基于k近邻属性重要度和相关系数的属性约简
2020-09-29林芷欣刘遵仁
林芷欣,刘遵仁,纪 俊
(青岛大学 计算机科学技术学院,山东 青岛 266071)
0 引 言
为了有效去除冗余信息,并且不改变原始信息的分类能力,属性约简算法随之产生。在邻域粗糙集中,为了能快速得到属性约简,Hu等提出基于属性重要度的前向贪心式属性约简算法;Hu等又通过研究正域的变化,发现新加入的属性不会改变之前正域样本的性质,由此提出了FARNeMF算法。Liu等通过改进Hu等的FARNeMF算法,提出了FHARA算法[1]。以上3种算法,都是通过逐渐优化所选待测样本,来降低邻域计算的次数,达到节省算法的时间开销的目的。但是,上述算法在贪心选择重要度高的属性时,一直保持着高维计算,算法复杂度高,且重复计算较多,浪费资源[2]。基于这种情况,本文在算法属性重要度的计算上做了一些改进,提出一种属性重要度计算方法,根据样本k近邻条件属性与决策属性的关系[3,4],重新给出了属性重要度的定义,降低计算维度,提高算法运行效率。另外,考虑到条件属性之间的关联程度,也会对约简结果产生影响,因此引入相关系数的概念,降低属性间关联程度对属性约简结果的影响[5]。实验结果表明,本文提出的算法能获得较好的属性,并得到较高的分类精度。
1 相关概念和理论
1.1 粗糙集理论
粗糙集理论认为,客观世界可以抽象为一个知识表达系统。这个知识表达系统又可以被看成是一个关系数据表,表的行代表被研究的对象,表的列代表被研究对象的属性,对象信息就通过各属性对应的属性值来表达[6]。给定一四元组DT=(U,A,V,f) 是一个知识表达系统,知识表达系统的详细定义请参考文献[7]。
定义1 设DT=(U,A,V,f), 若P⊆A, 对论域上的一个对象子集X⊆U, 定义X关于P的上近似、下近似和边界域分别为
(1)
(2)

(3)

1.2 邻域粗糙集
定义2 在给定实数空间Ω上的非空有限集合U={x1,x2,…,xn},U={x1,x2,…,xn} 对U中任意对象xi的δ-邻域定义为:δ(xi)={x|x∈U,d(x,xi)≤δ}。
其中δ≥0,d为距离函数。δ(xi) 称作由xi生成的δ-邻域信息粒子,简称为xi的邻域粒子。
定义3 给定一四元组NDT=(U,C∪D,V,f) 为邻域决策系统,C是条件属性集,D是决策属性集,C∩D=φ。D将U划分为N个等价类: (X1,X2,…,XN), 对∀B⊆C,X关于B的下近似、上近似和边界域分别为
(4)
(5)
(6)
2 属性约简算法
已有的基于属性重要度的约简算法,它们大部分都是基于Hu提出的属性重要度概念,在选择下一个属性时,需要计算所有未选入约简集合的属性的重要度,最后贪心的选择一个属性并入约简集合[2]。虽然后来提出的FHARA算法优化了待测样本的数量问题,但还是避免不了其中需要进行很多重复的邻域计算操作。针对这个问题本文提出了一种k近邻属性重要度算法,通过依次计算每一维度下样本点x的k近邻异类样本点平均距离和k近邻同类样本点平均距离的比值,来判断每一维度属性对同类和异类样本的区分能力,并将其作为属性重要度的衡量指标。但由于该方法只考虑了样本条件属性对决策类的影响,忽略了条件属性之间可能存在的相互影响[8],因此,本文再将属性间相关系数融入到属性约简算法中。当属性约简集拟并入新属性时,新属性需要和约简集中已有属性进行相关系数计算,若相关系数较高,则新属性不加入约简集,反之,新属性加入约简集,直至得到最终的属性约简。
2.1 现有属性重要度约简算法
基于邻域粗糙集属性重要度的定义最先是由Hu提出的,他给出的定义请参见文献[6]。
比较典型的基于属性重要度的约简算法有Hu提出的FARNeMF算法和Lin提出的FHARA算法。通过分析可知,现有属性重要度的定义是通过并入集合的属性集所划分的正域大小判断。也就是说,一个属性的加入,能让越多的样本划入正域,这个属性的重要度就越大。但每当要并入一个新的属性时,都需要将所有未并入的属性依次与已经选择的属性集相并,计算它们的正域大小[9,10]。最终选择ak, 使其满足
SIG(ak,red,D)=max(SIG(ai,red,D))
(7)

