基于蚁群算法的ICN路由算法
2020-09-29龚娉婷周金和
龚娉婷,周金和
(北京信息科技大学 信息与通信工程学院,北京 100101)
0 引 言
信息中心网络[1,2](information-centric network, ICN)以内容为中心并将内容分散缓存在网络基础设施如路由器中,实现了数据内容与数据位置的解耦。基于ICN路由,研究者们提出了若干路由策略,如:洪泛方式[3-5]、动态兴趣转发[6-8]、网内合作缓存[9,10]和基于SDN(软件定义网络)的策略[11]等。其中,文献[3]提出了一种基于相邻组块间关系的路由发现机制,以减少连续洪泛引起的开销;文献[5]研究了两种洪泛策略,并提出了用可用性的差异以及路由器的拓扑属性来微调洪泛半径的建议;文献[7]提出了具有名称映射(DIT-NM)的CCN中的动态兴趣传输方案,用于实时监视网络状态和流量负载信息;文献[10]提出了一种具有内容空间分区和哈希路由的协作式网络内缓存方案(CPHR),CPHR可以将总体命中率显著提高多达100%,但是此方案会产生一定的路由开销;文献[11]通过将数据平面与控制平面解耦并以集中方式管理信息,提出了一种基于SDN的路由策略,此方式便于数据的集中管理,使路由具有一定的可控性。以上方案多基于最短路径,未综合考虑时延、负载等多方面因素。
本文针对以上不足,综合考虑沿边兴趣蚂蚁队列长度、内容路由器间的内容相似度及沿边内容浓度三因素,提出一种基于蚁群算法的ICN路由算法(IRABA),将传统的蚁群算法结合到ICN路由中,解决了传统策略存在的时延大,平均路由跳数多及负载不均衡等问题。
1 蚁群算法的研究
1.1 蚁群算法的由来与基本原理
蚁群算法由意大利学者Dorigo M等根据自然界蚂蚁觅食行为提出。蚂蚁觅食行为表示大量蚂蚁组成的群体构成一个信息正反馈机制,在同一时间内路径越短蚂蚁分泌的信息素就越多,蚂蚁选择该路径的概率就更大。通过图1来描述一下蚁群的搜索过程。

图1 蚁群搜索过程
如图1所示,设A是请求源节点(蚁巢),D是内容提供节点(食物),共有30只蚂蚁进行觅食行为,每一只蚂蚁到达一个新节点分泌的信息素为1(蚂蚁只在相邻节点之间分泌信息素),蚂蚁最初的觅食路径如图1(a)所示,每只蚂蚁等概的选取一条路径进行转发,最后每条路径上分泌的信息素浓度相等,均为15;随着时间的推移,因为路径AED比路径ABCD短,路径越短越容易积累更多的信息素,如图1(b)所示,最后蚂蚁倾向于选择浓度更高的节点,即往E节点进行转发,最后尽可能快速地找寻到所需的食物。
