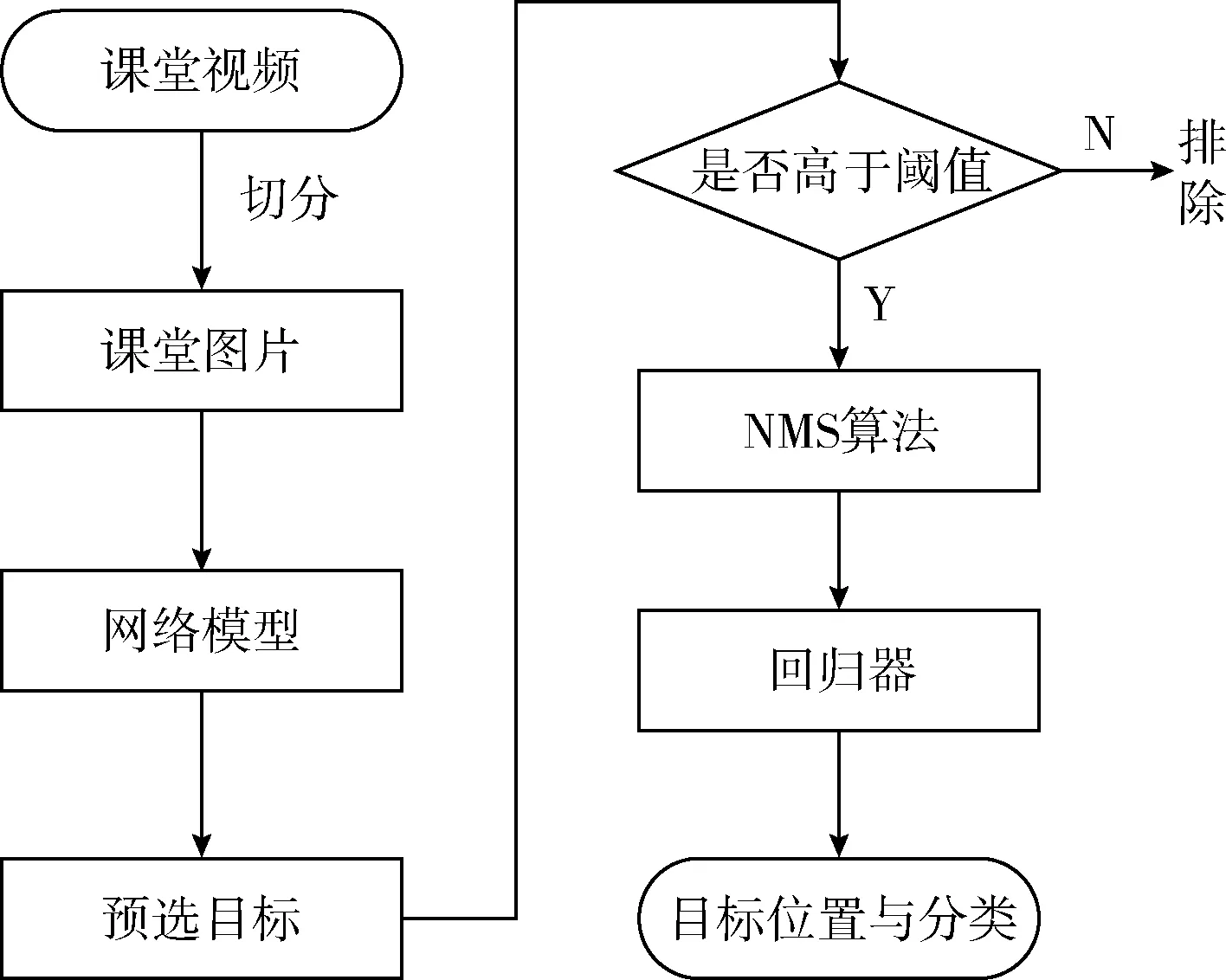
图2 学生课堂行为检测流程
3 实验与结果
本文设计了以下5组实验,用以筛选模型的训练参数。实验系统环境为Ubuntu 18.04.01,算法框架为Keras;计算硬件为Nvidia GPU∶Tesla P100。
3.1 学习率
为避免learning rate过大而造成目标函数发散、模型难以收敛,实验选取了10-3,10-4,10-5这3种不同的learning rate,验证该参数对模型训练产生的影响,实验结果如图3、图4所示。learning rate为10-5时,loss值下降较为缓慢。当learning rate为10-3时,loss值前期下降较快,但后期发生了震荡。learning rate为10-4时,loss值在整个过程中能够稳定下降。
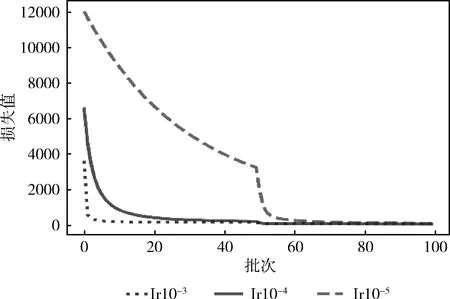
图3 不同学习率下loss值变化趋势
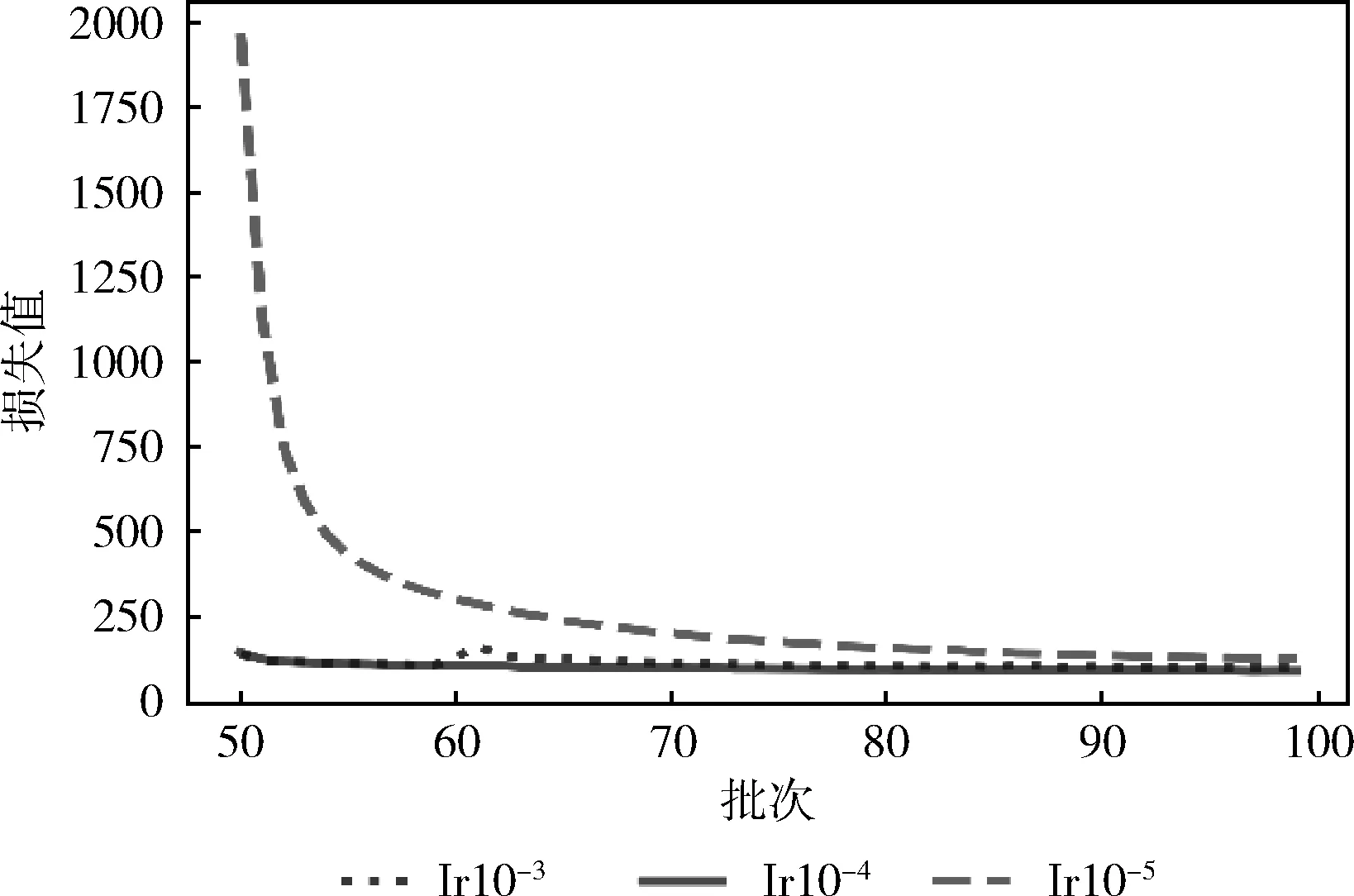
图4 不同学习率下loss值变化趋势局部图
3.2 批尺寸