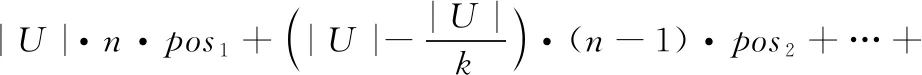
(8)
式中:posi表示加入第i个属性时,样本进行正域判定所耗时间。
2.2 基于k近邻的属性重要度
基于传统属性重要度的约简算法中新属性并入时正域的计算量虽然是一个降维的过程,但由于属性约简算法最终选择的属性较少,因此,即便是一个降维的过程,每次贪心选择属性时,平均正域的计算量也是维持在n维左右,算法计算量偏大,重复的正域计算较多[11]。本文提出的基于k近邻的属性重要度算法,在并入新属性时只需进行一维正域计算,算法计算量减少,运行效率较高。算法具体描述如下:

(9)

算法1: 基于k近邻的属性重要度算法
输入:NDT=(U,C∪D,V,f), 样本抽样次数m, 最近邻样本个数k
输出: 条件属性的属性重要度序列
(1)初始化,Pow=0
(2)∀x∈U
forj=1∶n
1)在每一维度下, 找距离样本x最近的k个同类样本点 (x1,x2,…,xk) 和k个异类样本点 (y1,y2,…,yk)。
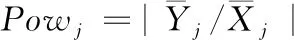
end
(3)Order=sort(Powj)
(4)return Order
2.3 相关系数及其性质
在2.2节提出的属性重要度的计算方法,只考虑了单个条件属性对决策属性的影响,没有考虑条件属性之间的关系也会对约简结果产生影响。如果两个条件属性的相关性较强,二者又都在约简结果中,就会导致数据冗余[12]。因此为了避免数据冗余,本文引入秩相关系数计算条件属性间的相关性,去除多余属性[10]。
定义4 给定一邻域决策系统NDT=(U,C∪D,V,f), ∀ai,aj∈C, 将ai和aj中的数据按照属性值从小到大分别进行排序后对每个对象进行编秩,第k个对象在ai,aj属性下对应的秩次分别为xk和yk, 则ai和aj的相关系数ρij定义为
(10)
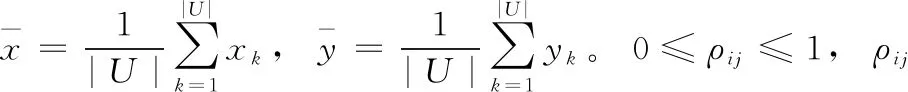
下面给出一求某对属性相关系数的例子。
例1:给定一决策表,见表1。求表中属性a,b的相关系数。
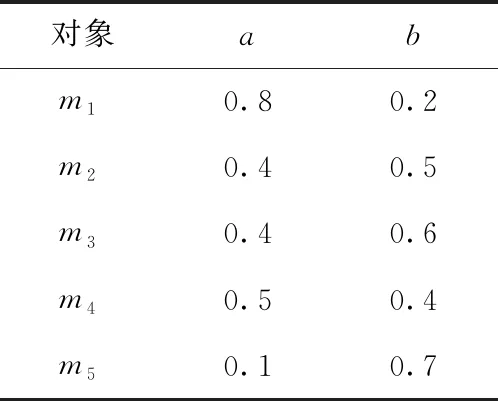
表1 决策表
(1)将属性a的属性值按从小到大排序,得到一个对象序列 {m5,m2,m3,m4,m1}, 对对象进行编秩得 {m5=1,m2=2,m3=3,m4=4,m1=5}。
(2)如果一个属性中有属性值相同,秩次取它们的平均值。属性a中m2=m3, 所以它们的秩次调整为m2=m3=(2+3)/2=2.5, 得到新的秩次序列 {m5=1,m2=2.5,m3=2.5,m4=4,m1=5}。
(3)同理可得属性b下各对象对应的秩次序列 {m1=1,m4=2,m2=3,m3=4,m5=5}。


表2 秩次表
(5)根据相关系数计算公式,计算属性a、b的相关系数为0.97。
算法2: 相关系数算法
输入:NDT=(U,C∪D,V,f), 条件属性子集ai,aj
输出: 相关系数ρij
(1)将对象按ai和aj下对应属性值从小到大排序, 并编秩;
(2)更新秩次序列, 按表中原始对象顺序排列;

