基于ConvLSTM双通道编码网络的夜间无人车场景预测
2020-09-04孙韶媛刘训华顾立鹏
李 想,孙韶媛,刘训华,顾立鹏
(1.东华大学 信息科学与技术学院,上海 201620;2.东华大学 数字化纺织服装技术教育部工程研究中心,上海 201620)
0 引言
场景预测[1-2]是根据已知视频序列预测下一帧或几帧图像,让无人车提前进行决策,降低了因决策不及时发生交通事故的风险。现如今,场景预测研究可见光领域较多,夜视领域很少,但夜间场景下的场景预测、驾驶决策等技术在无人车研究技术中占有重要的地位[3-4]。红外图像相比于可见光图像[5],缺少色彩信息、清晰度低、纹理细节特征少等特点,使得无人车对夜间周围环境进行准确感知并及时做出行为决策的难度比白天更大[6]。
目前场景预测算法主要分为两种:有监督场景预测和无监督场景预测。有监督场景预测,T.C.WANG等人[7]利用视频序列及其语义图序列、光流图和多个双通道网络得到了长时间的高清预测图像。J.T.PAN等人[8]利用语义图的语义信息、首帧图像以及光流图实现了图像的较准确预测。以上两种方法都是基于语义图的标签信息以及光流法进行分辨率的提升,此类网络得到的预测图像清晰度较高,预测的未来帧数较多,但计算量大,预测速度慢。无监督场景预测,Lotter等人[9]基于卷积长短时记忆(convolutional long-short term memory,ConvLSTM,)提出了一个预测编码网络,将图像的预测误差进行前向传播,实现了自然场景下的视频预测。该网络较好地捕获了动态信息,预测速度比较快,但预测图像清晰度低,预测未来帧数少。
无人车驾驶决策最重要的是实时性和准确性[10],有监督场景预测预测速度慢,实时性达不到,无监督学习虽实时性可以实现,但预测图像清晰度低,预测帧数少。本文结合文献[7]的双通道思路和文献[9]的动态信息提取思路,兼顾实时性和准确性,提出了基于ConvLSTM 的双通道编码夜间无人车场景预测网络。针对红外图像的特点,以及场景预测所需要获取的信息,利用两个子网络对红外图像分别进行编码;将两个子网络得到的特征进行融合后输入到解码网络中,得到预测图像;最后将预测图像输回网络中,继续预测下一帧,实现多帧预测。该网络具有端到端的特点,实现了较高的准确性、较好的实时性以及多帧预测。
1 网络结构
1.1 基础网络
本文所提出的基于ConvLSTM 的双通道编码夜间无人车场景预测网络包括卷积神经网络、卷积长短时记忆网络、残差网络和反卷积网络。
1.1.1 卷积和反卷积神经网络
