中国夏季降水预测因子潜在技巧分布图及应用
2020-09-09刘伯奇祝从文
刘伯奇 祝从文
(中国气象科学研究院, 北京 100081)
引 言
目前,数值模式已从单独大气环流模式发展成为海-陆-气-冰耦合的气候系统模式,基于模式产品的动力预测逐渐成为提高汛期降水季节预测能力的重要手段。尽管动力模式对热带大气环流和气温降水的预测技巧大幅提高,但由于模式尚无法完全准确模拟ENSO演变及其遥相关和海-陆-气相互作用[39],因此模式对热带外地区,尤其是对我国夏季汛期降水的预测技巧仍十分有限[40]。考虑到动力预测能力的不足,基于大气外强迫影响东亚夏季风的机理研究,很多学者从不同角度建立了我国夏季汛期降水异常的统计预测模型。这些模型有的基于ENSO对副高的调控[41],有的基于黑潮延伸体海温异常的气候效应[42],有的基于北大西洋NAO的下游影响[43],有的基于欧亚大陆积雪[44]或土壤湿度[45],有的则基于上述多种因子[46]。

1 数据与方法
1.1 数 据
本文预测对象是中国160站夏季(6—8月)平均降水异常,参考气候态为1981—2010年平均。大气环流的异常演变包含对下垫面强迫响应的重要信息,是大气外强迫因子与预测对象之间的重要桥梁。为兼顾热带和热带外地区对流和环流对外强迫响应的差异性,本文选取的预测因子包括低纬度地区(30°S~30°N)美国CPC的CMAP(Climate Prediction Center Merged Analysis of Precipitation)逐月降水[50]和南半球、北半球中高纬度地区(30°S以南和30°N以北)日本JRA-55再分析产品的逐月200 hPa位势高度场[51]。预测对象和预测因子的研究时段均为1981—2019年,从前期秋季(9—11月)开始至前期冬季(12月—次年2月)结束,针对预测因子进行3个月滑动平均,分别从前期4个不同阶段(9—11月、10—12月、11月—次年1月、12月—次年2月)对夏季降水预测。
1.2 基于交叉检验的EOF模态空间投影方法
假设有N年降水异常资料Y,预测当年为第i年,其降水异常场为Yi,首先用剔除预测当年信息的N-1年资料进行EOF展开,得到m个EOF主模态(Vk,i,1≤k≤m),再将第i年的观测资料投影到这些主模态上,获得第i年的多元回归系数(R1,i,R2,i,R3,i,…,Rm,i),则Yi可以展开为
(1)
其中,Rk,i表示Yi对第k个EOF主模态(Vk,i)的回归系数(即预测对象)。与传统的EOF分析相比,本方法中逐年的EOF模态(Vk,i)相对独立,虽然Vk,i会随预测年份变化,但由于本方法针对每个预测年独立计算其多元回归系数Rk,i,因此无论Vk,i如何变化,Yi总能通过Rk,i和Vk,i正确地重构。本方法将EOF模态视为时变函数,并使Rk,i随之逐年调整,可避免将预测当年信息通过主成分带入交叉检验的回报模型中。
包含预测年信息时,取前4个EOF主模态和主成分能够较全面刻画我国夏季汛期降水异常的整体时空变化特征[52]。剔除预测年信息时,则需要更多模态和多元回归系数方能反映我国夏季汛期降水异常的年际变化。分析发现,随着模态数的增加,重构场和观测场的空间相关系数逐渐升高,同时两者的空间方差比(重构场的空间方差除以观测场的空间方差)也逐渐加大(图1)。在该过程中,空间相关系数和空间方差比的增幅随模态为2个增至12个的过程中迅速加大,随后逐渐减小。这种非线性增幅说明,截取前12个EOF模态和多元回归系数(R1,R2,R3,…,R12)不会对预报模型和预报结果造成不稳定影响。基于前12个EOF模态和多元回归系数的重构场能很好地重现我国东部黄河以南地区夏季汛期降水异常的年际波动(图2),重构场和观测场的平均空间相关系数为0.601,其年际变化范围为0.35~0.85(图3)。值得注意的是,基于交叉检验和空间投影的EOF主模态和多元回归系数重构场对我国华北—东北和西部地区夏季汛期降水年际变率的刻画能力较弱,这是因为上述地区夏季降水以短时强降水过程为主,故在季节平均降水异常场上信号较弱,当采用空间投影法获取多元回归系数时,很可能无法准确捕获这些地区的夏季降水异常。这与我国西部和北方夏季降水的季节可预报性低于东部和南方的传统认知相符。此外,重构场和观测场相比空间方差较小(图1),这与EOF分析方法的空间平滑特性有关,也说明有必要对预测结果进行合理的方差订正。
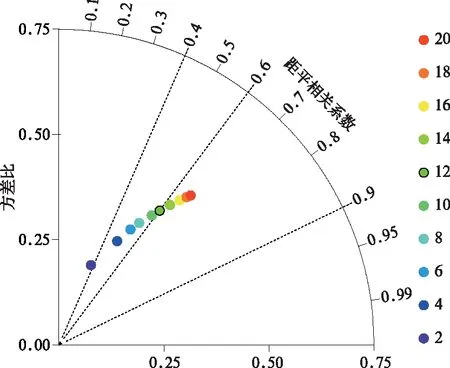