1.2 蚁群算法的应用
从以上分析可知,应用蚁群算法可以优化路由寻址和路径规划。文献[12]针对移动机器人路径规划中蚁群算法的搜索效率问题,提出一种改进的多步长蚁群算法;文献[13]将蚁群优化算法(ACO)引入船舶气象路径问题,旨在快速、高效、准确地找到越洋船舶的最优航路。
蚁群算法还能应用于信息中心网络(ICN)的研究中,可以将ICN路由过程近似于蚁群觅食过程,节点通过感知下一跳转发节点的内容浓度的高低进行兴趣包的转发。在ICN路由中,进行内容请求的兴趣包可以用兴趣蚂蚁(IA)来代替(一个兴趣蚂蚁携带一个特定的兴趣包),而检索过程返回的数据包则可用数据蚂蚁来表示(一个数据蚂蚁携带一个特定的内容数据包)。基于以上特点,文献[14]将蚁群算法应用于移动ICN场景,忽略了IA的多样性特征,可能导致负载的不均衡;文献[15]综合考虑内容浓度和内容相似度两因素,进行兴趣蚂蚁的转发与内容的获取,此算法在无拥塞的情况下效果良好,但是当单个节点聚集多个兴趣蚂蚁时可能导致瓶颈节点的出现,影响整个路由过程的顺利进行。针对以上不足,本文确定全新的兴趣蚂蚁概率转发机制,综合考虑内容浓度(即最短路径)、节点间IA队列长度以及各内容路由器节点内容多样性等因素,选取最佳的路由路径进行转发,以获得最佳的服务质量。
2 基于蚁群算法的ICN路由
在ICN中,内容路由器(CR)中包含3张表:内容存储表(content store, CS)、待定信息表(pending interest table,PIT)和转发信息表(forwarding information base,FIB)。CS用来记录已缓存的内容信息,包括内容名称和相应的内容;PIT由内容名和已接入接口ID两部分组成,便于内容数据包的高效转发;FIB用于确定兴趣包的下一跳,以做出最佳的路由决策。基于蚁群算法的ICN路由算法基于以上原理,IA基于CS、PIT和FIB这3张表进行兴趣包的转发,相关兴趣包的路由决策在FIB中完成。
2.1 总体思路
IRABA以传统蚁群算法为基础,构建请求节点与转发节点间的内容浓度更新模型、节点间IA队列长度模型及相邻两节点内容相似度模型,最终确定最佳转发概率模型。运用轮盘赌模型进行IA转发接口的分配,使在不造成节点拥塞的情况下概率更大的转发接口尽可能多地转发IA。此算法考虑了单个节点的处理能力,有效避免了瓶颈节点的出现,更节能更高效。图2为总体设计框架。