卷积神经网络[11](convolutional neural network,CNN)在图像处理中有着出色的表现,利用卷积层提取图像的特征,将高维特征映射为低维特征,实现分类等任务。反卷积网络与卷积网络操作相反,是将低维特征映射为高维特征或图像,主要用于语义分割和图像生成等领域。这两种网络的一大特性是权值共享,大大减少了参数量,提高了计算速度。
1.1.2 卷积长短时记忆网络
长短时记忆[12](long-short term memory,LSTM)网络是目前最常用的一种循环神经网络,它在很多涉及时序性的领域,例如语音识别、视频分析、序列建模等都取得了很好的成果,原始的LSTM 对时序数据处理很好,但在空间数据上存在冗余;而ConvLSTM恰好弥补了这一点,不仅具有LSTM 的时序建模能力,还能像CNN 一样刻画局部特征,减少了空间上的数据冗余,最终可以获取时空特征。
1.1.3 残差网络
残差网络[13](residual network,ResNet)相比于VGG(visual geometry group,VGG)等网络多了短跳转连接(shortcut connection)操作,该操作是将网络较之前的特征图叠加到当前特征图,弥补了由于池化操作丢失信息的缺点,大大提高了后续网络对特征图的理解能力,从而提高最终结果的准确度。
1.2 基于ConvLSTM 的双通道编码夜间无人车场景预测网络
本文提出的双通道编码预测网络包括4 个模块:时间子网络、空间子网络、特征融合网络和解码网络。本文所构建的基于ConvLSTM 的双通道编码夜间无人车场景预测网络结构图如图1所示。
整个网络的输入分为两部分:前n帧的视频序列X={X1,X2,…,Xn}和当前时刻图像Xt。相邻序列的差分图像循环输入到时间子网络中,提取时序信息;当前时刻图像Xt输入到空间子网络中,提取空间特征;利用特征融合网络融合得到时空特征,然后输入到解码网络中,得到预测图像。最后将预测图像替换Xt,实现多帧预测。
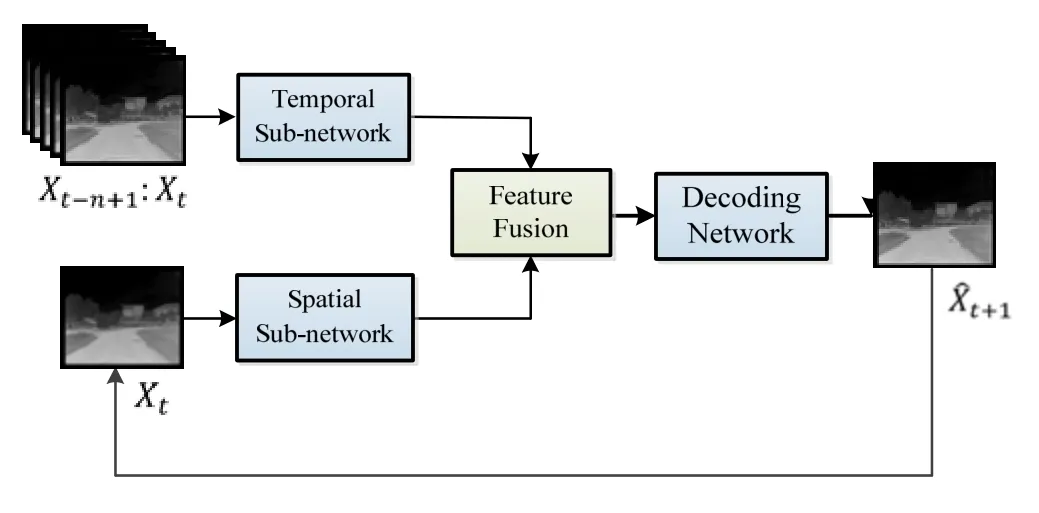
图1 基于ConvLSTM 的双通道编码夜间无人车场景预测结构图Fig.1 The structure diagram of dual-channel encoding based on ConvLSTM for night scene prediction
1.2.1 基于CNN 和ConvLSTM 的时间子网络