图1 基于1981—2019年EOF主模态和多元回归系数重构降水异常场和观测降水异常场(参考态)的泰勒图(不同颜色的点表示基于不同数量EOF主模态和多元回归系数的重构结果)Fig.1 Taylor diagram of the reconstructed rainfall anomaly field based on EOF modes and multiple regression coefficients referring to the observation during 1981-2019(dots in different colors denote reconstructed results using different numbers of EOF modes and principle components)

图2 基于1981—2019年前12个EOF主模态和多元回归系数重构的降水异常场与观测逐站降水异常序列时间相关系数空间分布(斜线和打点区分别表示达到0.05和0.01显著性水平)Fig.2 Correlation coefficient of reconstructed rainfall anomaly using the first 12 EOF modes and multiple regression coefficients to observed rainfall anomaly at each station during 1981-2019(areas with significance exceeding 0.05 and 0.01 levels are slashed and stippled,respectively)

图3 基于1981—2019年前12个EOF主模态和多元回归系数重构的降水异常场与观测降水异常场空间相关系数逐年时间序列Fig.3 Anomaly correlation coefficient of reconstructed rainfall anomaly using the first 12 EOF modes and multiple regression coefficients to observed rainfall anomaly during 1981-2019
2 潜在预测技巧分布图和预测因子自动选择器
通过EOF分析,将预测对象转换为12个多元回归系数序列,将预测的多元回归系数和剔除预测当年信息的EOF空间模态进行重构,即可得到预测当年降水场。因此,如何准确预测每一个回归系数成为关键问题。本章将结合降水场多元回归系数的预测问题,介绍搜索预测因子潜在预测技巧的方案和客观自动选择预测因子的思路。
2.1 潜在技巧分布图
传统的经验统计预测往往采用相关系数分布或SVD分析方法确定预测模型,但这与实际的气候预测存在较大差异。首先,相关系数反映的预测因子是预测对象的必要条件,而实际预测却需要寻找预测对象的充分条件;其次,相关系数易受极端气候事件的影响,且预测对象和预测因子之间的相关性还易受气候变化和年代际变率等缓变过程影响。因此,基于相关分析得到的预测因子随时间变化不稳定,直接导致预测模型的预测技巧不稳定,表现出强烈的年际和年代际波动。因此,基于交叉检验和最小二乘法线性拟合设计预测因子的潜在技巧分布图。
具体计算步骤如下:假设预测对象多元回归系数R(m,N)和预测因子场X(x,y,N)的总样本量为N,预测当年为第i年,其中m表示多元回归系数个数,x和y分别表示预测因子场的经向和纬向格点数,那么,①从R(m,N)和X(x,y,N)中剔除掉第i-1,i和i+1的数据,形成训练数据集。连续剔除预测当年及其相邻两年的数据是为了在年际尺度上完全去除预测当年信息,以尽量减小过度拟合的影响。该方法被广泛应用于季节预测回报试验的交叉检验中[53-55]。②基于训练数据集,利用最小二乘法拟合,建立预测因子场X(x,y,N)每个格点数据序列和预测对象的线性函数关系,得到回归参数K和截距B;再将第i年的前1年秋季至冬季的预测因子格点数据代入以上函数关系,得到第i年夏季降水场回归系数的预测值;遍历X的所有格点(x,y),得到基于不同格点数据的第i年预测回归系数场。③将预测年i循环N次,得到N年基于预测因子场X每个格点数据序列的预测回归系数场;再计算观测回归系数序列与预测回归系数场的相关系数,将其中具有显著相关性的格点视为存在潜在预测技巧,故将预测回归系数场和观测回归系数序列之间的相关系数场定义为潜在技巧分布图(potential skill map,简称PSM)。