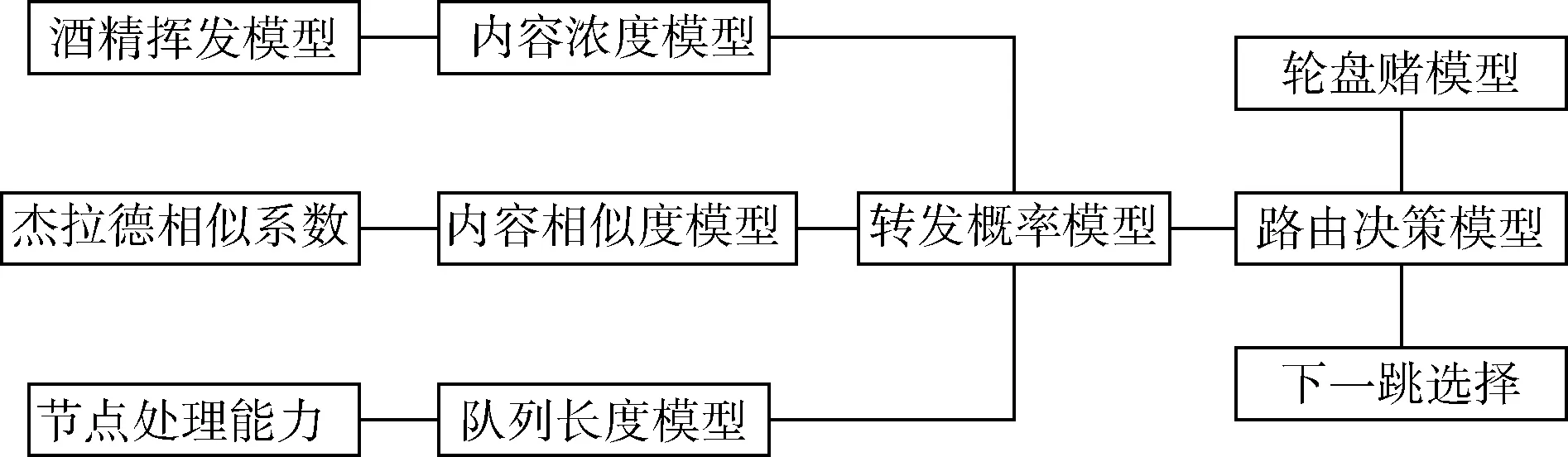
图2 总体设计框架
2.2 内容浓度模型
假设:兴趣蚂蚁只能感知一跳间的内容浓度;当一只IA到达一个新的节点,沿边均释放数值为τ的内容浓度;每一条边的初始内容浓度值为τ0。
随着时间的推移,酒精挥发的速度越来越快,直到酒精的浓度挥发到接近0。受酒精挥发模型的启发,内容浓度τ(t) 随t的变化曲线如图3所示,具体挥发表达式见式(1)。

图3 内容浓度变化曲线
(1)
如图4所示,m只兴趣蚂蚁位于请求源节点A,队列长度为m的兴趣包依次从节点A开始转发,m可变,节点A与其转发节点集间(转发节点集的确定见2.5)的内容浓度高低是IA选择下一跳转发接口的关键因素。其中,Tci,j(tn) 为CRi与CRj之间在 (0,tn] 内所积累的总内容浓度,表达式见式(2)。
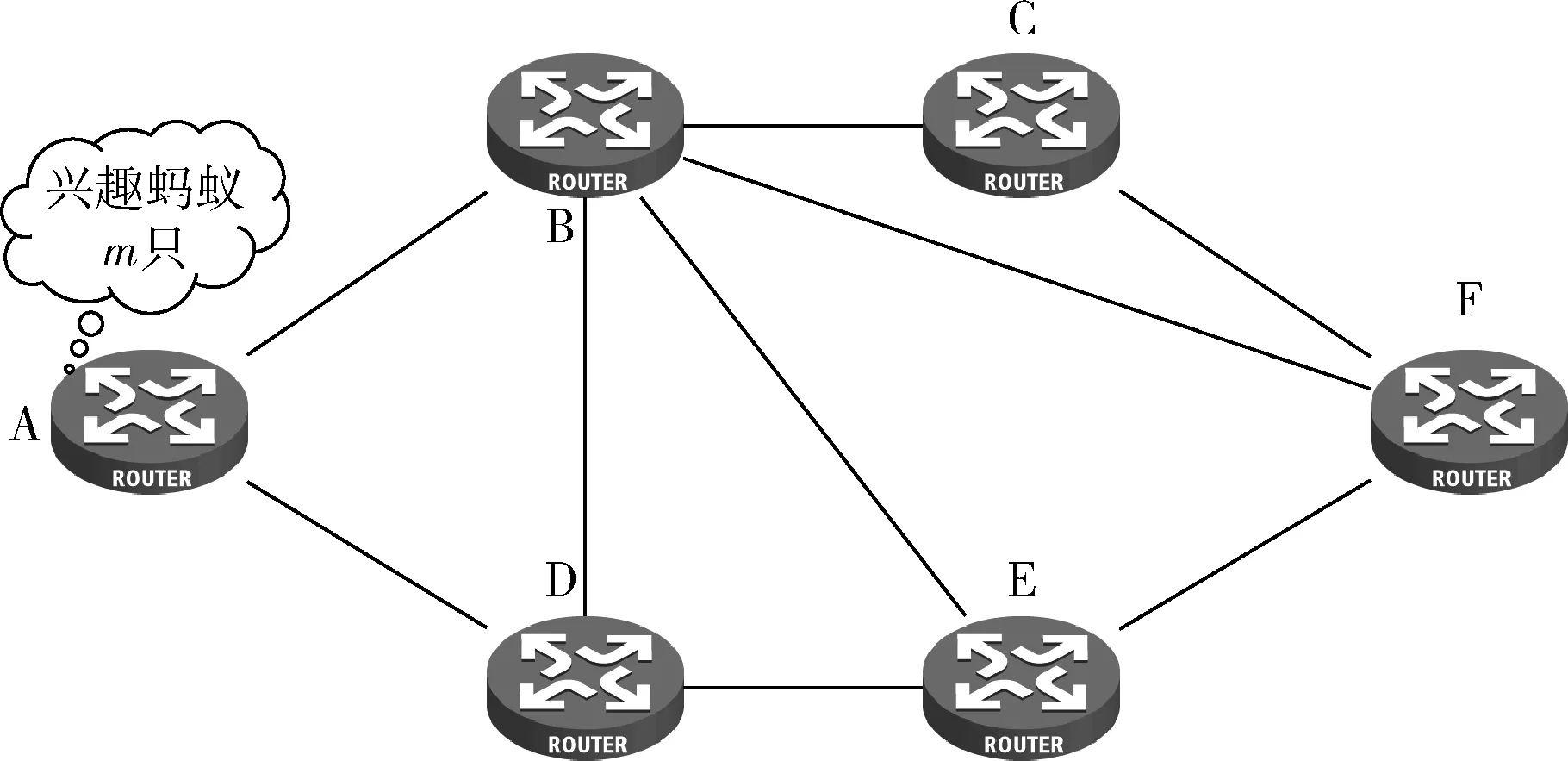
图4 基于蚁群算法的ICN模型实例
(2)
式中:aci,j(tn) 表示tn时刻沿边ij(eij) 所新增的内容浓度,rci,j(tn) 为eij在tn时刻的初始内容浓度,aci,j(tn) 和rci,j(tn) 的具体表达式见式(3)、式(4)
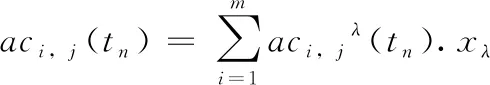
(3)
rci,j(tn)=Tci,j(tn-1)e-θ.tn
(4)
其中,aci,jλ(tn) 表示第λ只兴趣蚂蚁iaλ在tn时刻释放的内容浓度,对于xλ: 1表示iaλ经过节点j进行兴趣包的转发,0表示iaλ未经过eij。
以下是式(4)的推导过程:
(1)把 (0,tn] 时间段划分为n个小时隙,如图5所示;

图5n个时隙划分原理
(2)分别计算每一小时隙段的
rc
i,j
(
t
k
),1≤
k
≤
n
, 最后归纳总结得
rc
i,j
(
t
n
)。
1)t1时刻,已知每一条边的初始内容浓度值为τ0, 根据式(1)可得式(5);
2)t2时刻,t1时刻末的总内容浓度Tci,j(t1) 作为t2时刻的eij的初始内容浓度值,根据式(1)、式(2)即得式(6);
3) 以此类推,tn时刻,tn-1时刻末的总内容浓度Tci,j(tn-1) 作为tn时刻的eij的初始内容浓度值,即式(4)为rci,j(tn) 的最终表达式
rci,j(t1)=τ0e-θ.t1