时间子网络负责提取视频序列时序特征,由CNN和ConvLSTM 网络构成。该网络输入是相邻两帧的差分图像,利用CNN 对差分图像进行特征提取,经池化得到较低维特征图,减少了输入ConvLSTM 的参数量,加快运行的速度。ConvLSTM 提取动态信息,得到图像间的时序信息以及图像部分空间信息。基于CNN 和ConvLSTM 的时间子网络结构图如图2所示,从左到右分别是红外差分图像、卷积池化层、ConvLSTM 和时序特征。图2是时间子网络的一个过程,由一系列卷积、池化和一个ConvLSTM 构成,利用3X3 卷积核,提取红外差分图像特征,经最大池化操作得到低维特征图,最后输入到ConvLSTM 网络中,提取时序特征。将多帧红外差分图像输入时间子网络,促使ConvLSTM 对之前信息进行部分遗忘,对当前信息进行记忆,最终学习到红外视频序列的时序特征。本文网络输入10 帧图像,即9 张差分图像,时间子网络通过9 次学习来提取视频序列的时序特征。
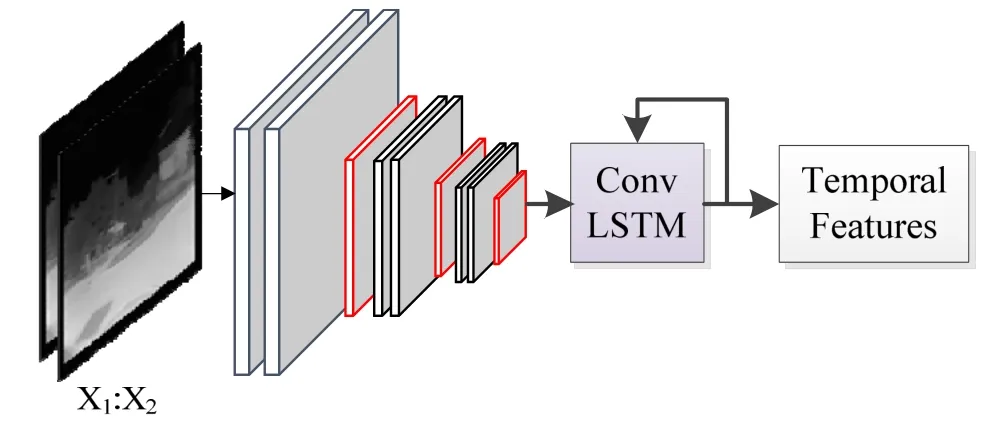
图2 基于CNN 和ConvLSTM 的时间子网络结构图Fig.2 Structure diagram of temporal sub-network based on CNN and ConvLSTM
1.2.2 基于ResNet 的空间子网络
空间子网络负责提取红外图像的空间信息。考虑到CNN 网络存在多个池化阶段,会丢失部分提取的特征信息,在最后解码时一些细节不能恢复,影响预测图像清晰度,因此空间子网络利用ResNet 网络进行特征提取。ResNet 网络增加了shortcut connection操作,即将之前的特征图与当前的特征图融合后再进行池化、卷积,这样处理弥补了池化阶段的信息丢失问题,在最后解码得到的图像中清晰度会有所提高。基于ResNet 的空间子网络结构图如图3所示,从左到右依次是红外图像、残差层、池化层和空间特征。该子网络选择了较小的卷积核,主要是从以下两方面进行考虑:①卷积核过大,参数量增加,从而导致计算量增加;②卷积核过大,不能很好地提取图像的特征,从而影响最终生成图像的清晰度。最后的池化用了最大池化,而不是平均池化,也是考虑到清晰度的问题。
1.2.3 特征融合网络和解码网络
特征融合网络是将时间子网络和空间子网络提取的两个特征进行融合,并利用ResNet 网络对得到的特征进行进一步提取。特征融合网络的结构图如图4所示。
解码网络是以反卷积神经网络为基础进行构建。输入是特征融合网络得到的时空特征,与空间子网络中的卷积相对应,经过一系列反池化和反卷积操作,得到预测图像。
2 实验及结果分析
2.1 实验配置
本实验所使用的硬件及软件配置如表1所示。网络是在Tensorflow 深度学习框架下搭建,在此基础上进行网络的训练与测试。
2.2 实验数据与步骤