与传统相关分析相比,PSM采用实际统计预测建模的计算流程,能够准确提取预测对象的充分条件,同时由于采用交叉检验思路,其结果可消除极端气候事件影响,因此得到的统计关系具有更好的时间稳定性。需要说明的是,在使用PSM时,需要人为确定总样本N的分析时段。本文采用的分析时段是1999—2019年,这是因为气候系统自然变率在20世纪90年代末期发生了显著的年代际调整,表现为北大西洋多年代振荡(AMO)[56]和太平洋年代际振荡(PDO)相继发生位相转换[57],受其影响,东亚夏季风的影响因子发生明显改变,这说明对统计预测而言,数据长度并非越长越好,应根据气候变化的观测事实挑选合理的训练期。
以R2为例,图4和图5展示传统相关系数分布图和PSM的区别。以R2为例,是因为它的前兆信号范围相对较广,更容易体现二者差别。事实上,其他回归系数也有类似的差别(图略)。虽然与R2显著相关的低纬度对流出现在前期秋季、冬季的热带西南印度洋(图4),但PSM显示,上述低纬度对流对R2并无潜在预测技巧(图5)。同时,前期秋季、冬季与R2显著相关的中高纬度环流异常位于欧亚大陆、北美大陆和南极大陆上空(图4),这些中高纬度环流信号在PSM上也显示出对R2的显著预测技巧(图5)。在当年春季和夏季,与R2显著相关的大范围低纬度对流位于热带东太平洋(图4),但它们在PSM上却并不明显(图5)。夏季同期具有潜在技巧的预测因子则是欧洲北部的高空环流(图4和图5)。同期预测因子为建立动力-统计相结合预测模型提供基础。尽管动力模式对中国夏季降水异常的直接预测技巧偏低,但其对低纬度降水和中高纬度高空环流却具有较好预测技巧。由于同期预测因子影响预测对象的物理过程更直接、不确定性更小,因此,可应用具有动力预测技巧的夏季热带外高空环流与观测多元回归系数的PSM,提高动力模式对中国夏季降水异常的预测技巧。以上对比说明,PSM比传统相关系数分布图更加严格,具有潜在技巧的前兆信号一定和预测因子具有显著相关,但和预测因子显著相关的前兆信号却未必具有潜在预测技巧。

图4 1999—2019年R2与不同季节预测因子的相关分布(打点区表示达到0.05显著水平,预测因子包括30°S~30°N地区降水和南半球、北半球中高纬度地区200 hPa位势高度场)Fig.4 Spatial distribution of temporal correlation coefficient between the second regression coefficient(R2) and the predictors in different seasons during 1999-2019 (the stippled denotes passing the test of 0.05 level, predictors include the rainfall in30°S-30°N and 200 hPa geopotential height in the mid-high latitude)

图5 1999—2019年不同季节预测因子对R2的潜在技巧分布图(打点区表示达到0.05显著性水平,预测因子包含30°S~30°N地区降水和南半球、北半球中高纬度地区200 hPa位势高度场)Fig.5 Potential skill map of the second regression coefficient(R2) referring to the predictors in different seasons during 1999-2019(the stippled denotes passing the test of 0.05 level, predictors include rainfall in30°S-30°N and 200 hPa geopotential height in the mid-high latitude)
2.2 预测因子自动选择器