(5)

(6)
综合式(2)~式(4),eij在 (0,tn] 内所积累的总内容浓度是初始内容浓度和新增内容浓度的叠加,具体见式(7)
(7)
由式(7)可知,tn时刻所积累的内容浓度是关于tn的连续函数,因此内容浓度更新模型是连续的。
2.3 内容相似度模型
杰拉德相似系数是衡量两个集合相似度的一种指标。本文将每个内容路由器的内容样本等效为一个集合,运用杰拉德相似系数来断定两相邻内容路由器的相似性程度的高低,最终过滤到相似度高的内容路由器,使整个网络具有更高的内容多样性。
杰拉德相似系数等于样本集交集个数与样本集并集个数的比值,具体见式(8)
(8)
所以判断内容路由器内容相似度的关键是获取各内容路由器的内容样本集(具体见算法1),最后通过式(8)得出最终的杰拉德相似系数。
算法1:
(1)找寻请求节点的转发节点集(见2.5);
(2)提取各节点(源节点和转发节点集)CS表中的内容成分,各自保存在集合中;
(3)统计各节点缓存内容的总数,确定一个内容数目的阈值(50),若节点缓存内容的总数小于等于50,则内容样本集即为最初的集合,直接跳到步骤(5),否则进入步骤(4);
(4)若节点缓存内容的总数过多(大于50),则要对初始集合进行分类,将相似的内容归为一类,根据内容名称进行分类(如:体育类内容、娱乐性内容、购物类内容等),得出最终的内容样本集;
(5)运用式(8)计算请求节点与转发节点集间的杰拉德相似系数。
2.4 队列长度
网络节点处理能力相同,设单位时间内单个节点转发兴趣蚂蚁的个数为c, 则经过时间t后,节点所处理的兴趣蚂蚁的个数为ct,源节点i拥有m个兴趣蚂蚁,源节点i的转发节点集合为 {j1,j2,…,jn} (见2.5),设每个转发节点在 (0,t] 时间段所接受的总兴趣蚂蚁的个数分别为 {Nac1,Nac2,…,Nacn}。 队列长度di,jk的大小会影响兴趣蚂蚁的转发,队列长度越长,表示两节点间汇聚了更多的兴趣蚂蚁,兴趣蚂蚁越可能选择其它节点进行转发(注:队列IA依先进先出原则进行转发)。队列长度的计算见式(9)
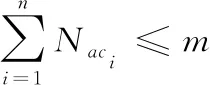
(9)
2.5 转发概率
兴趣蚂蚁的转发不仅与IA所释放的内容浓度有关,还与CR内容相似度及IA队列长度有关。综合考虑以上3因素,结合式(7)~式(9),得出iaλ(1≤λ≤m) 在eij的转发概率,以下为最佳概率转发模型,见式(10)

(10)
