基于门控卷积网络与CTC的端到端语音识别
2020-09-29杨德举马良荔谭琳珊裴晶晶
杨德举,马良荔,谭琳珊,裴晶晶
(1.海军工程大学 电子工程学院,湖北 武汉 430033;2.中国人民解放军91001部队,北京 100841)
0 引 言
传统的自动语音识别(automatic speech recognition,ASR)系统使用混合高斯模型-隐马尔科夫模型(GMM-HMM)[1]作为声学模型进行训练,然后利用外部语言模型对单词序列进行重核,生成合理的句子。系统一般包含声学模型、发音词典和语言模型等多个模块,设计过程中需要运用语音学、语言学等不同的领域知识,训练过程中各模块根据各自的优化目标单独进行训练,导致在推断阶段各模块的误差会不断累积。更重要的是,这些模型需要高质量的数据集来进行训练,数据集中的训练数据必须强制预对齐,保证每个输入帧必须有一个对应的标签,构建这样一个数据集需要大量的时间、精力。因此,设计和训练一个性能良好的ASR系统是极其复杂和困难的。
端到端的ASR系统是一种序列到序列(seq2seq)模型,它直接将输入的声学信号映射到字符或单词等输出,而不需要任何预定义的标签对齐。它将大多数模块包含到一个深度神经网络(deep neural network,DNN)中,使用一个整体的目标函数来优化模型[2-5]。基于此,本文提出了一种融合门控线性单元(gated linear units, GLU)[6]的卷积神经网络(convolutional neural network,CNN)模型。该模型使用一维CNN(1D-CNN)[7,8]联合上下文信息进行特征抽象,提高特征表达能力,利用链接时序分类(connectionist temporal classification,CTC)[9]技术实现端到端的语音识别。
1 相关研究