尽管PSM能过滤掉和预测对象显著相关却没有预测技巧的前兆信号,但仍需从中确定每年的关键预测因子,以便准确开展统计预测。传统的统计预测中,挑选关键因子依赖于预报员或科研人员的经验,具有很强的主观性。为克服这一不足,在PSM的基础上,借鉴集合预报思想,设计预测因子自动选择器,其计算方法分为两步:①从具有潜在预测技巧的预测因子格点中,挑选出预测和观测回归系数符号一致率达到一定阈值的格点,进入预测因子自动选择器。对1999—2019年共21年数据,选择的符号一致率样本量阈值为17,即21年的预测中,有17年预测结果和观测值同号。②将达到符号一致率阈值的所有预测回归系数值的中位数定义为回归系数的预测值。因此,在最终建模时,仅基于单一格点上的预测因子给出回归系数的预测值,这样可有效地避免多因子建模时的过度拟合问题。
预测因子自动选择器的优点之一是完全客观化,挑选的预测因子不会因人而异;它的另一优点是能针对不同年份挑选出不同预测因子,更符合实际情况。热度图能够反映这些多元回归系数的关键因子,且不同回归系数的关键因子存在明显年际差异(图6)。每幅热度图上都有21个点,对应为在21年的回报试验中,每个回归系数逐年不同的关键因子,若某些区域内点的聚集程度越高,则表示这些区域内的预测因子在回报试验中所起作用越大。以前4个多元回归系数为例,R1的关键因子主要集中在10—12月热带西太平洋暖池对流和12月—次年1月南太平洋的高空环流R2的关键因子则更多地分布在前期秋季、冬季南半球中高纬度高空环流中,对R3而言,前期秋季、冬季的大西洋低纬度对流成为大多数年份的关键因子,而R4关键因子的空间分布则较为分散,说明其预测难度相对较大。对其余多元回归系数而言,R5和R7的关键因子主要是前期秋季和初冬欧亚大陆上空的高空环流,R9和R10的关键因子主要是11月—次年1月和12月—次年2月南极洲上空的高空环流,R12的关键因子则包括前年10—12月北太平洋低纬度对流和12月—次年1月南太平洋高空环流,而R8和R11关键因子的空间分布较分散(图略)。
预测因子自动选择器挑选的关键因子对预测对象的影响应具有较清晰的物理过程。需要指出的是,预测对象和预测因子之间时空尺度的一致性是考察预测模型物理属性的重要前提。本方法将大范围的预测对象和小范围的预测因子建立统计关系,后者对前者的影响可能有两种途径:①直接影响,即小范围预测因子通过某种“升尺度”物理过程直接影响中国大范围汛期降水异常型。以R1的关键影响因子为例,10—12月热带西太平洋暖池对流反映前冬ENSO事件通过暖池区热带对流影响我国南方地区夏季降水异常的过程,在这一过程中,海-气相互作用和热带-热带外遥相关型将西太平洋暖池的局地对流异常信号和影响整个东亚地区的东亚—太平洋遥相关波列相联系。②间接影响,即小范围预测因子代表某种大尺度信号的统计投影,在这种情况下,需要分析预测因子对应的大尺度信号,并进一步分析其影响东亚夏季降水异常的物理过程。图6揭示的某些关键因子尚无明确的机理解释,这说明对东亚夏季风和我国夏季汛期降水年际变率的理解尚不全面。因此,潜在技巧图也为深入研究东亚夏季风年际变率机理提供新的切入点。
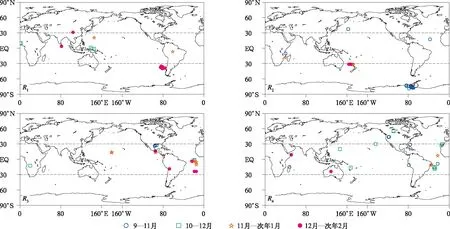
图6 预测因子自动选择器提取的1999—2019年前4个多元回归系数的预测因子热度图(预测因子包含30°S~30°N地区降水和南半球、北半球中高纬度地区200 hPa位势高度场)Fig.6 Heat map of predictors of the first 4 multiple regression coefficients during 1999-2019 obtained by the predictor automatic selection scheme(predictors include the rainfall in 30°S-30°N and 200 hPa geopotential height in the mid-high latitude)
3 历史回报试验
PSM和预测因子自动选择器可产生逐年降水场多元回归系数的历史回报值及其预测技巧。初筛后的每个预测因子均产生1个回归系数预测值,对应图7的阴影区。以前4个多元回归系数为例,通过预测因子自动选择器第1步初筛的预测因子个数依次为115,312,157和410。回报的多元回归系数值基本覆盖观测回归系数的变化范围,说明自动挑选的因子能反映回归系数变化的多样性。多元回归系数预测值的中位数集合就是各年回报的回归系数,对应图7的红线,且每个回归系数回报所用的预测因子具有明显年际差异(图6)。同时,前4个多元回归系数回报结果和观测的相关系数依次为0.70,0.57,0.82和0.87,均达到0.01的显著性水平。对第5至第12个多元回归系数而言,回报结果和观测数据的相关系数依次为0.8,0.7,0.74,0.85,0.47,0.59,0.8和0.76,均达到0.01显著性水平(图略)。以上结果说明该方法对多元回归系数具有显著回报技巧。