式中:α、β、γ为大于0的正数;Fwiλ为iaλ在节点i的下一跳转发节点集;Tci,j(tn) 为tn时间内边eij积累的总内容浓度,转发概率fpi,jλ(tn) 与其呈正相关;di,j(tn) 为tn时刻eij积累的IA队列长度,fpi,jλ(tn) 与其呈负相关;Ji,j(tn) 为tn时刻请求节点i与转发节点j的杰拉德相似系数,i(tn),j(tn) 分别为tn时刻节点i,j的内容样本集,fpi,jλ(tn) 与Ji,j(tn) 呈负相关。
下面确定内容路由器CRi的转发接口集。假设集合中具有μ个转发接口,则有Fwiλ={CRio|1≤o≤μ},Fwiλ的选取原则见下:
(1)Adiλ表示iaλ在节点i的相邻节点;
(2)若iaλ从 {CRk} (前继相邻节点集)出发遍历到CRi, 最后通过CRi进行后继相邻节点的转发,Reiλ即为这些后继相邻节点的集合,即Reiλ=Adiλ-{CRk}, 若i节点为兴趣蚂蚁请求的源节点,则有Reiλ=Adiλ;
(3)兴趣蚂蚁在请求内容节点i途中所经过的其它内容节点集记为Triλ。 当i为兴趣蚂蚁请求的源节点时,则有Triλ=∅, ∅表示空集;
(4)兴趣蚂蚁在节点i的转发节点集合记为Fwiλ,Fwiλ=Reiλ-Reiλ∩Triλ, 这一设计是为了防止路由出现环路的现象,做到高效路由,表1为图4部分节点的转发节点。
以图4中B节点为例,见例1:由表1,A为请求源节点,当m只IA已从A转发至节点B时,CDEF为其下一跳转发节点集,令 (a,b,c) 分别为各沿边内容浓度、队列长度和两节点间内容相似度。

表1 图4部分节点的转发节点
例1:已知α=β=γ=1, (a,b,c)BC=(11,8,0.25), (a,b,c)BD=(6,3,0.05), (a,b,c)BE=(4,1,0.5), (a,b,c)BF=(3,0,1), 运用式(10)计算出两节点之间的转发概率的值分别为:fB,C(tn)=0.097,fB,D(tn)=0.708,fB,E(tn)=0.142,fB,F(tn)=0.053。
由以上结论可得兴趣蚂蚁以更大的可能往节点D处转发,其次往E节点转发,然后往C点转发,最后才考虑往F处转发。因此最后考虑的就是路由问题,如何依概率将兴趣蚂蚁分配到转发节点集合中,在不造成拥塞的情况下改善Qos。
2.6 路由(Routing)