端到端的语音识别系统直接将输入的语音映射到字母或单词序列,并在单个系统中联合训练声学和发音等建模组件,其实现方法主要分为两类,分别为基于CTC的方法和基于注意力机制[10]的方法。基于CTC的方法通过引入CTC准则,解决了输入序列长度大于输出序列长度的问题,与DNN结合可直接用于端到端的模型建模。基于注意力机制的方法通常包括一个编码器网络和一个解码器网络,编码器将输入的语音映射到更高层次的特征表示,然后注意力机制决定应该注意哪些编码器特性,以便预测下一个输出符号,从而生成上下文向量,最后解码器获取注意力上下文向量和前一个预测的嵌入,以生成下一个输出的预测。
1.1 基于CTC的方法
语音识别数据集是语音文件和对应标签文本的集合,将数据集中的语音帧和文本字符进行对齐是一项艰难的任务。CTC算法是专门用于解决seq2seq模型中数据对齐问题的,它引入了一个blank标签代表静音帧和字符间隔。在空白标签的基础上,设计了路径的中间结构,通过删除路径中所有重复的和空白的标签,可以将一些路径包含到最终的标签序列中。因此,没有分割和对齐,CTC仍然可以将输入序列映射到输出序列。Maas A等[9]在对话语音转录任务中利用CTC训练了一个深度双向循环神经网络(deep bidirectional recurrent neural network,DBRNN),通过结合字符级语言模型,达到了与GMM-HMM基线系统相当的识别率。姚煜等[11]提出了基于双向长短时记忆神经网络(bidirectional long short-term memory,BLSTM)的声学模型构建方法,并将CTC应用于声学模型训练中,搭建出基于BLSTM-CTC的端到端中文语音识别系统。张立民等[12]将CTC作为目标函数,改进深度双向长短时记忆网络架构,以音素为基本建模单元,构建了一种基于序列级转录的端到端语音识别系统。通过在解码过程中引入词典和语言模型,并利用序列区分度训练技术提升CTC模型的建模效果。Wang等[13]提出一个CNN+BLSTM+CTC端到端普通话语音识别模型,采用CNN学习局部语音特征,BLSTM学习上下文信息,使用CTC进行解码。
1.2 基于注意力机制的方法
