基于《同义词词林》的商品搜索排序算法实现
2020-09-26余立毅
余立毅

摘要:在基于Lucene全文检索技术的商品搜索系统中,利用文本相似度算法来计算商品信息和关键词的相似程度,并以此对商品搜索结果排序,但是排序结果往往不尽如人意。通过分析商品信息数据的结构特点以及商品词条存在同义词的情况,在部分文本相似度算法的基础上,结合同义词词林的原子词群分类,设计一个适合于计算商品信息相似度的算法,用于提高商品搜索排序结果的准确性。
关键词:Lucene;商品搜索;相似度算法;原子词群;排序
中图分类号:TP311.13 文献标识码:A
文章编号:1009-3044(2020)24-0069-03
Abstract: In the commodity search system based on Lucene full-text retrieval technology, the text-similarity algorithm is used to calculate the similarity of commodity information and keywords, and the commodity search results are ranked based on this, but the ranking results are often unsatisfactory. By analyzing the structural characteristics of commodity information data and the existence of synonyms in commodity entries, based on the partial text similarity algorithm, combined with the atomic word group classification of the CiLin, design an algorithm suitable for calculating the similarity of commodity information. It is used to improve the accuracy of commodity search ranking results.
Key words: Lucene; commodity search; similarity algorithm; atomic word group; ranking
1 背景
近些年来,人们的消费习惯更多是网上购物,从而促使了更多的商业化购物平台的诞生。这些平台通过对外提供商品搜索、商品浏览、商品排序等服务来提升用户的使用体验,其中商品搜索结果的精确程度取决于搜索引擎的相似度算法。而目前文本相似度算法[1]大致分为四类,分别是基于字符串方法、基于语料库方法、基于世界知识方法和基于句法分析方法。在Lucene全文检索技术[2-3]中,使用语料库方法中的VSM方法来计算文本相似度[4],其核心思想是将每篇文档表示成一个基于词频或者词频–逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)权重的实值向量,之后采用BM25算法[5]替代。这类方法都是需要计算词频、文档频率和文档长度等因素,但是这些因素并不能很准确地决定搜索关键词和商品信息的匹配程度。基于世界知识方法中,利用WordNet、《知网》(HowNet)和《同义词词林》[6-7]等通用词典来计算文本相似度,这些词典能够准确地表示概念含义并能反映出概念之间的相似性和相关性。
通过对商品名称数据结构的分析,发现商家会把同义词堆叠在标题中,以期望获取到更多的流量,而且商品信息基本是名词组成。有研究证明,对词义进行有效扩展,或者对关键词做同义词替换可以明显改善信息检索的性能。本文经过以上研究分析之后,在原有BM25方法计算相似度的基础上,结合世界知识方法中的《同义词词林》,设计出一个基于相同关键词词频和同义词词频的相似度算法。
2 关键技术
2.1 Lucene全文检索技术