如果存在以下3种情况,单个IA转发结束:①IA已找到所请求的内容;②IA请求超时 (tr>TTL), 直接被丢弃;③兴趣蚂蚁所在节点的相邻节点Fwiλ为空集,即所处节点已无合适的转发节点,无法进行后续节点的转发。若一只兴趣蚂蚁在转发结束后仍未找到所需的内容,则在请求源节点会同样产生一只携带此内容的兴趣蚂蚁,再一次进行转发,若重复转发一次之后仍未检索出所需内容,默认此内容不存在此网络节点中(本文假定网络模型各节点已缓存了若干内容),当所确定的m只IA全部转发完毕,本轮路由结束,内容浓度和队列长度置0,等待下一轮兴趣请求重新更新,内容相似度的更新策略依据每一节点的CS表,具体见2.3的算法1。
在路由途中,兴趣蚂蚁转发节点的分配根据轮盘赌模型原理。设所给出的随机值stri∈[0,1], 将m只兴趣蚂蚁在请求节点进行转发,设兴趣蚂蚁在请求节点i处具有ωi个转发节点,转发节点集合表示为Fwiλ={CR1,CR2,…,CRω i}, 若对于∀stri, 有式(11)存在,则向对应的内容路由器CRiκ转发m×fpi,iκλ(tn) 只兴趣蚂蚁,其中fpi,iκλ(tn) 为位于节点i的iaλ往节点iκ(1≤κ≤ωi) 转发的概率,令i节点的兴趣蚂蚁个数为m, 直到兴趣蚂蚁全部转发至Fwiλ, 即满足式(12),则这一跳间的IA转发完毕,IA继续向其它节点转发,直到IA满足以上3种情况后结束转发
(11)
(12)
以请求节点B节点为例,设请求兴趣蚂蚁m=10, 节点间的转发概率见2.5例1,运用轮盘赌模型分配兴趣蚂蚁转发个数见下:
(1)取stri=0.5, 有0.097<0.5, 不满足式(11)条件; 0.097+0.708=0.805>0.5, 满足条件,兴趣蚂蚁往节点D转发,转发数目为7只。
(2)又取stri=0.75, 0.097+0.708+0.172>0.75, 满足条件,则向节点E处转发,转发数目为2只。
(3)最后剩1个转发节点F,要使转发接口集合接收10只兴趣蚂蚁,则要向节点F转发1只兴趣蚂蚁。
运用此方法转发兴趣蚂蚁,使兴趣蚂蚁尽可能往大概率接口转发,符合实际要求,而且此方法会尽可能避免拥塞的出现,平衡网络负载。
3 算法仿真及结果分析