Chan等[3]提出的LAS(listen, attend and spell)神经网络结构包含一个监听器和一个拼写器,监听器是一个金字塔式的BLSTM网络,拼写器是一种基于注意力的循环网络解码器,它根据所有之前的字符和整个声音序列发出每个字符。与DNN-HMM、CTC等模型相比,LAS对给定的声序列输出字符序列的概率分布没有独立的假设。针对LAS在普通话语音识别中效果不佳的问题,Shan等[5]对其进行了改进,使用字符嵌入来处理大量的词汇,采用L2正则化、高斯权值噪声和跳帧等方法对模型进行有效训练,并在注意力模型中使用注意力平滑方法来覆盖更长的上下文。Chiu等[14]使用多头注意力机制对LAS模型进行了结构的优化改进,显著提高了性能。Zhou等[15]将Transformer扩展到语音识别领域,提出了一个贪婪级联解码器Transformer模型,在普通话语音识别上效果良好。
2 模型结构
本文设计的1D-CNN+GLU+CTC的深度神经网络模型结构如图1所示。首先对输入的原始音频序列x进行预处理和特征提取。然后通过4类共10个卷积块(CNN blocks),每个CNN block包含3个操作,分别为一维卷积、门控线性单元和Dropout,每类CNN block设置不同的参数。之后,经过一个卷积核大小和步长均为1的一维卷积层,将输出映射为在每个时间步输出不同汉字的概率,最后由CTC层进行解码,输出标签序列y。

图1 模型结构
2.1 特征提取
在端到端的语音识别系统中,最常用的特征为梅尔频率倒谱系数(Mel-frequency cepstral coefficient,MFCC)和基于滤波器组的特征Fbank(Filter bank)。MFCC基于人耳听觉特性进行设计,是在梅尔刻度频率提取出来的倒谱参数。Fbank特征相当于去掉MFCC提取过程最后一步的离散余弦变换操作,与MFCC相比,Fbank特征保留了更多的原始语音信息。最近的研究中也出现了直接使用语谱图(Spectrogram)和原始语音波形进行建模的方法[4]。本文分别使用Spectrogram、Fbank、MFCC特征进行了研究和实验,特征提取的流程如图2所示。

图2 音频特征提取流程
2.2 门控卷积神经网络