(4)按照公式计算相关系数ρij;
(5)返回ρij。
2.4 基于k近邻属性重要度和相关系数的属性约简算法(K2NCRS)
K2NCRS算法在根据算法1算出属性重要度序列后,要依次选取属性重要度最大的属性加入约简集,加入约简集前,要对拟加入属性和约简集中的所有属性进行相关系数的判定,这里需要设置一个阈值γ。 如果拟加入的属性和约简集中其它属性的相关系数都小于γ, 则对拟加入的属性继续进行判断,若加入后正域的样本增多,则将该属性加入约简集,反之,删除该属性。如果拟加入的属性和约简集中其它属性的相关系数存在不小于γ的,将拟加入的属性删除,继续遍历除约简集外其它属性重要度较高的属性,直至所有样本都被加入正域。
另外,在进行样本正域计算时,需要设置样本的邻域大小,为了能获得较好的效果,本文选用文献[10]提到的标准差方法,来确定邻域δ的大小。
算法3: K2NCRS算法
输入:NDT=(U,C∪D,V,f),δ
输出: red
(1) 初始化pos=φ,smp=U,flag=φ;
(2) 利用算法1算出属性重要度序列Order;
(3) red=Order(1);
(4)while sum(smp)~=0
forai=Order-(red∪flag)
flag=φ;
for ∀aj∈red
利用算法2, 计算ai和aj的相关系数ρij。
ifρij>γ
去掉和已选属性相关性大的属性
else
pos=Pos(smp,[red,ai]);
red=red∪ai;
smp=setdiff(smp,max_pos);
end
end
end
end while
(5) return red


(11)
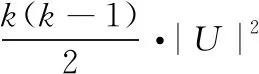
3 实验分析
3.1 实验准备
为检验本文算法的性能,从UCI数据库中选取6组常用连续型数据进行实验,表3给出了数据集的详细描述。另外,为消除数量级对计算的影响,本文对所有实验数据进行归一化处理,使得所有实验数据都在[0,1]区间内。

表3 数据集描述
3.2 算法有效性验证
实验将K2NCRS算法与Liu提出的FHARA算法分别在属性约简数量、分类精度及算法运行时间上进行了详细的对比分析,通过各项实验数据验证了K2NCRS算法是有效的。并且本文算法实验结果是在相关系数阈值设置γ为0.6的条件下得到的。
3.2.1 属性约简数量比较
表4显示了FHARA算法和K2NCRS算法在约简前后,属性数量的变化。从表中可以看出,当邻域大小一定时,在wdbc、sonor和wpbc这3组数据集上K2NCRS算法得到的属性比FHARA算法多1个,在diabetes数据集上K2NCRS算法约简得到的属性比FHARA算法多两个,在ionosphere和biodeg两组数据集上K2NCRS算法得到的约简属性比FHARA算法多3个。整体上看K2NCRS算法约简得到的属性数量比FHARA算法偏多。但是,两算法约简后的属性个数都明显少于原始条件属性的个数,因此,本文K2NCRS算法都能有效删除冗余信息,达到属性约简的效果。
3.2.2 分类精度比较
为获得约简后属性的分类能力,我们选用了SVM分类学习算法,选用10折交叉验证的方法,得到两算法约简后属性分类精度见表5,表5中两算法在SVM分类器下的分类精度的对比柱状图如图1所示。
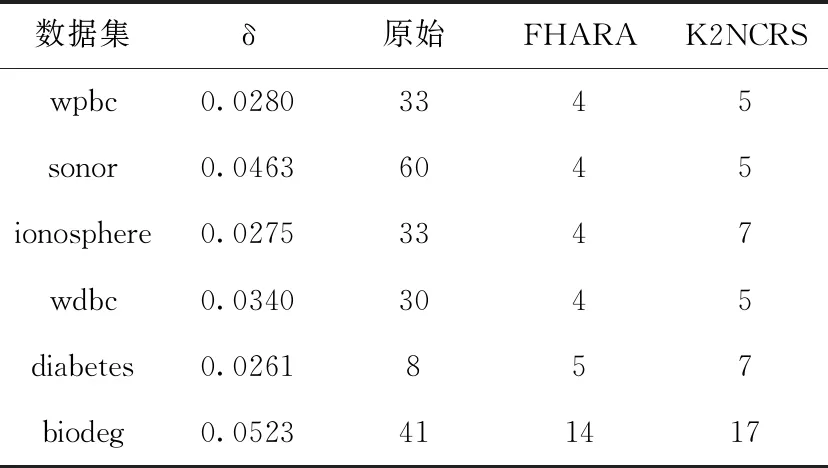
表4 属性约简数量比较