信息中心网络节点重要性符合Zipf分布,更少的节点被更多的用户访问,具有无标度特性。因此无标度网络适合于信息中心网络的应用场景,本算法采用networkx产生两个无标度网络进行模拟仿真,其中,图6为顶点数为10,每次新增1条边的BA网络,A节点为兴趣蚂蚁请求源节点,图7为顶点数为20,每次新增2条边的BA网络,B节点为兴趣蚂蚁请求源节点,已知网络各节点已缓存若干相应的内容,利用这两个网络模型来检验此算法的性能。本算法中的参数设置见表2。若干次仿真后比较IRABA、QAPSR与AIRCS这3个算法的性能,比较在不同兴趣请求包数目下运用这3个算法的IA在网络中请求的平均路由命中率、平均负载均衡度以及平均执行时间的好坏程度。
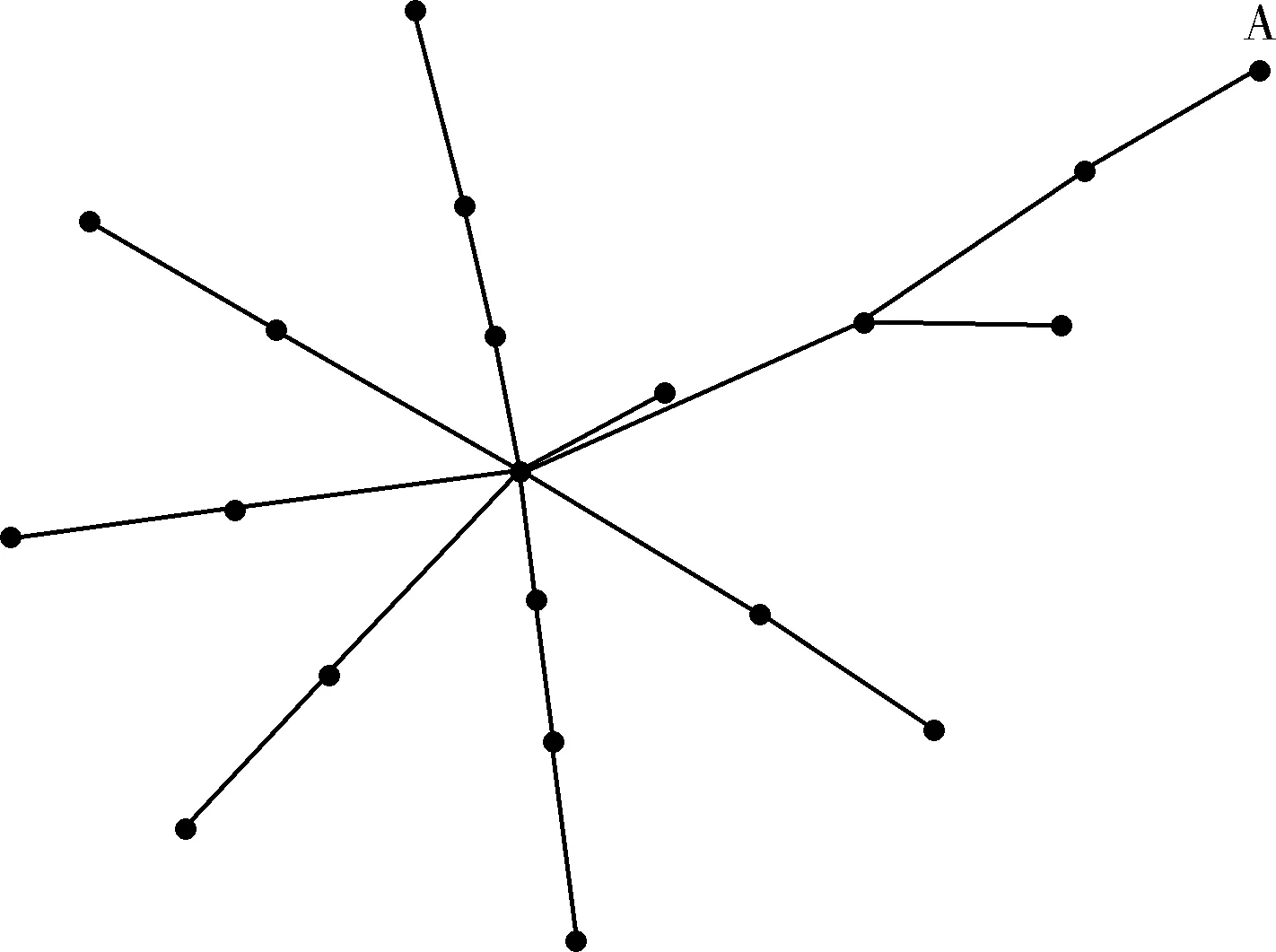
图6 BA(10,1)

图7 BA(20,2)
3.1 平均路由命中率ARSR
ARSR(average routing success rate)定义为成功检索到内容副本的兴趣包请求数占总兴趣包请求数的比例。见式(13)
(13)

表2 IRABA算法的参数设置
式中:m为兴趣包总数,xi={1,0}, 1表示兴趣蚂蚁成功检索出内容副本,反之0表示兴趣未能检索出内容副本直接消亡。
将IRABA,QAPSR和AIRCS这3个算法进行比较,仿真发现,对于两个BA网络图: BA(10,1) 和BA(20,2), 运用IRABA和AIRCS进行兴趣蚂蚁转发具有接近100%的ARSR,几乎每个兴趣蚂蚁都能检索出所需的内容副本,相比前两种算法,QAPSR的ARSR范围为91%-92%,不同数目兴趣蚂蚁(50,250,350,400)运用不同算法在两个BA网络的ARSR见表3。ARSR变化曲线分别如图8和图9所示。
3.2 平均时延AD
AD(average delay)定义为所有兴趣蚂蚁从产生到消亡所经历的时间的平均值。兴趣蚂蚁消亡的条件有两个:其一,携带此兴趣包的兴趣蚂蚁已检索到所需的内容副本;其二,携带此兴趣包兴趣蚂蚁在指定的TTL内未检索出所需内容。AD的计算公式见式(14)。其中,m为请求兴趣蚂蚁总数,ti为单个兴趣包的存在时间
(14)
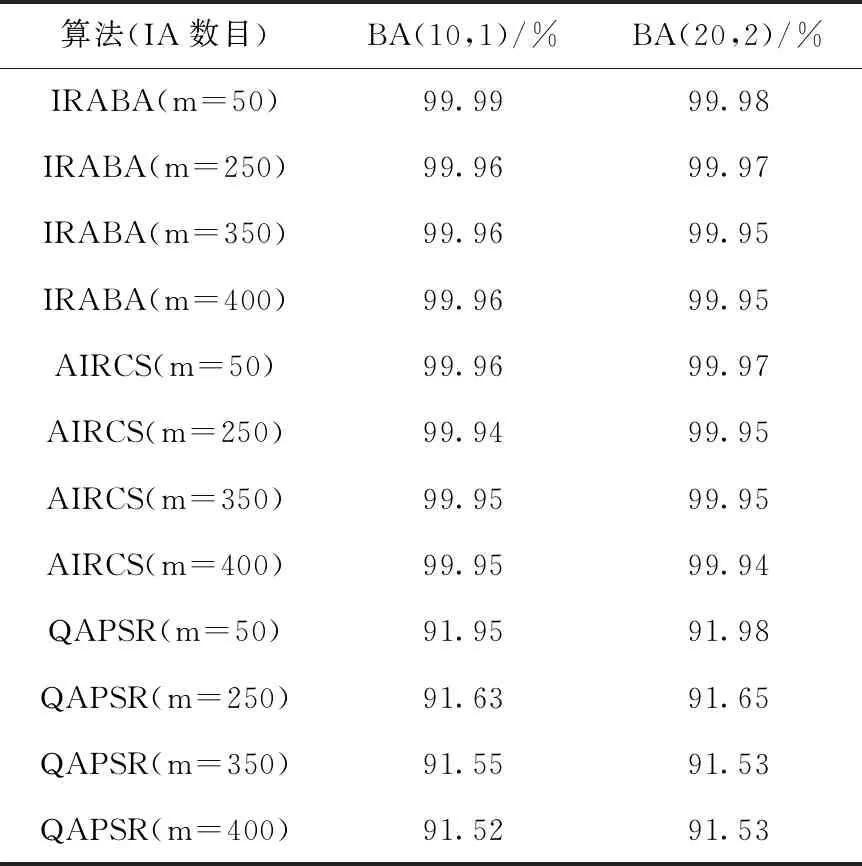
表3 不同算法在两个BA网络中的ARSR
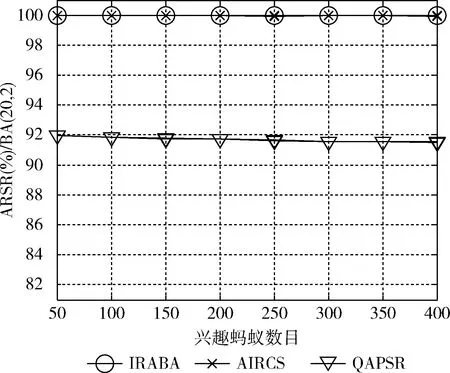
图9 BA(20,2)的ARSR变化曲线
由于IRABA考虑了IA的队列长度,综合考虑了内容浓度、节点负载以及节点内容相似度,能有效避开高拥塞节点,在请求数目众多的情况下,大大节约了兴趣包等待时间。因此在兴趣蚂蚁数量较多的情况下,相比QAPSR和AIRCS算法,IRABA在减少AD方面具有更大的优势,而QAPSR算法也考虑了拥塞情况,在减少平均时延性能方面效果良好。不同数目兴趣蚂蚁(50,250,350,400)运用不同算法在两个BA网络的AD见表4,具体AD变化曲线分别如图10和图11所示。