卷积神经网络最先在图像识别领域得到广泛的应用,之后被引入到自然语言处理和语音识别领域。将CNN用于语音识别,不仅可以精确控制依赖项的长度,通过堆叠CNN来标识长序列还可以使邻近的输入元素在较低的层进行交互,而远处的元素在较高的层进行交互,从而提取更高层、更抽象的特征。本文使用融合了GLU的一维门控卷积神经网络,训练将一系列音频特征映射到对应的汉字。门控卷积神经网络结构如图3所示。
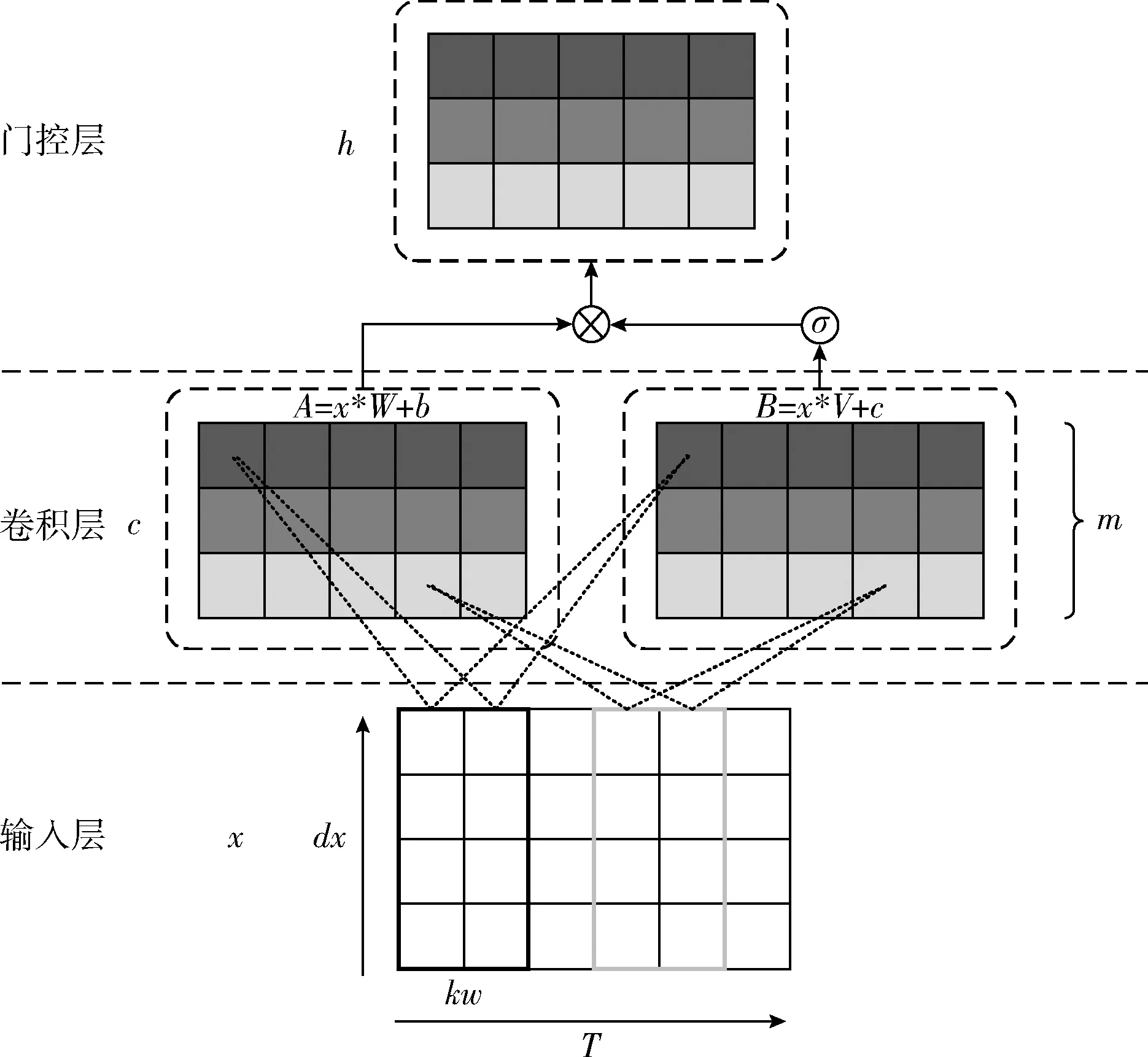
图3 一维门控卷积神经网络结构
设输入层的输入序列x=(x1,x2,…,xT), 其中xi∈Rdx, 即每一帧的输入为dx维的特征向量。其与宽度为kw, 步长为s, 深度为m的卷积核进行卷积计算的公式如式(1)所示
(1)
式中:w∈Rm×dx×kw和b∈Rm为模型需要学习的参数。在图3 中我们可以看到,当T=6,dx=4,kw=2,s=1,m=3时,经计算输出张量的大小为size=(3,5)。
对于门控线性单元,其计算公式如式(2)所示
h(x)=(x*W+b)⊗σ(x*V+c)
(2)
式中:*为卷积运算,⊗为矩阵对应元素相乘,σ是sigmoid函数。通过门控机制,网络可以控制在层次结构中传递的信息,使更有价值的信息通过网络,抑制无用的信息,提高网络的学习能力。门控卷积在保持非线性能力的同时为梯度提供了线性路径,可以减少梯度弥散问题[6]。
2.3 链接时序分类
链接时序分类(CTC)是一种将输入序列x转换为输出序列y的技术,其中x的长度大于y。它可以将音频数据直接转换为文本,而不需要中间语音表示。此外,不需要在输入序列和目标序列之间进行任何预对齐。
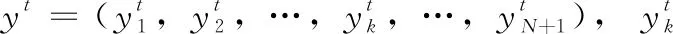
y=F(x),F∶(Rdx)T→(RN+1)T
(3)
在每个时间步t取字典L′中的一个元素并按时序排列,则可得到一个输出序列π, 我们称之为一条路径。在输入为x的条件下,输出路径为π的概率如式(4)所示
(4)
即在每个时间步输出路径π的相应标签字符的概率乘积。以上为路径概率计算的过程,该过程中路径与输入序列的长度T相同,而实际上标签文本的长度通常比输入序列要短得多。因此,我们应该将一些相关的路径合并到一个更短的标签序列中,路径合并一般分为两步:
(1)删除重复的标签。如果在连续的时间步骤中有多个相同的输出,则只保留其中的一个。例如:对于6个时间步的路径“cc-aat”、“c-attt”,移除重复标签后的路径均为“c-at”。
(2)从路径中移除空白标签“-”。“-”表示这一帧没有输出,应该删除它以获得最终的标签序列。第一步得到的标签“c-at”移除“-”之后得到最终输出为“cat”。
通常,一个很短的输出序列可以由多条路径π合并得到。图4的篱笆图给出了当路径长度为6时,标签序列“cat”的全部合法路径。
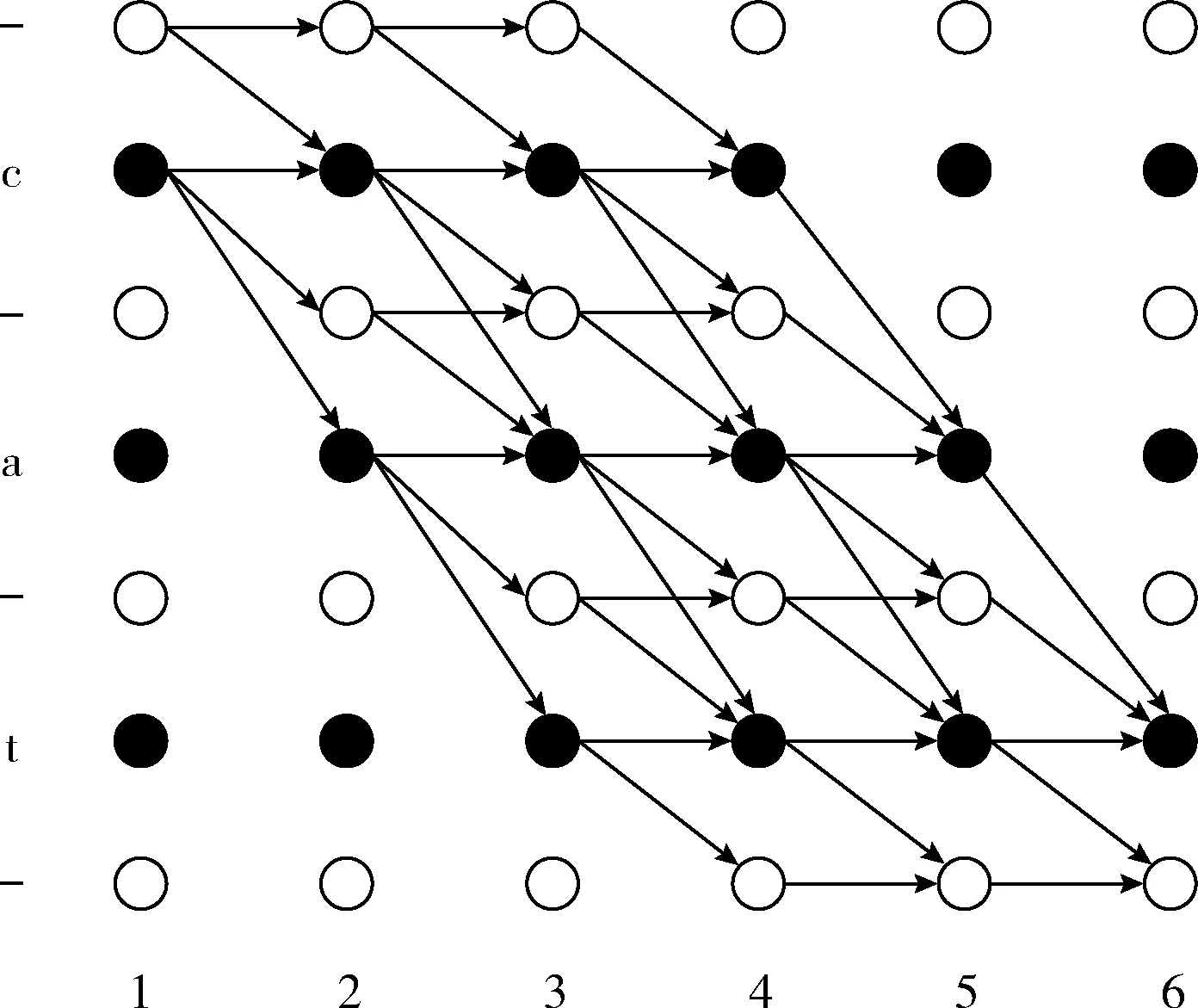
图4 CTC篱笆网格
除了从路径中获取最终标签序列外,路径合并过程还旨在计算最终标签序列的概率。定义变换B为从序列中删除空白和重复,则B(cc-aat)=B(c-attt)=cat。 对于给定输入x的情况下,输出为l的概率如式(5)所示
(5)
从上面描述的计算可以看出,标签序列的概率是可微的。因此,我们可以利用反向传播算法训练模型,使真标签的概率最大化,并利用训练后的模型,将概率最大的标签序列作为最终结果来识别语音。
3 实验与分析
3.1 实验环境
本文实验在i7 CPU和NVIDIA TITAN Xp GPU构建的硬件计算平台上,使用PyTorch深度学习框架进行。具体配置见表1。
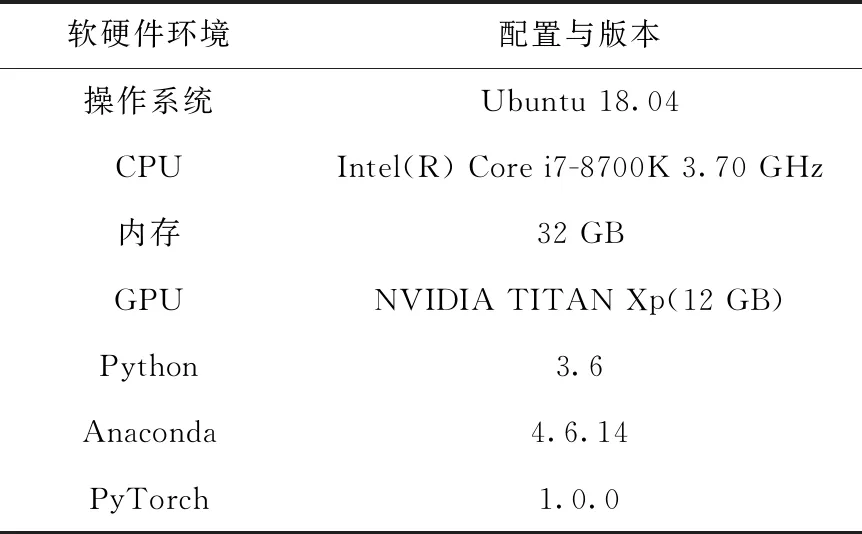
表1 实验的软硬件环境
3.2 数据集与评价指标
本文使用希尔贝壳开源的AISHELL-1中文普通话语音数据集[16]进行模型训练和实验,数据集包含400个说话人的141 600条录音文件,录音时长共计165 h,涉及常用的4000多个汉字。数据集被划分为训练集、验证集和测试集三部分,具体分布见表2。
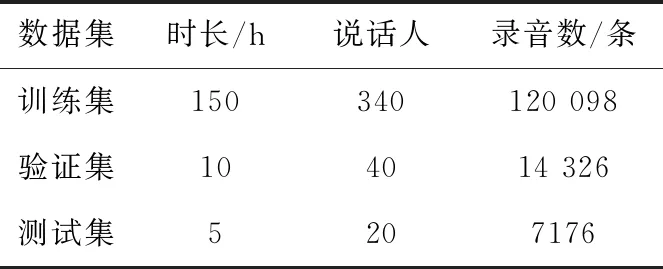
表2 数据集划分
英语语音识别任务中评价指标通常为WER,中文普通话语音识别任务中通常为字错误率(character error rate,CER)。本文使用CER作为评价指标,其计算公式如式(6)所示