图7 1999—2019年前4个多元回归系数的回报检验(阴影区表示回归系数范围)Fig.7 Reforecast test of the first 4 multiple regression coefficients during 1999-2019(the shaded denotes range of regression coefficients)
基于每年预测的多元回归系数和剔除该年信息的EOF主模态,能重构出预测年夏季汛期降水异常值,通过和观测降水异常值对比反映该方法的整体预测技巧。当采用前12个多元回归系数和EOF模态进行回报时,该预测模型对我国东部大部分地区的夏季汛期降水异常具有较高的季节预测技巧(提前3个月,基于前期秋季至冬季的预测因子),大值中心位于长江流域、黄河流域和珠江流域等人口密集区(图8),这与预测技巧上限(图2)的分布特征一致。同时,该模型对我国华北—东北地区和西部地区夏季降水的季节预测能力相对较弱。从降水型的整体分布看,该模型预测的我国夏季汛期降水异常场和观测结果的符号一致率变化范围为40%~70%,平均符号一致率达到60%(图9a),两者空间相关系数的变化范围为0.25~0.65,平均空间相关系数为0.436(图9b),均远高于现有主流的气候模式动力预测技巧(空间相关系数小于0.1)[40,46,58]。当采用前12个多元回归系数和EOF空间模态进行回报试验时,回报结果和观测的符号一致率及空间相关系数的年际波动相对较小,说明该模型的预测技巧具有良好的时间平稳性。
需要指出的是,多元回归系数的物理含义是降水场在由某组EOF向量作为基底所支撑的相空间中各个分量轴上的投影,因此,需要考虑EOF模态作为相空间基底的时间稳定性对预测性能的影响。为定量分析这种影响,可分别取不同的多元回归系数和EOF模态(m=1, 2, 3, …, 12)进行回报检验(图9b和图10)。结果表明:除了2001年,其余年份回报结果相对于观测降水的空间相关系数均随着模态数的增加而增大(图9b)。多年平均结果也证明,高阶模态的引入能够进一步提高回报技巧(图10)。这说明本文中的高阶模态仍具有潜在的物理意义,它们通过增加回报结果的多样性提高预测技巧。此外,空间相关系数随m值的增长并非线性,在m为1~4阶段,空间相关系数增长最快,随后增长变缓,这说明前4个多元回归系数和主模态对降水的整体分布起决定性作用,这与庞轶舒等[52]的结果一致。若基于PSM中具有显著技巧的某一区域大范围平均的前兆信号进行我国夏季降水异常的回报试验,回报效果(1999—2019年平均空间相关系数为0.15~0.23,依赖于选取的预测因子)远低于自动因子选择器,这说明变因子预测更符合实际情况,即每年影响我国夏季降水异常的关键因子可能不同。

图8 采用前12个多元回归系数和EOF模态的回报与观测降水站点相关系数空间分布(打点区表示达到0.1显著性水平)Fig.8 Correlation coefficient of reforecast anomalous rainfall using the first 12 multiple regression coefficients and EOF modes to observed rainfall anomaly(the stippled denotes passing the test of 0.1 level)

图9 预测模型对1999—2019年中国夏季汛期平均降水异常的回报检验(a)采用前12个多元回归系数和EOF模态的回报结果相对于观测的同号率,(b)基于不同多元回归系数的回报结果相对于观测降水异常的空间相关系数的逐年变化(m表示前1~12个多元回归系数和EOF主模态的回报结果)Fig.9 Reforecast test of Chinese summer rainfall anomaly during 1999-2019 using new predicting method(a)the same sign rate between reforecast and observation using the first 12 multiple regression coefficients and EOF modes,(b)anomaly correlation coefficients between observation and reforecast based on different numbers of multiple regression coefficients(m,ranging from 1 to 12,indicates the reforecast generated by different numbers of multiple regression coefficients and EOF modes)