实验所用视频由实验室载有红外摄像头的无人车在夜间拍摄所得。考虑到图像信息冗余性问题,将数据集每隔3 帧抽取一帧,得到了6500 张图像,训练集为6000 张红外图像,测试集为500 张红外图像。训练过程中学习率为0.0001,迭代的次数为100 k,整个网络的训练时间为2.5 d,通过多次迭代学习红外视频序列的时空特征,保存模型参数,模型的参数通过Adam 算法优化获得。将测试集中的图像输入到训练好的模型中,得到预测结果,具体的实验流程如图5所示。
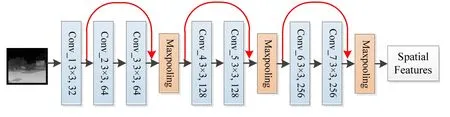
图3 基于ResNet 的空间子网络结构图Fig.3 Structure diagram of spatial sub-network based on ResNet
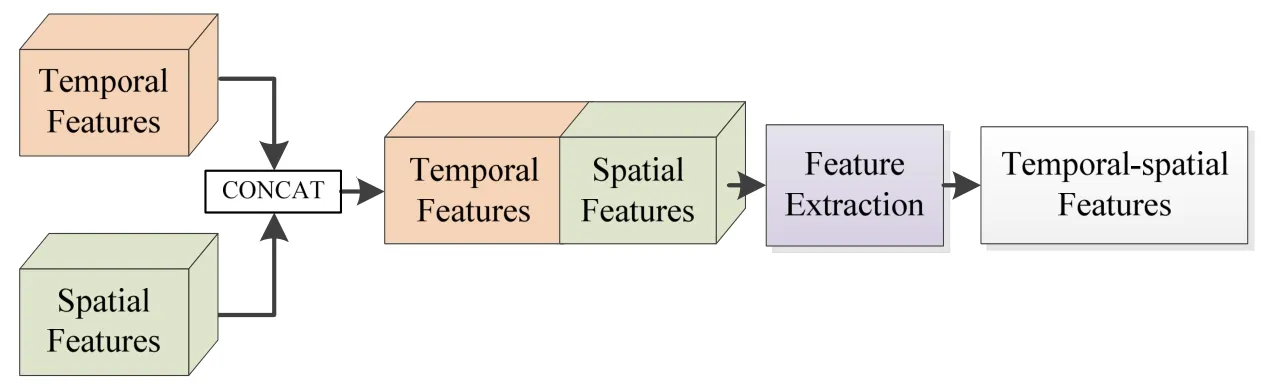
图4 特征融合网络Fig.4 Feature fusion network

表1 实验配置Table 1 Experimental configuration
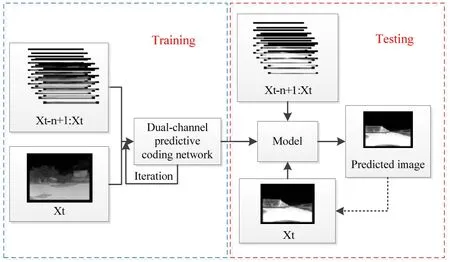
图5 实验流程图Fig.5 Experimental flowchart
常见的图像预测评估中主要有以下两个评价指标[14]:
1)峰值信噪比(peak signal to noise ratio, PSNR)
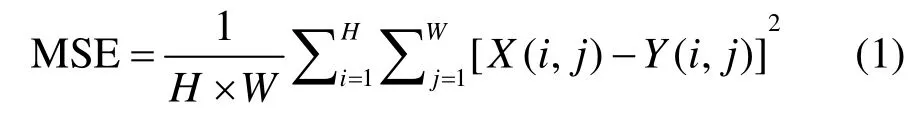
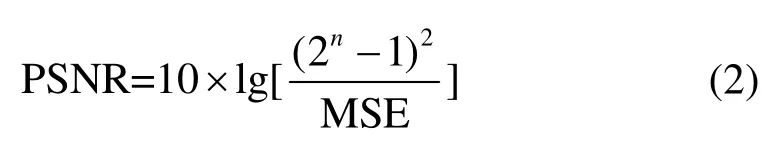
式中:MSE 表示实际图像X和预测图像Y的均方误差(mean square error);H、W分别表示图像的高度和宽度;PSNR 的单位是dB,数值越大,表示失真越小,即图像内容越接近。
2)结构相似性(structural similarity, SSIM)

式中:μX、μY分别表示实际图像X和预测图像Y的均值;σX、σY分别表示图像X和Y的方差;σXY表示图像X和Y的协方差;C1、C2是维持稳定的常数。SSIM数值越大,表示图像内容越接近。
2.3 实验结果与分析
将测试集输入到场景预测网络中,得到预测图像序列。输入10 帧图像,可以预测未来8 帧图像,因数据集是每隔3 帧抽取一帧,则可以预测到第32 帧图像,即1.2 s 以后的图像,预测的结果如图6所示,分别给出了转弯、行人和车辆3 种典型场景的预测场景图像与真实场景图像的比较。

图6 红外图像场景预测结果Fig.6 Infrared image scene prediction results