因计算设备内存(12 G)的限制,训练时batch size设置的上限第一阶段为64,第二阶段为15。由于第一阶段训练只对模型最后3层的权重做更新,对模型性能影响小,因此主要观察第二阶段batch size变化对模型性能产生的影响。实验结果见表3,随着batch size减小,训练迭代次数增加时,模型有更多的机会向不同梯度方向做更新、更具泛化能力,mAP(平均精准度)值逐渐提高。
3.3 预选框尺寸
为适应课堂场景中不同尺寸学生目标,选取了6、9、12这3个不同的k值,通过聚类训练集中的目标边框尺寸,得到3组预选框。实验结果见表4,其中avg_iou为预测框
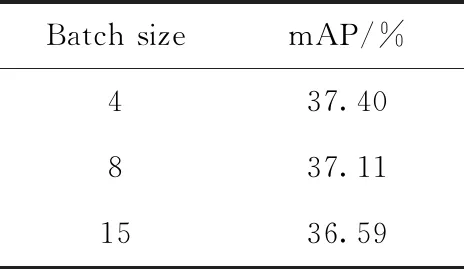
表3 不同批尺寸下模型mAP值

表4 不同预选框下模型avg_iou与mAP值
尺寸与真实目标框IOU的平均值。实验结果表明聚类得到的预选框尺寸提高了模型的检测性能,且随着预选框个数的增加模型的检测性能进一步提升。
3.4 激活函数
实验对比了ELU、ReLU、LeakyReLU、Softmax为激活函数时模型loss值的变化趋势,实验结果如图5、图6所示。由于第一阶段只对网络最后3层权重进行更新,导致Softmax作为激活函数时loss值下降缓慢,且Softmax函数易发生梯度消失现象。相较于指数型的ELU激活函数,ReLU和LeakyReLU这类导数恒定的激活函数计算成本更低,loss值收敛更快。