表5 SVM分类器下分类精度比较

图1 SVM分类器下FHARA与K2NCRS算法分类精度对比
图1横坐标表示实验所选属性集编号,并且该编号顺序是按照数据集样本数量由少至多编排,纵坐标表示约简后每组属性集对应的分类精度。从图整体上看,两种算法对应柱体的变化趋势大致相同,对比两种算法实验得到分类精度的最大最小值发现,本文算法分类精度的变化区间小于 FHARA 算法,说明本文算法能够得到较好的约简属性。从前4组数据可以明显看出,K2NCRS算法的分类精度高于FHARA算法,对比后两组数据发现,K2NCRS算法的分类精度略低于FHARA算法。造成这种现象的原因,是因为本文算法中仅通过两类相邻样本的距离大小来判断某个属性的重要度这一条件,随着样本数量的增多,受数据中其它噪声的影响变大,判断条件的不稳定性增大,进而影响属性重要度的判断。
3.2.3 相关系数阈值选取
计算属性间相关系数时,需要设置相关系数的阈值,通常情况下,相关系数大于0.8,代表属性间相关性极强,相关系数在0.4-0.8代表属性间有较强的相关性,相关系数低于0.4代表属性间相关性较弱。表6~表9分别记录了相关系数阈值γ取0.4,0.5,0.6,0.7时本文算法对应得到的属性约简数量和分类精度。
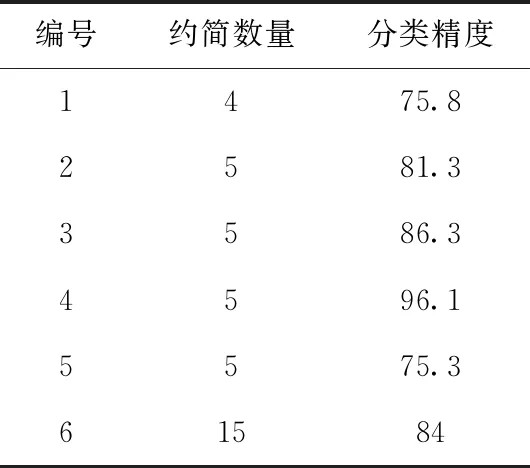
表6 γ=0.4
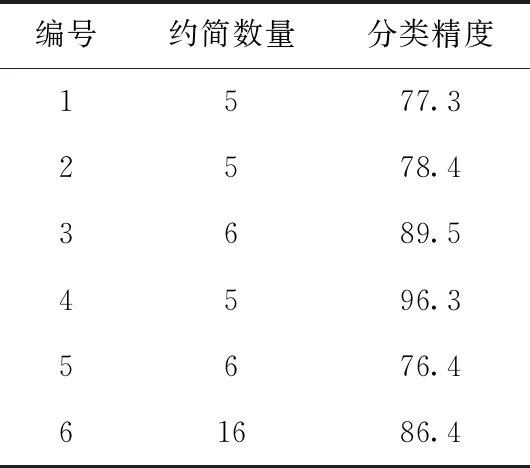
表7 γ=0.5

表8 γ=0.6

表9 γ=0.7
为了方便观察,绘制6组数据在不同阈值下的分类精度对比折线图如图2所示。

图2 6组数据在不同阈值下的分类精度对比
对比表6~表9及图2,可以发现当阈值为0.4时,各个数据集得到的约简数量最少,并且对应的分类精度普遍较低,当阈值为0.7时,各个数据集对应的约简数量最多,并且大部分数据集对应的分类精度随着阈值的增大也逐渐提高,这是因为当阈值设置较小时,判断属性相关性的条件就显得过于严苛,因而导致最终剩余属性较少,且分类精度不高。当阈值设置较大时,判断属性相关性的条件又显得过于宽松,不能有效去除冗余属性,导致最终约简出的属性个数较多,并且阈值较大时对应的分类精度的变化也不明显。综合考虑,本文算法在阈值为0.6时,约简得到的属性个数不是最大,并且各组数据对应的分类精度均接近最大值,因此,本文算法的相关系数阈值设为0.6.
3.2.4 运行时间比较
图3是本文提出的K2NCRS算法与Liu提出的FHARA算法在同一台机器上的运行时间对比折线图。对比图中两条折线,执行K2NCRS算法得到的折线一直在执行FHARA算法得到折线的下方,说明对于大部分数据集而言,K2NCRS算法的运行效率更高,算法执行速度更快。同时,这一结果也与2.4节中对两种算法计算量的分析结果相吻合。再次验证了本文提出的基于k近邻的属性重要度算法的时间复杂度低于基于依赖度的属性重要度算法。所以,K2NCRS算法能获得更短的时间开销,算法运行效率更高。

图3 FHARA与K2NCRS算法运行时间对比
通过以上几组实验的对比,虽然本文的K2NCRS算法约简得到的属性数量比基于属性依赖度的传统FHARA算法多,但和原始数据集的属性个数相比,本文算法仍能够有效去除多余属性,并根据最终得到的属性约简集也能获得不错的分类精度,并且随着样本数量和条件属性个数的增多,本文算法的运行时间和FHARA算法的对比就越明显。
4 结束语
目前邻域粗糙集下基于属性重要度的属性约简算法,大多都是通过优化区间减少正域计算时比较样本的数量,来提高算法的运行效率。但是这种优化方法还是避免不了每次贪心选择属性时仍需要依次反复的对所有尚未选择的属性进行重要度计算,因此本文从属性重要度的定义着手,提出一种基于k近邻的属性重要度算法,将贪心选择属性时重复的重要度计算改为对每个样本k近邻的属性加权评估计算,极大提高了算法的运行效率,减少了算法的时间开销。