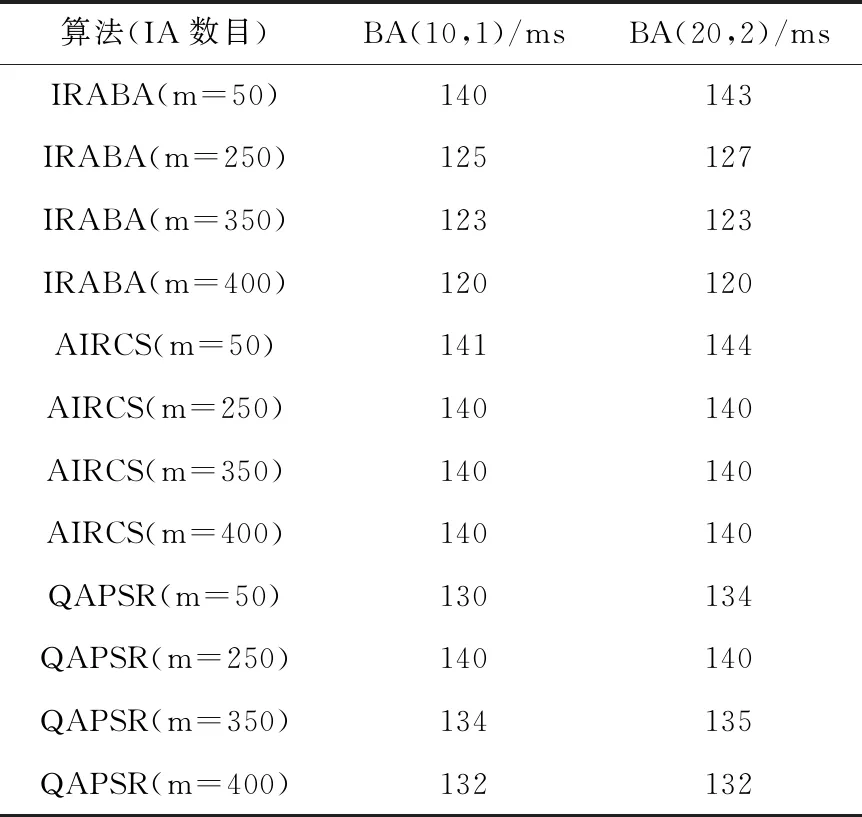
表4 不同算法在两个BA网络中的AD
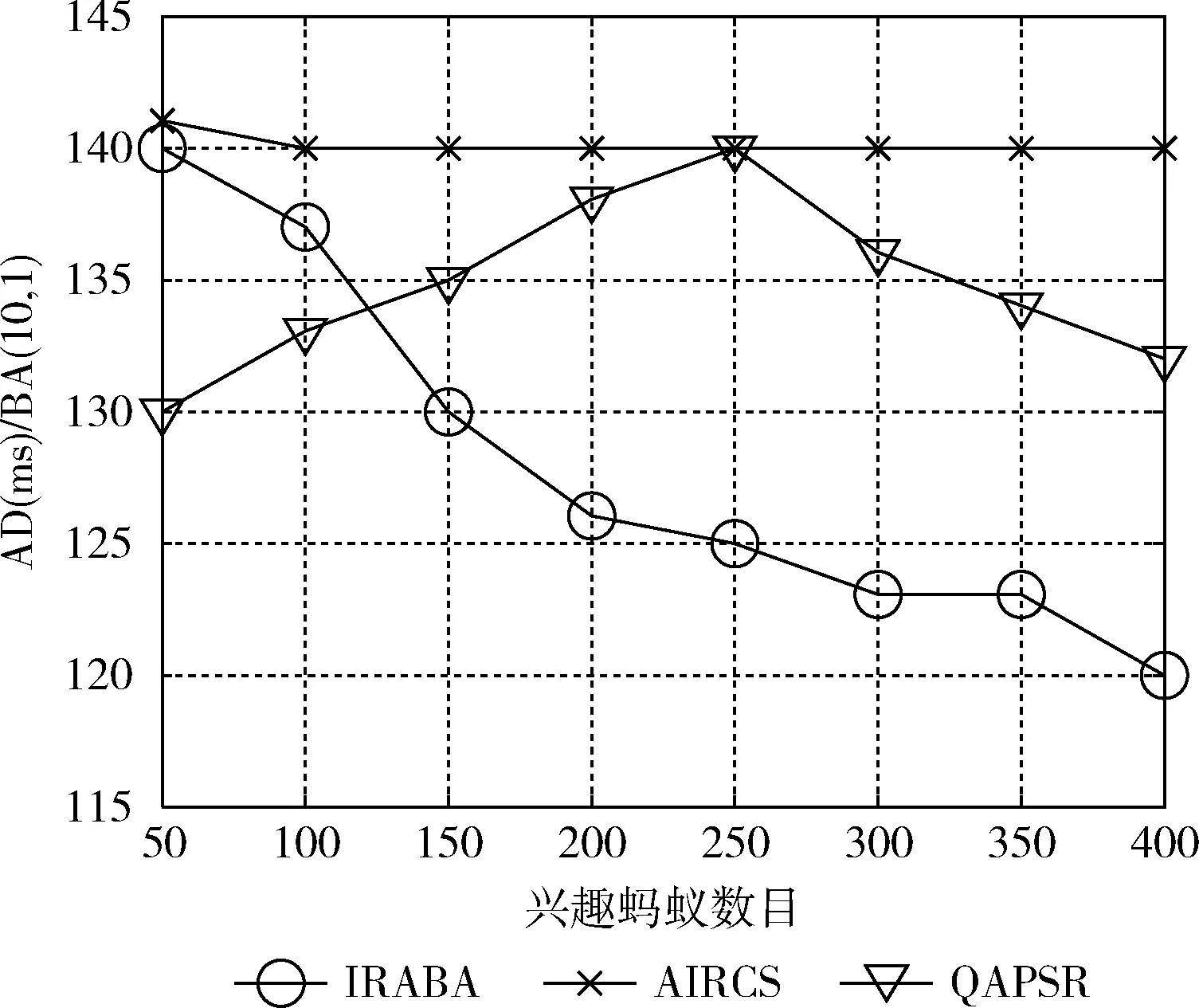
图10 BA(10,1)的AD变化曲线
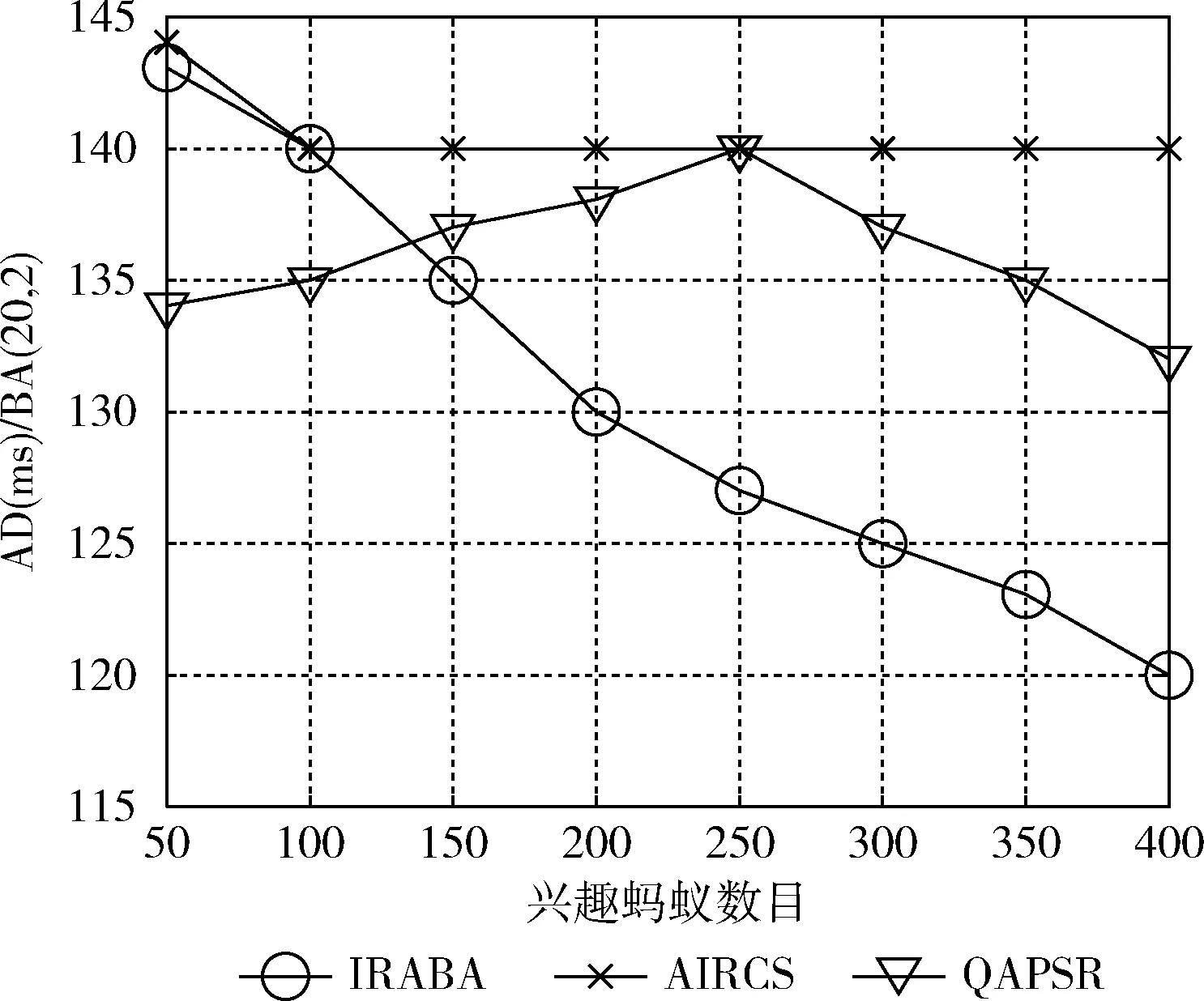
图11 BA(20,2)的AD变化曲线
3.3 平均负载均衡度ALBD
ALBD(average load balance degree)定义为所有链路负载的变化率,用来表征网络整体的拥塞性能。网络的拥塞状况可用式(15)来表示
(15)
式中: ΔNp=Np(t+Δt)-Np(t),c为每个节点的处理能力 (c=3),R为网络数据产生率,Np(t) 为t时刻网络的数据包总数。通畅状态下,ALBD=0, 有拥塞的状态下ALBD是一个常数。比较以上4种算法,只有IRABA考虑了单个节点负载情况,避免了局部拥塞节点的出现,更好地促进了兴趣蚂蚁的转发,提高了网络的整体性能,其ALBD≈0。 两个BA网络的ALBD见表5,具体变化曲线如图12和图13所示。

表5 不同算法在两个BA网络中的ALBD
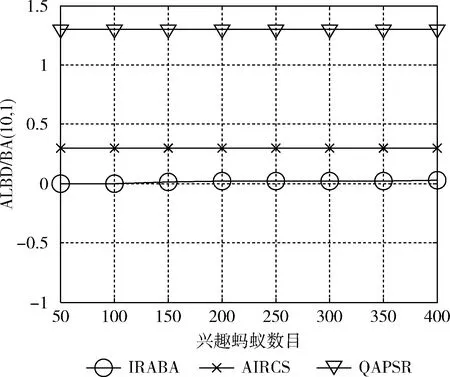
图12 BA(10,1)的ALBD变化曲线
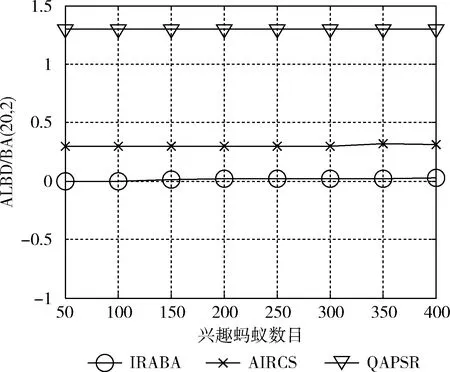
图13 BA(20,2)的ALBD变化曲线
4 结束语
为了进一步优化ICN路由问题,本文提出了一种基于蚁群算法的ICN路由算法(IRABA)。此算法通过构建内容浓度模型、节点内容相似度模型和节点兴趣蚂蚁队列长度模型,最终得出最佳的概率转发模型。此算法结合了传统的酒精挥发模型、杰拉德相似系数以及轮盘赌模型等,旨在更好更高效实现携带兴趣请求包的兴趣蚂蚁的转发。此外,将IRABA与已有的基于蚁群算法改进的算法进行比较,仿真表现在请求数不断增加的情况下IRABA具有更好的性能,更适合于兴趣蚂蚁的转发。
移动ICN的进一步发展,海量用户的接入加重了网络的负载,运用此路由算法可以改善当前网络拥塞的环境,促进网络的负载均衡,能进一步提高Qos,降低网络运行成本。