Lucene是apache软件基金會的一个子项目,是一个开放源代码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。索引技术是Lucene全文检索的核心功能之一,是一种称为反向索引[8](inverted index)的机制,通过预先将数据构建成索引库,在后续的搜索过程中读取索引库,实现快速检索。索引库内部的数据由两部分组成——词典和倒排表,词典是文本数据经过分词以后得到的所有不重复的词条,倒排表则是记录了存在词条的所有文件形成的链表结构。构建索引库就是将原文本数据进行分词处理,得到若干词条以及对应的文件信息,包括该词条在文件中出现的频率和词条在文件中出现的位置信息,这些词条以词典的形式保存,对应的文件信息以倒排表的形式保存。搜索关键词就是搜索索引库的过程,先在词典中找到对应的关键词,然后通过词典和倒排表之间的映射,找到出现该关键词的某个文件或一组文件的集合。
2.2 HanLP中文分词器
中文分词[9]是中文文本处理的一个基础步骤,也是全文搜索技术的核心关键之一,分词效果的好坏以及效率直接关系到搜索引擎的综合表现。HanLP中文分词器具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。默认模型训练自全世界最大规模的中文语料库,同时自带一些语料处理工具,帮助用户训练自己的模型。目前支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统。
2.3 BM25算法
Lucene全文检索的另一个核心功能就是搜索排序,排序是依据各个文本和搜索关键词之间的相似度分值,计算相似度得分的算法是BM25检索算法,它是一种用来评价搜索词和文档之间相关性的算法,基于概率检索模型提出的算法。BM25模型在二元独立模型基础上,在对查询结果的评分计算中,考虑了IDF因子、文档长度因子、文档词频和查询词频, 并利用2个自由调节因子 (k1和b) 对各种因子的权值进行调整组合。算法公式如下:
其中Q为Query,d标识搜索结果的文档,qi表示Query中的一个语素(分词),Wi表示qi的权重,R(qi,d)表示语素qi与文档d的相关性得分。N為索引中的全部文档数,n(qi)为包含了qi的文档数,k1、b为调节因子,通常根据经验设置,一般k1=2,b=0.75。fi为qi在d中出现的频率,dl为文档d的长度,avgdl为所有文档的平均长度。
2.4 同义词词林
《哈工大信息检索研究室同义词词林扩展版》是在《同义词词林》的基础上剔除不常见词并扩展,最终的词表包含 77,343 条词语,以下简称《词林》。
《词林》按照树状的层次结构把所有收录的词条组织到一起,把词 汇分成大、中、小三类,大类有 12 个,中类有 97 个,小类有 1,400 个。每个小 类里都有很多的词,这些词有根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语有进一步分成了若干个行,同一行的词语要么词义相同 (有的词义十分接近),要么词义有很强的相关性。
大类用大写英文字母表示,中类用小写英文字母表示,小类用二位十进制整数表示。第四级用大写英文字母表示,第五级用二位十进制整数表示。具体的标记参见表1。
表中的编码位是按照从左到右的顺序排列。第八位的标记有3种,分别是“=”“#”“@”,“=”代表“相等”“同义”。末尾的“#”代表“不等”“同类”,属于相关词语。末尾的“@”代表“自我封闭”“独立”,它在词典中既没有同义词,也没有相关词。
在《词林》的编码体系中,前面四层结点都代表抽象的类别,只有第五层的叶子结点才是具体的词语,同一个词语可能有多个不同的义项,即同一词语可能在不同的原子词群中同时存在。其中第一层级的大类代码含义如表2所示。
其中 A、B、C 类多为名词,D 类多为数词和量词,E 类多为形容词,F、G、H、I、J 类多为动词,K 类多为虚词,L 类是难以被分到上述类别中的一些词语。
3 系统设计
3.1 索引库字段设计
商品表products结构如下表3所示,索引库字段为id、prod_pname、prod_catalog_name、prod_price、prod_description和prod_picture。
3.2 相似度算法设计