(6)
式中:I为插入错误字数,D为删除错误字数,R为替换错误字数,L为真标签的总字数。
3.3 不同输入特征的比较
本文对Spectrogram、Fbank、MFCC这3类输入特征进行了实验比较,语音数据采用原始的16 KHz采样率,设置时间窗宽度为20 ms,时移10 ms,使用汉明窗对原始语音进行分帧、加窗,经FFT和谱线能量计算得到161维的Spectrogram特征,经Mel滤波得到40维的Fbank特征,MFCC使用常见的包含一阶、二阶差分的共39维特征。
不同输入特征下的系统最佳CER性能见表3,可以看出Fbank特征的CER最低,为15.9%。Spectrogram特征次之,MFCC效果最差。这是因为MFCC特征经过了更多的人工特征提取操作,不可避免地会造成信息的丢失,从而降低系统性能。而Spectrogram虽然最大限度保留了语音的原始特征,但也使冗余的无用信息得以保留,受其影响,在数据集规模没有足够大时,模型还不足以学习到真正有用的音频信息。
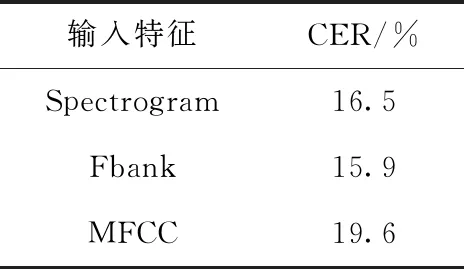
表3 不同输入特征的比较
3.4 与基线模型的性能比较
本文将文献[12,13]的模型作为基线模型,使用Fbank作为输入特征,在均不外接语言模型的情况下,将本文模型与基线模型在测试集上进行了性能对比,结果见表4,本文提出的1D-CNN+GLU+CTC模型在AISHELL-1数据集上比BLSTM+CTC[12]模型和CNN+BLSTM+CTC[13]模型的CER分别降低了4.8%和3.3%,取得了更好的效果。

表4 与基线模型的比较
4 结束语
本文提出了一个基于一维门控卷积神经网络和CTC的中文普通话语音识别系统,直接使用汉字作为输出标签,简化了系统训练和解码流程。尝试了不同的系统输入特征,验证了不同音频特征对系统性能的影响。在AISHELL-1数据集上的实验结果表明,与基线系统相比,该系统明显地降低了识别错误率。在今后的工作中,拟尝试进一步改进模型架构,并在现有数据集的基础上通过数据增强的方式弥补数据不足的问题,进一步提高系统的识别率。