从图6预测结果可以看出,本文的场景预测图像接近真实值,预测图像较准确,清晰度较高。图6共有3 组预测结果,每一组的第一行是真实场景的8 帧图像,第二行是网络预测的8 帧图像。图6(a)很好地反映了车辆行驶过程中道路转弯的变化,道路轮廓预测准确、清晰,路面上的一些标识可以预测到第5 张(即第20 帧);图6(b)能够合理地预测道路中行人的位置变化,虽然预测的行人轮廓比较模糊,但移动位置准确,并且可以合理填补消失的空缺;图6(c)可以反映前方行驶车辆的运动情况,虽然后续预测图像中车辆不是很清楚,但依旧可以看出车辆的基本轮廓。图6(c)倒数2 张预测的图像中车辆比较模糊,初步考虑是车辆行驶的速度过快,相邻帧车辆位置变化比较大导致的。
为了更好地评价预测的结果,进行了定量的分析,将复制前一帧图像、Conv-LSTM[15]、Prednet 网络、SAVP 网络[16]以及本文提出的网络在PSNR 和SSIM 上进行了对比,对比的结果是针对不同网络分别预测出的第1 帧红外图像而言,具体结果如表2所示。
PSNR 和SSIM 指标数值越大代表预测图像与真实图像越接近,预测时间越小预测速度越快。从表2可以看出,本文提出的方法无论是在PSNR、SSIM 还是预测时间上,其效果优于其他方法,SSIM 达到0.9以上,说明预测图像准确度较高;预测一帧图像的时间是0.02 s,即1 s 可以预测50 帧,达到了实际中实时性要求。
图6和表2分别从定性和定量的方面说明了本文网络预测图像清晰度高、预测内容较准确度且速度快,满足实时性要求。但本文也存在一些不足,图6(c)预测的图像中车辆的轮廓预测不是很清楚,初步考虑是数据集中含有车辆的红外图像较少以及未来的不确定性导致的。
3 结论
本文针对红外图像清晰度低、无色彩信息等特点,提出了基于ConvLSTM 的双通道编码夜间无人车场景预测网络,利用时间子网络提取视频序列的时序特征,空间子网络提取图像的空间特征,通过特征融合网络融合后输入到解码网络,得到预测图像。本文网络能够较准确地预测未来场景的变化,并且可以预测未来1.2 s 后的场景,改善了之前预测图像模糊、预测帧数少的问题,为驾驶决策提供了足够的决策时间,满足实时性和准确性的要求。目前公开的红外数据集基本没有,本文所使用的数据集是自己课题组成员采集,场景相对比较单一,主要包括校园环路或者教学区等一些道路。之后会针对更复杂的场景进行进一步的研究。
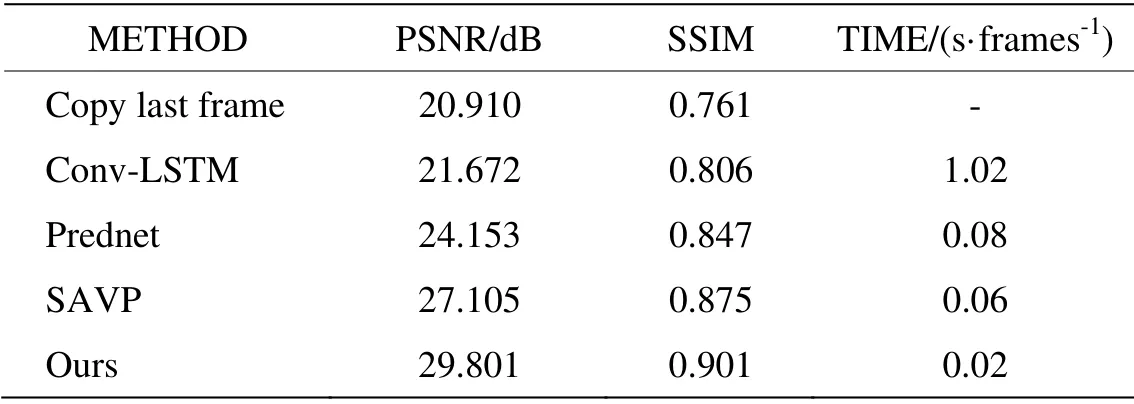
表2 场景预测不同方法对比结果Table 2 Comparison results of different methods for scene prediction