图10 基于1999—2019年不同多元回归系数的回报结果相对于观测降水异常的空间相关系数多年平均值Fig.10 Mean value of anomaly correlation coefficients between observation and reforecast based on different numbers of multiple regression coefficients during 1999-2019
图11是将历史回报的降水异常转换为降水距平百分率后,基于国家气候中心预测技巧评分标准(PS评分)的回报技巧。结果表明:在回报时段内,该模型预测的我国夏季汛期降水距平百分率平均PS评分为71.00分,除2009年PS评分偏低以外,其余年份的PS评分均在70分左右,回报结果PS评分的时间平稳性良好(图11b)。如前文所述,该模型在采用EOF分析和统计建模的过程中,不可避免地使预测降水的方差衰减。为合理定义方差订正系数,需要首先计算预测结果PS评分对方差订正系数A(线性放大倍数)的响应曲线(图11a)。如图11a所示,在A=5.5后,PS评分不再随A的增大而增加,说明A=5.5是适用于该模型的相对合理的方差订正系数。订正后(A=5.5),该模型回报结果的平均PS评分技巧从71.00分进一步提升至82.10分,其变化范围为70分~90分,展现出稳定的高回报技巧(图11b)。

图11 回报降水距平百分率的PS评分对方差订正系数的响应函数(a)和方差订正前后的PS评分(b)Fig.11 Response PS score curve of the reforecast percentage of rainfall anomaly to the variance correction parameter(a) and PS score before and after variance corrected(b)
4 结论与讨论
由于传统的相关分析和主观挑选预测因子进行季节预测存在较大不确定性,本文提出PSM和预测因子自动选择器,并基于二者建立我国夏季汛期降水异常的季节预测模型。该模型对我国夏季汛期降水异常具有稳定的较好历史回报技巧。具体结论如下:
1) PSM采用交叉检验思路,能够反映预测因子对预测对象的潜在预测技巧,且不受极端样本影响。PSM完全基于实际的统计预测建模流程,在逻辑上体现寻找预测对象的充分条件的特点,是对传统相关系数分布图(寻找必要条件)的重要补充。结合两者结果,可揭示符合预测对象充要条件的预测因子。
2) 预测因子自动选择器借鉴集合预报思想,从PSM中挑选出具有最显著潜在预测技巧的预测因子,再通过大量预测结果的集合产生最终预测产品,实现逐年自动挑选预测因子的功能。该方案不仅克服了依赖于预报员主观经验选择预测因子的不足,也为进一步深入东亚夏季风年际变率可预报性研究提供新切入点。
3) 基于PSM和预测因子自动选择器的统计预测模型对我国夏季汛期降水异常的回报技巧较高。在基于前期秋季、冬季预测因子的21年回报试验中,预测结果和观测的平均符号一致率为60%,平均空间相关系数为0.436,平均PS评分为71.00分,经方差订正后,平均PS评分可达82.10分,远高于现有动力模式的预测技巧。
目前,动力模式直接输出的降水预测技巧偏低,但其对东亚夏季风主要环流系统(西北太平洋副热带高压、东亚大槽、高空副热带西风急流等)的预测技巧正在逐步提高。因此,通过统计方法利用动力模式输出的环流信息提高我国夏季汛期降水异常预测能力成为气候预测研究的新热点,且已有一些动力-统计相结合预测汛期降水异常的成功案例[59-61]。本文采用的预测因子既包含低纬度降水,也包含中高纬度高空环流,动力模式对二者具有一定的预测能力,如何将本文提出的统计预测模型和动力预测结果相结合,进一步发展全新的动力-统计相结合预测模型,将成为未来的工作重点。