相似度计算[10-11]只是为了对商品信息和搜索语句之间相关程度进行排序,不需要准确的相似度分值,因此可以简化BM25算法。去掉wi项,因为wi项在同一查询语句下对于各商品记录来说都是固定值。此外文档长度项dl和avgdl,也就是商品名称信息的长度,并不能决定商品排序,而应该根据搜索词和同义词在文档中出现的词频,来决定商品信息和搜索语句之间的相关程度。综上所述,BM25算法简化如下,
3.3 同义词设计
考虑到商品名称中的关键信息都是名词构成,对《词林》进行筛选,保留B类,还要对第2级分类进行筛选,过滤掉Bb拟状物、Bd天体、Be地貌和Bf气候,并且去掉@、#结尾的记录。
4 实验结果
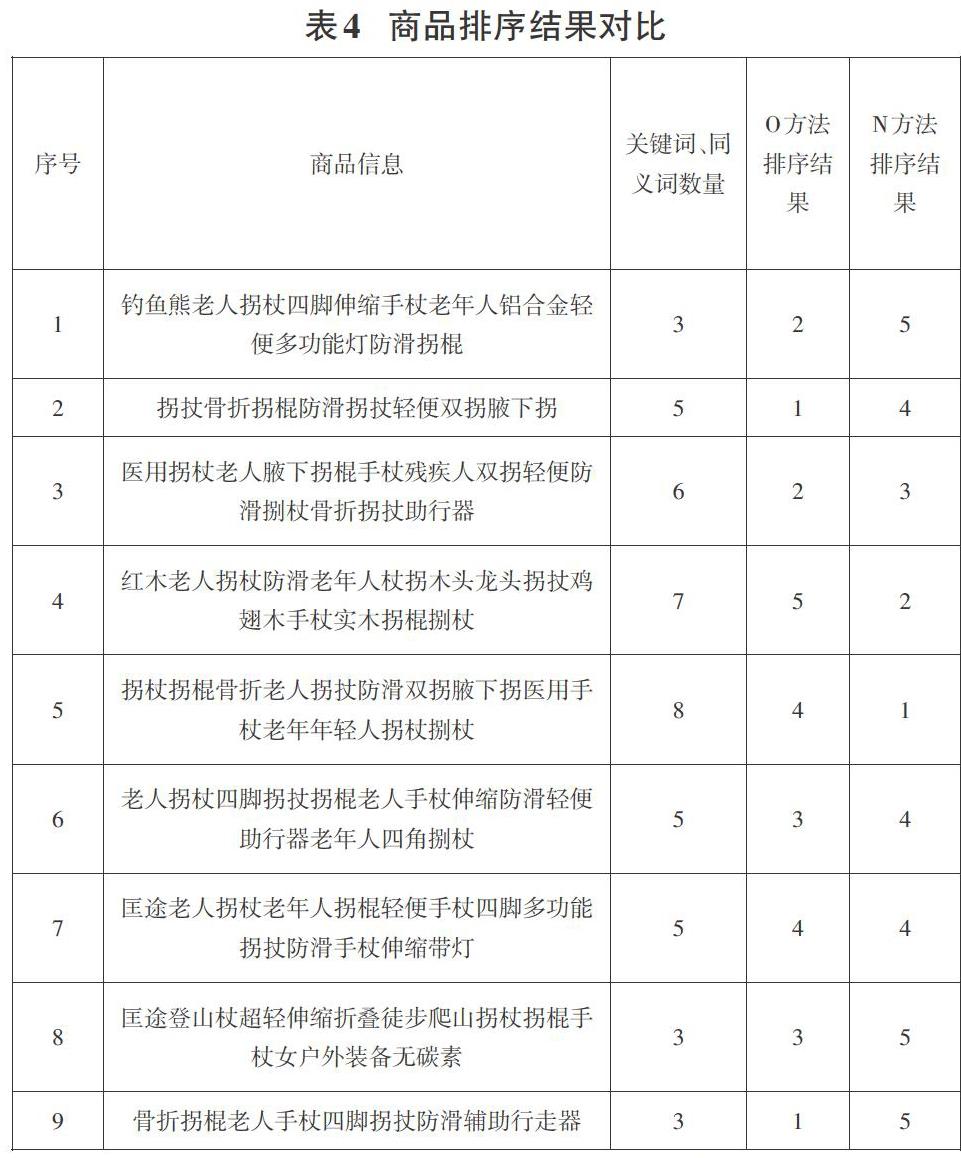
为了分析对比基于Lucene原有BM25算法和基于同义词的改进BM25算法在商品排序结果方面的差异,从《词库》中选取“拐棍”关键词作为搜索词,采用淘宝网站关于“拐棍”商品的9条信息作为测试数据集,这里原有BM25算法称为O方法,本文采用的同义词改进BM25算法称为N方法,前后方法排序结果如下表4所示的实验数据。
从两者排序结果来看,发现两者的差别较大。首先,对比商品1或8和商品9的商品信息,三个商品都用到了“拐棍”的三个同义词来描述商品,因此它们三个商品的排序应该相同,而商品9的信息长度较其他两者短,导致在O方法中排序相对靠前,在N方法中三者排序一致,类似的有商品2、6和7之间的排序对比,验证了商品信息长度不能决定商品的排序。
其次,对比商品1和商品5的商品信息,商品5用了8个同义词来描述商品,相较商品1的3个同义词要描述得更为全面,因此按照理解,商品5的相关性更高,排序更应该靠前,符合在N方法中的排序结果,验证了商品同义词数量决定商品的排序。
总的来说,基于同义词的改进BM25算法在排序结果方面更加符合人们对于商品信息与搜索关键词之间相关程度的理解。
5 结束语
通过对Lucene全文检索技术和《词库》同义词体系结构的研究,根据商品排序的实际需求,利用同义词对原有的BM25排序算法进行改进,构建出商品搜索排序系统。经过实验的对比分析,改进的排序算法得到的排序结果更为合理,说明系统的设计达到了最初的目的。
参考文献:
[1] 王春柳, 杨永辉, 邓霏, 等. 文本相似度计算方法研究综述[J]. 情报科学, 2019, 37(3): 158-168.
[2] 周敬才, 胡华平, 岳虹. 基于Lucene全文检索系统的设计与实现[J]. 计算机工程与科学, 2015, 37(2): 252-256.
[3] 徐诚皓. 基于Lucene的全文检索的研究及实现[J]. 电脑知识与技术, 2018, 14(10): 92-94.
[4] Zhou Y, Wu X Q, Wang R Y. A semantic similarity retrieval model based on Lucene[C]//2014 IEEE 5th International Conference on Software Engineering and Service Science. 27-29 June 2014, Beijing, China. IEEE, 2014: 854-858.
[5] 范晨熙, 黄理灿, 李雪利. 基于Lucene的BM25模型的评分机制的研究[J]. 工业控制计算机, 2013, 26(3): 78-79.
[6] 梅家驹. 同义词词林[M]. 上海: 上海辞书出版社, 1983.
[7] 田久乐, 赵蔚. 基于同义词词林的词语相似度计算方法[J]. 吉林大学学报(信息科学版), 2010, 28(6): 602-608.
[8] 郑榕增, 林世平. 基于Lucene的中文倒排索引技术的研究[J]. 计算机技术与发展, 2010, 20(3): 80-83.
[9] 奉国和, 郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 55(2): 41-45.
[10] 胡博, 蒋宗礼. 融合位置相关和概率排序的Lucene排序算法改进[J]. 计算机科学, 2016, 43(9): 247-249, 273.
[11] 苏琴, 谢卫华. 融合词性与位置信息改进的Lucene排序算法[J]. 电脑知识与技术, 2019, 15(17): 82-85.
【通联编辑:谢媛媛】