图5 不同激活函数下loss值变化趋势
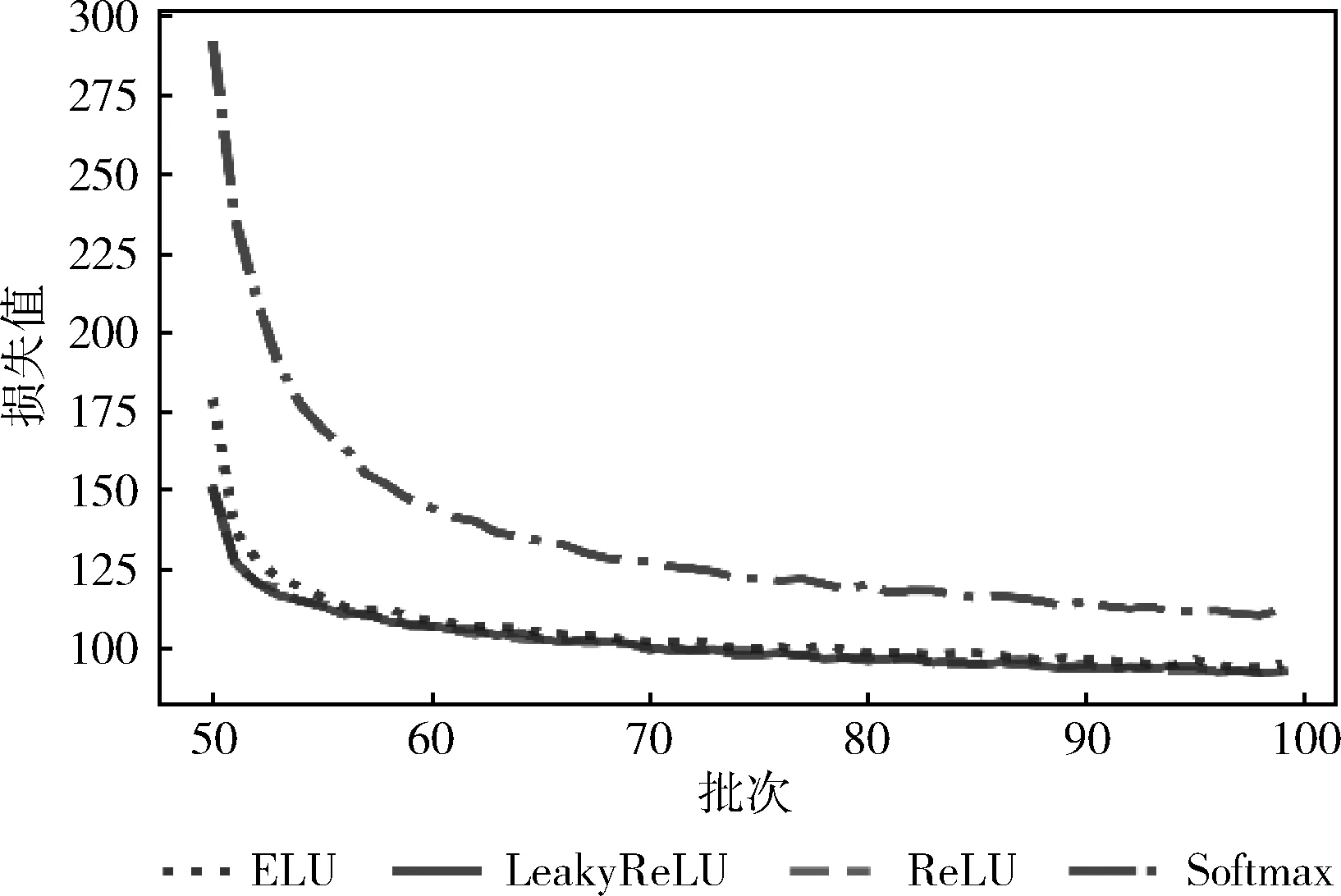
图6 不同激活函数下loss值变化趋势局部图
3.5 优化器
实验对比了SGD、Adagrad、RMSprop、Adam这4种优化器对模型训练产生的影响,实验结果如图7、图8所示。模型在第一阶段训练中只对最后3层权重进行更新,因此固定学习率的SGD优化器效果更佳;第二阶段对网络各层权重进行整体优化,RMSprop和Adam优化器采用指数移动平均公式计算梯度的二阶动量,能自动调整学习率,且改善Adgrad学习率下降过快问题,而Adam计算了梯度的一阶动量使模型训练更具稳定性。

图7 不同优化器下loss值变化趋势
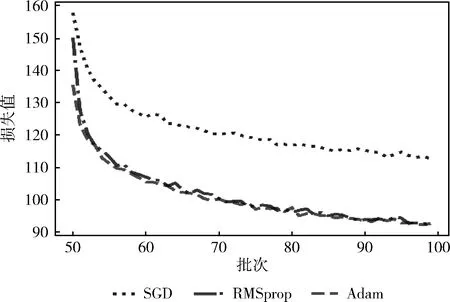
图8 不同优化器下loss值变化趋势局部图
3.6 优化训练方案
通过分析以上5组实验,最终确定训练方案见表5。详述如下:①为防止梯度消失,且避免因为ReLU函数在输入为0时造成的神经元坏死,整个训练过程都采用LeakyReLU激活函数。②为提高模型的检测性能,并保证模型训练速度,训练过程使用k=9时聚类所得预选框。③第一阶段训练选择固定学习率的SGD优化器,且使用较大学习率与批尺寸,加速第一阶段的训练,使loss值较快向最优区间收敛。④为保证模型稳定收敛且具有良好泛化能力,第二阶段起始学习率设置为10-4,并使用较小的批尺寸和更适应参数变化的Adam优化器。
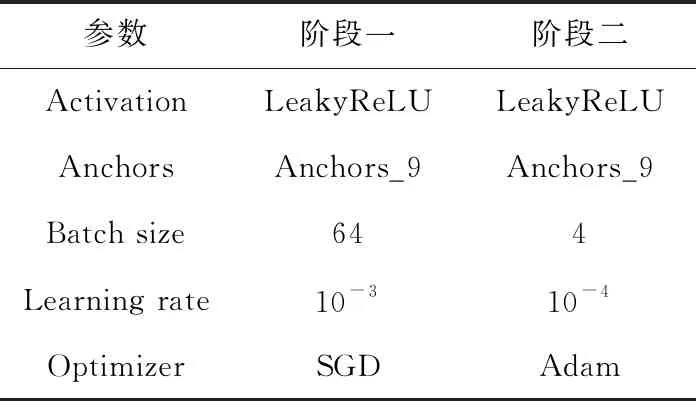
表5 优化训练方案
经上述方案训练,模型训练时长由384分钟缩减为206分钟,mAP由最初的35.32%提高为40.73%,在视频检测中平均fps为20,检测效果如图9所示。

图9 模型检测效果
4 结束语
由于课堂场景中学生个体多、行为不统一等特点,常见行为识别方法难以运用其中。本文采用多目标回归的方法,通过制作学生课堂行为检测数据集、构造学生行为检测模型,实现了课堂场景下的学生行为检测。通过观察不同参数对模型性能产生的影响,结合两段式模型训练策略,本文提出了一种优化的模型训练方案。经过验证,该方案有效缩短了训练所需的时长,提高了模型检测的能力,实现了在视频中学生行为的实时检测。
